每日一问_02_使用Pandas做简单的数据处理分析
每日一问_02_使用Pandas做简单的数据处理分析

老表
发布于 2023-09-09 09:52:50
发布于 2023-09-09 09:52:50

图片来自@AIGC
推荐:一本书精通3D科研绘图与学术图表绘制的核心技术!
公众号:简说Python 今日每日一题
问题: 请写出一个 Python 代码,使用 pandas 库读取一个 CSV 文件,然后进行数据清洗和分析。
提示: 假设 CSV 文件内容如下:
姓名,年龄,性别,身高,体重
张三,25,男,175,70
李四,30,男,180,75
王五,28,女,165,55
赵六,35,男,170,80
考察点: pandas 库的基本操作、数据清洗、数据分析基础
问题分析和解答
问题分析:
- 首先,我们需要使用 pandas 库来读取 CSV 文件。
- 接下来,进行数据清洗,例如处理缺失值、重复值等。
- 然后,可以进行一些简单的数据分析,比如计算平均年龄、身高等。
实战应用场景分析:这种任务常见于数据处理和分析领域。通过 pandas 库可以方便地加载、处理和分析结构化数据,适用于各种数据集的清洗和分析工作。
解答代码:
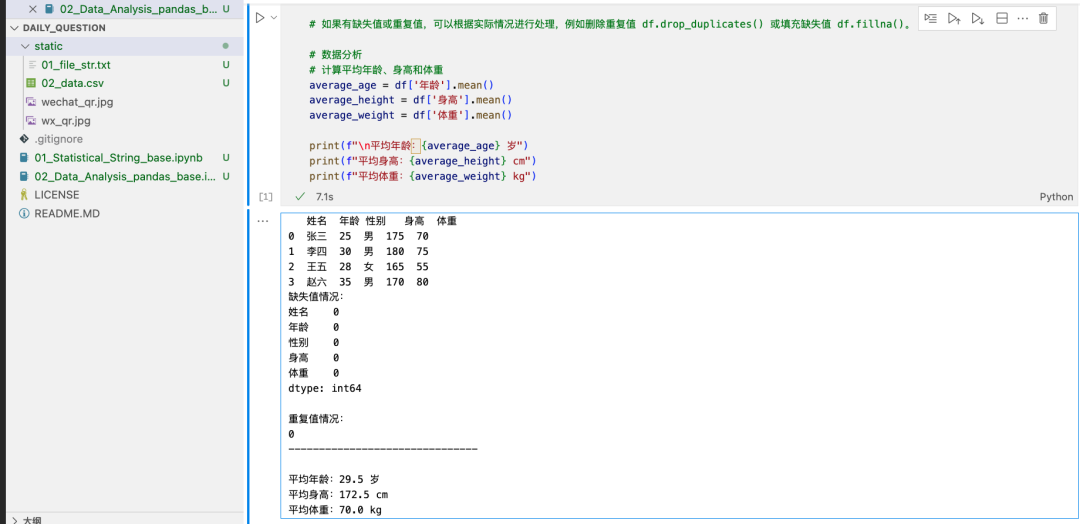
import pandas as pd
# 读取CSV文件
df = pd.read_csv('./static/02_data.csv')
# 查看数据的前几行
print(df.head())
# 数据清洗
# 1. 检查缺失值
print("缺失值情况:")
print(df.isnull().sum())
# 2. 检查重复值
print("\n重复值情况:")
print(df.duplicated().sum())
print("-------------------------------")
# 如果有缺失值或重复值,可以根据实际情况进行处理,例如删除重复值 df.drop_duplicates() 或填充缺失值 df.fillna()。
# 数据分析
# 计算平均年龄、身高和体重
average_age = df['年龄'].mean()
average_height = df['身高'].mean()
average_weight = df['体重'].mean()
print(f"\n平均年龄:{average_age} 岁")
print(f"平均身高:{average_height} cm")
print(f"平均体重:{average_weight} kg")
代码解析:
- 首先,导入了pandas库并将其简称为
pd。 - 使用
pd.read_csv()方法读取名为'data.csv'的CSV文件,并将数据存储在DataFrame对象df中。 - 通过
df.head()查看了数据的前几行,以便了解数据的结构和内容。 - 进行数据清洗,首先检查了是否有缺失值和重复值,并输出了相应的统计信息。
- 如果有缺失值或重复值,可以使用相应的方法进行处理,如删除重复值
df.drop_duplicates()或填充缺失值df.fillna()。 - 最后,进行了一些简单的数据分析,计算了平均年龄、身高和体重,并将结果输出。
拓展分享:这个例子展示了如何使用pandas库进行数据的读取、清洗和分析。
在实际工作中,你可能会面对更复杂的数据处理任务,需要使用pandas提供的更多功能和方法来处理不同类型的数据。
同时,还可以结合其他库如 matplotlib、seaborn 等进行数据可视化,以更直观地了解数据的特征和趋势。
群友分享解答
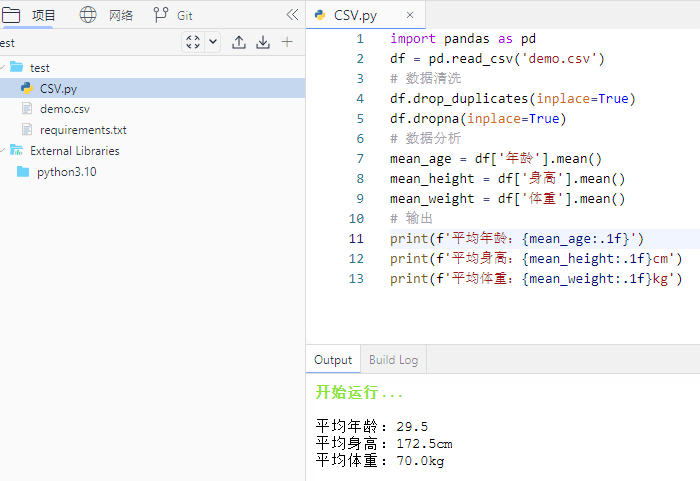
- 张大胖
- 冷月🇻
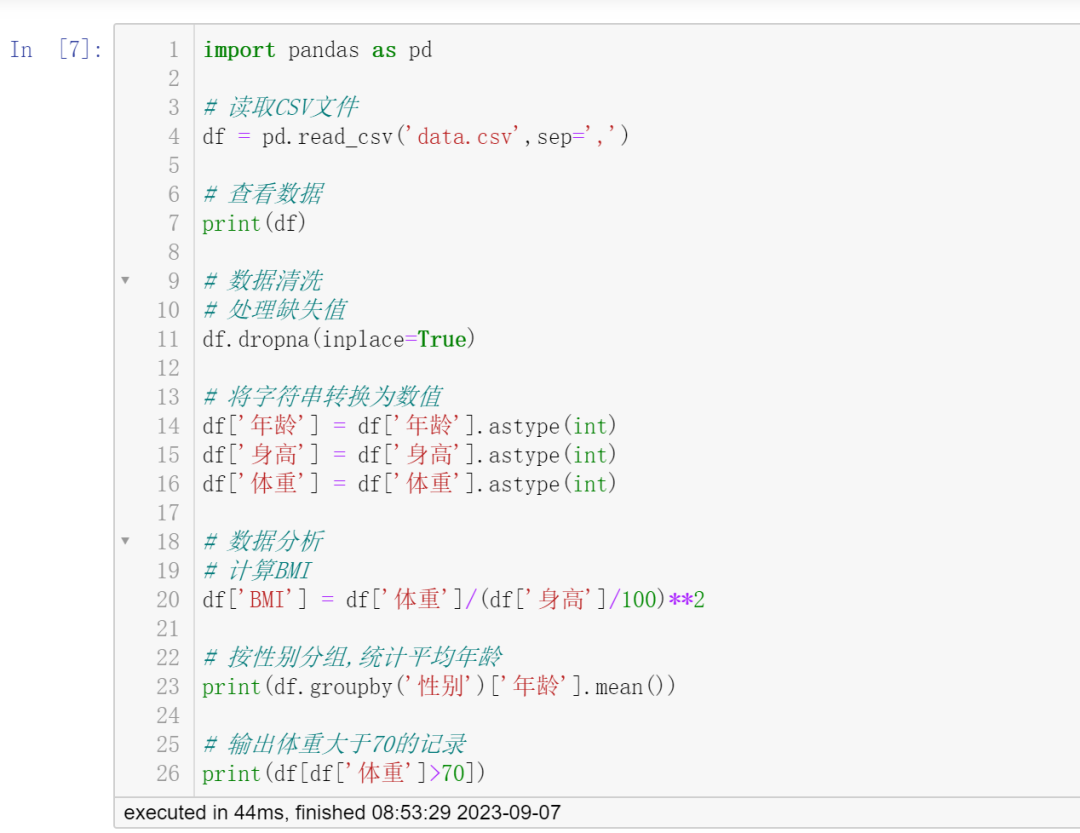
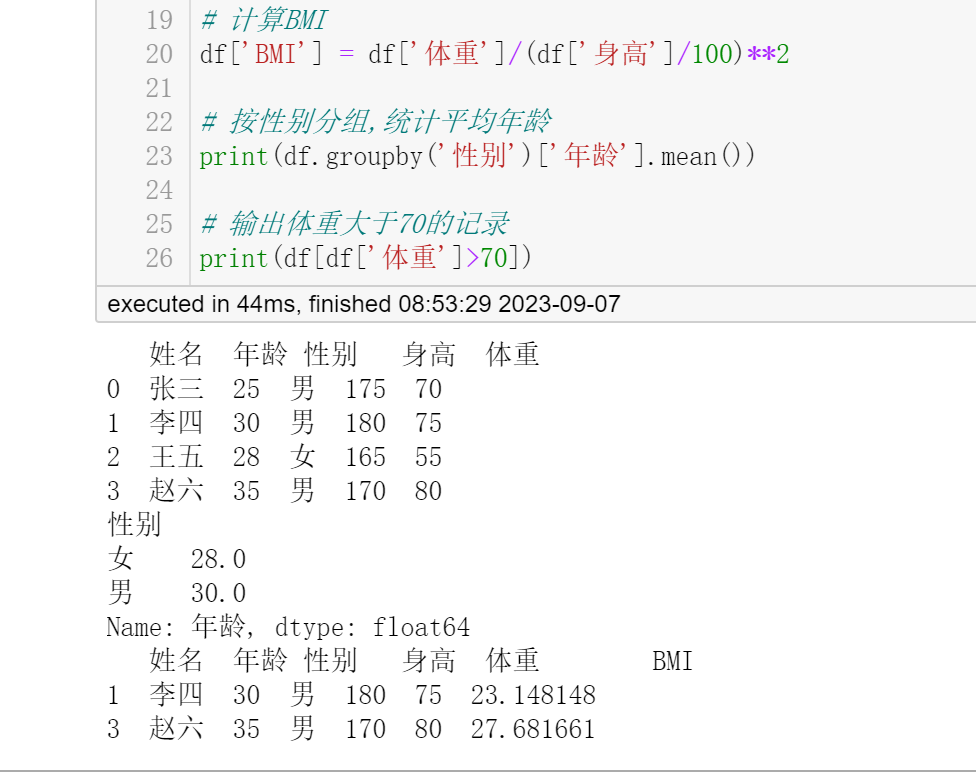
- 南风

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-09-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
相关产品与服务
数据保险箱
数据保险箱(Cloud Data Coffer Service,CDCS)为您提供更高安全系数的企业核心数据存储服务。您可以通过自定义过期天数的方法删除数据,避免误删带来的损害,还可以将数据跨地域存储,防止一些不可抗因素导致的数据丢失。数据保险箱支持通过控制台、API 等多样化方式快速简单接入,实现海量数据的存储管理。您可以使用数据保险箱对文件数据进行上传、下载,最终实现数据的安全存储和提取。