分享一个快速获取网页表格的好方法

分享一个快速获取网页表格的好方法
哈喽,大家好,我是老表,学 Python 编程,找老表就对了。
大家好,我打算每日花1小时来写一篇文章,这一小时包括文章主题思考和实现,今天是日更的第7天,看看能不能被官方推荐。(帮我点点赞哦~)
今天的主题是:分享一个快速获取网页表格的好方法,如果这篇文章对你有所帮助或者你觉得写的还行,欢迎你点赞/分享给你的朋友、她、他,一起成长。
也欢迎大家留言,说说自己想看什么主题的Python文章,留言越具体,我写的越快,比如留言:我想看Python 自动操作Excel 相关文章。
如果你有具体的需求想通过使用Python实现自动化,那将更好,欢迎私聊我微信,一起交流探讨。
直接上货
以获取2023福布斯中国30 Under 30榜单为例子,数据页面地址:
“https://www.forbeschina.com/lists/1815 ”
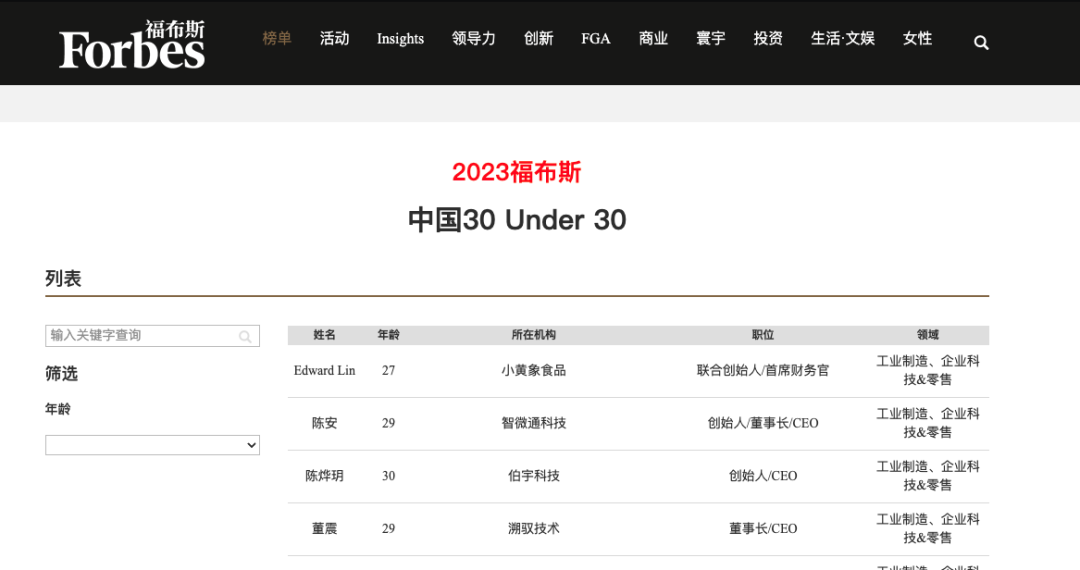
正常我们要获取这个页面数据可能会使用 requests 先获取页面内容,然后使用 xpath 或者什么方式去提取页面中的表格内容,需要一步步分析,看每个元素 xpath 寻找规律,然后遍历获取,流程有点复杂,特别对于大部分用户只是想获取数据,并不想深入研究爬虫相关知识。
这里给大家推荐我之前分享过的pandas 的 read_html 或者 read_table方法直接从网页中提取表格数据。
使用方法特别简单,先安装好 pandas,这个方法还依赖一个 lxml 库,也一起安装下,安装指令如下图:
pip install pandas lxml requests
【推荐】如果你第一次了解Python,可以看我写的更详细的教程,Linux/Mac/Windows 配置Python环境方法我都写到这里了点击查看各系统Python环境配置教程

环境配置好直接运行以下代码。
import pandas as pd
df = pd.read_html("https://www.forbeschina.com/lists/1815")
df.to_csv(r'html_table_data.csv', encoding='utf_8_sig', index=False)
你可能会遇到这个错误,看着是网站证书验证失败导致的。

一般网站应该不会出现上面这个错误,比如:
“https://news.uuu9.com/djws/rank/201907/ ”

“https://www.phb123.com/renwu/fuhao/shishi.html ”
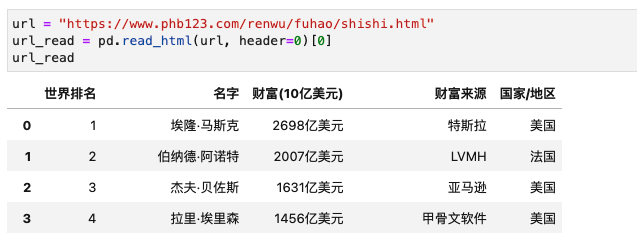
那遇到这种问题怎么解决呢?read_html 函数没有跳过证书验证的方法,但是 requests 是有对应方法的,有一个思路是:先使用 requests 获取网页源码存入 html文件,然后使用 read_html 读取解析 html文件。
代码如下:
import pandas as pd
import requests
# requests 获取页面数据
r = requests.get("https://www.forbeschina.com/lists/1815", verify=False)
# 数据存入本地
data_path = "test.html"
with open(data_path, mode="w", encoding="utf_8_sig") as f:
f.write(r.text)
# 解析数据
url_read = pd.read_html(data_path)[0]
url_read.to_csv(r'html_table_data.csv', encoding='utf_8_sig', index=False)
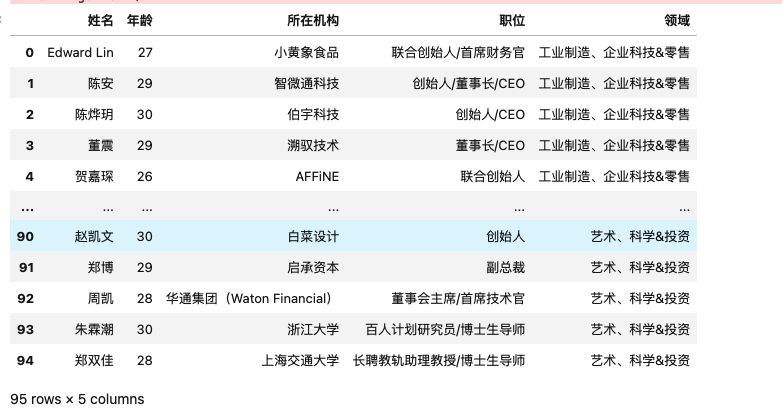
简单分析数据
导包和读取数据:
import matplotlib.pyplot as plt
import pandas as pd
# 读取数据
df = pd.read_csv("./html_table_data.csv")
- 年龄
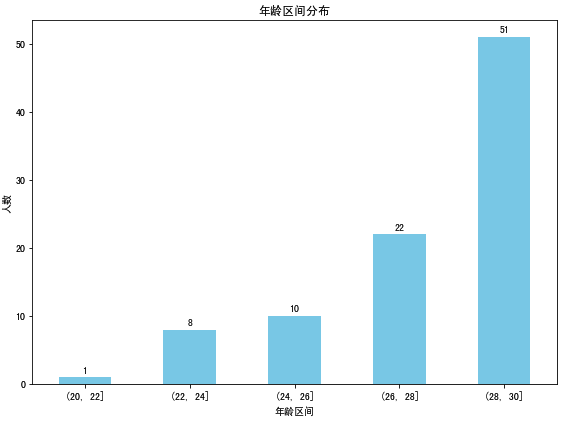
# 创建年龄区间
age_bins = [20, 22, 24, 26, 28, 30]
# 使用pandas.cut将年龄分配到区间中
age_groups = pd.cut(df['年龄'], bins=age_bins)
# 统计每个年龄区间内的人数
age_counts = age_groups.value_counts().sort_index()
# 创建柱状图
plt.figure(figsize=(8, 6))
ax = age_counts.plot(kind='bar', color='skyblue')
plt.title('年龄区间分布')
plt.xlabel('年龄区间')
plt.ylabel('人数')
plt.xticks(rotation=0) # 不旋转横坐标标签
# 在柱子上显示数量
for i, v in enumerate(age_counts):
ax.text(i, v + 0.5, str(v), ha='center', va='bottom', fontsize=10)
# 显示柱状图
plt.tight_layout()
plt.show()
- 领域
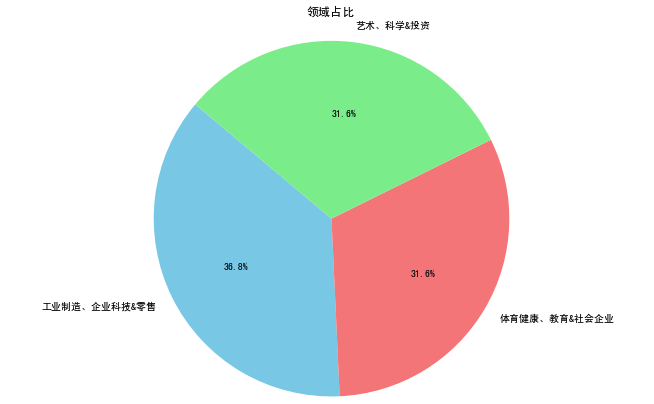
# 统计每个领域的数量
domain_counts = df['领域'].value_counts()
# 创建饼图
plt.figure(figsize=(8, 6))
plt.pie(domain_counts, labels=domain_counts.index, autopct='%1.1f%%', startangle=140, colors=['skyblue', 'lightcoral', 'lightgreen', 'lightsalmon', 'lightpink'])
plt.title('领域占比')
# 显示饼图
plt.axis('equal') # 使饼图成为一个正圆
plt.tight_layout()
plt.show()
- 所在机构

from wordcloud import WordCloud
import jieba
# 将所在机构的数据合并成一个字符串
organizations_text = ' '.join(df['所在机构'])
# 使用jieba分词处理中文文本
seg_list = jieba.cut(organizations_text, cut_all=False)
cut_text = ' '.join(seg_list)
# 创建词云并设置中文字体
font_path = './SimHei.ttf' # 根据你的系统和字体路径自行设置
wordcloud = WordCloud(width=800, height=400, background_color='white', font_path=font_path).generate(cut_text)
# 显示词云图
plt.figure(figsize=(10, 6))
plt.imshow(wordcloud, interpolation='bilinear')
plt.title('所在机构词云')
plt.axis('off') # 隐藏坐标轴
plt.tight_layout()
plt.show()
如果觉得文章还不错,记得点赞转发收藏。