Part3-2.获取高质量的阿姆斯特丹建筑立面图像(补档)
Part3-2.获取高质量的阿姆斯特丹建筑立面图像(补档)

(补档,建议点击底部阅读原文跳转到我的博客阅读)本文为《通过深度学习了解建筑年代和风格》论文复现的第三部分——获取阿姆斯特丹高质量街景图像的下篇,主要是介绍如何用Python的selenium库去操控浏览器截取谷歌街景图像,并按照Pytorch中标准ImageFolder保存,最后使用语义分割模型进行进一步筛选图片。
目录:
- 1.1 浏览器初始化
- 1.2 selenium打开网页并截图
- 1.3 对截图进行裁剪
- 1.4 按照 PyTorch 中标准ImageFolder文件夹结构保存
- 3.1 整合get_webdriver函数
- 3.2 多线程
- 3.3 使用文件锁避免写入错误
- 3.4 新增进度统计和通知
- 4.1 如何筛选出高质量的街景
- 4.2 语义分割的模型选择
- 4.3 配置 semantic-segmentation-pytorch 环境
- 4.2 加载颜色映射表(分类的标签)
- 4.3 加载模型和权重
- 4.4 加载数据集
- 4.5 自定义数据集
- 4.5 运行预测模型
- 4.6 使用预测的原始输出来筛选图片
- 5.1 街景图获取的偏差
- 1)在某些特殊的建筑中,未能正确获取到它的街景图。
- 2) 语义分割删除掉的街景点未重新获取
- 额外阅读
- 写在最后
阅读前必看知识点
- 正确配置好
selenium,版本建议高于4.6.0,我安装的selenium版本是4.14.0。关于如何安装selenuim、配置chromedriver可以查看文章:如何在多平台(win/mac/linux)上安装webdriver并使用selenium[1]
一、通过selenium打开浏览器自动截图采集街景
我们会从上文Part3.获取高质量的阿姆斯特丹建筑立面图像(上)[2]得到的包含指定位置的谷歌街景图像的12303条网址出发,通过自动化获取街景图像。首先,因为谷歌地图不能在国内访问,所以需要K-X-S-W。
Codespace中使用selenium[3]。
1.1 浏览器初始化
from selenium import webdriver
from selenium.webdriver import ChromeOptions
from selenium.webdriver.chrome.service import Service as ChromeService
from webdriver_manager.chrome import ChromeDriverManager
options = ChromeOptions()
options.add_argument('--headless')
options.add_argument('lang=zh_CN.UTF-8')
options.add_argument('--disable-gpu')
options.add_argument('--disable-dev-shm-usage')
options.add_argument('--no-sandbox') # 解决DevToolsActivePort文件不存在的报错
options.add_argument("--start-maximized")
options.add_argument("--window-size={1920},{1080}")
# options.add_argument('blink-settings=imagesEnabled=false') # 不加载图片, 提升速度
# 启动webdriver
driver = webdriver.Chrome(service=ChromeService(ChromeDriverManager().install()), options=options)
以上浏览器选项足以应对所有的浏览器自动化项目,不过有几点要说明:
options.add_argument('--headless'):启用无头模式,意味着浏览器不会启动界面,后台运行,如果需要调试则把它注释掉。options.add_argument("--start-maximized")和options.add_argument("--window-size={},{}".format(width, height)):最大化浏览器窗口,并且设置分辨率为1920*1080。options.add_argument('blink-settings=imagesEnabled=false'):不加载图片, 提升速度,本项目不需要。ChromeService:高版本的selenium使用ChromeService('/path/to/chromedriver.exe')定义浏览器驱动的路径。Service类是用来创建一个 WebDriver 服务的。这个服务是 Selenium WebDriver 和浏览器之间通信的桥梁。Service类的构造函数需要一个参数,即 WebDriver 可执行文件的路径。ChromeDriverManager().install():使用webdriver_manager库的浏览器驱动管理,自动安装适合本地浏览器版本的浏览器驱动。- 最后一步会启动浏览器,下一步是打开指定网页。
1.2 selenium打开网页并截图
我们把网页称为url,我们先先定义一个用于测试的url,然后去获取截图:
url = "https://www.google.com/maps/@52.36141240422054,4.979456793520979,3a,70y,326.09721714642694h,90t/data=!3m6!1e1!3m4!1sVz0QmEdXIKTJ5mluzj4VgA!2e0!7i16384!8i8192" # 测试url
driver.get(url) # 打开指定网页
time.sleep(3) # 在国内时间适当延长
# 截图
driver.save_screenshot(origin_path := "test.png") # := 海象运算符,在表达式中同时进行变量赋值和返回赋值的结果。
# 退出浏览器
driver.quit()
# driver.close() # 关闭当前标签页
我们查看保存的test.png文件,和用浏览器打开的街景是一样的:

test.png
1.3 对截图进行裁剪
我们还需要进行裁切掉左右的干扰图标,同时,为了后续的深度学习训练,我从1920x1080像素裁剪到了一个合适的大小:512x512像素。
你也可以根据自己的情况选择一个正方形的像素大小,一方面是为了匹配深度学习,后续模型输入的是宽高最好高于214x214,但是又不能过大,另一方面是减小数据量。裁剪之后文件约420kb大小:

test.png裁切后
1.4 按照 PyTorch 中标准ImageFolder文件夹结构保存
在 PyTorch 中,ImageFolder 是一个方便的数据加载器,它可以从一个目录结构中加载图像数据并且自动生成标签。它期望的目录结构是每个类别一个子目录,所有属于同一类别的图像都放在同一个子目录中。他的结构如下图:
data/
class1/
img1.jpg
img2.jpg
...
class2/
img1.jpg
img2.jpg
...
...
在我们的项目中,类别(class)就是9种建筑年代,未知年代文件夹是在selenium中爬取时遗留的文件,需要手动删除:
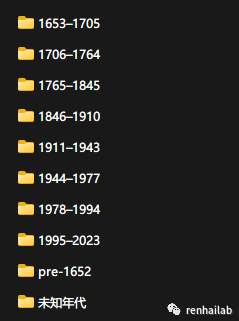
街景图像目录结构
所以,我们根据从建筑足迹中传递到url文件中bouwjaar年代标签,对文件进行分类,并保存图片到对应的文件夹:
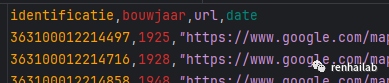
url文件示例
year = int(year) # 转化为整数
if year <= 1652:
return "pre-1652"
elif 1653 <= year <= 1705:
return "1653–1705"
elif 1706 <= year <= 1764:
return "1706–1764"
elif 1765 <= year <= 1845:
return "1765–1845"
elif 1846 <= year <= 1910:
return "1846–1910"
elif 1911 <= year <= 1943:
return "1911–1943"
elif 1944 <= year <= 1977:
return "1944–1977"
elif 1978 <= year <= 1994:
return "1978–1994"
elif 1995 <= year <= 2023: # 作者是2020年写的,我们采用今年——2023年
return "1995–2023"
三、优化代码,进行多线程处理
首先,我们以函数的组织代码,然后增加多线程处理,最后增加一些进度统计和通知的函数。
3.1 整合get_webdriver函数
为了让同一个get_webdriver能同时在windows和codespace中运行打开浏览器,我们需要对其做一些改变,在windows中我们使用ChromeDriverManager().install()去定义浏览器执行路径,在codespace中我们选择直接输入chromedriver_path来定义浏览器执行路径,所以最终在代码 service = Service(chromedriver_path or ChromeDriverManager().install()) 中使用or语句用于判断:
- 如果
chromedriver_path变量不是None(也就是说,它包含一个有效的路径),那么Service(chromedriver_path)会被执行,chromedriver_path的值会被传递给Service构造函数。 - 如果
chromedriver_path变量是None,那么ChromeDriverManager().install()会被执行。ChromeDriverManager是webdriver_manager库的一个类,它的install方法会自动下载和安装最新版本的 ChromeDriver,并返回 ChromeDriver 可执行文件的路径。然后这个路径会被传递给Service构造函数。
def get_webdriver(headless, driver_implicity_wait_time, chromedriver_path=None):
options = Options()
if headless: # 方便调试,headless的值为布尔:True or False
options.add_argument('--headless')
options.add_argument('lang=zh_CN.UTF-8')
options.add_argument('--disable-gpu')
options.add_argument('--disable-dev-shm-usage')
options.add_argument('--no-sandbox')
options.add_argument("--window-size=1920,1080")
options.add_argument("--color-depth=24")
service = Service(chromedriver_path or ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=options)
return driver
3.2 多线程
通过 concurrent.futures.ThreadPoolExecutor 使用多线程,这是 Python 标准库中提供的一个多线程实现方式,它允许你非常方便地创建和管理线程。这个类提供了一个高层次的接口来异步地执行可调用对象,并能返回 Future 对象,这些对象代表了异步操作的结果。下面是如何使用 ThreadPoolExecutor 来执行多线程任务的基本步骤:
- 导入模块:
from concurrent.futures import ThreadPoolExecutor
- 创建
ThreadPoolExecutor实例:
executor = ThreadPoolExecutor(max_workers=5) # 创建一个最大线程数为5的线程池
max_workers参数指定了线程池中的最大线程数,根据自己电脑的cpu、内存等资源占有情况自行设置
- 提交任务:
def say_hello(name):
print(f"Hello, {name}!")
# 提交单个任务
future = executor.submit(say_hello, 'Alice')
# 或者使用 map 方法提交多个任务
futures = executor.map(say_hello, ['Alice', 'Bob', 'Charlie'])
submit方法提交一个任务,并返回一个Future对象。map方法可以同时提交多个任务,并返回一个迭代器,它将产生Future对象。
- 处理结果:
# 使用 result 方法获取任务的结果
result = future.result()
# 对于使用 map 提交的任务,可以直接迭代结果
for result in futures:
print(result)
OUT:
Hello, Alice!
Hello, Bob!
Hello, Charlie!
Future对象的result方法可以用来获取任务的结果。如果任务还没有完成,result方法会阻塞,直到任务完成。
3.3 使用文件锁避免写入错误
在多线程环境中,当多个线程尝试同时访问和修改同一个文件时,可能会出现竞争条件(race conditions),导致数据损坏或其他不可预见的错误。为了避免这种情况,可以使用文件锁来确保一次只有一个线程能够访问文件。
import threading
file_lock = threading.Lock()
with file_lock:
image.save(new_path)
print(f"保存图片{new_path}成功")
3.4 新增进度统计和通知
- 利用count计数和pypushdeer[4]实现进度统计和通知。IOS系统接受pushdeer通知的的方法见:https://github.com/easychen/pushdeer
四、对街景图像进行进一步筛选
4.1 如何筛选出高质量的街景
我们上述获取的街景只有一个筛选条件——建筑到街景拍摄点的距离(我定义的是20米),但是从上图中我们可以看出以下两类数据也需要删除:
- 拍摄点依旧较远,导致图像中建筑物较小(如下图);

建筑物较小
- 建筑物被树木或其他物体遮挡。比如下图
test.png裁切后。
test.png裁切后
我们借鉴论文作者的方法使用语义分割来筛选街景:
“为此去除以上两类数据,我们提出了一种基于图像内容定量表示的评估方法。 该方法遵循三个步骤:
- 将候选图像输入场景解析 DCNN 模型。场景解析模型为图像中的每个像素分配语义类别标签(例如天空、建筑物和树)。这里我们采用在 ADE20K 数据集上训练的场景解析模型,ADE20K 数据集是一个大规模图像数据集,包含由 150 个类别标记的图像;
- 计算图像各视觉对象(例如天空、建筑物和树)的比例;
- 保留符合以下两个标准的图像:
- 建筑物类别所占比例在所有类别中最高;
- 建筑物占据图像的 40% 以上。”——来自论文
4.2 语义分割的模型选择
在Github上搜索到一个使用MIT ADE 20K数据集进行语义分割研究的仓库:semantic-segmentation-pytorch[5],使用的是pytorch包,利用MIT ADE 20 K场景解析数据集(http//sceneparsing.csail.mit.edu/[6])进行语义分割的模型:

语义分割演示
[From从左到右:测试图像、地面真实值、预测结果]
评估得分:
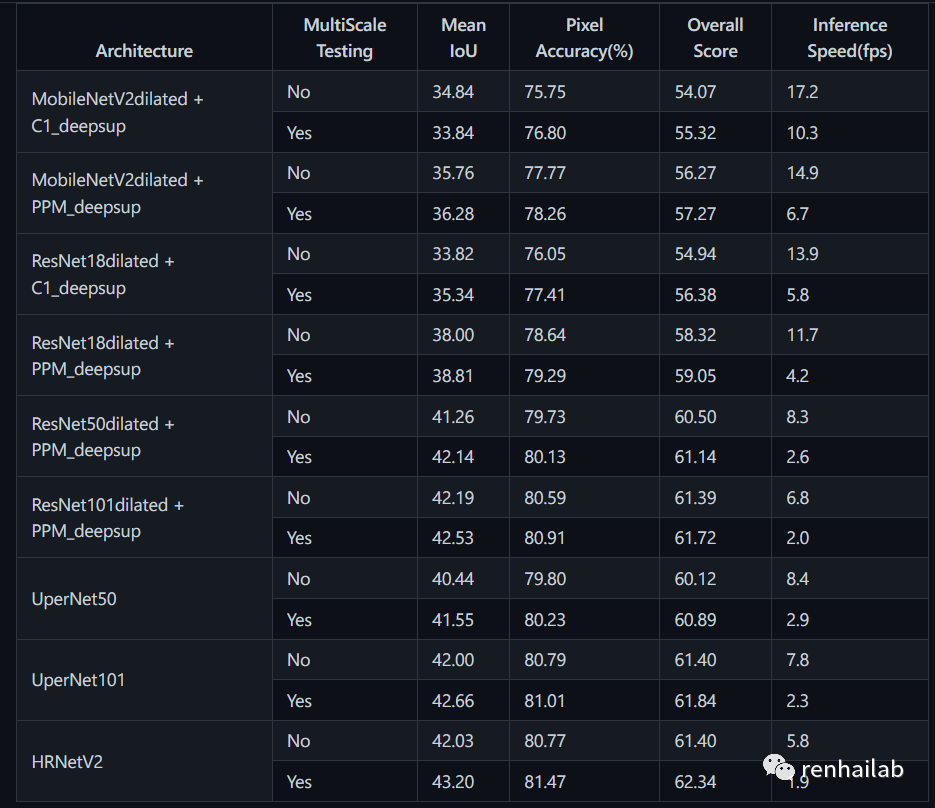
评估得分
此储存库最近一次提交实在2020年八月,距离现在2023也已经过去了三年,从准确率上来看也与现在的流行的语义分割模型(比如Meta[7]发布的segment-anything[8],Deeplab V3+[9])还是有一定差距,
segment-anything可以访问官方https://segment-anything.com/查看更多案例。

segment-anything examples 1

segment-anything examples 2
不过更精确的语义分割意味着更多的GPU资源的占用,处理的时间成本会增加,考虑到我们仅用来筛选图片,所以我们还是选用论文采用的模型。
也有可能现在的模型速度更快并且时间更短,如果你尝试了另外一个模型可以和我探讨。
4.3 配置 semantic-segmentation-pytorch 环境
可以在Colab上使用先运行模型: https://colab.research.google.com/github/CSAILVision/semantic-segmentation-pytorch/blob/master/notebooks/DemoSegmenter.ipynb。
对于本项目,我选择在本地运行,除了在环境中安装Pytoch环境外,还要克隆此仓库,终端运行:
git clone https://github.com/CSAILVision/semantic-segmentation-pytorch.git
pip install git+https://github.com/CSAILVision/semantic-segmentation-pytorch.git@master # 需访问国外网站
首先,导入相关库:
# 导入库
import PIL.Image
import csv
import numpy as np
import os
import scipy.io
import torch
import torchvision.transforms
from IPython.display import display
# 导入仓库定义的库 从github地址下载 或者安装 pip install git+https://github.com/CSAILVision/semantic-segmentation-pytorch.git@master
from mit_semseg.models import ModelBuilder, SegmentationModule
from mit_semseg.utils import colorEncode
定义刚刚semantic-segmentation-pytorch的仓库位置:
seg_repo_dir = "./semantic-segmentation-pytorch-master"
4.2 加载颜色映射表(分类的标签)
我们先加载150种颜色分类表和参数,获取idx和name,注意此处的idx是从1开始的,预测结果的class是0开始的,所以idx+1为最终预测class。比如,idx为2的Name是building,但是在预测的class中为1:
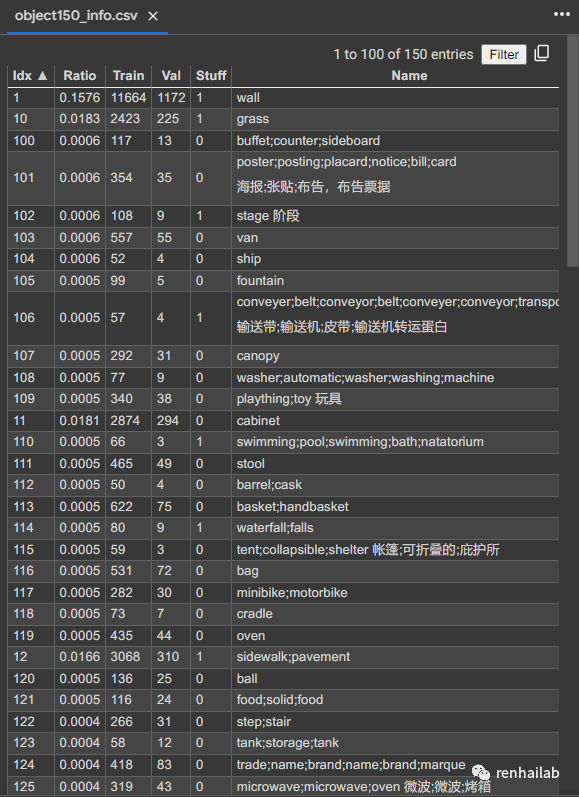
150种标签
在代码中加载上述颜色映射表:
# 加载颜色映射表
colors = scipy.io.loadmat(f'{seg_repo_dir}/data/color150.mat')['colors']
# 加载类别名称映射表
names = {}
with open(f'{seg_repo_dir}/data/object150_info.csv') as f:
reader = csv.reader(f) # 使用csv库读取,这是原始notebook中的代码,你也可以用pandas读取csv
next(reader) # 迭代器选择下一个要素,跳过标题行
for row in reader:
names[int(row[0])] = row[5].split(";")[0] # 在name字段中以分号分割,取第一个
接下来的操作需要有一定的Pytorch的基础,推荐阅读:02-快速入门:使用PyTorch进行机器学习和深度学习的基本工作流程(笔记+代码)[10]。
4.3 加载模型和权重
这里,我们加载一个预训练的语义分割模型。 像任何 pytorch 模型一样,我们可以像函数一样调用它,或者检查所有层中的参数。加载后,我们将其转移到 GPU 上。 由于我们是在进行推理,而不是训练,因此我们将模型置于评估(eval)模式。
# 网络构建器
net_encoder = ModelBuilder.build_encoder(
arch='resnet50dilated',
fc_dim=2048,
weights=f'{seg_repo_dir}/ckpt/ade20k-resnet50dilated-ppm_deepsup/encoder_epoch_20.pth')
# 使用预训练的resnet50dilated模型构建编码器,设置全连接层维度为2048,加载权重文件路径为...
net_decoder = ModelBuilder.build_decoder(
arch='ppm_deepsup',
fc_dim=2048,
num_class=150,
weights=f'{seg_repo_dir}/ckpt/ade20k-resnet50dilated-ppm_deepsup/decoder_epoch_20.pth',
use_softmax=True)
# 使用ppm_deepsup模型构建解码器,设置全连接层维度为2048,类别数为150,加载权重文件路径为...,使用softmax激活函数
权重文件可以从 http://sceneparsing.csail.mit.edu/model/pytorch/ade20k-resnet50dilated-ppm_deepsup/ 获取,但是似乎链接失效了,我重新找到了此权重文件,百度网盘链接:https://pan.baidu.com/s/1_rED7Xnl0n2VEhPayFkwcw?pwd=6was | 提取码:6was 。
接下来定义损失函数、之后定义模型:
crit = torch.nn.NLLLoss(ignore_index=-1) # 定义损失函数为负对数似然损失,忽略索引为-1的部分
segmentation_module = SegmentationModule(net_encoder, net_decoder, crit) # 构建语义分割模块,传入编码器、解码器和损失函数
segmentation_module.eval() # 将语义分割模块设置为评估模式,不进行梯度计算
segmentation_module.cuda() # 将语义分割模块移动到GPU上进行计算,使用CUDA加速
4.4 加载数据集
现在我们加载并对一张测试图像进行归一化处理,将图像归一化到一个尺度,使得大型照片数据集的RGB值具有零均值和单位标准差。(这些数值来自于ImageNet数据集。)通过这种归一化,RGB值的取值范围大约在(-2.2到+2.7)之间。
首先传入单张照片:
file_path = "9--363100012064199.png"
# 加载并归一化一张图像作为单张张量批次
pil_to_tensor = transforms.Compose([
transforms.ToTensor(), # 将图像转换为张量
transforms.Normalize(
mean=[0.485, 0.456, 0.406], # 这些是RGB均值和标准差的值
std=[0.229, 0.224, 0.225]) # 来自于一个大型照片数据集的统计数据
])
# 打开图像并转换为RGB模式(实际是转换图片的维度顺序)
pil_image = PIL.Image.open(file_path).convert('RGB')
# 将图像转换为NumPy数组
img_original = np.array(pil_image)
# 使用pil_to_tensor函数对图像进行归一化处理
img_data = pil_to_tensor(pil_image)
# 创建一个单张批次的字典
# singleton_batch = {'img_data': img_data[None].cpu()} # 在CPU上运行
singleton_batch = {'img_data': img_data[None].cuda()} # 在CUDA上运行
# 通过使用img_data.shape[1:],我们可以访问从第二个维度开始的维度,也就是获取形状[H, W]。
# 这表示图像的高度和宽度,而不考虑通道数。
output_size = img_data.shape[1:]
output_size
out:
torch.Size([512, 512])
不考虑颜色通道,我们输出的图像为512X512。
4.5 自定义数据集
批量加载图像也可以用自定义数据集并且使用数据加载器:
有关自定义数据集并且使用数据加载器可以查看笔记:05-PyTorch自定义数据集[11]
# 定义数据集类
class ImageDataset(Dataset):
def __init__(self, file_paths):
self.file_paths = file_paths
self.transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
def __len__(self):
return len(self.file_paths)
def __getitem__(self, idx):
pil_image = PIL.Image.open(self.file_paths[idx]).convert('RGB')
img_data = self.transform(pil_image)
return img_data
dataset = ImageDataset(file_paths)
# 数据加载器
dataloader = DataLoader(dataset, batch_size=2, shuffle=False, num_workers=0) # batch_size为批量处理的数量,和你的gpu内存相关,注意num_workers要大于batch_size,在某些jupyter notebook中使用num_workers=0以防止多线程错误。
4.5 运行预测模型
先定义一个利用pillow绘制原始图像和结果的函数:
def visualize_result(img, pred, index=None):
# 如果指定了类别索引,过滤预测结果
if index is not None:
pred = pred.copy()
pred[pred != index] = -1 # 把不是index的都变成-1
print(f'{names[index+1]}:') # 打印类别名称
# 为预测结果上色
pred_color = colorEncode(pred, colors).astype(numpy.uint8)
# 合并图像并保存
im_vis = numpy.concatenate((img, pred_color), axis=1) # 将原始图像和彩色编码的分割结果并排放置
display(PIL.Image.fromarray(im_vis))
return pred_color
# 使用inference_mode速度更快
with torch.inference_mode():
# 使用分割模块对单张批次进行分割,输出尺寸为output_size
scores = segmentation_module(singleton_batch, segSize=output_size)
# 获取每个像素的预测得分
# 使用torch.max()函数获取每个像素位置的最大得分及其对应的类别索引
_, pred = torch.max(scores, dim=1)
pred = pred.cpu()[0].numpy() # 将预测结果转移到CPU上,并转换为NumPy数组
# 将预测结果可视化为彩色图像
pred_color = visualize_result(img_original, pred)

originl image和pred_color的对比
4.6 使用预测的原始输出来筛选图片
我们可以查看pred.shape为(512, 512),为一个二维数组,有512行和512列。接下来我们需要要求筛选图片,满足“建筑物类别所占比例在所有类别中最高; 建筑物占据图像的 40% 以上。”
# 查看这个数组
pred
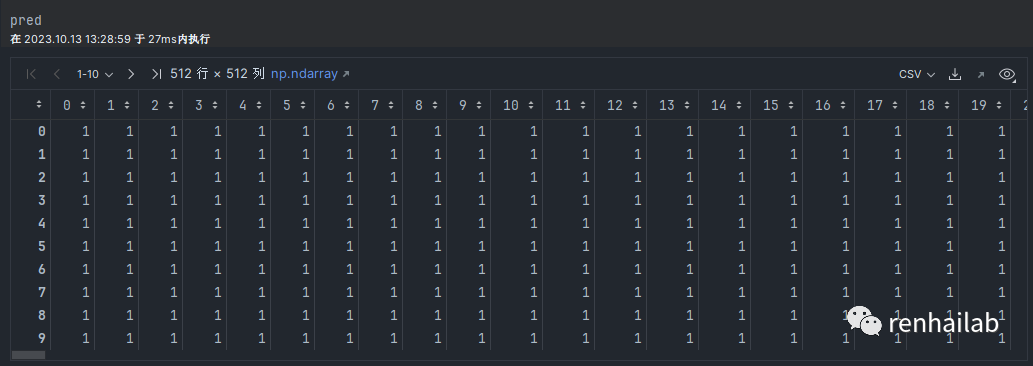
pred
数组中的数字1即代表此处的预测的结果是:index为2、预测类别(Name)为building的像素点,我们可以直接统计每类数字出现的占比来得到相应类别的占比,所以我们对结果进行数组运算来找出符合要求的图:
首先使用numpy.bincount(pred.flatten())用于统计数组中每个元素出现次数:
# 计算每个类别的像素数,并获取从多到少的排序
class_counts = np.bincount(pred.flatten())
pred是一个二维数组,通过pred.flatten()将其展平成一维数组,然后使用numpy.bincount()对展平后的数组进行统计。
numpy.bincount()返回一个长度为n的数组,其中n是输入数组中的最大元素加1。数组的索引表示元素的值,数组的值表示该元素在输入数组中出现的次数。
接下来,argsort()函数对统计结果进行排序,返回按照元素值从小到大排列的索引数组。然而,为了按照出现次数从大到小的顺序进行排序,我们使用[::-1]来对索引数组进行逆序排列。
sorted_classes = class_counts.argsort()[::-1]
因此,predicted_classes将包含按照元素出现次数从大到小排列的类别索引。这意味着predicted_classes[0]将是出现次数最多的类别索引,predicted_classes[1]将是次多的类别索引,以此类推。
# 打印前四个最常见的类别
for i, c in enumerate(sorted_classes[:4]):
print(f'排序后(占比多的在前)第{i+1}个类别名称是:{names[c+1]},预测的类别代号:{c}')
out:
排序后(占比多的在前)第1个类别名称是:building,预测的类别代号:1
排序后(占比多的在前)第2个类别名称是:car,预测的类别代号:20
排序后(占比多的在前)第3个类别名称是:tree,预测的类别代号:4
排序后(占比多的在前)第4个类别名称是:person,预测的类别代号:12
最后进行if语句的判断就可以进行筛选。
# 检查“建筑物”是否是最常见的类别
building_index = 1
if sorted_classes[0] == building_index:
building_ratio = class_counts[building_index] / pred.size
print(f'“建筑物”类别的像素数占比为{building_ratio:.2%}')
# 如果“建筑物”的比例超过40%,执行相应的操作
if building_ratio > 0.4:
# 执行你想要的操作,例如可视化或保存图像
old_path = file_paths_batch[idx]
new_path = old_path.replace("clip", "image_not_qualified")
shutil.move(old_path,
new_path)
else:
print("照片不符合要求:建筑占比超过40%")
else:
print("照片不符合要求:占比最大的类别不是建筑")
这样我们就能把不符合要求的街景都筛选出来了。因为数据量比较大,如果要获取处理好的街景图像(约79571张图片,36G)。
如何获取街景数据:
请关注微信公众号renhailab,点赞本文之后发送私信:“阿姆斯特丹街景图像”到本公众号,即可获取百度网盘链接。
五、不足之处
5.1 街景图获取的偏差
1)在某些特殊的建筑中,未能正确获取到它的街景图。
比如在被包围的建筑中,街景图代表的是临街建筑,在目前的方法中,最短距离、语义分割的筛选方式都未能将其筛选出来:
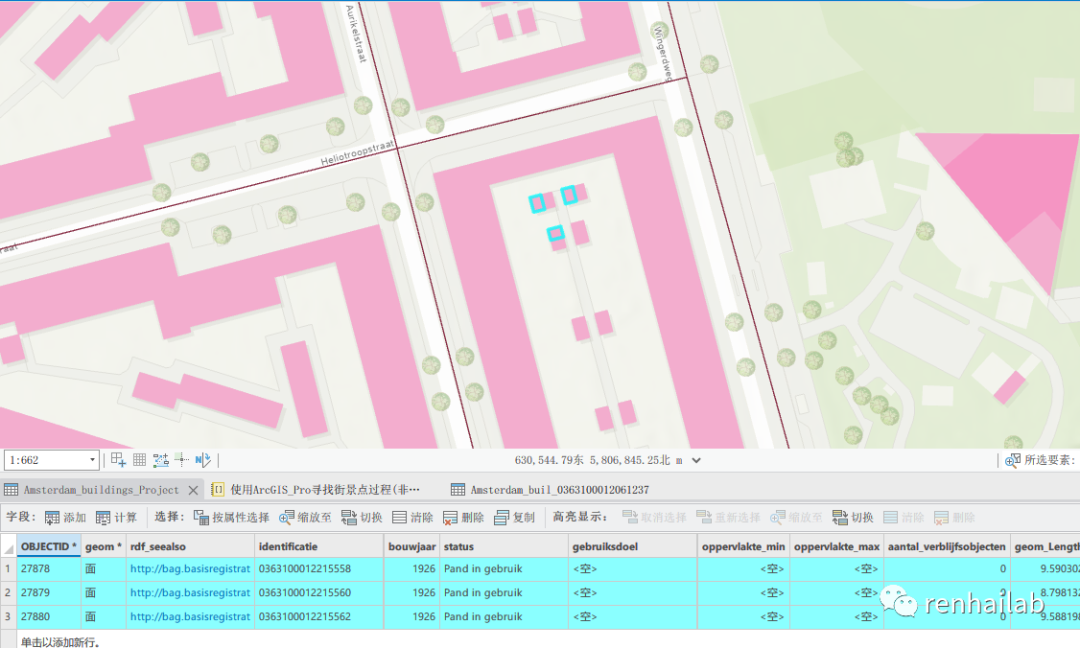
被包围的建筑的街景都是它附近的临街建筑
以下是可能的解决方式:
- 在python中初步处理BAG建筑时,加入建筑物是否在内部的判断,直接忽略掉至少三面都被建筑物包围的建筑。不过这样建筑年代分析不够完整,但是深度学习模型会更准确。
- 或者在ArcGIS Pro中,进行临近分析时,在障碍物字段输入周围的建筑,这样可以考虑到这部分建筑。但是在Arcpy中因为很难使用多线程,所以比较耗时,有时间可以尝试一下。
2) 语义分割删除掉的街景点未重新获取
筛选之后的文件为44447章,占总数的35%,本项目未重新获取,但是论文中似乎大多数建筑都对其进行了预测(图 7),我们需要重新获取同一街景点更早时间的街景图,甚至需要更换街景点,因为距离建筑最近的点不一定是观测建筑的最佳点,这是一个繁重的工作。
上一篇:Part3.获取高质量的阿姆斯特丹建筑立面图像(上)——《通过深度学习了解建筑年代和风格》[12]
下一篇:Part4.对建筑年代进行深度学习训练和预测——《通过深度学习了解建筑年代和风格》[13]
额外阅读
- 一些语义分割模型:
- Deeplab V3+在城市研究中的最新应用:Cites期刊中有一篇论文:《基于深度学习方法分析步行环境对附近商业地产价值的影响》[22]中用到了Deeplab V3+ 模型,说该模型 Cityscapes 数据集进行训练,并在验证中显示出约 81.7% 的模型准确度。在文章的研究进一步基于GSV数据集对模型进行了验证过程。论文作者手动创建了 400 张带注释的 GSV 图像(地面真实数据),识别了由道路、人行道、天空、植被和其他背景组成的五个类别。 Deeplab V3+ 模型的准确度约为 0.914,F1 分数约为 0.919。最后,他们利用该模型检测首尔 GSV 全景图像中的各种街景元素(例如道路、人行道、植被、天空等)(图 3)。
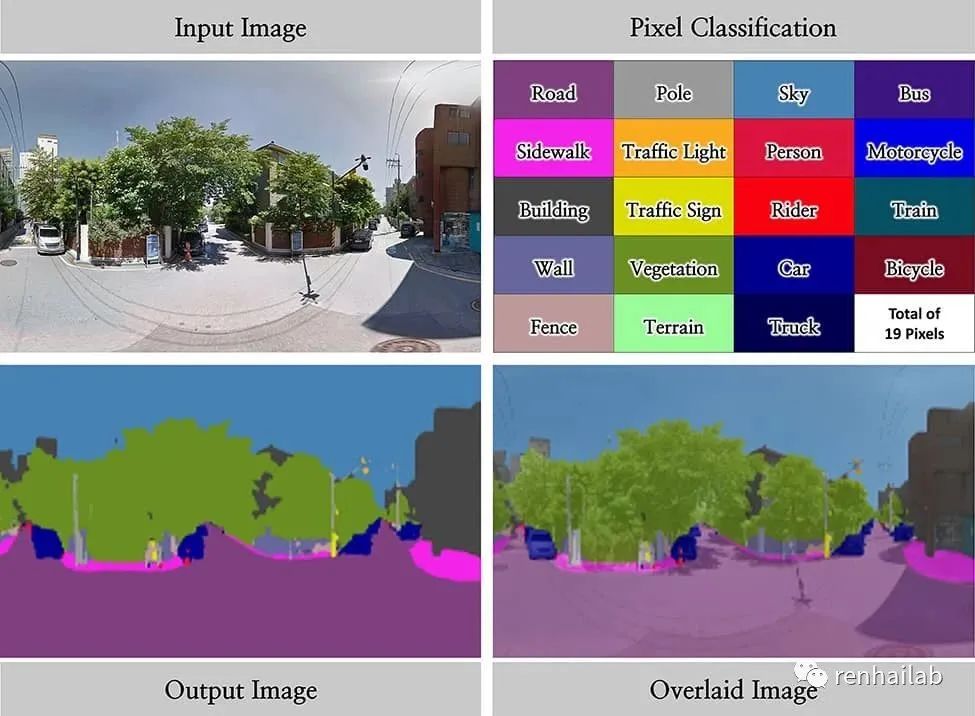
图 3
- Meta[17]发布的segment-anything[18]。
- Ultralytics[19] YOLOv8[20] :一款前沿、最先进(SOTA)的模型,基于先前 YOLO 版本的成功,引入了新功能和改进,进一步提升性能和灵活性。YOLOv8 设计快速、准确且易于使用,使其成为各种物体检测与跟踪、实例分割、图像分类和姿态估计任务的绝佳选择。

Ultralytics YOLO supported tasks
- Deeplab V3+[21]:DeepLabV3+ 是一个语义分割架构,它在 DeepLabV3 的基础上做了多项改进,以增强分割结果。这种架构的设计目标是处理图像语义分割任务。
写在最后
论文引用:
Maoran Sun, Fan Zhang, Fabio Duarte, Carlo Ratti, Understanding architecture age and style through deep learning, Cities, Volume 128, 2022, 103787, ISSN 0264-2751, https://doi.org/10.1016/j.cities.2022.103787.
参考资料
[1]
如何在多平台(win/mac/linux)上安装webdriver并使用selenium: https://cdn.renhai-lab.tech/archives/tools-codespace-selenium#%E4%BA%8C%E3%80%81%E5%AE%89%E8%A3%85chromedriver
[2]
Part3.获取高质量的阿姆斯特丹建筑立面图像(上): https://cdn.renhai-lab.tech/archives/Understanding_architecture_age_and_style_through_deep_learning_part3-1
[3]
Codespace中使用selenium: https://cdn.renhai-lab.tech/archives/tools-codespace-selenium#codespace%E4%B8%AD%E5%A6%82%E4%BD%95%E4%BD%BF%E7%94%A8selenium%E5%91%A2
[4]
pypushdeer: https://github.com/gaoliang/pypushdeer
[5]
semantic-segmentation-pytorch: https://github.com/CSAILVision/semantic-segmentation-pytorch
[6]
http//sceneparsing.csail.mit.edu/: http://sceneparsing.csail.mit.edu/
[7]
Meta: https://ai.meta.com/
[8]
segment-anything: https://github.com/facebookresearch/segment-anything
[9]
Deeplab V3+: https://arxiv.org/abs/1802.02611
[10]
02-快速入门:使用PyTorch进行机器学习和深度学习的基本工作流程(笔记+代码): https://cdn.renhai-lab.tech/archives/DL-02-pytorch-workflow
[11]
05-PyTorch自定义数据集: https://cdn.renhai-lab.tech/archives/DL-05-pytorch-custom_datasets
[12]
Part3.获取高质量的阿姆斯特丹建筑立面图像(上)——《通过深度学习了解建筑年代和风格》: https://cdn.renhai-lab.tech/archives/Understanding_architecture_age_and_style_through_deep_learning_part3-1
[13]
Part4.对建筑年代进行深度学习训练和预测——《通过深度学习了解建筑年代和风格》: https://cdn.renhai-lab.tech/archives/Understanding_architecture_age_and_style_through_deep_learning_part4-1
[14]
我的博客: https://cdn.renhai-lab.tech
[15]
阅读原文: https://cdn.renhai-lab.tech/archives/Understanding_architecture_age_and_style_through_deep_learning_part3-2
[16]
本仓库的issue页面: https://github.com/renhai-lab/Paper_Replication--Understanding-architecture-age-and-style-through-deep-learning/issues
[17]
Meta: https://ai.meta.com/
[18]
segment-anything: https://github.com/facebookresearch/segment-anything
[19]
Ultralytics: https://ultralytics.com/
[20]
YOLOv8: https://github.com/ultralytics/ultralytics
[21]
Deeplab V3+: https://arxiv.org/abs/1802.02611
[22]
《基于深度学习方法分析步行环境对附近商业地产价值的影响》: https://doi.org/10.1016/j.cities.2023.104628