MySQL索引

索引分类
- 单值索引:即一个索引只包含单个列,一个表可以有多个单列索引。
- 唯一索引:索引列的值必须唯一,但允许有空值。(主键列不允许有空值)
- 复合索引:即一个索引包含多个列。
primary 主键 唯一且不能为空 index或Key 普通索引 对特殊最经常出现的数据列创建该索引(唯一任务是加快对数据的访问速度) unique 唯一索引 不允许有重复 fulltext 全文索引 用于一篇"文章"中,检索文本信息
创建索引
create 索引 index 索引名称 on 表名(字段名); 举例: create index idx_city_name on city(city_name); 创建普通索引 create unique index city_unique on city(cid); 创建唯一索引
查看索引
show index from 表名;
删除索引
drop index 索引名称 on 表名;
创建复合索引
create 索引 索引名称 on 表名(字段名,字段名......); 举例:create index idx_name_email_status on tb_seller(name,email,status); 相当于对name创建索引, 对name,email创建了索引, 对name,email,status创建了索引。 最左原则解释: 比如:创建的复合索引字段为(a,b,c),那么支持索引查找的组合为(a|a,b|a,c|a,b,c),不支持b|c|b,c这样组合查找。如果弄乱了顺序如 c,b,a,mysql也会自动帮你改为a,b,c。这就是mysql最左原则,查询条件里面要有复合索引最左边的那个字段才会用到索引。
全文索引
只有字段的数据类型为char、varchar、text及其系列才可以创建全文索引。
概念:如果希望通过关键字的匹配来进行查询过滤,那么就需要基于相似度的查询,而不是原来的精确数值比较。全文索引就是为这种场景设计的。 like+% 模糊查询在文本较少时是合适的,但是对于大量的文本数据检索,是不可想象的。全文索引在大量的数据面前,能比like + %快N倍,速度不是一个量级,但是全文索引可能存在精度问题。
show variables like '%ft%'; 查看全文索引的信息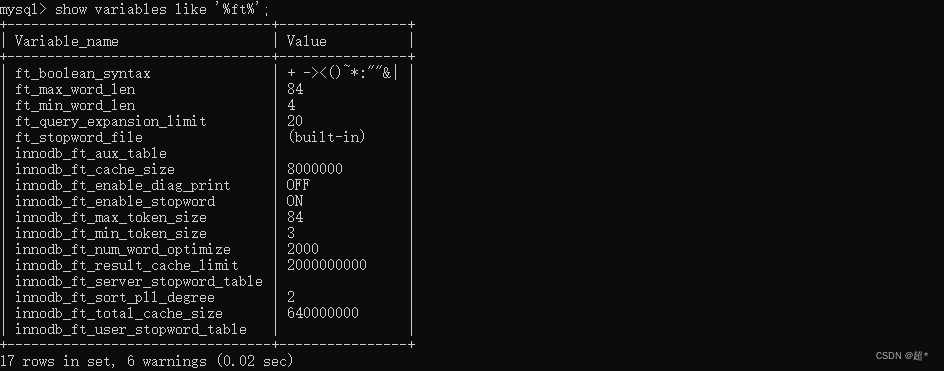
参数 | 描述 |
|---|---|
ft_boolean_syntax | 全文索引分词关键字,不能更改,为内置变量(比如:a+aaa 切成a、aaa) |
ft_max_word_len | 针对MyISAM引擎的,也就是你创建的全文索引的字段的内容最大长度 |
ft_min_word_len | 针对MyISAM引擎的,也就是你创建的全文索引的字段的内容最小长度 |
innodb_ft_max_token_size | 针对Innodb引擎的,也就是你创建的全文索引的字段的内容最大长度 |
innodb_ft_min_token_size | 针对Innodb引擎的,也就是你创建的全文索引的字段的内容最小长度 |
如上图,也就是说你的MyISAM引擎的全文索引字段的内容分词长度只有在4~84的时候,你的全文索引才会有效。你的Innodb引擎的全文索引字段的内容分词长度必须在3~84之间才会有效。
如何修改以上参数的值? 1)找到mysql配置文件my.ini 2)在my.ini最后增加一行,如:ft_min_word_len=2 3)重启mysql生效
使用
Match() 指定被搜索的列 Against() 指定要使用的搜索表达式 match() 函数中指定的列必须和全文索引中指定的列完全相同,否则就会报错,无法使用全文索引,这是因为全文索引不会记录关键字来自哪一列。 举例: select * from people where match(name) against('aaa’); 自然语言模式(NATURAL LANGUAGE MODE) select * from people where match(name) against('aaa*' in boolean mode); 可以使用in boolean mode修饰符执行布尔全文搜索
布尔操作符 | 说明 |
|---|---|
+ | 包含,词必须存在 |
- | 排除,词必须不出现 |
> | 包含,且增加等级值 等级越高显示在上面 |
< | 包含,且减少等级值 |
() | 把词组成表达式 |
~ | 取消一个词的排序值 |
* | 词尾的通配符 |
" " | 定义一个短语 |
注意:在MySQL 5.6版本以前,只有MyISAM存储引擎支持全文引擎.在5.6版本中,InnoDB加入了对全文索引的支持,但是不支持中文全文索引.在5.7.6版本,MySQL内置了ngram全文解析器,用来支持亚洲语种的分词。
#查看ngram_token_size
show variables like '%token%';
ngram_token_size 默认2,表示2个字符作为内置分词解析器的一个关键词,比如:我是帅哥,关键词为’我是‘,‘是帅’,‘帅哥’。
当使用ngram分词解析器时,innodb_ft_min_token_size和innodb_ft_max_token_size 无效。
全文索引练习
创建表并创建全文索引(中文全文解析)
create table full_test(
id int not null primary key auto_increment,
name varchar(255),
address text,
fulltext full_zd_test (address) with parser ngram
);添加测试数据
insert into full_test(name,address) values('张三','北京市昌平区');
insert into full_test(name,address) values('李四','北京市丰台区');
insert into full_test(name,address) values('小三','北京市昌平区沙河镇');
insert into full_test(name,address) values('小四','北京市丰台区刘家窑');
insert into full_test(name,address) values('大三','北京海淀区');
insert into full_test(name,address) values('大四','北京市朝阳区');
insert into full_test(name,address) values('老四','北京市房山区');测试
-- 查找地址北京昌平的行
select *,match(address) against('北京昌平') as '相似度评分'
from full_test where match(address) against('北京昌平');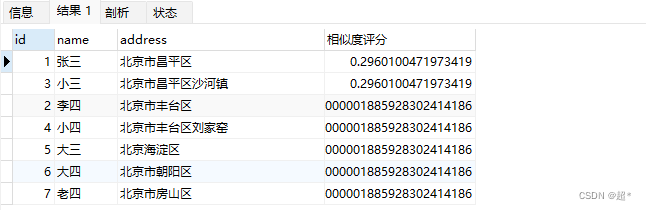
-- 查找包含北京或昌平的行
select * from full_test where match(address) against('北京 昌平' IN BOOLEAN MODE);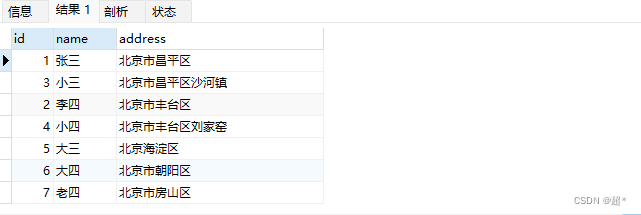
-- 查找必须包含北京和昌平的行
select * from full_test where match(address) against('+北京 +昌平' IN BOOLEAN MODE);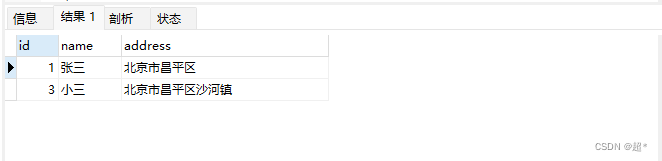
-- 查找必须包含北京,但不包含丰台的行
select * from full_test where match(address) against('+北京 -丰台' IN BOOLEAN MODE);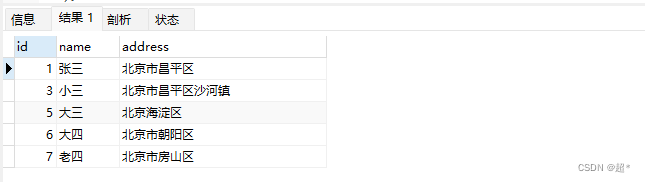
-- 查找必须包含北京,如果包含昌平则不包含昌平的排序值
select *,match(address) against('+北京 ~昌平' IN BOOLEAN MODE) as '评分'
from full_test where match(address) against('+北京 ~昌平' IN BOOLEAN MODE);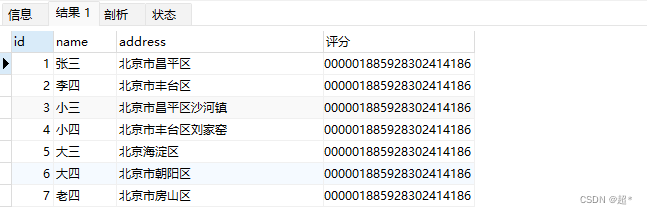
-- 查找必须包含北京和 昌平或丰台,增加昌平等级值,减少丰台等级值
select * from full_test where match(address) against('+北京 +(>昌平 <丰台)' IN BOOLEAN MODE)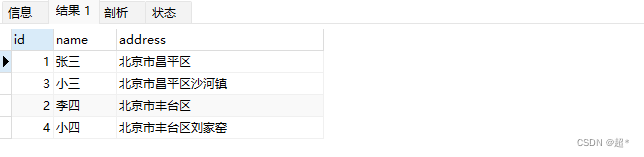
-- 查找以北京市昌平开头的行
select * from full_test where match(address) against('北京市昌平*' IN BOOLEAN MODE)
-- 效果类似(like '%昌平区%')
select * from full_test where match(address) against('"昌平区"' IN BOOLEAN MODE)
创建表并创建全文索引(默认英文全文解析)
create table full_test1(
id int not null primary key auto_increment,
name varchar(255),
address text,
fulltext full_zd_test (address)
);添加测试数据
insert into full_test1(name,address) values('ja','abcd');
insert into full_test1(name,address) values('ja1','abcd+aaa');
insert into full_test1(name,address) values('ja2','abcd+aaaa');
insert into full_test1(name,address) values('ja3','abcd+bbb');
insert into full_test1(name,address) values('ja3','abcd-aab');测试
-- 查找aaa的行
select * from full_test1 where match(address) against('aaa')
-- 查找abcd的行
select * from full_test1 where match(address) against('abcd')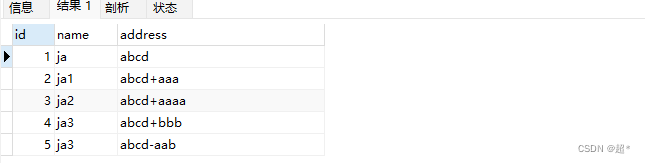
-- 查找aab的行
select * from full_test1 where match(address) against('aab')
-- 查找以aa开头的行
select * from full_test1 where match(address) against('aa*' IN BOOLEAN MODE)
用法和中文全文解析一样,只是分词方式不一样