腾讯向量数据库——Embedding
腾讯向量数据库——Embedding

红目香薰
发布于 2023-11-19 08:46:10
发布于 2023-11-19 08:46:10
Embedding 功能提供将非结构化数据转换为向量数据的能力,自动将原始文本转换为向量数据后插入数据库或进行相似性计算,更简单地使用向量数据库。
概述
Embedding 功能是腾讯云向量数据库(Tencent Cloud VectorDB)提供将非结构化数据转换为向量数据的能力,目前已支持文本 Embedding 模型,能够覆盖多种主流语言的向量转换,包括但不限于中文、英文。开启 Embedding 功能并在创建 Collection 时配置模型,在插入、更新和相似性检索数据时直接传入原始文本,向量数据库会自动将原始文本进行转换,生成对应的向量数据后插入数据库或进行相似性计算,大幅提高业务接入效率。
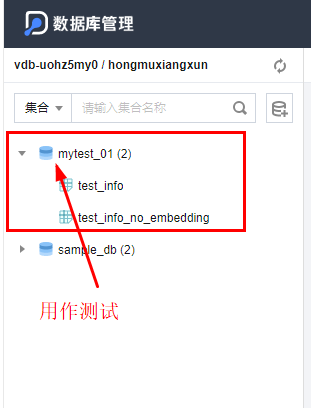
一、创建向量数据库以及创建集合
请直接参考这个文章。
向量数据库
二、Python链接向量数据库
需要包
pip install tcvectordb访问代码
import tcvectordb
from tcvectordb.model.enum import FieldType, IndexType, MetricType, ReadConsistency
#create a database client object
client = tcvectordb.VectorDBClient(url='换成自己的公网地址:40000', username='root', key='EgERjI66Plcj8************', read_consistency=ReadConsistency.EVENTUAL_CONSISTENCY, timeout=30)
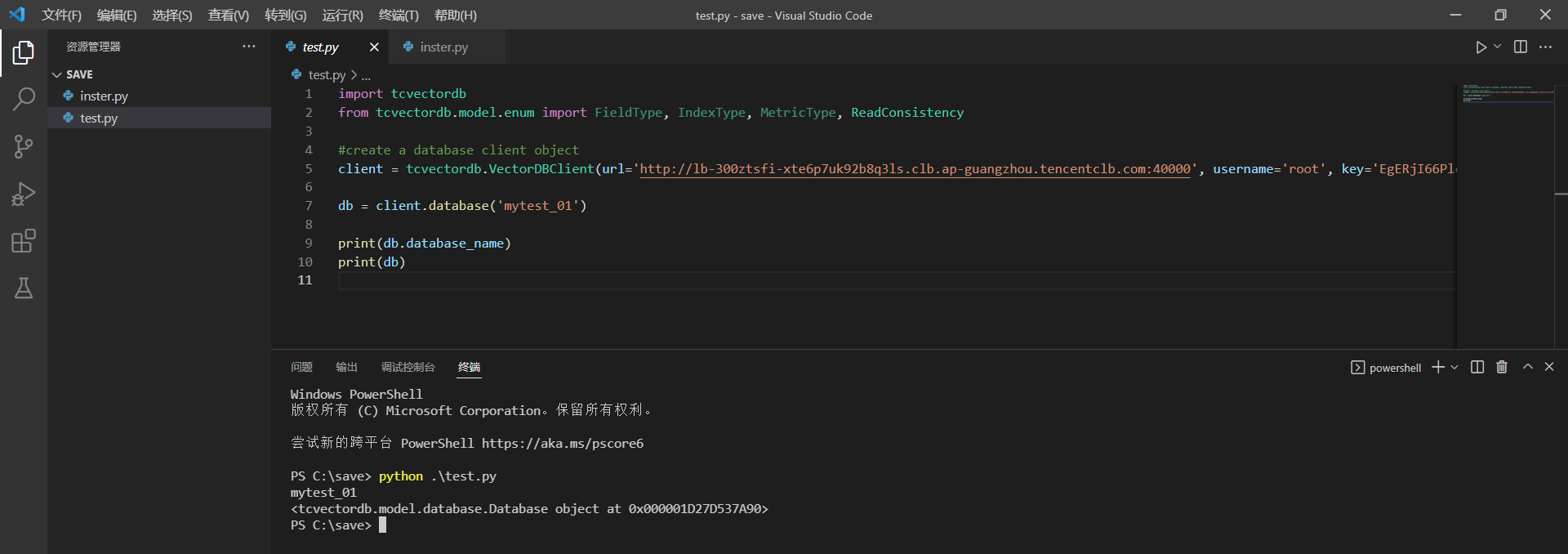
# 链接你的数据库名称
db = client.database('mytest_01')
# 能输出名称代表成功
print(db.database_name)
print(db)访问效果:

整体效果:
三、向集合插入文本数据
代码
import tcvectordb
from tcvectordb.model.collection import Embedding, UpdateQuery
from tcvectordb.model.document import Document, Filter, SearchParams
from tcvectordb.model.enum import FieldType, IndexType, MetricType, EmbeddingModel
from tcvectordb.model.index import Index, VectorIndex, FilterIndex, HNSWParams, IVFFLATParams
from tcvectordb.model.enum import FieldType, IndexType, MetricType, ReadConsistency
# create a database client object
client = tcvectordb.VectorDBClient(url='换成自己的公网地址:40000', username='root', key='EgERjI66Plcj8************', read_consistency=ReadConsistency.EVENTUAL_CONSISTENCY, timeout=30)
# 指定写入原始文本的数据库与集合
db = client.database('mytest_01')
coll = db.collection('test_info')
# 写入数据,可能存在一定延迟
# 1. 支持动态 Schema,除了 id、text 字段必须写入,可以写入其他任意字段,text 字段为创建集合时,设置的文本字段名
# 2. upsert 会执行覆盖写,若文档id已存在,则新数据会直接覆盖原有数据(删除原有数据,再插入新数据)
# 3. 参数 build_index 为 True,指写入数据同时重新创建索引。
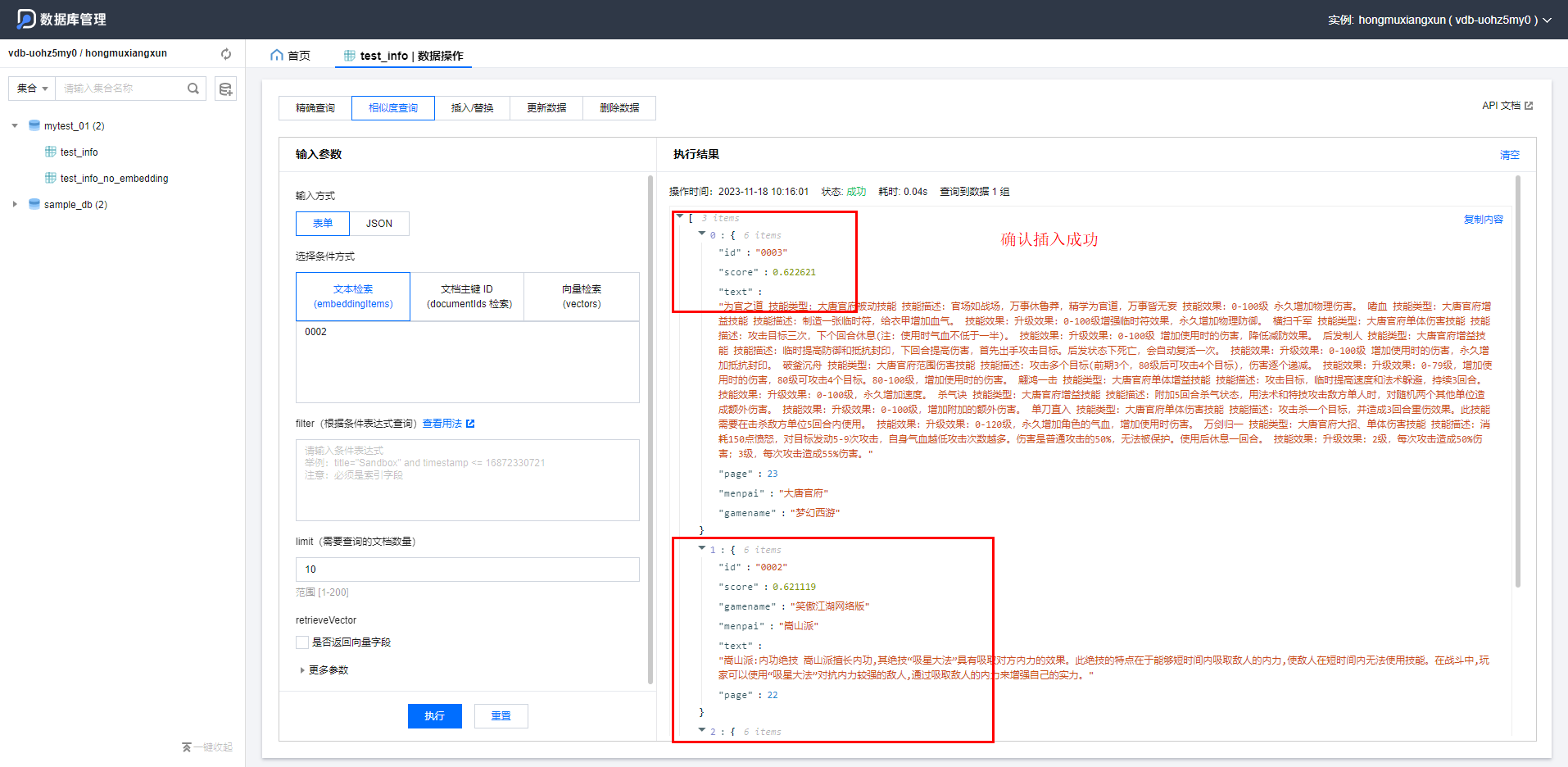
res = coll.upsert(
documents=[
Document(id='0001', text="华山技能类型介绍 华山派有三种不同类型的技能,分别是狂风快剑、天罡北斗和紫霞神功。狂风快剑以快速攻击为主,天罡北斗以防御和吸收伤害为主,紫霞神功以远程攻击和治疗为主。",
menpai='华山派', gamename='笑傲江湖OL', page=21),
Document(id='0002', text="嵩山派:内功绝技 嵩山派擅长内功,其绝技“吸星大法”具有吸取对方内力的效果。此绝技的特点在于能够短时间内吸取敌人的内力,使敌人在短时间内无法使用技能。在战斗中,玩家可以使用“吸星大法”对抗内力较强的敌人,通过吸取敌人的内力来增强自己的实力。",
menpai='嵩山派', gamename='笑傲江湖网络版', page=22),
Document(id='0003', text="""为官之道
技能类型:大唐官府被动技能
技能描述:官场如战场,万事休鲁莽,精学为官道,万事皆无妄
技能效果:0-100级 永久增加物理伤害。
嗜血
技能类型:大唐官府增益技能
技能描述:制造一张临时符,给衣甲增加血气。
技能效果:升级效果:0-100级增强临时符效果,永久增加物理防御。
横扫千军
技能类型:大唐官府单体伤害技能
技能描述:攻击目标三次,下个回合休息(注:使用时气血不低于一半)。
技能效果:升级效果:0-100级 增加使用时的伤害,降低减防效果。
后发制人
技能类型:大唐官府增益技能
技能描述:临时提高防御和抵抗封印,下回合提高伤害,首先出手攻击目标。后发状态下死亡,会自动复活一次。
技能效果:升级效果:0-100级 增加使用时的伤害,永久增加抵抗封印。
破釜沉舟
技能类型:大唐官府范围伤害技能
技能描述:攻击多个目标(前期3个,80级后可攻击4个目标),伤害逐个递减。
技能效果:升级效果:0-79级,增加使用时的伤害,80级可攻击4个目标。80-100级,增加使用时的伤害。
翩鸿一击
技能类型:大唐官府单体增益技能
技能描述:攻击目标,临时提高速度和法术躲避,持续3回合。
技能效果:升级效果:0-100级,永久增加速度。
杀气诀
技能类型:大唐官府增益技能
技能描述:附加5回合杀气状态,用法术和特技攻击敌方单人时,对随机两个其他单位造成额外伤害。
技能效果:升级效果:0-100级,增加附加的额外伤害。
单刀直入
技能类型:大唐官府单体伤害技能
技能描述:攻击杀一个目标,并造成3回合重伤效果。此技能需要在击杀敌方单位5回合内使用。
技能效果:升级效果:0-120级,永久增加角色的气血,增加使用时伤害。
万剑归一
技能类型:大唐官府大招、单体伤害技能
技能描述:消耗150点愤怒,对目标发动5-9次攻击,自身气血越低攻击次数越多。伤害是普通攻击的50%,无法被保护。使用后休息一回合。
技能效果:升级效果:2级,每次攻击造成50%伤害;3级,每次攻击造成55%伤害。""",
menpai='大唐官府', gamename='梦幻西游', page=23)
],
build_index=True
)运行结果
四、查询检索
这里我提供一个json的列表,根据这些参数修改即可。
{
"database": "mytest_01",
"collection": "test_info",
"search": {
"vectors": [],
"documentIds": [],
"embeddingItems": [
"吸星大法"
],
"params": {
"ef": 100
},
"filter": "",
"retrieveVector": false,
"limit": 10,
"outputFields": []
}
}代码:
import tcvectordb
from tcvectordb.model.enum import FieldType, IndexType, MetricType, EmbeddingModel, ReadConsistency
from tcvectordb.model.index import Index, VectorIndex, FilterIndex, HNSWParams
from tcvectordb.model.document import Document, Filter, SearchParams
# create a database client object
client = tcvectordb.VectorDBClient(url='http://lb-300ztsfi-xte6p7uk92b8q3ls.clb.ap-guangzhou.tencentclb.com:40000',
username='root',
key='EgERjI66Plcj80J5W8ZUE8Wib3t1OzZq2pBilNQO',
read_consistency=ReadConsistency.EVENTUAL_CONSISTENCY, timeout=30)
db = client.database('mytest_01')
coll = db.collection('test_info')
# 1. searchByText 提供按照 embeddingItems 输入的文本批量进行相似性查询的能力
# 2. 支持通过 filter 过滤数据
# 3. 如果仅需要部分 field 的数据,可以指定 output_fields 用于指定返回数据包含哪些 field,不指定默认全部返回
# 4. limit 用于限制每个单元搜索条件的条数,如 vector 传入三组向量,limit 为 3,则 limit 限制的是每组向量返回 top 3 的相似度向量
# 5. params 指定索引类型对应的查询参数,HNSW 类型需要设置 ef,指定查询的遍历范围;IVF 系列需要设置 nprobe,指定查询的单位数量
# 6. retrieve_vector 指定是否输出向量字段
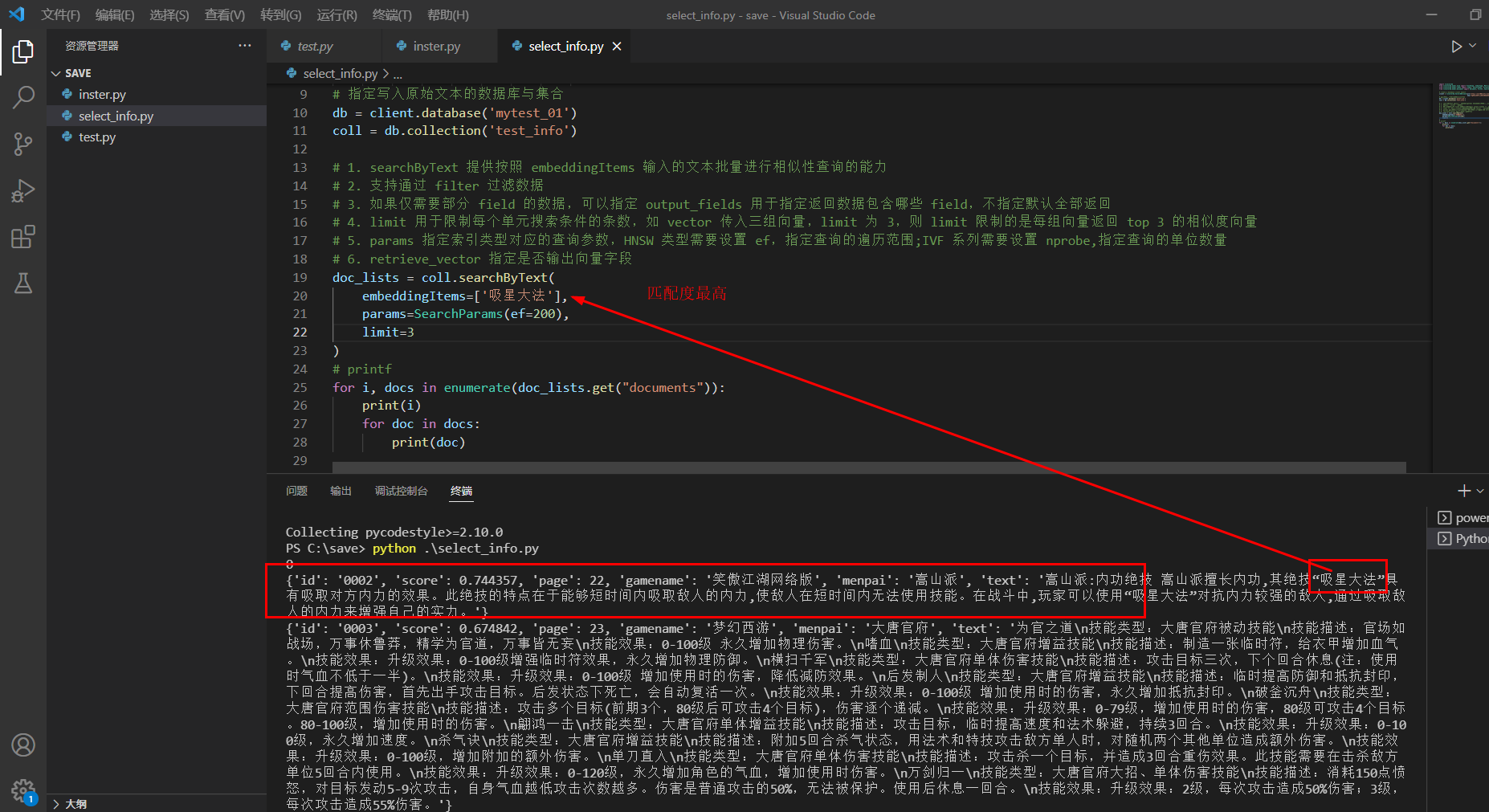
doc_lists = coll.searchByText(
embeddingItems=['吸星大法'],
params=SearchParams(ef=200),
limit=3
)
# printf
for i, docs in enumerate(doc_lists.get("documents")):
print(i)
for doc in docs:
print(doc)效果:
五、修改数据
代码
import tcvectordb
from tcvectordb.model.collection import Embedding, UpdateQuery
from tcvectordb.model.document import Document, Filter, SearchParams
from tcvectordb.model.enum import FieldType, IndexType, MetricType, EmbeddingModel
from tcvectordb.model.index import Index, VectorIndex, FilterIndex, HNSWParams, IVFFLATParams
from tcvectordb.model.enum import FieldType, IndexType, MetricType, ReadConsistency
# create a database client object
client = tcvectordb.VectorDBClient(url='http://lb-300ztsfi-xte6p7uk92b8q3ls.clb.ap-guangzhou.tencentclb.com:40000', username='root',
key='EgERjI66Plcj80J5W8ZUE8Wib3t1OzZq2pBilNQO', read_consistency=ReadConsistency.EVENTUAL_CONSISTENCY, timeout=30)
# 指定写入原始文本的数据库与集合
db = client.database('mytest_01')
coll = db.collection('test_info')
# 写入数据,可能存在一定延迟
# 1. 支持动态 Schema,除了 id、text 字段必须写入,可以写入其他任意字段,text 字段为创建集合时,设置的文本字段名
# 2. upsert 会执行覆盖写,若文档id已存在,则新数据会直接覆盖原有数据(删除原有数据,再插入新数据)
# 3. 参数 build_index 为 True,指写入数据同时重新创建索引。
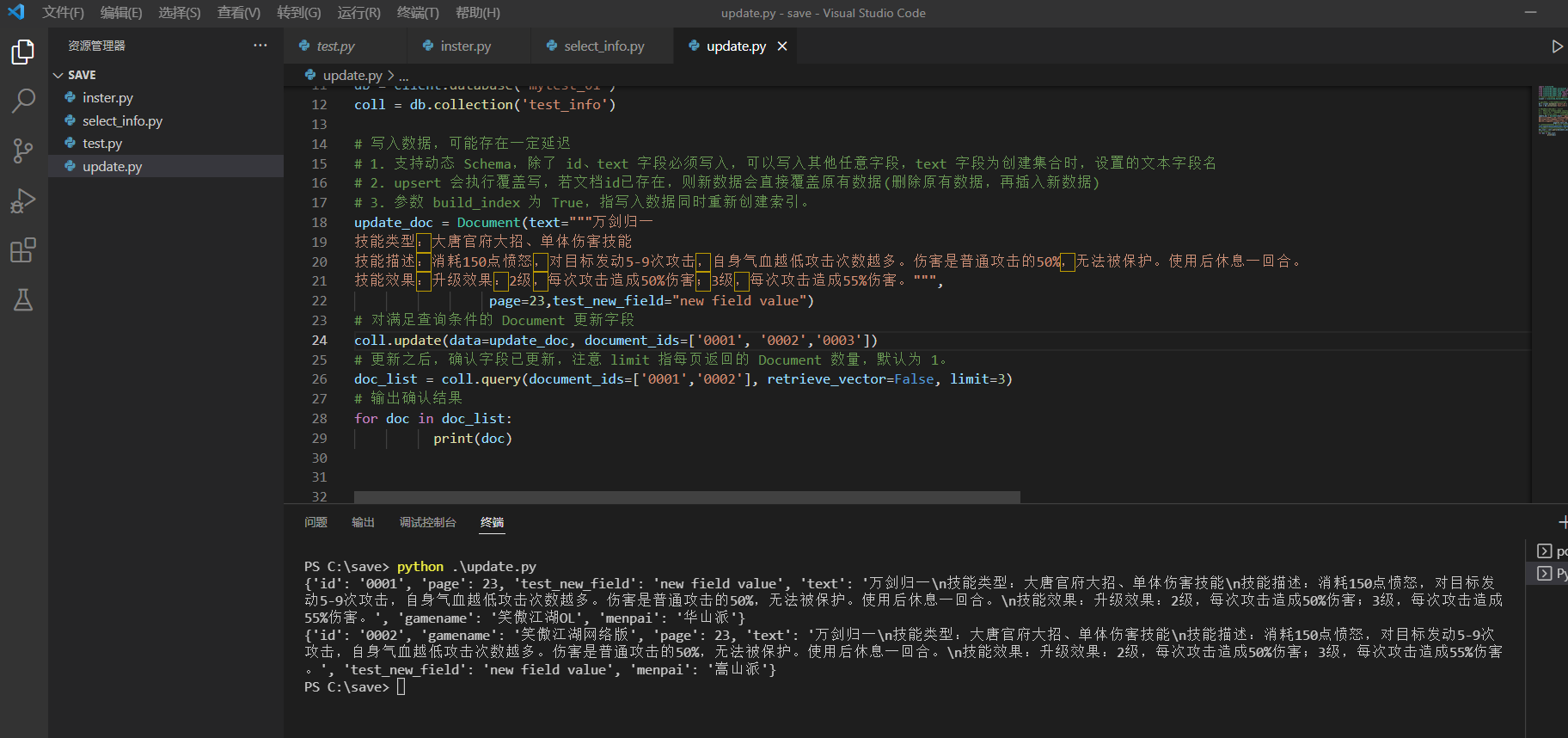
update_doc = Document(text="""万剑归一
技能类型:大唐官府大招、单体伤害技能
技能描述:消耗150点愤怒,对目标发动5-9次攻击,自身气血越低攻击次数越多。伤害是普通攻击的50%,无法被保护。使用后休息一回合。
技能效果:升级效果:2级,每次攻击造成50%伤害;3级,每次攻击造成55%伤害。""",
page=23,test_new_field="new field value")
# 对满足查询条件的 Document 更新字段
coll.update(data=update_doc, document_ids=['0001', '0002','0003'])
# 更新之后,确认字段已更新,注意 limit 指每页返回的 Document 数量,默认为 1。
doc_list = coll.query(document_ids=['0001','0002'], retrieve_vector=False, limit=3)
# 输出确认结果
for doc in doc_list:
print(doc)修改以及查询效果
总结
相关 API | 含义 | Embedding 信息 |
|---|---|---|
/collection/create | 创建集合 | 指定 Embedding 模型,配置输入文本的字段名及其输出的向量字段。 |
/document/upsert | 插入数据 | 插入原始文本信息,将原始文本直接向量化,将原始文本与向量数据一并存入数据库。 |
/document/update | 更新数据 | 更新之前写入的文本信息,自动向量化后存入数据库。 |
/document/search | 检索数据 | 检索数据时,可根据输入的文本信息,自动向量化并检索与其最相似的数据。 |
本文参与 腾讯云自媒体分享计划,分享自作者个人站点/博客。
原始发表:2023-11-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读