记一种不错的缓存设计思路

之前与同事讨论接口性能问题时听他介绍了一种缓存设计思路,觉得不错,做个记录供以后参考。
场景
假设有个以下格式的接口:
GET /api?keys={key1,key2,key3,...}&types={1,2,3,...}其中 keys 是业务主键列表,types 是想要取到的信息的类型。
请求该接口需要返回业务主键列表对应的业务对象列表,对象里需要包含指定类型的信息。
业务主键可能的取值较多,千万量级,type 取值范围为 1-10,可以任意组合,每种 type 对应到数据库是 1-N 张表,示意:
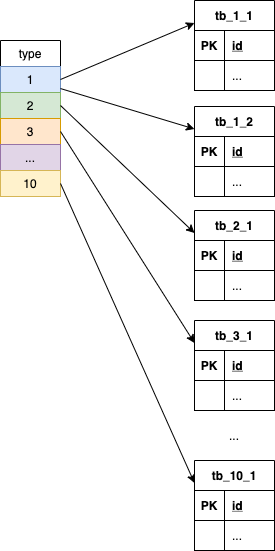
现在设想这个接口遇到了性能瓶颈,打算添加 Redis 缓存来改善响应速度,应该如何设计?
设计思路
方案一:
最简单粗暴的方法是直接使用请求的所有参数作为缓存 key,请求的返回内容为 value。
方案二:
如果稍做一下思考,可能就会想到文首我提到的觉得不错的思路了:
- 使用
业务主键:表名作为缓存 key,表名里对应的该业务主键的记录作为 value; - 查询时,先根据查询参数 keys,以及 types 对应的表,得到所有
key1:tb_1_1、key1:tb_1_2这样的组合,使用 Redis 的 mget 命令,批量取到所有缓存中存在的信息,剩下没有命中的,批量到数据库里查询到结果,并放入缓存; - 在某个表的数据有更新时,只需刷新
涉及业务主键:该表名的缓存,或令其失效即可。
小结
在以上两种方案之间做评估和选择,考虑几个方面:
- 缓存命中率;
- 缓存数量、占用空间大小;
- 刷新缓存是否方便;
稍作思考和计算,就会发现此场景下方案二的优势。
另外,就是需要根据实际业务场景,如业务对象复杂度、读写次数比等,来评估合适的缓存数据的粒度和层次,是对应到某一级组合后的业务对象(缓存值对应存储 + 部分逻辑),还是最基本的数据库表/字段(存储的归存储,逻辑的归逻辑)。
文档信息
- 本文作者:Zhuang Ma
- 本文链接:https://cloud.tencent.com/developer/article/2349726
- 版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)
本文参与 腾讯云自媒体分享计划,分享自作者个人站点/博客。
原始发表:2023/08/27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
相关产品与服务
数据库
云数据库为企业提供了完善的关系型数据库、非关系型数据库、分析型数据库和数据库生态工具。您可以通过产品选择和组合搭建,轻松实现高可靠、高可用性、高性能等数据库需求。云数据库服务也可大幅减少您的运维工作量,更专注于业务发展,让企业一站式享受数据上云及分布式架构的技术红利!