RabbitMQ——流控

【概述】
rabbitmq是采用erlang开发的,而erlang开发的程序其内部通常由成千上万个进程组成。每个进程都有自己的邮箱,进程与进程之间通过消息投递来进行通信(发送端将消息投递到接收端进程的邮箱,接收端进程从邮箱中拿到消息进行处理)。
由于erlang默认对邮箱的大小没有限制,这样当接收端进程的消息处理不及时的时候,大量的消息会堆积在邮箱中,最终出现内存溢出导致服务异常 。
在rabbitmq的实现中,为了防止消息发送速度过快,最终因大量消息的堆积导致异常,内部基于credit算法实现了一套流控机制。
【大概原理】
rabbitmq实现的流控机制,原理其实很简单,可总结为下面几点
- 每个发送端都有一个初始的信用值,每向接收端进程发送一个消息,信用值减1,当信用值为0时,发送端变为阻塞状态。
- 每个接收端也有一个初始的信用值,每接收到一个消息时,信用值减1,当信用值减到0时,给对应的发送端进程发送消息增加信用值,同时将信用值重新置为初始值。发送端进程收到接收端增加信用的消息后,在自己的信用上增加对应的值。
- 一个发送端,可以同时向多个接收端发送消息,信用是按不同的接收端分开计算的。同样,一个接收端可以接收来自不同发送端发来的消息,并按不同的发送端分别计算其信用制。
- 接收端也可能同时作为发送端,即多个进程串联在一起,位于中间的进程对于上游而言是接收端,对下游而言是发送端。当对下游而言,作为发送端出现阻塞时,给上游发送端增加信用的消息会被延迟发送。
具体实现中,利用erlang的进程字典保存相关的信息。
在发送端进程字典中存放的信息有:
{credit_from, RecvPID, Credit}:表示还能向接收端进程RecvPID发送Credit条消息。
{credit_blocked, [RecvPID]}:表示发送端进程被哪些接收端进程阻塞了,注意,存放的是一个进程列表。
{credit_blocked_at, Time}:发生阻塞的时间。
在接收端进程字典中存放的信息有:
{credit_to, SenderPID, Credit}:表示还可以接收来自发送端进程Credit条消息,此后需要向这个发送端进程发送消息增加信用值。
{credit_deferred, [{SenderPID, Msg}]}:当该进程被阻塞时,记录需要延迟给哪个发送端进程发送增加信用值的消息;Msg为增加信用的消息。
【rabbitmq中的处理】
在rabbitmq内部,主要有如下几类进程
rabbit_reader:每个tcp连接都有这么一个进程,负责从socket中接收数据,并完成AMQP的解析。
rabbit_channel:每个tcp连接上打开的通道都有这么一个对应的进程,负责处理通道上的请求信令。比如声明exchange,声明queue等
rabbit_amqqueue_process:每个队列都有这么一个进程,负责处理队列的消息。比如生产者投递到队列的消息,消费者的订阅请求,给消费者推送消息等。
rabbit_msg_store:负责所有队列存储方式为msg_store的消息的存储。如果消息的存储方式为queue_index,即消息内容嵌入到索引信息中一并存储,不会用到该进程。
在这些进程之间串成消息流。

对于生产者而言,生产者发送的消息从socket被接收并完成AMQP协议的解析后,发送到通道对应的进程中;通道进程收到消息后,根据路由规则,查找该消息需要路由的所有队列,然后将消息发送给队列对应的进程;队列进程收到消息后,按需将消息发送给消息存储进程完成消息的存储,或直接将消息与索引一并存到索引文件中。
当队列处理消息的速度跟不上生产者消息发送的速度时(比如写文件耗时),队列进程来不及处理的消息将会堆积在进程的邮箱中,同时给通道进程增加信用的速度变慢,到达一定程度后,通道进程就会被阻塞。
当通道进程阻塞时,给网络接收进程增加信用的消息会被暂时存在进程字典中直到通道进程处于非阻塞状态才发送,这样就逐步导致网络接收进程也被阻塞。
网络接收进程每收到一条消息完成协议解析并发送给通道进程后,会判断自身是否处于阻塞状态,如果处于阻塞状态,则不再从socket上接收数据。
最终从rabbitmq的角度来看,暂停接收来自生产者的消息,直到队列进程将邮箱中的消息处理掉,逐步让通道进程,网络接收进程处于非阻塞状态,这个时候才继续接收并处理生产者发送的消息。
这里有几点要说明:
1)由于一个消息可能会被路由到多个队列中,即通道进程可能会向多个队列进程投递消息,只要其中一个队列进程的信用变为0,该通道就会处于阻塞状态;同理:一个连接上可能会打开多个通道,因此网络接收进程会向多个通道进程发送消息,只要其中一个通道进程的信用变为0,网络接收进程也就会变为阻塞状态。
因此这里可以看出来,一个业务同时作为生产者消费者时,最好不要使用一个连接上多个通道的方式,而是将生产者消费者的tcp连接独立开来,避免因生产者被流控导致消费者收到牵连。
2)暂停接收生产者的消息并非意味着生产者发送的消息会失败,这里的暂停仅仅是网络接收进程不从socket的接收缓冲区中拷贝数据到业务层来,而socket上的数据还是在接收的,即生产者仍旧可以发送消息,但这些消息都被接收存放在socket的接收缓冲区中。如果当接收缓冲区的数据达到设置的上限时,会出现tcp的零窗口(zero window),这个时候生产者发送的消息将会失败。
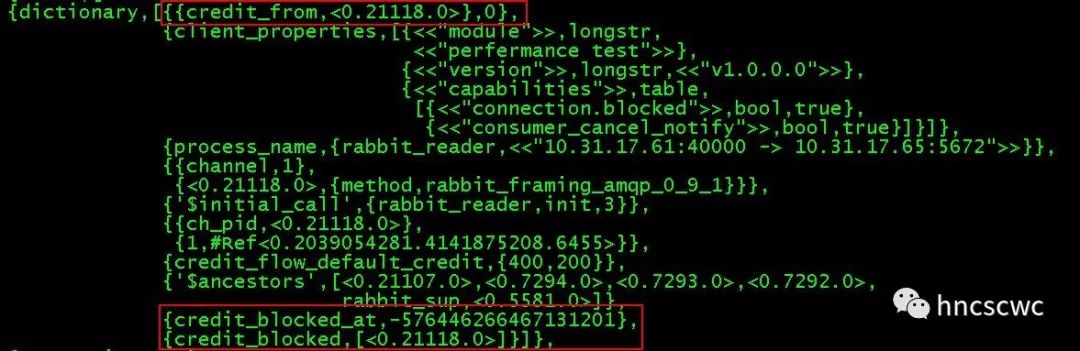
来看一个实际的例子,下面两幅图分别为出现流控时网络接收进程与通道进程对应进程字典的信息。
网络接收进程:
通道进程:
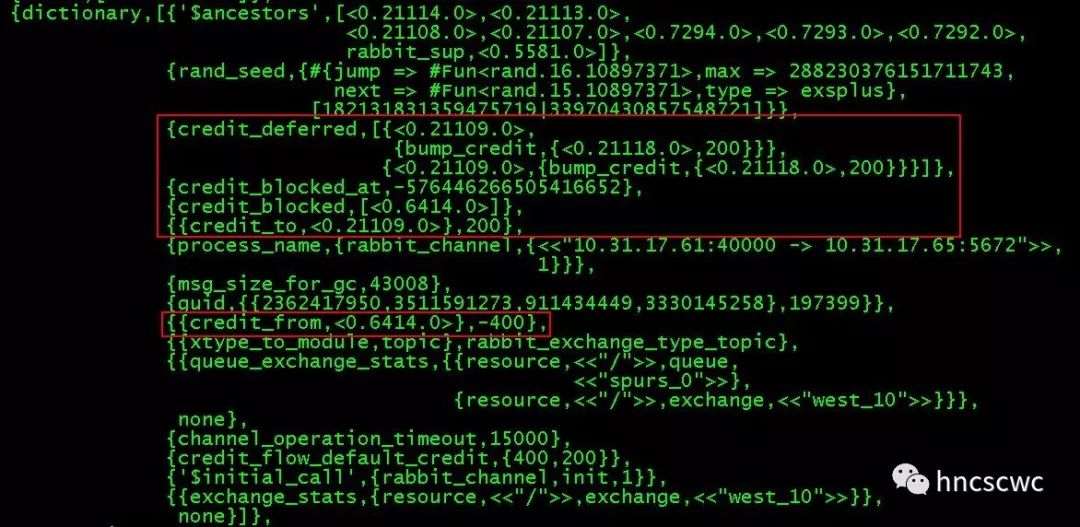
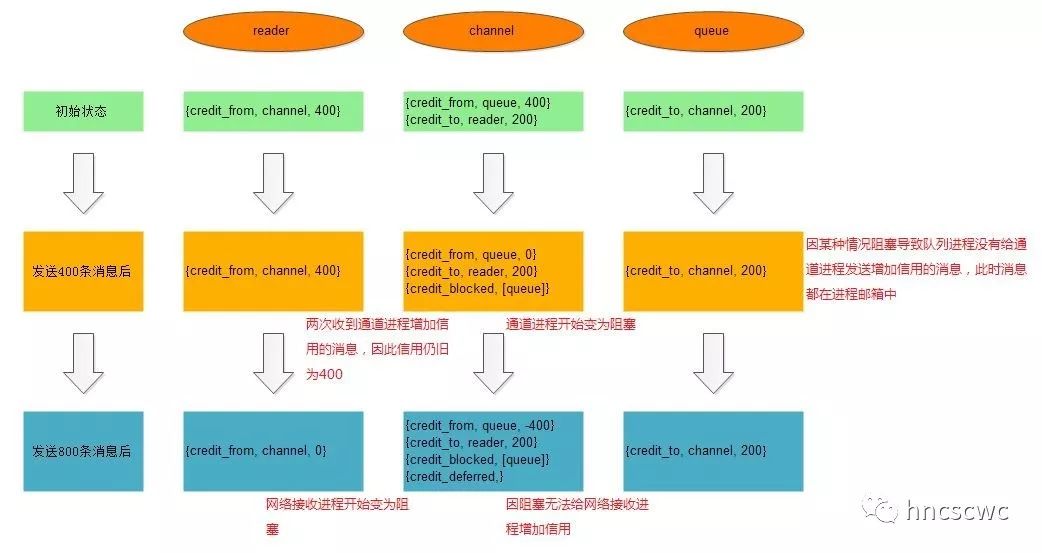
对照前面的分析,都能一一对应起来,但有一点要注意,通道进程中的信用值出现了负数,这个要怎么解释呢?分析了源码后,发现处于阻塞状态的进程仅仅是延迟给上游发送端发送增加信用的消息,对于收到的消息如有需要仍旧会往下游的接收端发送。因此信用为负数的情况可以用下图的场景来解释说明。
【信用的配置】
可通过配置项credit_flow_default_credit进行信用的设置,其默认值为{400,200}。表示发送端初始信用值为400,接收端初始信用为200,即每接收200条消息给发送端增加200的信用。
另外,队列进程和消息存储进程之间的信用是通过msg_store_credit_disk_bound进行配置,其默认值为{4000,800}。
【消费者的流控】
对于生产者的消息发送流程,我们看到了进程间的消息流。而对于消费者的消费流程,实际上也有一个进程间的消息流,在这些进程之间也使用到了信用流控机制,避免因网络发送慢,消息都堆积在网络发送进程中从而出现内存溢出等异常问题。
每个tcp连接建立时,除了有一个用于网络接收的进程外,还有一个用于网络数据发送的进程,消息从队列进程投递到消费者的通道进程,通道进程再将消息发送给网络发送进程。消费者订阅消息到消息发送流程大概如下图所示:
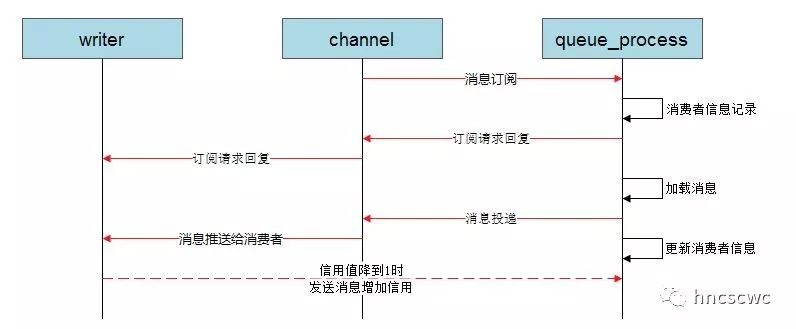
虽然消息推送给消费者经过了队列进程、通道进程和网络发送进程,但信用机制仅作用于队列进程和网络发送进程之间,即这两个进程在进程字典中相互记录了信用的相关信息。另外,消费者信用值是不可配置的,内部采用默认值为{200,50}。
【总结】
本文讲述了基于信用的流控机制的相关原理,以及rabbitmq内部流控逻辑在生产、消费过程中的处理机制。