ElasticSearch客户端调用

1 JavaRestClient
1.1 客户端介绍
在elasticsearch官网中提供了各种语言的客户端:https://www.elastic.co/guide/en/elasticsearch/client/index.html
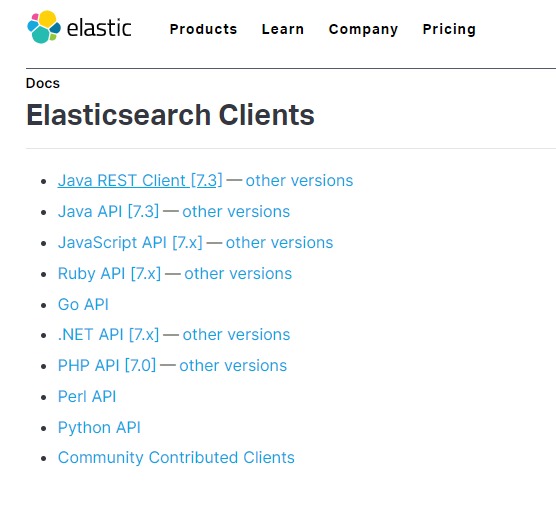
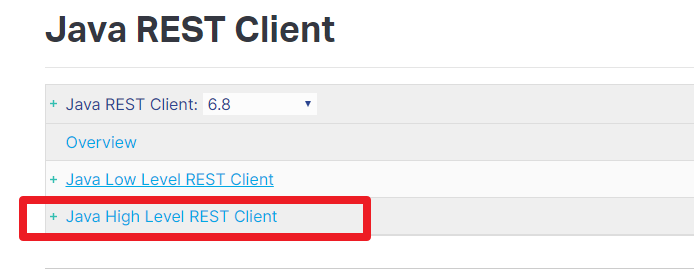
我们JavaRestClient的客户端。注意点击进入后,选择版本到6.8,和我们的es版本对应。
- Low Level Rest Client:是低级别封装,提供一些基础功能,但更灵活
- High Level Rest Client:是在Low Level Rest Client基础上进行的高级别封装,功能更丰富和完善,而且API会变的简单
1.2 创建Demo工程
初始化项目
创建springboot es项目
pom文件添加
<!-- fastjson-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.58</version>
</dependency>
<!-- High-level-Rest-Client-->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>6.8.3</version>
</dependency>
<!-- es 依赖 -->
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>6.8.3</version>
</dependency>1.3 索引库及映射
创建索引库的同时,我们也会创建type及其映射关系,但是这些操作不建议使用java客户端完成,原因如下:
- 索引库和映射往往是初始化时完成,不需要频繁操作,不如提前配置好
- 官方提供的创建索引库及映射API非常繁琐,需要通过字符串拼接json结构:
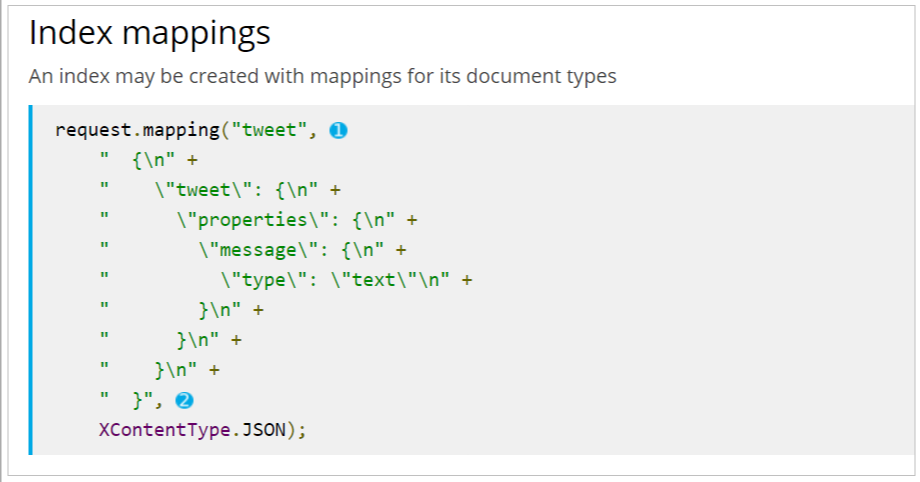
因此,这些操作建议还是使用我Rest风格API去实现。 我们接下来以这样一个商品数据为例来创建索引库:
package cn.itcast.elastic.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Product {
private Long id;
/**
* 标题
*/
private String title;
/**
* 分类
*/
private String category;
/**
* 品牌
*/
private String brand;
/**
* 价格
*/
private Double price;
/**
* 图片地址
*/
private String images;
}分析一下数据结构:
- id:可以认为是主键,将来判断数据是否重复的标示,不分词,可以使用keyword类型
- title:商品标题,搜索字段,需要分词,可以用text类型
- category:商品分类,这个是整体,不分词,可以使用keyword类型
- brand:品牌,与分类类似,不分词,可以使用keyword类型
- price:价格,这个是double类型
- images:图片,用来展示的字段,不搜索,index为false,不分词,可以使用keyword类型
我们可以编写这样的映射配置:
PUT /heima
{
"mappings": {
"product": {
"properties": {
"id": {
"type": "keyword"
},
"title": {
"type": "text",
"analyzer": "ik_max_word"
},
"category": {
"type": "keyword"
},
"brand": {
"type": "keyword"
},
"images": {
"type": "keyword",
"index": false
},
"price": {
"type": "double"
}
}
}
}
}1.4 文档操作
初始化客户端
客户端和es服务器完成任何操作都需要通过RestHighLevelClient对象,我们编写一个测试类,在@Before测试方法初始化该对象,通信完需要关闭RestHighLevelClient对象,我们在@After测试方法关闭:
然后再@Before的方法中编写client初始化:
package cn.itcast.elastic.test;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestClientBuilder;
import org.elasticsearch.client.RestHighLevelClient;
import org.junit.After;
import org.junit.Before;
/**
* 测试es增删改API
*/
public class TestES01 {
private RestHighLevelClient restHighLevelClient;
/**
* 在@Before方法初始化restHighLevelClient对象
*/
@Before
public void initClient() {
client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("192.168.129.139", 9200, "http")));
}
/**
*在@After方法中关闭restHighLevelClient对象
*/
@After
public void closeClient() {
if (null != client) {
try {
client.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}新增文档
新增时,如果传递的id是已经存在的,则会完成修改操作,如果不存在,则是新增。 流程:
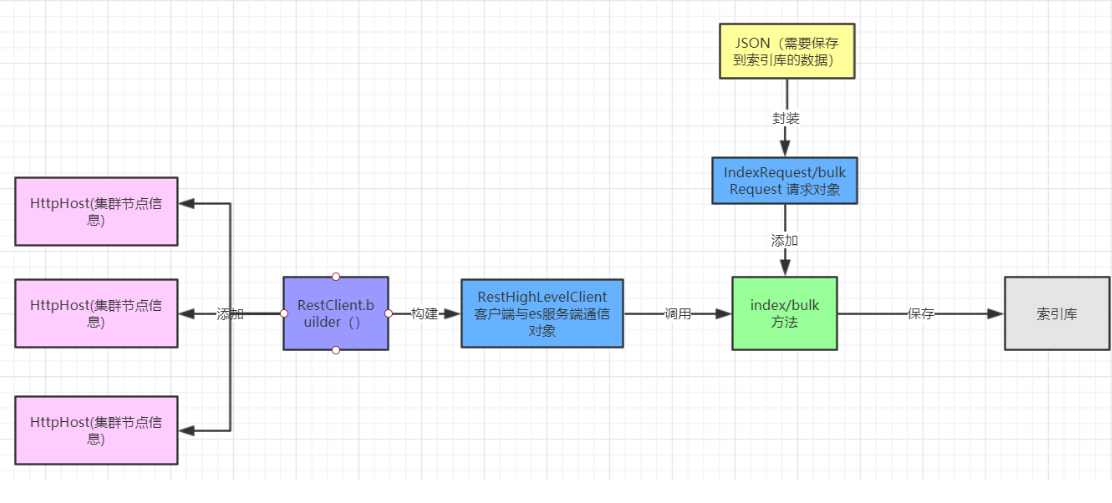
步骤:
- 准备需要保存到索引库的json文档数据
- 创建IndexRequest请求对象,指定索引库、类型、id(可选)
- 调用source方法将请求数据封装到IndexRequest请求对象中
- 调用方法进行数据通信
- 解析输出结果
代码实现:
@Test
public void addDoc() {
//1.准备需要保存到索引库的json文档数据
Product product = new Product(1l, "小米手机", "手机", "小米",
2899.00, "http://www.baidu.com");
//将对象转为json字符串
String jsonString = JSON.toJSONString(product);
//2.创建请求对象,指定索引库、类型、id(可选)
IndexRequest indexRequest = new IndexRequest("heima", "product", "1");
//3.调用source方法将请求数据封装到IndexRequest请求对象中
indexRequest.source(jsonString, XContentType.JSON);
try {
//4.调用方法进行数据通信
IndexResponse indexResponse = client.index(indexRequest, RequestOptions.DEFAULT);
//5.解析输出结果
System.out.println("结果: " + JSON.toJSONString(indexResponse));
} catch (IOException e) {
e.printStackTrace();
}
}响应结果,成功:

查看文档
刚刚我们保存了一条数据进行,接下来我们根据rest风格,根据id进行get查询。 相关类:
- GetRquest:封装get请求参数
- GetResponse:封装get数据响应
流程:
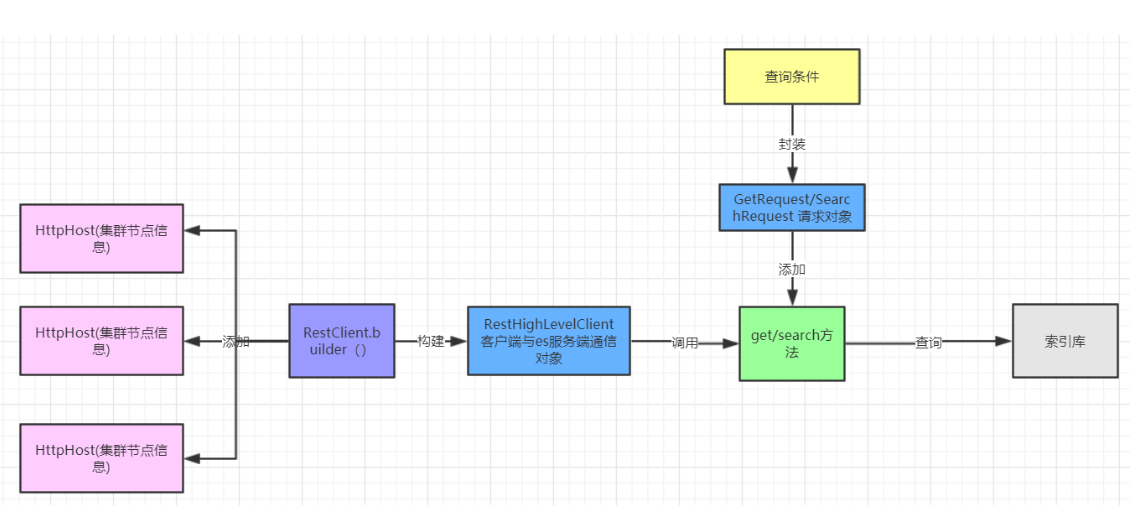
步骤:
- 构建GetRequest请求对象,指定索引库、类型、id
- 调用方法进行数据通信
- 解析输出结果
代码实现:
@Test
public void getDocById() {
//1.构建GetRequest请求对象,指定索引库、类型、id
GetRequest getRequest = new GetRequest("heima", "product", "1");
try {
//2.调用方法进行数据通信
GetResponse getResponse = client.get(getRequest, RequestOptions.DEFAULT);
//3.解析输出结果
System.out.println("结果: " + JSON.toJSONString(getResponse));
} catch (IOException e) {
e.printStackTrace();
}
}结果:

批量新增
当需要新增的数据较多时,单个新增比较耗费性能,所以这时候批量新增功能就比较好用了。
流程图如单个新增一样。
步骤:
- 构建批量新增BulkRequest请求对象
- 准备需要保存到索引库的json文档数据封装到IndexRequest请求对象中
- 添加IndexRequest请求对象至批量新增BulkRequest请求对象
- 调用方法进行数据通信
代码实现:
@Test
public void bulkAddDoc() {
//1.构建批量新增BulkRequest请求对象
BulkRequest bulkRequest = new BulkRequest();
//2.准备需要保存到索引库的json文档数据封装到IndexRequest请求对象中
for (long i = 2; i < 9; i++) {
//2.1准备需要保存到索引库的json文档数据
Product product = new Product(i, "小米手机" + i, "手机", "小米",
2899.00 + i, "http://www.baidu.com");
String jsonString = JSON.toJSONString(product);
//2.2创建请求对象,指定索引库、类型、id(可选)
IndexRequest indexRequest = new IndexRequest("heima", "product", "" + i);
//2.3将请求数据封装到IndexRequest请求对象中
indexRequest.source(jsonString, XContentType.JSON);
//3.添加IndexRequest请求对象至批量新增BulkRequest请求对象
bulkRequest.add(indexRequest);
}
try {
//4.调用方法进行数据通信
client.bulk(bulkRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
e.printStackTrace();
}
}通过kibana查询所有:
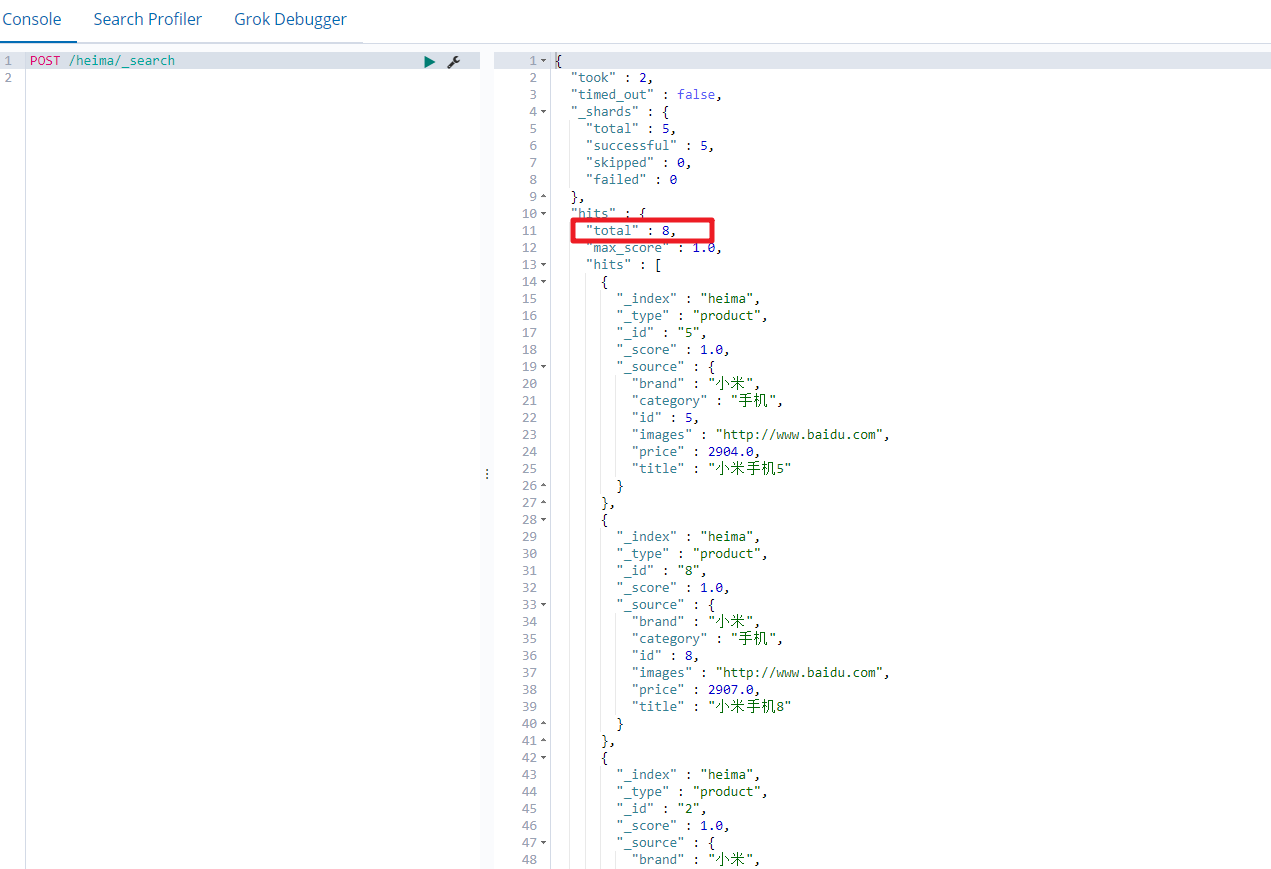
关键点:
- BulkRequest:批量请求,可以添加多个IndexRequest对象,完成批处理
修改文档
restAPI只提供了按文档id进行修改的操作。 流程:
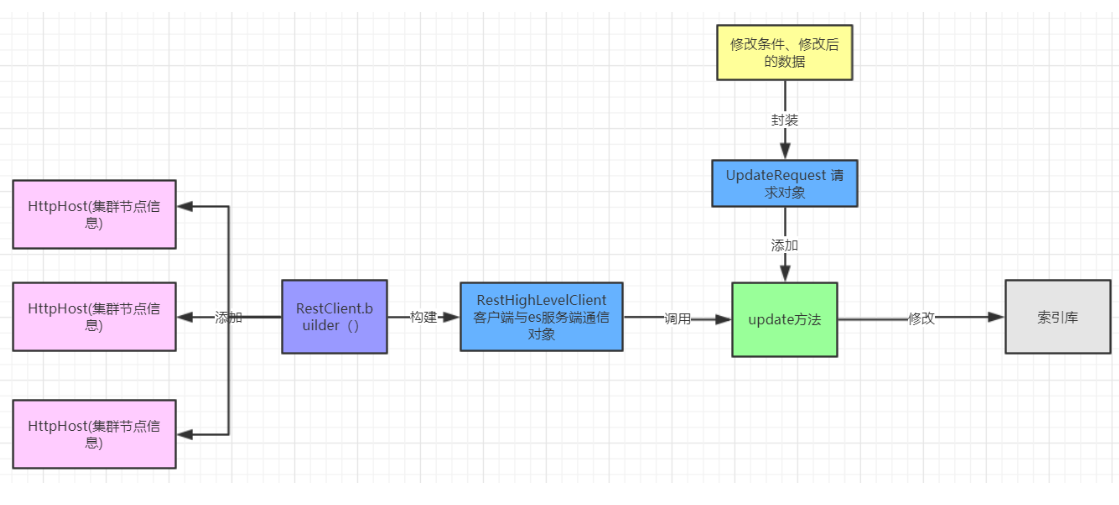
步骤:
- 构建修改请求对象,指定索引库、类型、id
- 准备需要修改的json文档数据
- 将需要修改的json文档数据封装到UpdateRequest请求对象中
- 调用方法进行数据通信
- 解析输出结果
代码实现:
@Test
public void updataDocById() {
//1.构建修改请求对象,指定索引库、类型、id
UpdateRequest updateRequest = new UpdateRequest("heima", "product", "1");
//2.准备需要修改的json文档数据
Product product = new Product(1l, "大米手机", "手机", "大米",
2899.00, "http://www.baidu.com");
String jsonString = JSON.toJSONString(product);
//3.将需要修改的json文档数据封装到IndexRequest请求对象中
updateRequest.doc(jsonString, XContentType.JSON);
try {
//4.调用方法进行数据通信
UpdateResponse updateResponse = client.update(updateRequest, RequestOptions.DEFAULT);
//5.解析输出结果
System.out.println("结果: " + JSON.toJSONString(updateResponse));
} catch (IOException e) {
e.printStackTrace();
}
}结果:

删除文档
resetApi只提供了根据id删除。 步骤:
- 构建删除请求对象,指定索引库、类型、id
- 调用方法进行数据通信
- 解析输出结果
代码实现:
@Test
public void delDocById() {
try {
//1.构建删除请求对象,指定索引库、类型、id
DeleteRequest deleteRequest = new DeleteRequest("heima", "product", "2");
//2.调用方法进行数据通信
DeleteResponse deleteResponse = client.delete(deleteRequest, RequestOptions.DEFAULT);
//3.解析输出结果
System.out.println("结果" + JSON.toJSONString(deleteResponse));
} catch (IOException e) {
e.printStackTrace();
}
}结果:


1.5 搜索数据
搜索流程:
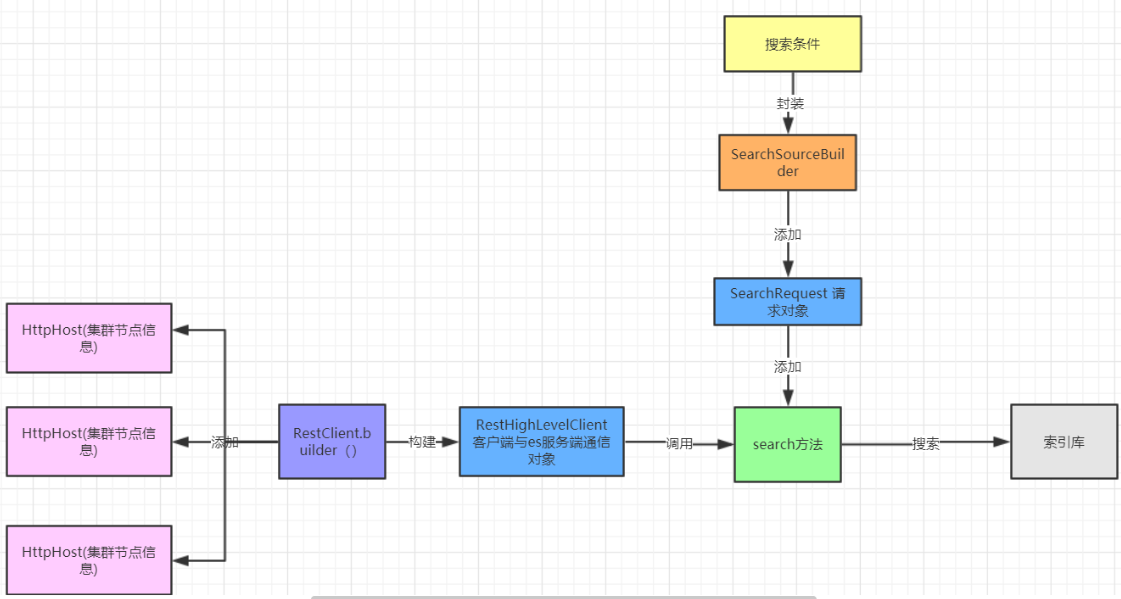
关键字搜索match
- SearchRequest:封装搜索请求
- SearchSourceBuilder:指定查询类型、排序、高亮等,后面几乎所有的操作都需要该类参与
- QueryBuilders:用来构建各种查询类型和查询条件
步骤:
- 构建SearchRequest请求对象,指定索引库
- 构建SearchSourceBuilder查询对象
- 构建QueryBuilder对象指定查询方式和查询条件
- 将QueryBuilder对象设置到SearchSourceBuilder中
- 将SearchSourceBuilder查询对象封装到请求对象SearchRequest中
- 调用方法进行数据通信
- 解析输出结果
代码实现:
@Test
public void matchDoc() {
//1.构建SearchRequest请求对象,指定索引库
SearchRequest searchRequest = new SearchRequest("heima");
//2.构建SearchSourceBuilder查询对象
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//3.构建QueryBuilder对象指定查询方式和查询条件
QueryBuilder queryBuilder = QueryBuilders.matchQuery("title", "大米");
//4.将QueryBuilder对象设置到SearchSourceBuilder中
sourceBuilder.query(queryBuilder);
//5.将SearchSourceBuilder对象封装到请求对象SearchRequest中
searchRequest.source(sourceBuilder);
try {
//6.调用方法进行数据通信
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
//7.解析输出结果
SearchHit[] hits = searchResponse.getHits().getHits();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
System.out.println("结果: " + sourceAsString);
}
} catch (IOException e) {
e.printStackTrace();
}
}结果:

注意,上面的代码中,搜索条件是通过sourceBuilder.query(QueryBuilders.matchAllQuery())来添加的。这个query()方法接受的参数是:QueryBuilder接口类型。
这个接口提供了很多实现类,分别对应我们在之前中学习的不同类型的查询,例如:term查询、match查询、range查询、boolean查询等,我们如果要使用各种不同查询,其实仅仅是传递给sourceBuilder.query()方法的参数不同而已。而这些实现类不需要我们去new,官方提供了QueryBuilders工厂帮我们构建各种实现类:
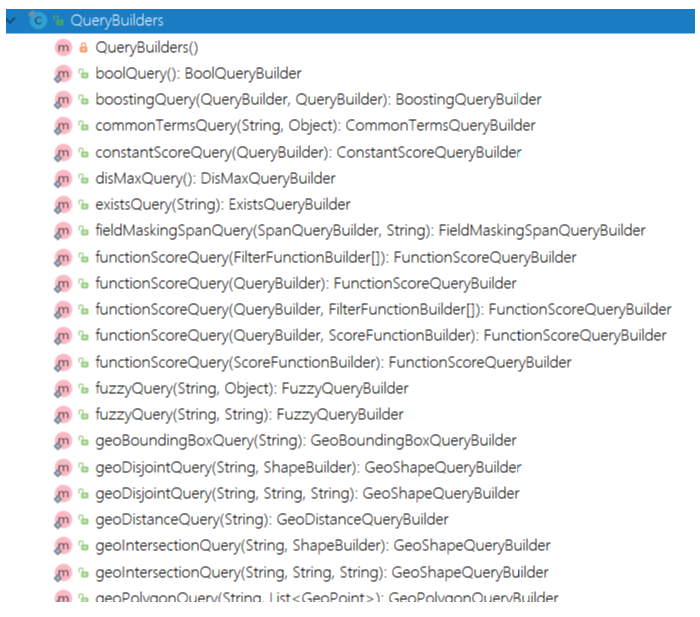
查询所有match_all
步骤:
- 构建SearchRequest请求对象,指定索引库
- 构建SearchSourceBuilder查询对象
- 构建QueryBuilder对象指定查询方式
- 将QueryBuilder对象设置到SearchSourceBuilder中
- 将SearchSourceBuilder查询对象封装到请求对象SearchRequest中
- 调用方法进行数据通信
- .解析输出结果
代码实现:
@Test
public void matchAllDoc() {
//1.构建SearchRequest请求对象,指定索引库
SearchRequest searchRequest = new SearchRequest("heima");
//2.构建SearchSourceBuilder查询对象
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//3.构建QueryBuilder对象指定查询方式
QueryBuilder queryBuilder = QueryBuilders.matchAllQuery();
//4.将QueryBuilder对象设置到SearchSourceBuilder中
sourceBuilder.query(queryBuilder);
//5.将SearchSourceBuilder查询对象封装到请求对象SearchRequest中
searchRequest.source(sourceBuilder);
try {
//6.调用方法进行数据通信
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
//7.解析输出结果
SearchHit[] hits = searchResponse.getHits().getHits();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
System.out.println("结果: " + sourceAsString);
}
} catch (IOException e) {
e.printStackTrace();
}
}结果:

其实搜索类型的变化,仅仅是利用QueryBuilders构建的查询对象不同而已,其他代码基本一致。因此,我们可以把这段代码封装,然后把查询条件作为参数传递:
private void commonSearch(QueryBuilder queryBuilder) {
//1.构建SearchRequest请求对象,指定索引库
SearchRequest searchRequest = new SearchRequest("heima");
//2.构建SearchSourceBuilder查询对象
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//4.将QueryBuilder对象设置到SearchSourceBuilder中
sourceBuilder.query(queryBuilder);
//5.将SearchSourceBuilder查询对象封装到请求对象SearchRequest中
searchRequest.source(sourceBuilder);
try {
//6.调用方法进行数据通信
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
//7.解析输出结果
SearchHit[] hits = searchResponse.getHits().getHits();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
System.out.println("结果: " + sourceAsString);
}
} catch (IOException e) {
e.printStackTrace();
}
} source过滤
默认情况下,索引库中所有字段都会返回,如果我们想只返回部分字段,可以通过source filter来控制。
private void commonSearch(QueryBuilder queryBuilder) {
//1.构建SearchRequest请求对象,指定索引库
SearchRequest searchRequest = new SearchRequest("heima");
//2.构建SearchSourceBuilder查询对象
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//4.将QueryBuilder对象设置到SearchSourceBuilder中
sourceBuilder.query(queryBuilder);
//使用fetchSource实现过滤
sourceBuilder.fetchSource(new String[]{"id","title","prict"},null);
//5.将SearchSourceBuilder查询对象封装到请求对象SearchRequest中
searchRequest.source(sourceBuilder);
try {
//6.调用方法进行数据通信
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
//7.解析输出结果
SearchHit[] hits = searchResponse.getHits().getHits();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
System.out.println("结果: " + sourceAsString);
}
} catch (IOException e) {
e.printStackTrace();
}
}结果:
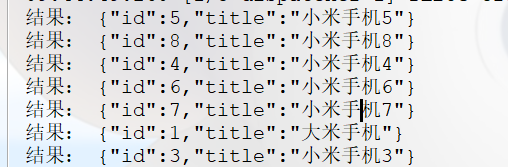
1.6 排序
依然是通过sourceBuilder来配置 代码:
private void commonSearch(QueryBuilder queryBuilder) {
//1.构建SearchRequest请求对象,指定索引库
SearchRequest searchRequest = new SearchRequest("heima");
//2.构建SearchSourceBuilder查询对象
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//4.将QueryBuilder对象设置到SearchSourceBuilder中
sourceBuilder.query(queryBuilder);
/*
* 通过sort方法指定排序规则
* 第一个参数:排序字段
* 第二个参数:升序还是降序(可以不填写,默认升序)
*/
sourceBuilder.sort("id", SortOrder.DESC);
sourceBuilder.sort("price",SortOrder.DESC);
//5.将SearchSourceBuilder查询对象封装到请求对象SearchRequest中
searchRequest.source(sourceBuilder);
try {
//6.调用方法进行数据通信
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
//7.解析输出结果
SearchHit[] hits = searchResponse.getHits().getHits();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
System.out.println("结果: " + sourceAsString);
}
} catch (IOException e) {
e.printStackTrace();
}
}结果:

备注:默认不能使用text类型的字段进行排序。不然那会报错
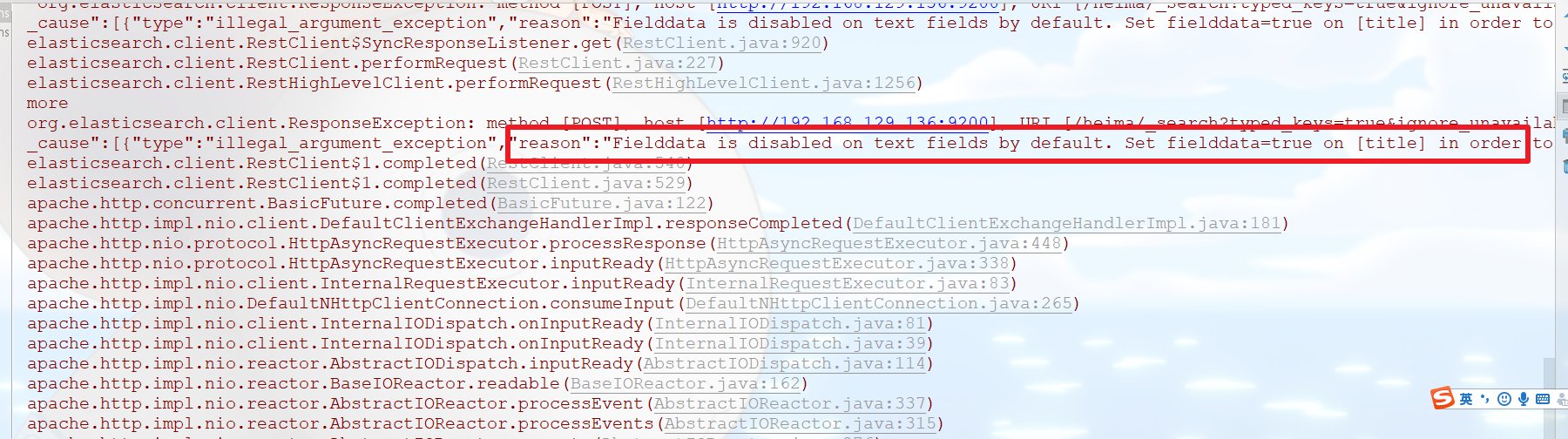
官网说明:

解决方法:将需要进行排序的text类型的字段,设置fielddata=true即可。
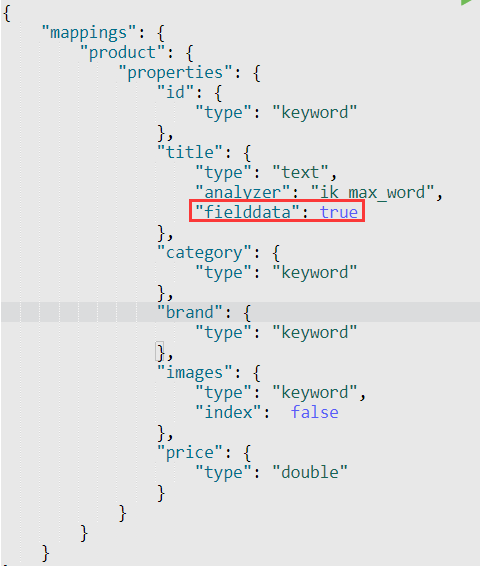
1.7 分页
- from:当前页起始索引, int from= (pageNum - 1) * size;
- size:每页显示多少条
代码:
private void commonSearch(QueryBuilder queryBuilder) {
//1.构建SearchRequest请求对象,指定索引库
SearchRequest searchRequest = new SearchRequest("heima");
//2.构建SearchSourceBuilder查询对象
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//4.将QueryBuilder对象设置到SearchSourceBuilder中
sourceBuilder.query(queryBuilder);
/*
* 通过sort方法指定排序规则
* 第一个参数:排序字段
* 第二个参数:升序还是降序(可以不填写,默认升序)
*/
sourceBuilder.sort("id", SortOrder.DESC);
sourceBuilder.sort("price",SortOrder.DESC);
/*
- from:当前页起始索引, int from= (pageNum - 1) * size;
- size:每页显示多少条
*/
sourceBuilder.from(0);
sourceBuilder.size(4);
//5.将SearchSourceBuilder查询对象封装到请求对象SearchRequest中
searchRequest.source(sourceBuilder);
try {
//6.调用方法进行数据通信
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
//7.解析输出结果
SearchHit[] hits = searchResponse.getHits().getHits();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
System.out.println("结果: " + sourceAsString);
}
} catch (IOException e) {
e.printStackTrace();
}
}page=1,结果:

page=2,结果:

1.8 高亮
高亮就是对匹配的内容里的关键词通过html+css进行加颜色处理显示。 步骤:
- 构建HighlightBuilder高亮对象
- 设置要高亮的字段
- 设置高亮样式
- 高亮对象highlightBuilder设置到sourceBuilder中
代码示例:
@Test
public void highLightMatch() {
//1.构建QueryBuilder对象指定查询方式
QueryBuilder queryBuilder = QueryBuilders.matchQuery("title", "小米");
//2.构建SearchRequest请求对象,指定索引库
SearchRequest searchRequest = new SearchRequest("heima");
//3.构建SearchSourceBuilder查询对象
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//4.将QueryBuilder对象设置到SearchSourceBuilder中
sourceBuilder.query(queryBuilder);
//5构建HighlightBuilder高亮对象
HighlightBuilder highlightBuilder = new HighlightBuilder();
//5.1设置要高亮的字段
highlightBuilder.field("title");
//5.2设置高亮样式
highlightBuilder.preTags("<font color='pink' >");
highlightBuilder.postTags("</font>");
//6.将高亮对象highlightBuilder设置到sourceBuilder中
sourceBuilder.highlighter(highlightBuilder);
//7.将SearchSourceBuilder查询对象封装到请求对象SearchRequest中
searchRequest.source(sourceBuilder);
try {
//6.调用方法进行数据通信
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
//7.解析输出结果
SearchHit[] hits = searchResponse.getHits().getHits();
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
System.out.println("结果: " + sourceAsString);
//获取高亮结果
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
HighlightField title = highlightFields.get("title");
Text[] fragments = title.getFragments();
for (Text fragment : fragments) {
System.err.println("高亮结果: " + fragment.toString());
}
}
} catch (IOException e) {
e.printStackTrace();
}
}关键代码:
- 查询条件中添加高亮字段:

new HighlightBuilder():创建高亮构建器.field("title"):指定高亮字段.preTags("")和.postTags(""):指定高亮的前置和后置标签
- 解析高亮结果:

结果:

2 SpringDataElasticsearch
2.1 Spring Data ElasticSearch简介
什么是Spring Data
Spring Data是一个用于简化数据访问,并支持云服务的开源框架。其主要目标是使得对数据的访问变得方便快捷。 Spring Data可以极大的简化数据操作的写法,可以在几乎不用写实现的情况下,实现对数据的访问和操作。除了CRUD外,还包括如分页、排序等一些常用的功能。例如spring-boot-starter-data-redis对应的redisTemplate。 查看 Spring Data的官网:https://spring.io/projects/spring-data。
什么是SpringDataES
SpringDataElasticsearch(以后简称SDE)是Spring Data项目下的一个子模块,是Spring提供的操作ElasticSearch的数据层,封装了大量的基础操作,通过它可以很方便的操作ElasticSearch的数据。

Spring Data 的使命是给各种数据访问提供统一的编程接口,不管是关系型数据库(如MySQL),还是非关系数据库(如Redis),或者类似Elasticsearch这样的索引数据库。从而简化开发人员的代码,提高开发效率。 包含很多不同数据操作的模块:

Spring Data Elasticsearch的页面:https://projects.spring.io/spring-data-elasticsearch/
特征:
- 支持Spring的基于
@Configuration的java配置方式,或者XML配置方式 - 提供了用于操作ES的便捷工具类
ElasticsearchTemplate。包括实现文档到POJO之间的自动智能映射。 - 利用Spring的数据转换服务实现的功能丰富的对象映射。
- 基于注解的元数据映射方式,而且可扩展以支持更多不同的数据格式。
- 根据持久层接口自动生成对应实现方法,无需人工编写基本操作代码(类似mybatis,根据接口自动得到实现)。当然,也支持人工定制查询。
2.2 创建spring data es工程
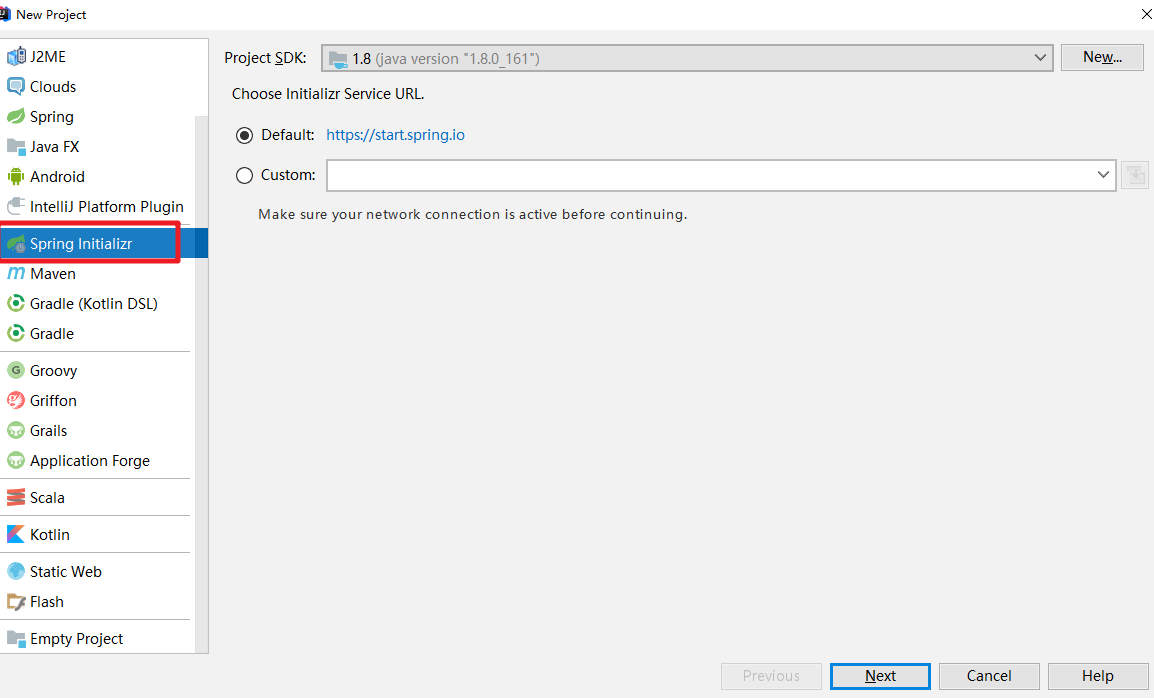
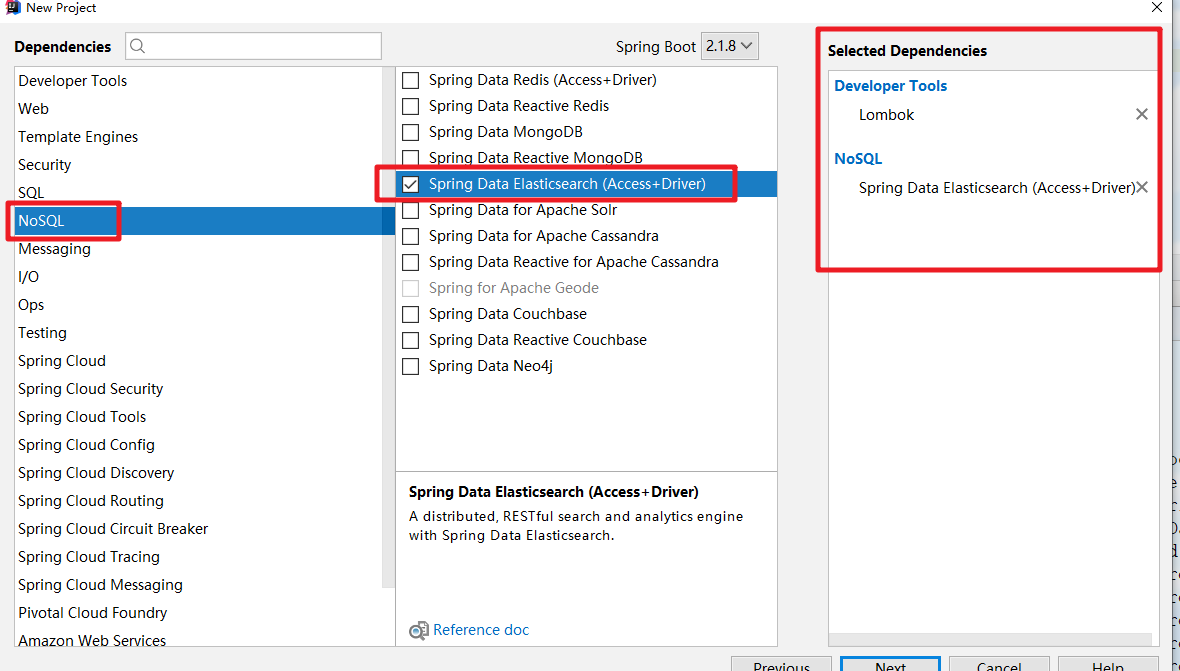
在application.yml文件中引入elasticsearch的host和port即可:
spring:
data:
elasticsearch:
cluster-name: elasticsearch #es集群名称
cluster-nodes: 127.0.0.1:9300 #准备连接的es节点tcp地址
#集群配置:192.168.129.139:9301,192.168.129.139:9302,192.168.129.139:9303需要注意的是,SpringDataElasticsearch底层使用的不是Elasticsearch提供的RestHighLevelClient,而是TransportClient,并不采用Http协议通信,而是访问elasticsearch对外开放的tcp端口,ElasticSearch默认tcp端口。 另外,SpringBoot已经帮我们配置好了各种SDE配置,并且注册了一个ElasticsearchTemplate供我们使用。
2.3 创建索引库和映射
新建实体类Goods,作为与索引库对应的文档,通过实体类上的注解来配置索引库信息的,比如:索引库名、类型名、分片、副本数量、还有映射信息:
/**
* 与索引库对应的文档实体类型。
*/
@Data
@AllArgsConstructor
@NoArgsConstructor
//集群时可以设置 : shards:分片数量(默认值:5),replicas:副本数量(默认值:1)
@Document(indexName = "goods",type = "goods")
public class Goods {
/*
必须有id,这里的id是全局唯一的标识,等同于es中的“_id”
*/
@Id
private Long id;
/**
* 标题
* type: 字段数据类型
* analyzer: 分词器类型
* index: 是否索引(默认值:true)
* store: 是否存储(默认值:false)
*/
@Field(type = FieldType.Text,analyzer = "ik_max_word")
private String title;
/**
* 分类
*/
@Field(type = FieldType.Keyword)
private String category;
/**
* 品牌
*/
@Field(type = FieldType.Keyword)
private String brand;
/**
* 价格
*/
@Field(type = FieldType.Double)
private Double price;
/**
* 图片地址
*/
@Field(type = FieldType.Keyword,index = false)
private String images;
}几个用到的注解:
- @Document:声明索引库配置
- indexName:索引库名称
- type:类型名称,默认是“docs”
- shards:分片数量,默认5
- replicas:副本数量,默认1
- @Id:声明实体类的id
- @Field:声明字段属性
- type:字段的数据类型
- analyzer:指定分词器类型
- index:是否创建索引 默认为true
- store:是否存储 默认为false
创建索引库的API示例: ElasticsearchTemplate:可以用来操作复杂的es
//spring data es模板工具
@Autowired
private ElasticsearchTemplate template;
@Test
public void testCreateIndex() {
boolean createIndex = template.createIndex(Goods.class);
System.out.println("创建索引库是否成功 : " + createIndex);
boolean putMapping = template.putMapping(Goods.class);
System.out.println("创建映射是否成功 : " + putMapping);
}结果:

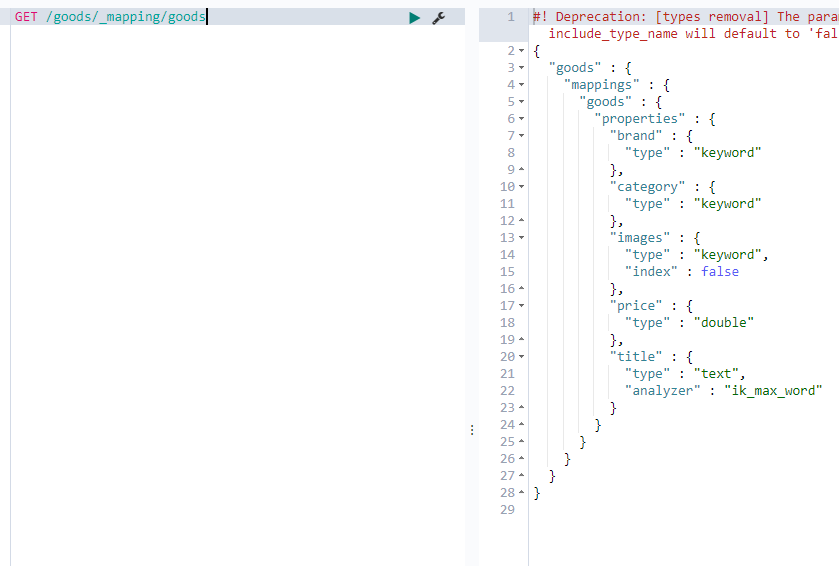
kibana查看创建结果:
2.4 删除索引
@Test
public void deleteIndex() {
//根据对象删除
boolean deleteIndex = template.deleteIndex(Goods.class);
//根据索引名称删除
//boolean goods = template.deleteIndex("goods");
System.out.println("删除是否成功: " + deleteIndex);
}2.5 使用ElasticsearchRepository对数据CRUD
SDE的文档索引数据CRUD并没有封装在ElasticsearchTemplate中,而是有一个叫做ElasticsearchRepository的接口:
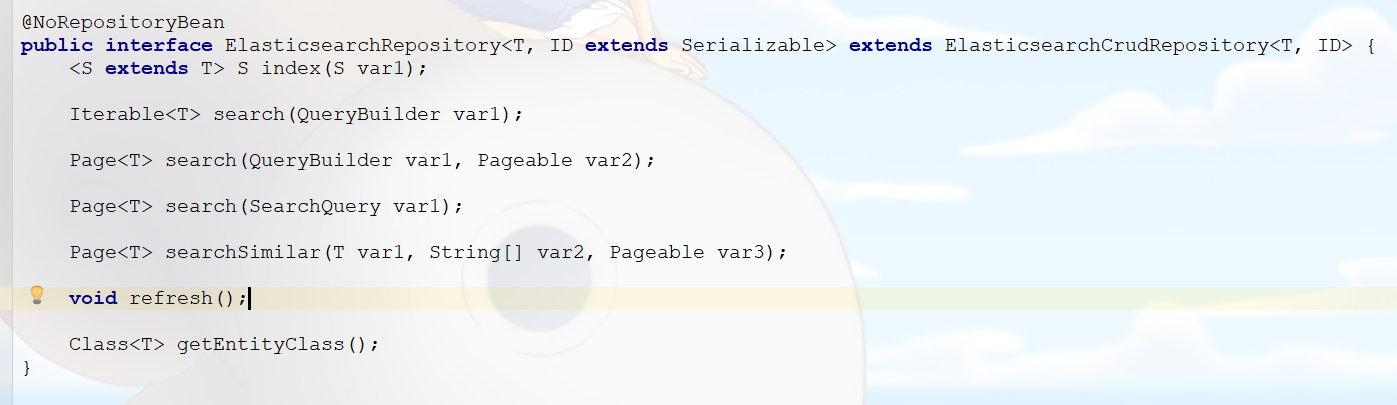
我们需要自定义接口,继承ElasticsearchRespository:
import com.itheima.dao.Goods;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
public interface GoodsRepository extends ElasticsearchRepository<Goods,Long> {
}创建文档数据
创建索引有单个创建和批量创建之分,如果文档已经存在则执行更新操作。 单个创建:
- 创建新增文档对象
- 调用goods仓库保存方法
//goods索引操作仓库
@Autowired
private GoodsRepository goodsRepository;
/**
* @Author: guodong
* @Date: 15:32 2019/9/27
* @Description: 添加文档: 不存在就新增,存在就更新
*/
@Test
public void addDoc(){
//1.创建新增文档对象
Goods goods = new Goods(1l, "小米手机", "手机", "小米",
19999.00, "http://www.baidu.com");
//2.调用goods仓库保存
goodsRepository.save(goods);
}批量创建:
- 创建新增文档对象添加至list中
- 调用goods仓库批量保存方法
@Test
public void batchAddDoc() {
//1.创建新增文档对象添加至list中
List<Goods> goodsList = new ArrayList<>();
for (long i = 2; i < 10; i++) {
Goods goods = new Goods(i, "小米手机" + i, "手机", "小米",
19999.00 + i, "http://www.baidu.com");
goodsList.add(goods);
}
//2.调用goods仓库批量保存方法
goodsRepository.saveAll(goodsList);
} 通过kibana查看:
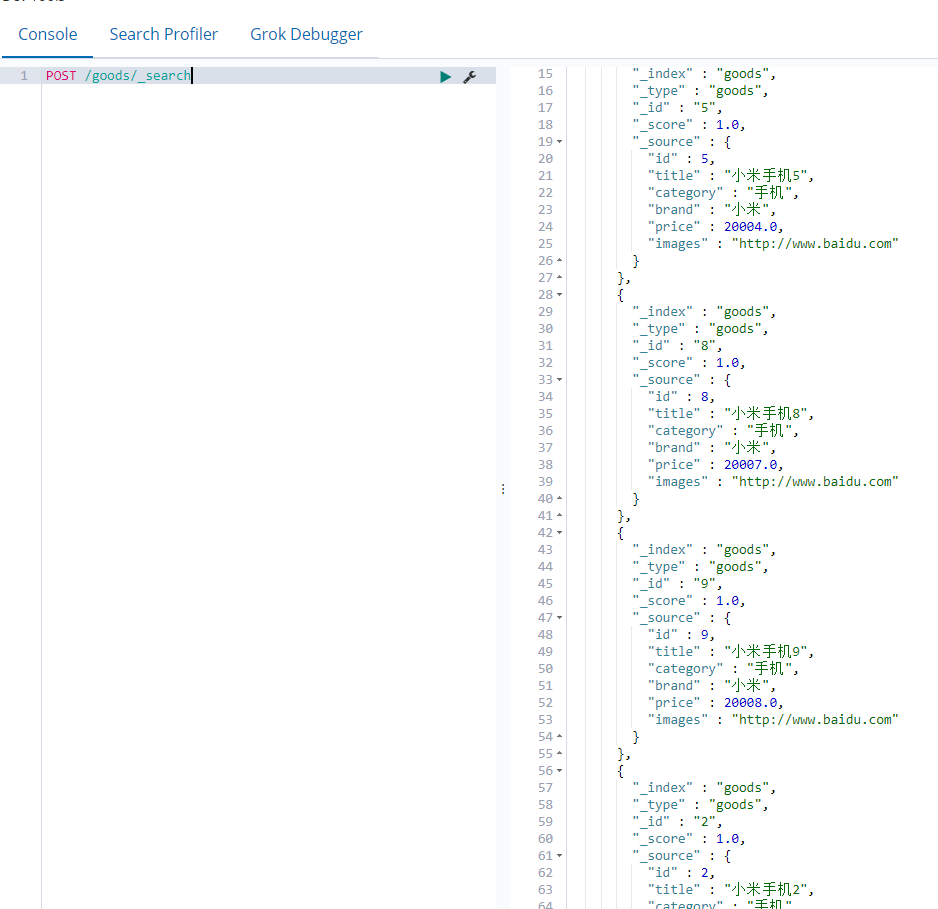
查询文档数据
默认提供了根据id查询,查询所有两个功能:
根据id查询
- 调用goods仓库根据id查询
- 判断返回的Optional对象中是否有值
- 从Optional对象中获取查询结果
@Test
public void findDocById() {
//1.调用goods仓库根据id查询
Optional<Goods> optional = goodsRepository.findById(1L);
//2.判断返回的Optional对象中是否有值
if (optional.isPresent()) {//有值
//3.从Optional对象中获取查询结果
Goods goods = optional.get();
System.out.println("结果: " + goods);
}
}结果:
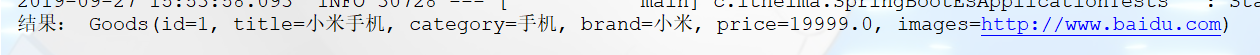
查询所有
@Test
public void findAllDoc() {
//1.调用goods仓库查询所有
Iterable<Goods> all = goodsRepository.findAll();
//2.遍历打印输出查询结果
for (Goods goods : all) {
System.out.println("结果 : " + goods);
}
}结果:
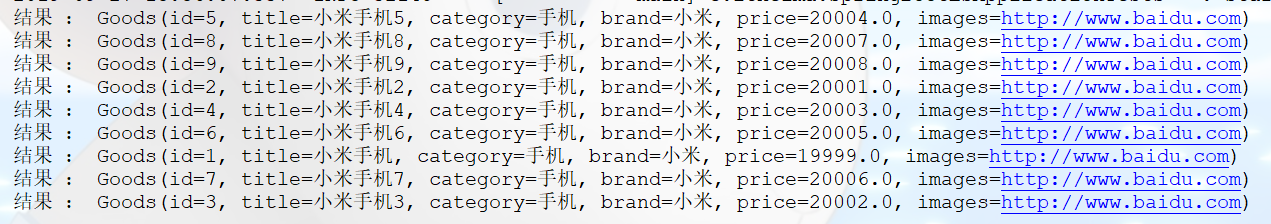
使用search查询
- 构建QueryBuilder对象设置查询类型和查询条件
- 调用goods仓库search方法进行查询
- 遍历打印输出查询结果
@Test
public void search(){
//1.构建QueryBuilder对象设置查询类型和查询条件
QueryBuilder queryBuilder = QueryBuilders.termQuery("title", "大米");
//2.调用goods仓库search方法进行查询
Iterable<Goods> iterable = goodsRepository.search(queryBuilder);
//3.遍历打印输出查询结果
for (Goods goods : iterable) {
System.out.println("结果: " + goods);
}
}使用search查询并分页排序
- 构建Sort排序对象,指定排序字段和排序方式
- 使用PageRequest构建Pageable分页对象,指定分页参数,并将排序对象设置到分页对象中
- 调用goods仓库search方法进行查询
- 解析结果
/**
* @Description: search查询并实现分页、排序
*/
@Test
public void pageSortQuery() {
//1.构建排序对象,指定排序字段和排序方式
Sort sort = new Sort(Sort.Direction.ASC, "id");
//2.构建分页对象,指定分页参数,并将排序对象设置到分页对象中
Pageable pageable = PageRequest.of(0, 2,sort);
//3.调用goods仓库search方法进行查询
Page<Goods> page = goodsRepository.search(QueryBuilders.matchQuery("title", "小米"), pageable);
//4.解析结果
//4.1获取总记录数
long totalElements = page.getTotalElements();
System.out.println("totalElements: " + totalElements);
//4.2获取总页数
int totalPages = page.getTotalPages();
System.out.println("totalPages: " + totalPages);
//4.3遍历查询结果
for (Goods goods : page) {
System.out.println("结果 : " + goods);
}
}自定义方法查询
GoodsRepository提供的查询方法有限,但是它却提供了非常强大的自定义查询功能;只要遵循SpringData提供的语法,我们可以任意定义方法声明:
public interface GoodsRepository extends ElasticsearchRepository<Goods,Long> {
/**
* @Description: 根据价格范围查询 from:开始价格 to 结束价格
*/
List<Goods> findByPriceBetween(Double from, Double to);
}无需写实现,SDE会自动帮我们实现该方法,我们只需调用即可:
/**
* @Description: 自定义仓库查询方法:根据价格范围查找
*/
@Test
public void findGoodsByPriceRang(){
//1.调用仓库自定义方法findByPriceBetween
List<Goods> byPriceBetween = goodsRepository.findByPriceBetween(19999.0, 20006.0);
//2.遍历输出结果
for (Goods goods : byPriceBetween) {
System.out.println(goods);
}
}结果:

支持的一些语法示例:findGoods By Price Between 语法:findBy+字段名+Keyword+字段名+….
Keyword | Sample | Elasticsearch Query String |
|---|---|---|
And | findByNameAndPrice | {"bool" : {"must" : [ {"field" : {"name" : "?"}}, {"field" : {"price" : "?"}} ]}} |
Or | findByNameOrPrice | {"bool" : {"should" : [ {"field" : {"name" : "?"}}, {"field" : {"price" : "?"}} ]}} |
Is | findByName | {"bool" : {"must" : {"field" : {"name" : "?"}}}} |
Not | findByNameNot | {"bool" : {"must_not" : {"field" : {"name" : "?"}}}} |
Between | findByPriceBetween | {"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : ?,"include_lower" : true,"include_upper" : true}}}}} |
Before | findByPriceBefore | {"bool" : {"must" : {"range" : {"price" : {"from" : null,"to" : ?,"include_lower" : true,"include_upper" : true}}}}} |
After | findByPriceAfter | {"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : null,"include_lower" : true,"include_upper" : true}}}}} |
Like | findByNameLike | {"bool" : {"must" : {"field" : {"name" : {"query" : "?*","analyze_wildcard" : true}}}}} |
StartingWith | findByNameStartingWith | {"bool" : {"must" : {"field" : {"name" : {"query" : "?*","analyze_wildcard" : true}}}}} |
EndingWith | findByNameEndingWith | {"bool" : {"must" : {"field" : {"name" : {"query" : "*?","analyze_wildcard" : true}}}}} |
In | findByNameIn(Collection<String>names) | {"bool" : {"must" : {"bool" : {"should" : [ {"field" : {"name" : "?"}}, {"field" : {"name" : "?"}} ]}}}} |
NotIn | findByNameNotIn(Collection<String>names) | {"bool" : {"must_not" : {"bool" : {"should" : {"field" : {"name" : "?"}}}}}} |
OrderBy | findByNameOrderByNameDesc | {"sort" : [{ "name" : {"order" : "desc"} }],"bool" : {"must" : {"field" : {"name" : "?"}}} |
2.6 使用ElasticsearchTemplate查询
SDE也支持使用ElasticsearchTemplate进行原生查询。
而查询条件的构建是通过一个名为NativeSearchQueryBuilder的类来完成的,不过这个类的底层还是使用的原生API中的QueryBuilders、HighlightBuilders等工具。
分页和排序
可以通过NativeSearchQueryBuilder类来构建分页和排序、聚合等操作
queryBuilder.withQuery() //设置查询类型和查询条件
queryBuilder.withPageable() //设置分页
queryBuilder.withSort()//设置排序步骤:
- 构建NativeSearchQueryBuilder查询对象
- 使用QueryBuilders指定查询类型和查询条件
- 使用SortBuilders指定排序字段和排序方式
- 使用PageRequest对象指定分页参数
- 调用NativeSearchQueryBuilder的build方法完成构建
- 使用ElasticsearchTemplate完成查询
- 解析结果
代码示例:
/**
* @Description: 使用ElasticsearchTemplate完成分页排序查询
*/
@Test
public void nativeSearchQuery(){
//1.构建NativeSearchQueryBuilder查询对象
NativeSearchQueryBuilder searchQueryBuilder = new NativeSearchQueryBuilder();
//2.使用QueryBuilders指定查询类型和查询条件
searchQueryBuilder.withQuery(QueryBuilders.matchQuery("title","小米"));
//3.使用SortBuilders指定排序字段和排序方式
searchQueryBuilder.withSort(SortBuilders.fieldSort("id").order(SortOrder.DESC));
//4.使用PageRequest对象指定分页参数
searchQueryBuilder.withPageable(PageRequest.of(0,2));
//5.调用NativeSearchQueryBuilder的build方法完成构建
NativeSearchQuery searchQuery = searchQueryBuilder.build();
//6.使用ElasticsearchTemplate完成查询
AggregatedPage<Goods> page = template.queryForPage(searchQuery, Goods.class);
//7.解析结果
//7.1获取总记录数
long totalElements = page.getTotalElements();
System.out.println("totalElements: " + totalElements);
//7.2获取页总数
int totalPages = page.getTotalPages();
System.out.println("totalPages: " + totalPages);
//7.3遍历查询结果
for (Goods goods : page) {
System.out.println("结果 : " + goods);
}
}