Power BI:优化筛选条件

1 定义优化策略2 优化DAX表达式中的瓶颈2.1 优化筛选条件2.1.1 优化前2.1.2 优化后2.1.3 小结
1 定义优化策略
每次优化DAX代码时都应遵循以下步骤:
- 识别出要优化的单个DAX表达式;
- 创建一个可以重现问题的测试查询;
- 分析用时信息(Server Timings)和查询计划(Query Plan)信息。
- 识别存储引擎或公式引擎中的瓶颈。
- 修改代码并重新运行测试查询。
2 优化DAX表达式中的瓶颈
存储引擎执行时间较长通常是由以下一个或多个原因造成的。
- 扫描时间较长;
- 大基数;
- 频繁使用
CallbackDataID函数; - 大型物化。
2.1 优化筛选条件
示例:观察下图(图1)的报表,展示了每个产品品牌的销售总额(Sales Amount)与大于$1000的销售总额(Big Sales Amount)。

Sales Amount度量值定义如下:
Sales Amount = SUMX ( Sales, Sales[Quantity] * Sales[Net Price] )2.1.1 优化前
Big Sales Amount度量值中的筛选器参数涉及两列,一种简单的定义筛选器的方法是直接在整个Sales表上使用筛选器。下面的查询只计算报表中的Big Sales Amount度量值。
DEFINE
MEASURE Sales[Big Sales Amount (slow)] =
CALCULATE (
[Sales Amount],
FILTER ( Sales, Sales[Quantity] * Sales[Net Price] > 1000 )
)
EVALUATE
SUMMARIZECOLUMNS (
ROLLUPADDISSUBTOTAL ( 'Product'[Brand], "IsGrandTotalRow" ),
"Big_Sales_Amount", 'Sales'[Big Sales Amount (slow)]
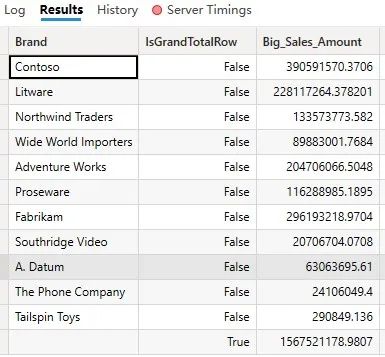
)查询结果如下图(图2):
生成的Server Timings结果如下图(图3)所示。
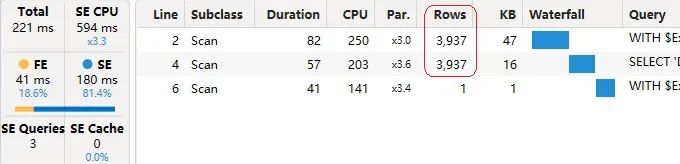
因为FILTER函数迭代了一个表,所以这个查询生成的数据缓存比实际需要的要大。查询结果只显示了11个品牌和1个总计行。尽管如此,查询计划预估前两个数据缓存返回3937行,这与下图(图4)显示的Query Plan窗格中的数字相同。

公式引擎接收的数据缓存要比查询结果所需的缓存大得多,因为筛选条件中还包括了两个额外的列。图3中第2行的xmSQL查询如下图(图5)所示:

CALCULATE函数的表筛选器会在查询计划中导致这种副作用,因为筛选器的语义包括Sales表扩展表的所有列。
2.1.2 优化后
这里使用列筛选器对度量值进行优化。因为筛选表达式使用了两列,所以行上下文需要一个只包含这两列的表,作为更高效的CALCULATE函数的筛选器参数。下面的查询实现了列筛选器,并且加入KEEPFILTER函数,保持与上一版本相同的语义。
DEFINE
MEASURE Sales[Big Sales Amount (fast)] =
CALCULATE (
[Sales Amount],
KEEPFILTERS (
FILTER (
ALL ( Sales[Quantity], Sales[Net Price] ),
Sales[Quantity] * Sales[Net Price] > 1000
)
)
)
EVALUATE
SUMMARIZECOLUMNS (
ROLLUPADDISSUBTOTAL ( 'Product'[Brand], "IsGrandTotalRowTotal" ),
"Big_Sales_Amount", 'Sales'[Big Sales Amount (fast)]
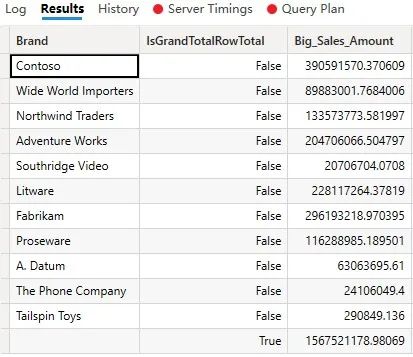
)查询结果如下图(图6)所示:
生成的Server Timings结果如下图(图7)所示。
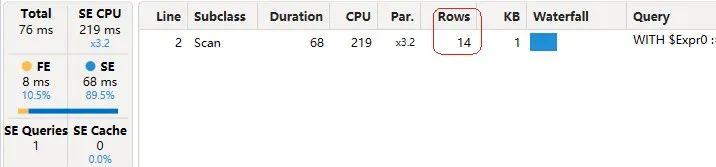
这个DAX查询运行得更快,但更重要的是,结果只使用了一个数据缓存,包括总计行。图7中第2行物化的缓存只返回大约14行,而在下图(图8)所示的Query Plan窗格中,实际统计到的只有11行。
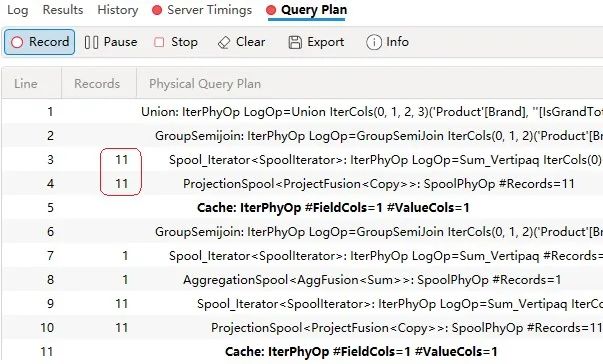
采用这种优化措施的依据是查询计划可以在存储引擎中创建更高效的计算,从而避免使用表筛选器的语义向公式引擎返回额外的列。下图(图9)是图7中第2行的xmSQL查询:

数据缓存中不再包含Quantity列和Net Price列,它的基数对应DAX结果的基数。这是理想条件下的最小物化。使用列而不是使用表所为筛选条件是实现这一效果的关键步骤。
2.1.3 小结
(1)在可能的情况下,CALCULATE/CALCULATETABLE函数的筛选器参数应该始终筛选列,而不是表。
(2)应该始终关注存储引擎查询返回的行。当它们的数量远远大于DAX查询结果中包含的行数时,这其中可能会包含一些额外的计算开销。表筛选器是导致过度物化的最常见原因之一,但它们并不是造成公式性能不佳的唯一原因。
视频讲解:
参考资料:
[1] DAX权威指南(https://www.powerbigeek.com/definitive-guide-to-dax-cn/)