R语言入门-02:向量
原创
2. 向量
在R语言中,向量(Vector)是相同基本类型元素组成的序列,相当于一维数组。
2.1. 向量生成
(1) 用 c() 结合到一起
c(2,5,6,2,9)
c("a","f","md","b")
[1] 2 5 6 2 9
[1] "a" "f" "md" "b" (2) 连续的数字用冒号“:”
1:5
[1] 1 2 3 4 5(3) 有重复的用rep(),有规律的序列用seq(),随机数用rnorm()
rep("x",times=3)
seq(from=3,to=21,by=3)
rnorm(n=3)
[1] "x" "x" "x"
[1] 3 6 9 12 15 18 21
[1] -0.8970375 1.3205699 0.22382112.2 对单个向量进行的操作
(1) 赋值给一个变量名
规范的赋值符号 <- 快捷键: Alt+减号
x = c(1,3,5,1) #随意的写法; = 可以随时代替<-赋值符号!!!
x
x <- c(1,3,5,1) #规范的赋值符号快捷键: Alt+减号 <- !!!
x
> x
[1] 1 3 5 1
> x
[1] 1 3 5 1赋值+输出一起实现
x <- c(1,3,5,1);x
(x <- c(1,3,5,1))
[1] 1 3 5 1
[1] 1 3 5 1(2) 简单数学计算
x+1
log(x)
sqrt(x) #开方
[1] 2 4 6 2
[1] 0.000000 1.098612 1.609438 0.000000
[1] 1.000000 1.732051 2.236068 1.000000(3) 根据某条件进行判断,生成逻辑型向量
x>3
x==3
[1] FALSE FALSE TRUE FALSE
[1] FALSE TRUE FALSE FALSE(4) 初级统计
max(x) #最大值
min(x) #最小值
mean(x) #均值
median(x) #中位数
var(x) #方差
sd(x) #标准差
sum(x) #总和
[1] 5
[1] 1
[1] 2.5
[1] 2
[1] 3.666667
[1] 1.914854
[1] 10一些重要函数!!!
length(x) #长度;x里面含有的元素
unique(x) #去重复;输出元素!!!
duplicated(x) #判断对应元素是否重复,输出逻辑值;同unique
!duplicated(x) #判断对应元素是否重复,且如果是第一次出现标记为TRUE,重复出现标记为FALSE
table(x) #重复值统计
sort(x) #排序,默认从小到大;从help文档中看
sort(x,decreasing = F)
sort(x,decreasing = T)
?sort #看help文档
[1] 4
[1] 1 3 5
[1] FALSE FALSE FALSE TRUE
[1] TRUE TRUE TRUE FALSE
> table(x) #重复值统计
x
1 3 5
2 1 1
[1] 1 1 3 5
[1] 1 1 3 5
[1] 5 3 1 1
#打开帮助文档2.3 对两个向量进行的操作(比较运算、数学计算、连接:均能发生循环补齐)
赋值x,y
x = c(1,3,5,1);x
y = c(3,2,5,6);y
> x = c(1,3,5,1);x
[1] 1 3 5 1
> y = c(3,2,5,6);y
[1] 3 2 5 6(1) 比较运算,生成等长的逻辑向量:会发生循环补齐
判断:一对一元素是否相等
x == y
y == x
[1] FALSE FALSE TRUE FALSE
[1] FALSE FALSE TRUE FALSE若元素个数不一致,会发生循环补齐,且根据最长元素的对象来定(输出结果中会出现warning,但不影响结果的正确性!)
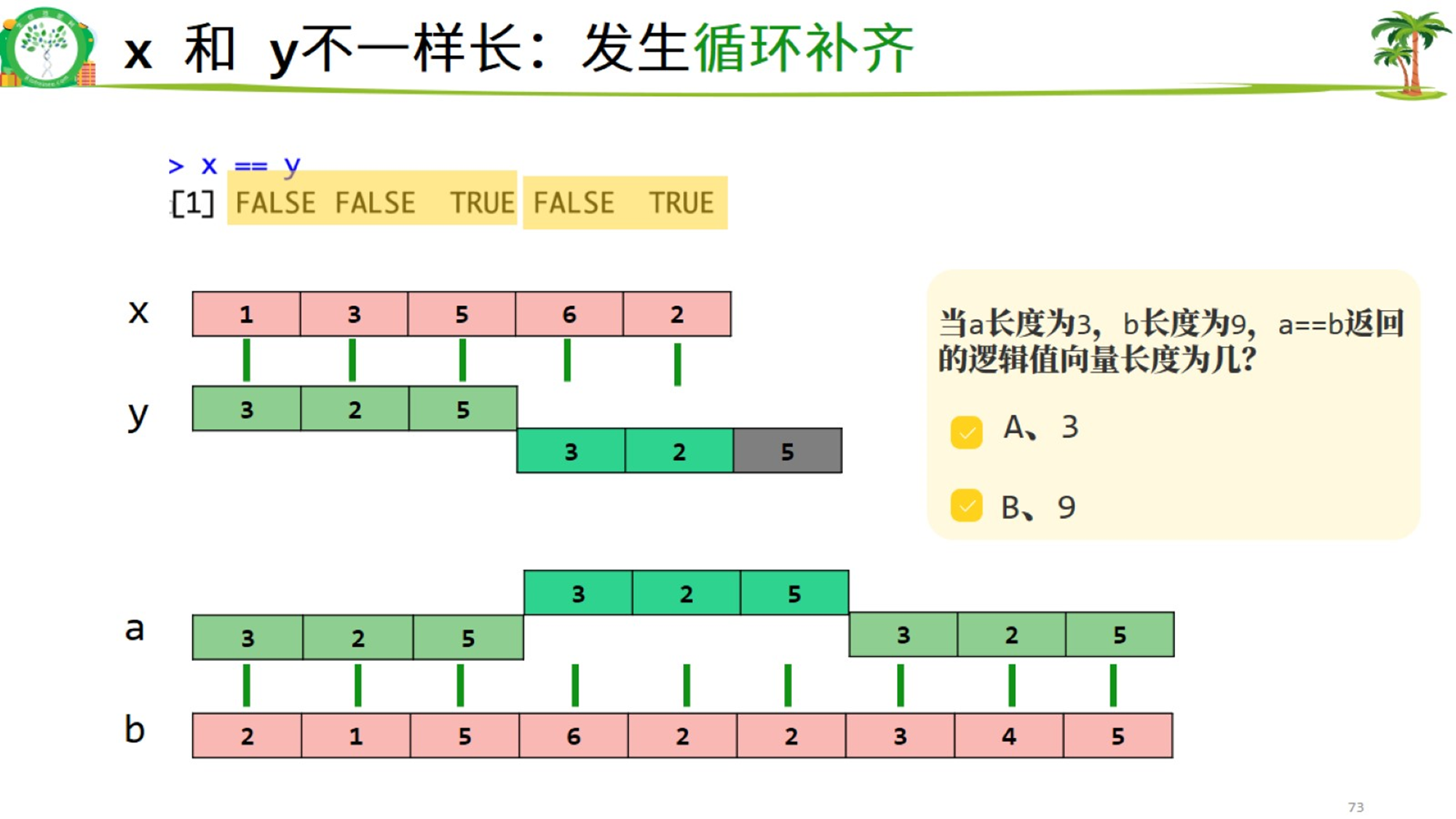
x = c(1,3,5,6,2);x
y = c(3,2,5);y
x == y # 啊!warning!
y == x
[1] 1 3 5 6 2
[1] 3 2 5
> x == y # 啊!warning!
[1] FALSE FALSE TRUE FALSE TRUE
Warning message:
In x == y : longer object length is not a multiple of shorter object length
> y == x
[1] FALSE FALSE TRUE FALSE TRUE
Warning message:
In y == x : longer object length is not a multiple of shorter object length
#输出结果中出现warning,知识强调“较长的对象长度不是较短的对象长度的倍数”,但是并不妨碍比对结果是正确的!!!
#!!!我们不关心warning,只关心error!!!
#!!!warning的信息可不看,因为不会影响结果!!!
# !!!除非后面的代码的发生了错误,这时候可回来看看warning提示的信息是否导致了后面的错误!!!
尝试:较长的对象长度是较短的对象长度的倍数,看输出结果后warning没有了。
x = c(3,6);x
y = c(3,2,5,6);y
x == y
y == x
[1] 3 6
[1] 3 2 5 6
[1] TRUE FALSE FALSE TRUE
[1] TRUE FALSE FALSE TRUE(2) 数学计算:会发生循环补齐
元素数量一致
x = c(1,3,5,1);x
y = c(3,2,5,6);y
x + y #会发生循环补齐
[1] 1 3 5 1
[1] 3 2 5 6
[1] 4 5 10 7元素数量不一致,会发生循环补齐
x = c(1,3);x
y = c(3,2,5,6);y
[1] 1 3
[1] 3 2 5 6
[1] 4 5 6 9(3) 连接:会发生循环补齐
两个向量长度一致
x = c(1,3,5,1);x
y = c(3,2,5,6);y
paste(x,y,sep=",")
[1] 1 3 5
[1] 3 2 5 6
[1] "1,3" "3,2" "5,5" "1,6"paste与paste0的区别:
paste 可将连接的对象添加分隔符(如空格 逗号 斜杆 字母等);
paste0 无缝连接
paste(x,y)
paste0(x,y)
paste(x,y,sep = "") #sep分隔符
paste(x,y,sep = ",")
[1] "1 3" "3 2" "1 5" "3 6"
[1] "13" "32" "15" "36"
[1] "13" "32" "15" "36"
[1] "1,3" "3,2" "1,5" "3,6"两个向量长度不一致:循环补齐
x = c(1,3,5,6,2);x
y = c(3,2,5);y
paste(x,y)
[1] 1 3 5 6 2
[1] 3 2 5
[1] "1 3" "3 2" "5 5" "6 3" "2 2"且利用循环补齐简化代码;参数的名称可以省略
#利用循环补齐简化代码;参数的名称可以省略
paste0(rep("x",times=3),1:3)
paste0(rep("x",3),1:3)
paste0("x",1:3)
[1] "x1" "x2" "x3"
[1] "x1" "x2" "x3"
[1] "x1" "x2" "x3"(4) 交集、并集、差集
x = c(1,3,5,6,2);x
y = c(3,2,5);y
intersect(x,y) #取交集
union(x,y) #去重复
setdiff(x,y) #仅在x存在,不在y中存在的元素
setdiff(y,x) #仅在y存在,不在x中存在的元素
[1] 1 3 5 6 2
[1] 3 2 5
[1] 3 5 2
[1] 1 3 5 6 2
[1] 1 6
> setdiff(y,x) #仅在y存在,不在x中存在的元素
numeric(0)比较:(逻辑值)%in%
x = c(1,3,5,6,2);x
y = c(3,2,5);y
x %in% y #x的每个元素在y中存在吗
y %in% x #y的每个元素在x中存在吗
[1] 1 3 5 6 2
[1] 3 2 5
[1] FALSE TRUE TRUE FALSE TRUE
[1] TRUE TRUE TRUE# x %in% y 和 x==y 的区别
# %in% 是x每一个元素和y的每一个元素逐一比较;当x、y元素的长短不一时,根据x的元素输出相应的逻辑值
# x==y 是x中的每一个元素与y中对应位置的元素相比较;当x、y元素的长短不一时,短元素发生循环补齐,根据长元素的个数输出逻辑值
# !!!有没有发生循环补齐:有没有一长一短,且返回结果和长的向量相等!!!
2.4 向量筛选(取子集)
赋值
x <- 8:12;x
[1] 8 9 10 11 12根据逻辑值取子集
x[x==10]
x[x<12]
x[x %in% c(9,13)]
[1] 10
[1] 8 9 10 11
[1] 9根据位置取子集
x[4]
x[2:4]
x[c(1,5)]
x[-4]
x[-(2:4)]
[1] 11
[1] 9 10 11
[1] 8 12
[1] 8 9 10 12
[1] 8 12#按照逻辑值:中括号里是与x相等且一一对应的逻辑值向量
#按照位置:中括号里是由x的下标组成的向量
2.5.修改向量中的某个/某些元素:取子集+赋值
修改一个元素
x
x[4] <- 40
x
[1] 8 9 10 11 12
[1] 8 9 10 40 12改多个元素
x[c(1,5)] <- c(80,20)
x
[1] 80 9 10 40 202.6 简单向量作图
赋值
k1 = rnorm(12);k1
k2 = rep(c("a","b","c","d"),each = 3);k2
> k1 = rnorm(12);k1
[1] 0.15497991 -0.48102051 -0.06577547 0.26494925
[5] 0.50734937 0.85281476 -0.58299483 -0.60821739
[9] -1.24924050 -0.47403997 -1.50574185 0.56906125
> k2 = rep(c("a","b","c","d"),each = 3);k2
[1] "a" "a" "a" "b" "b" "b" "c" "c" "c" "d" "d" "d"
plot(k1)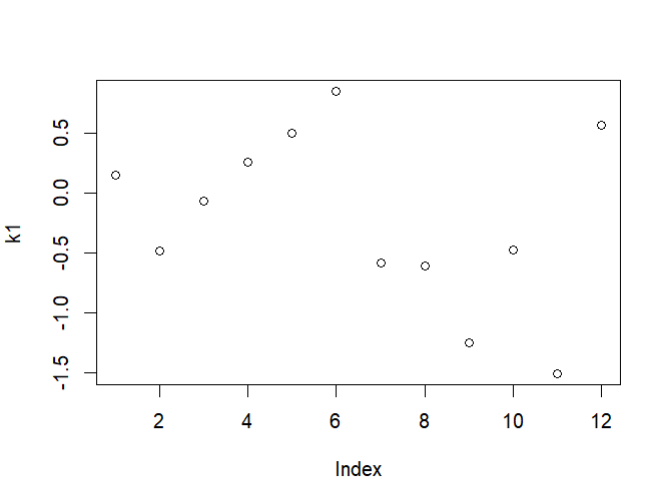
boxplot(k1~k2)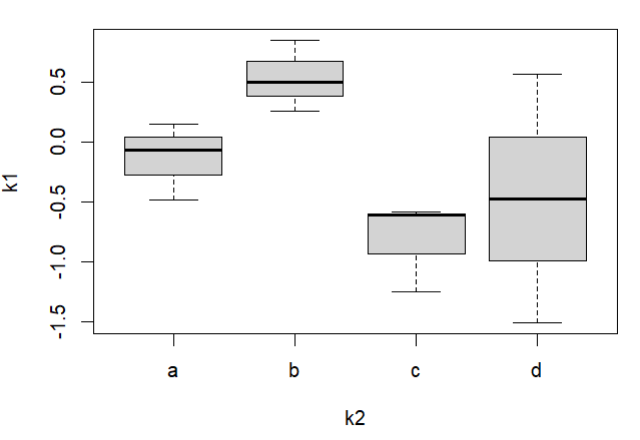
箱线图(Boxplot)也称箱须图(Box-whiskerPlot),它是用一组数据中的最小值、第一四分位数、中位数、第三四分位数和最大值来反映数据分布的中心位置和散布范围,可以粗略地看出数据是否具有对称性。
代码及图片来自生信技能树
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。