打造企业级自动化运维平台系列(六):Jenkins Pipeline 入门及使用详解
打造企业级自动化运维平台系列(六):Jenkins Pipeline 入门及使用详解

Jenkins Pipeline
作为一种流行的持续集成和交付工具,Jenkins有多种方式来实现交付流水线。其中,Jenkins Pipeline是一种比较流行的方式,它提供了一个DSL(Domain Specific Language 的缩写,中文翻译为:领域特定语言)来描述交付流水线。
- 官方:Pipeline Syntax (jenkins.io)
什么是 Jenkins Pipeline
Jenkins Pipeline是一种基于Groovy编写的DSL,它可以描述交付流水线。Pipeline支持串行和并行的执行,可以将多个任务组合成一个流水线。Pipeline也支持将上下文传递给不同的阶段,使得阶段之间的数据共享变得更加容易。
Pipeline 是Jenkins 2.X 的最核心的特性,帮助 Jenkins 实现从CI 到 CD 与 DevOps的转变。
Pipeline 是一组插件,让 jenkins 可以实现持续交付管道的落地和实施。持续交付管道是将软件从版本控制阶段到交付给用户/客户的完整过程的自动化表现。
Pipeline提供了三种编写Pipeline的方式:
- Declarative Pipeline:是基于YAML编写的声明式语言,它可以更容易地描述交付流水线。
- Scripted Pipeline:是基于Groovy编写的脚本语言,它是一种灵活的方式来描述交付流水线。
- Jenkinsfile:是一种将Pipeline脚本保存为Jenkins源代码管理系统中的文件的方式。
Pipeline任务
创建Pipeline任务
新增任务,选择流水线
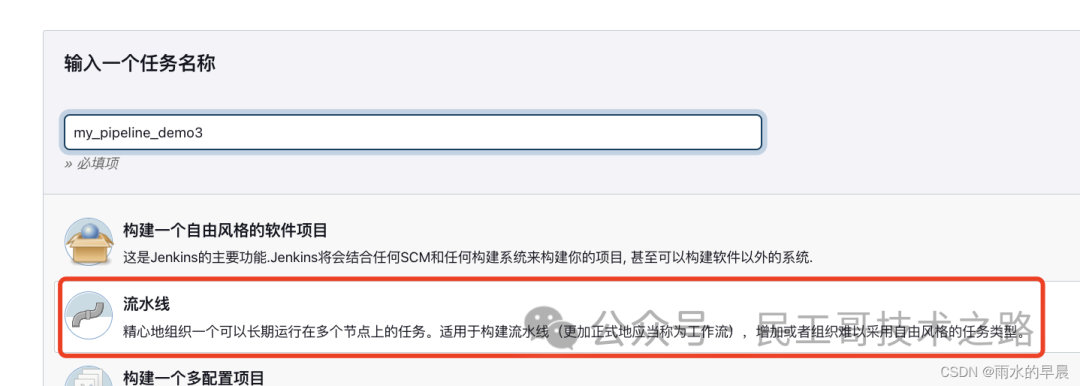
Pipeline定义有两种方式:
- 一种是Pipeline Script ,是直接把脚本内容写到脚本对话框中;
- 另一种是 Pipeline script from SCM (Source Control Management–源代码控制管理,即从gitlab/github/git上获得pipeline脚本–JenkisFile)
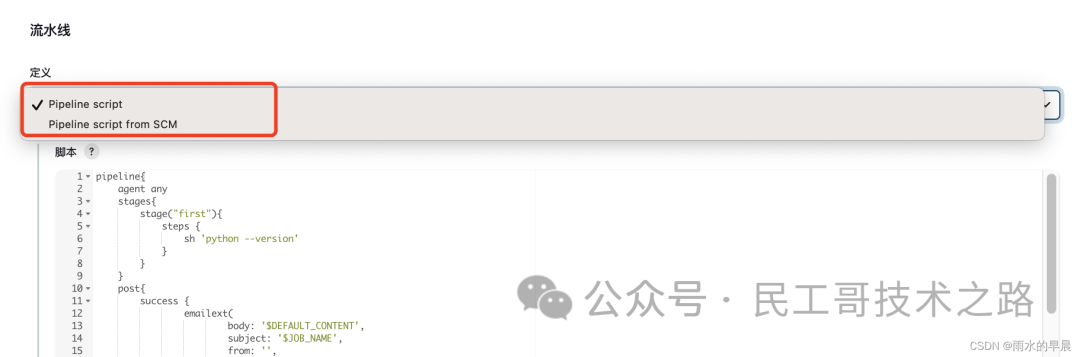
Pipeline Script 运行任务
- 脚本如下
pipeline{
agent any
stages{
stage("first"){
steps {
echo 'hello world'
}
}
stage("run test"){
steps {
echo 'run test'
}
}
}
post{
always{
echo 'always say goodbay'
}
}
}
脚本中定义了2个阶段(stage):first和run test;post是jenkins完成构建动作之后需要做的事情。
运行任务,可以看到分为3个部分,如下图所示:

Pipeline script from SCM 通过代码库运行任务
将pipeline代码(Jenkinsfile)保存到代码库中,然后通过指定代码位置(脚本位置)的方式来运行pipeline任务。
创建Jenkinsfile,由Groovy语言实现。一般是存放在项目根目录,随项目一起受源代码管理软件控制。
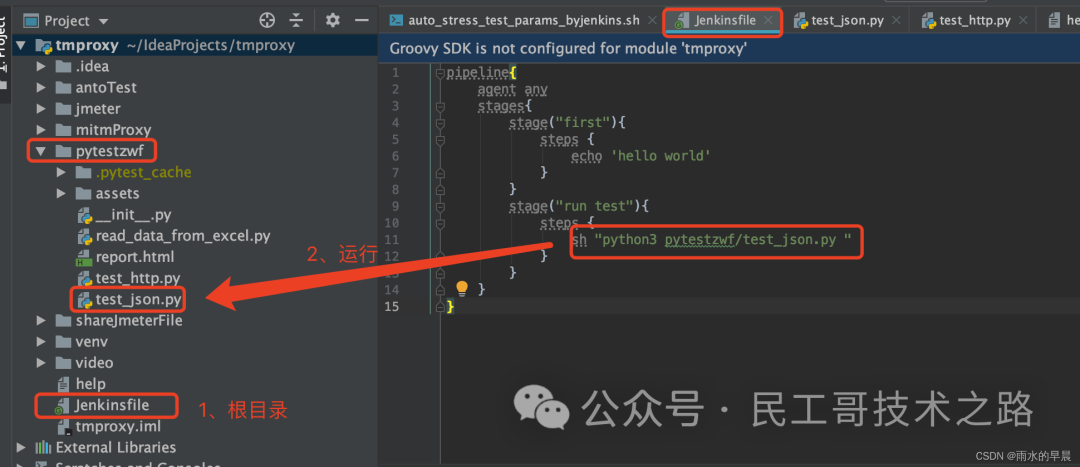
- Jenkinsfile :创建在根目录
- 脚本的第二stage 是执行pytestzwf文件下的test_json.py脚本
- 将项目提交到代码库。
在 job(任务)中配置Pipeline script from SCM
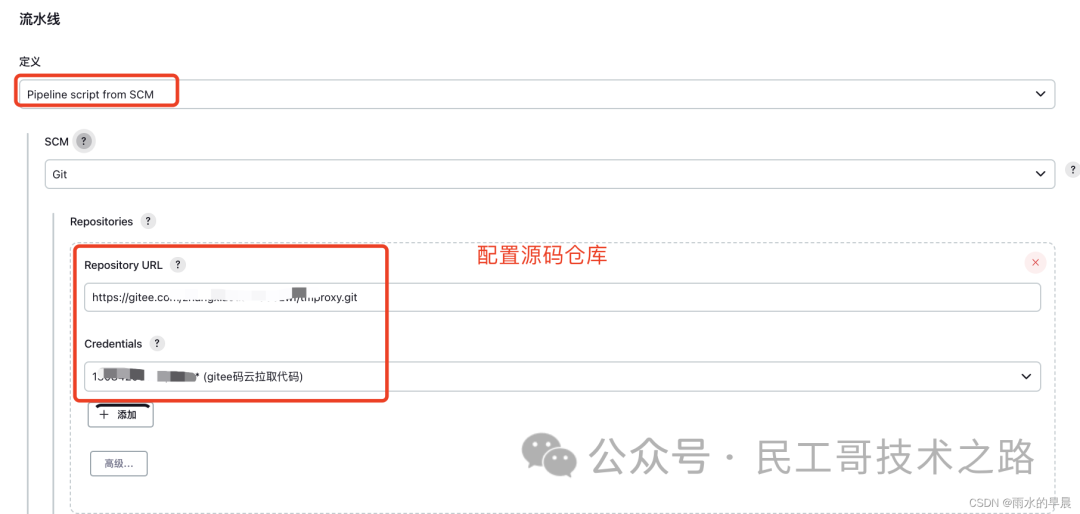

运行任务,查看结果:

Jenkinsfile
Jenkinsfile 支持两种语法形式:
- Declarative pipeline – 在pipeline v2.5 之后引入,结构化方式,比较简单,容易上手。这种类似于我们在做自动化测试时所接触的关键字驱动模式,只要理解其定义好的关键词,按要求填充数据即可。入门容易,但是灵活性欠缺。
- Scripted pipeline – 基于grjoovy的语法,相较于Declarative,扩展性比较高,好封装,但是有些难度,需要一定的编程工具。
Declarative pipeline(声明式)流水线
- 必须包含在一个pipeline块内,具体来说是:pipeline{}
- 基本的部分 是“steps”,steps即告诉Jenkins要做什么
- 语句分类具体包含 【Sections,Directives,Steps,赋值】等几大类
声明式核心概念
- 1.pipeline:声明其内容为一个声明式的pipeline脚本;
- 2.agent:执行节点(job运行的slave或者master节点);
- 3.stages:阶段集合,包裹所有的阶段(例如:打包,部署等各个阶段)
- 4.stage:阶段,被stages包裹,一个stages可以有多个stage;
- 5.steps:步骤,为每个阶段的最小执行单元,被stage包裹;
- 6.post:执行构建后的操作,根据构建结果来执行对应的操作;
agent使用
基本介绍
agent:即定义pipeline执行节点,是必须出现的指令。
参数:
-- any:可以在任意agent上执行pipeline
-- none:pipeline将不分配全局agent,每个stage分配自己的agent
-- label:指定运行节点的Label
-- node:自定义运行节点配置
-指定label
-指定customWorkspace
-- docker:控制目标节点上的docker运行相关内容
代码示例
# 指定运行节点为slave,工作区间为mikasaWorkspace
pipeline{
agent{
node{
label "slave"
customWorkspace "mikasaWorkspace"
}
}
}
stages,stage,steps 使用
基本介绍
stages: 包含一个或多个stage的序列,Pipeline的大部分工作在此执行。
- 他是必须出现的指令
- 无参数
- 并且每个pipeline代码区间中必须只有一个stages
stage: 包含在stages中,pipeline完成的所有实际工作都需要包含到stage中。
- 他是必须出现的指令
- 无参数
- 需要定义stage的名字
steps: 包含在stage代码区间中
- 必须出现的指令
- 无参数
- 具体执行步骤,包含在stage代码区间中
代码示例
# 外层必须包裹一个stages
# stage:定义一个步骤的名字(提交git源码)
# steps:里面写具体执行步骤(输出更新代码,git源码地址)
stages{
stage('git pull source code')
steps{
echo "updated code"
git "https://github.com/Burden1/Mikasa_pipeline_demo.git"
}
}
post使用
基本使用
post:即定义Pipeline或stage运行结束时的操作,不是必须出现的指令,简单来说,他就是【构建后操作】。
参数:
-- always:无论Pipeline运行的完成状态如何都会运行
-- changed:只有当前pipeline运行的状态与先前完成的pipeline的状态不同时,才能运行
-- failure:只有当前pipeline处于"【失败】"状态时才能运行
-- success:只有当前pipeline处于"【成功】"状态时才能运行
-- unstable:只有当前pipeline处于"【不稳定】"状态时才能运行
-- aborted:只有当前pipeline处于"【中止】"状态时才能运行
代码示例
# 如果前面的stage操作都运行成功后,就会执行success里面的操作,否则不进入
# always即无论前面的stage操作成功与否,每次执行都会输出'always say goobye'
post{
success{
echo 'goodbye mikasa'
sleep 2
}
always{
echo 'always say goobye'
}
}
environment使用
基本使用
environment: 定义pipeline或stage运行时的环境变量
- 无参数
- 不是必须出现的指令
代码示例
# 环境里面定义一个mikasa变量
# stages里面输出mikasa,得到结果即:hello mikasa
environment{
mikasa = 'hello mikasa'
}
stages {
stage('print enviroment'){
steps{
echo mikasa
}
}
}
options使用
基本使用
options: 定义pipeline的专有属性,不是必须出现的指令
参数
-- buildDiscarder:保持构建的最大个数
-- disableConcurrentBuilds:不允许并行执行pipeline任务
-- timeout:pipeline超时时间
-- retry:失败后,重试整个pipeline的次数
-- timestamps:预定义由pipeline生成的所有控制台输出时间
-- skipStagesAfterUnstable:一旦构建状态进入了“Unstable”状态,就跳过此stage
代码示例
#
# 若失败,则重试5次
options{
timeout(time:30,unit:'SECONDS')
buildDiscarder(logRotator(numToKeepStr: '2'))
retry(5)
}
parameters使用
基本使用
parameters: 定义pipeline的专有参数列表
- 不是必须出现的指令
- 支持数据类型:booleanParam,choice,credentials,file,text,password,run,string
- 类似参数化构建的选项
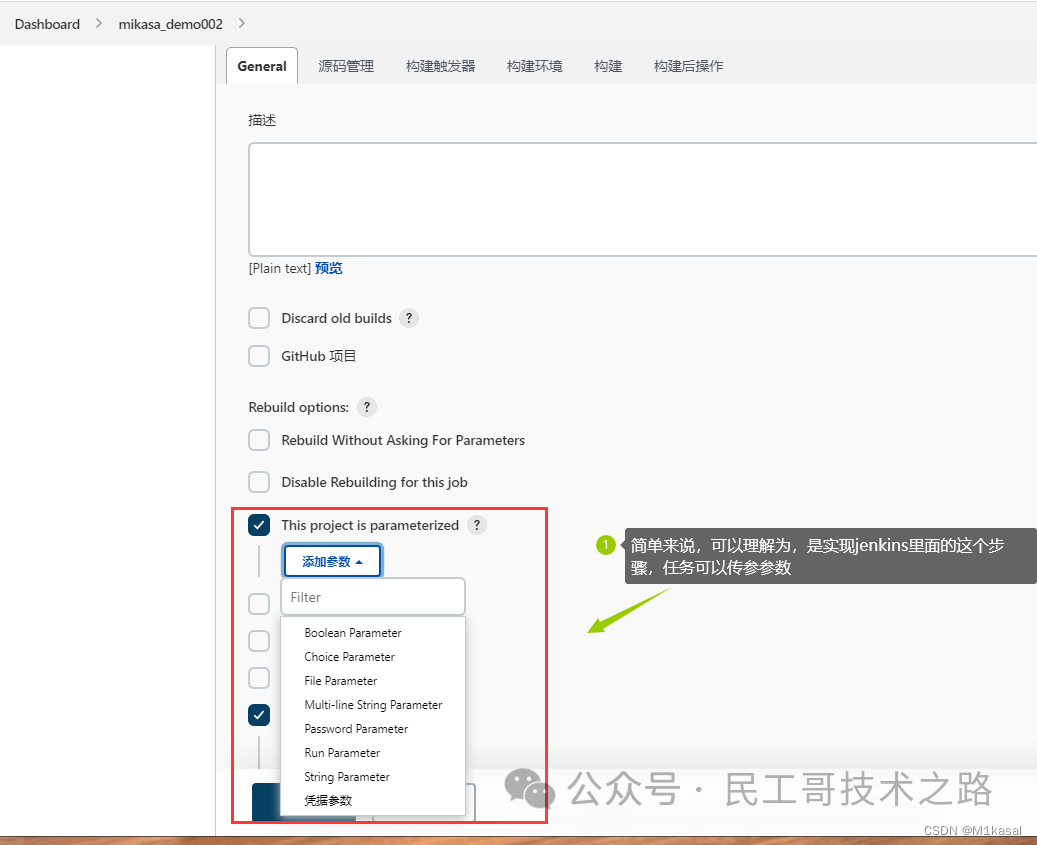
代码示例
# 定义三个string类型的参数
# 步骤里面输出参数
parameters{
string(name: 'PERSON',defaultValue:'Jenkins',description:'输入的文本参数')
}
stages {
stage{
steps{
echo "HELLO ${params.PERSON}"
}
}
}
triggers使用
基本使用
triggers: 定义了pipeline自动化触发的方式
- 不是必须出现的指令
参数
-- cron: 接受一个cron风格的字符串来定义pipeline触发的常规间隔
-- pollSCM: 接受一个cron风格的字符串来定义Jenkins检查SCM源更改的常规间隔;如果存在新的更改,则pipeline将被重新触发
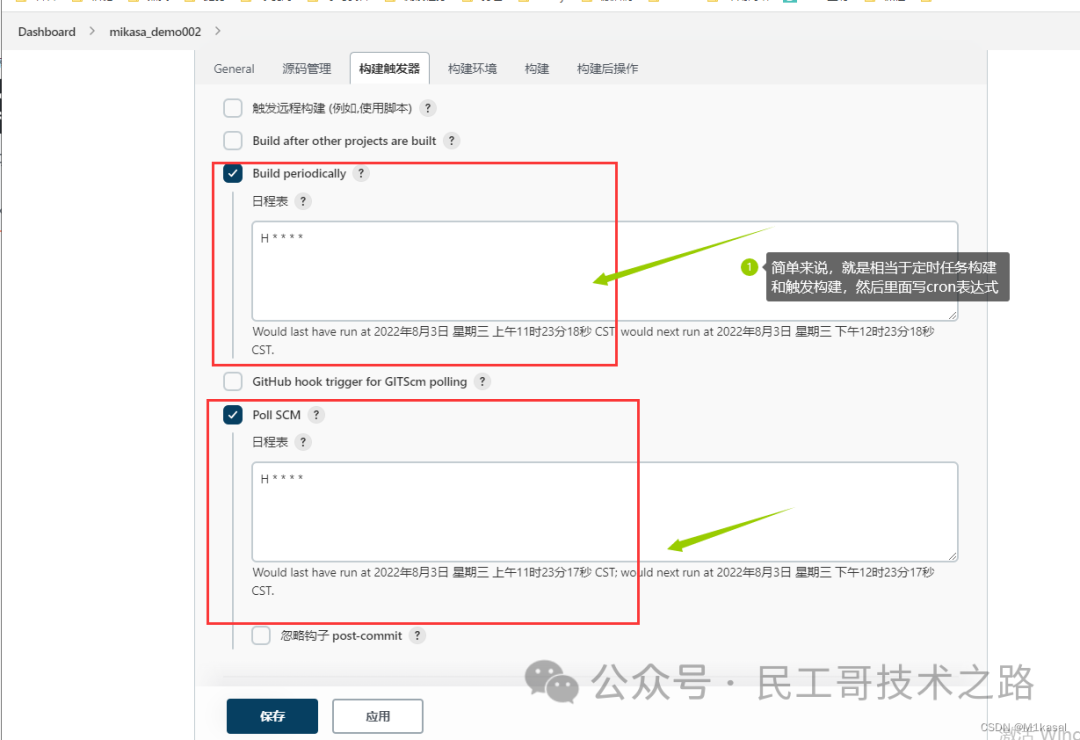
代码示例
# 每个小时构建一次
triggers{
pollSCM('H * * * *')
}
Scripts Pipeline(脚本式)流水线
Scripts Pipeline:是基于groovy语法定制的一种DSL语言
- 灵活性更高
- 可扩展性更好
- 与Declarative pipeline 程序构成方式有不同之处,基本语句也有相似之处
流程控制之if/else使用
# node包裹起来,里面定义stage,然后判断当前分支是不是master分支,对应输出结果
node {
stage('Example'){
if (env.BRANCH_NAME) == 'master'{
echo 'I ONLY EXECUTE ON THE MASTER BRANCH'
}else{
echo 'i execute elsewhere'
}
}
}
流程控制之try/catch使用
# node包裹起来,然后里面进行try catch,其实使用和java差不多
node{
echo "this is test stage which run on the slave agent"
try{
echo "this is in the try block"
}catch(exc){
echo "Something failed,i am in the catch block"
}finally{
echo "Finally,i am in the finally block"
}
}
Declarative pipeline和Scripted pipeline的比较
共同点
两者都是pipeline代码的持久实现,都能够使用pipeline内置的插件或者插件提供的steps,两者都可以利用共享库扩展。
区别
两者不同之处在于语法和灵活性。
Declarative pipeline:对用户来说,语法更严格,有固定的组织结构,容易生成代码段,使其成为用户更理想的选择。
Scripted pipeline:更加灵活,因为Groovy本身只能对结构和语法进行限制,对于更复杂的pipeline来说,用户可以根据自己的业务进行灵活的实现和扩展。
优化交付流水线性能
随着交付流水线的复杂度越来越高,需要优化交付流水线的性能成为了一个时刻需要关注的问题。
下面是一些常见的优化策略:
并行执行
使用并行执行可以大大缩短交付流水线的执行时间。Pipeline可以很容易地支持并行执行。
例如,我们可以将测试阶段并行执行:
stage('Test') {
parallel (
"test1" : { sh 'mvn test -Dtest=Test1' },
"test2" : { sh 'mvn test -Dtest=Test2' },
"test3" : { sh 'mvn test -Dtest=Test3' }
)
}
在这个示例中,我们使用了 parallel块 来并行执行。
在parallel块内,我们定义了三个分支来执行测试。分支的名称是任意的,它们将被用作日志输出。每个分支都有自己的命令来执行测试。
缓存依赖项
使用缓存可以避免在每个阶段中重新下载依赖项。
例如,如果一个项目使用Maven,我们可以在build阶段前缓存Maven仓库:
pipeline {
agent any
stages {
stage('Build') {
steps {
script {
def mvnHome = tool 'Maven-3.8.2'
env.M2_HOME = mvnHome
sh "${mvnHome}/bin/mvn -B -Dmaven.repo.local=$HOME/.m2/repository clean package"
}
}
}
}
post {
success {
cleanWs()
}
}
}
在这个示例中,我们使用了Maven插件的tool方法来定义Maven的版本。然后,我们将M2_HOME设置为我们定义的Maven的路径。
最后,我们在Maven命令中使用-Dmaven.repo.local选项来指定Maven仓库的位置。
删除不必要的阶段
一些阶段可能不必要并且会大大降低交付流水线的性能。
例如,我们可能只需要在提交代码时执行 build和 test 阶段,而不是在每次构建时执行这些阶段。
示例:
pipeline {
agent any
stages {
stage('Build') {
when {
changeset "src/**"
}
steps {
sh 'mvn clean install'
}
}
stage('Test') {
when {
changeset "src/**"
}
steps {
sh 'mvn test'
}
}
stage('Deploy') {
when {
changeset "src/**"
}
steps {
sh './deploy.sh'
}
}
}
post {
success {
cleanWs()
}
}
}
在这个示例中,我们在build、test和deploy阶段之前添加了when块。当检测到代码库中的更改时,这些阶段才会被执行。
总结
Scripted Pipeline 和 Declarative Pipeline 两种流水线定义的主要区别在于语法和灵活性上。
- Declarative Pipeline 语法要求更严,需使用 Jenkins 预定义的DSL 结构,使用简单;
- Scripted Pipeline 受限很少,限制主要在 Groovy 的结构和语法;
大家可以根据个人或企业的情况选择两种方式,比如如果公司没有 Groovy 技术栈,可以考虑直接使用 Declarative Pipeline, 学习曲线低,可以快速上手;
如果需要对公司的业务场景灵活配置或者对 Groovy 熟悉,那么 Scripted Pipeline 是一个不错的选择;
参考来源:https://blog.csdn.net/Makasa/article/ details/126136257 https://rainymorning.blog. csdn.net/article/details/127284810