我攻克的技术难题 - 如何快速搭建Hadoop3集群
原创我攻克的技术难题 - 如何快速搭建Hadoop3集群
原创
前言
距离唯一一次搭建Hadoop集群,已是六年有余。那时候大数据的学习资料还是我从某宝25买来的,如今大数据已遍地开花。最近想写一些关于大数据的东西,例如Spark、flink等,想放在Yarn上跑,所以就从Hadoop的搭建开始写起。
关于Hadoop
刚接触Hadoop的时候,还是Hadoop1,如今已经是Hadoop3,在搭建的过程中也多了一些配置。本次使用的是Apache Hadoop,在生产中一般用国内大厂的Hadoop,或者CDH、HDP(2019年合并成CDP)版本的Hadoop。
我们生产中有两个Hadoop集群,规模在1200台主机左右,是基于Hadoop3的HDP版本。为什么不选择Apache版本的,我个人认为有几个原因:
1. 安装
HDP有一个后台管理平台,叫Ambari 。首先具有安装导向的作用,在页面安装时直接将所有IP/Hosts填入,然后选择每个节点安装哪些组件。不用像Apache Hadoop一样,手动分发安装包到每个节点安装。
2. 集成
HDP将所有软件都放在了一个包里,例如Kafka、Spark、Flume、Hadoop等,都做了版本的适配,不用自己去各个网站下载了。
3. 运维
Apache Hadoop只有一个HDFS和Yarn的web页面,来查看节点的信息。当某个节点发生故障的时候,只能登录到主机上查看日志,然后手动启停服务。
而Ambari提供了节点服务启停、Hadoop的dashboard、以及节点状态的监控等功能。
既然这么好,为什么这里我不使用HDP?
原因就是:HDP的软件包太大了。我之前用docker搭建过HDP版本的Hadoop,需要下载四个软件包,大概12G左右,而Apache只有几百MB。而且在安装过程中,Ambari会启动很多进程,进行Ambari Server与Agent的通信,就会导致电脑很卡。如果只是测试,那就使用HDP
环境配置
环境配置主要是对节点的配置,包括网络、防火墙等。
1. 安装虚拟机
下载Centos镜像,我选择的版本是7,在VMware中进行虚拟机的安装配置。
2. 配置虚拟机网络
在VMware中,通过虚拟机网络编辑器可以看到NAT网络分配的子网,我这里分配的是192.168.227网段,所以我将这个主机的节点的IP配置为192.168.227.100。
同时在修改网络配置时,要将BOOTPROTO从DHCP修改为static。
vi /etc/sysconfig/network-scripts/ifcfg-ens33 然后重启网络:
systemctl restart network3. 分配节点IP,设置host
我这里分配了三个节点,一个master主节点,两个slave从节点。我这里的master为192.168.227.100,slave1为192.168.227.101,slave2为192.168.227.102,在/etc/hosts中添加host映射:
192.168.227.100 master
192.168.227.101 slave1
192.168.227.102 slave24. 关闭并禁用防火墙
一定要关闭并禁用防火墙,否则集群之间就会出现通信问题。
systemctl stop firewalld
systemctl disable firewalld
搭建Hadoop
我的搭建思路就是先配置一台master主节点,各种配置完成之后,再克隆主节点,生成两个slave。在HDFS中,master是NameNode,slave是DataNode。在Yarn中,master是ResourceManager,slave是NodeManager。
接下来就是对master节点进行配置。
1. Hadoop配置
下载Aapche Hadoop 3.3.6版本的安装包,然后进行配置然后分别对core-site.xml、hdfs-site.xml、yarn-site.xml以及mapred-site.xml进行核心参数的配置 ,然后把从节点配置在workers(之前叫做slaves)中。
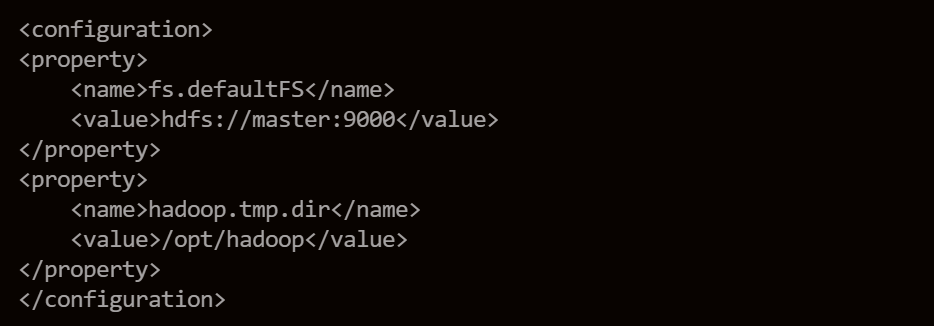
core-site.xml
主要配置fs.defaultFS参数,来确定DataNode和NameNode之间的通信。这样我们在客户端使用hdfs等命令的时候,就不用指定IP和端口了。
hdfs-site.xml
指定HDFS文件系统的配置,例如副本数、数据块大小、NameNode元数据目录、DataNode数据目录以及webui路径等。

yarn-site.xml
主要指定Resourcemanager的地址,后面大部分都是默认配置。

这里最值得提的就是yarn.nodemanager.aux-services,默认值是mapreduce_shuffle,只支持运行MapReduce程序,如果想要支持spark,修改成mapreduce_shuffle,spark2_shuffle即可。
mapred-site.xml
通过配置mapreduce.framework.name为yarn,MapReduce任务才能提交到yarn集群上。
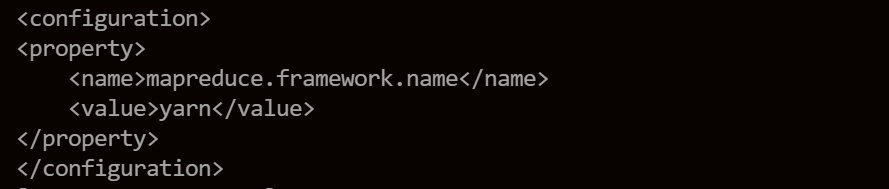
除了yarn之外,还可以设置为local(默认)、classic。
workers
之前叫slaves,现在改成workers,将从节点的host填入即可。

hadoop-env.sh
之前Hadoop都没有这个环境脚本的配置,现在需要配置。
export JAVA_HOME=/root/app/jdk1.8.0_201
export HDFS_SECURE_DN_USER=root
export HDFS_NAMENODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
#export HDFS_DATANODE_SECURE_USER=root
export HDFS_DATANODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root主要是配置HDFS和YARN的启动用户,默认是hdfs和yarn,不配置的话用root启动就会报错。
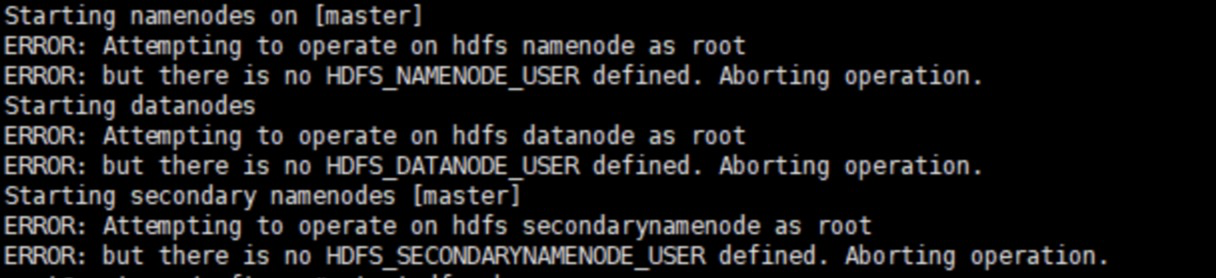
上面的配置我用#注释了一个,如果使用这个配置DataNode将会启动失败,使用下面不带SECURE的DataNode才能启动成功。
3. 配置JDK
下载Linux版本JDK,解压到app目录下,在/etc/profile中进行配置。
export JAVA_HOME=/root/app/jdk1.8.0_201
export HADOOP_HOME=/root/app/hadoop-3.3.6
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin 
4. 拷贝从节点
将master关机,用master克隆出两个从节点slave1和slave2。
修改slave1和slave2的网络为101和102.
vi /etc/sysconfig/network-scripts/ifcfg-ens33 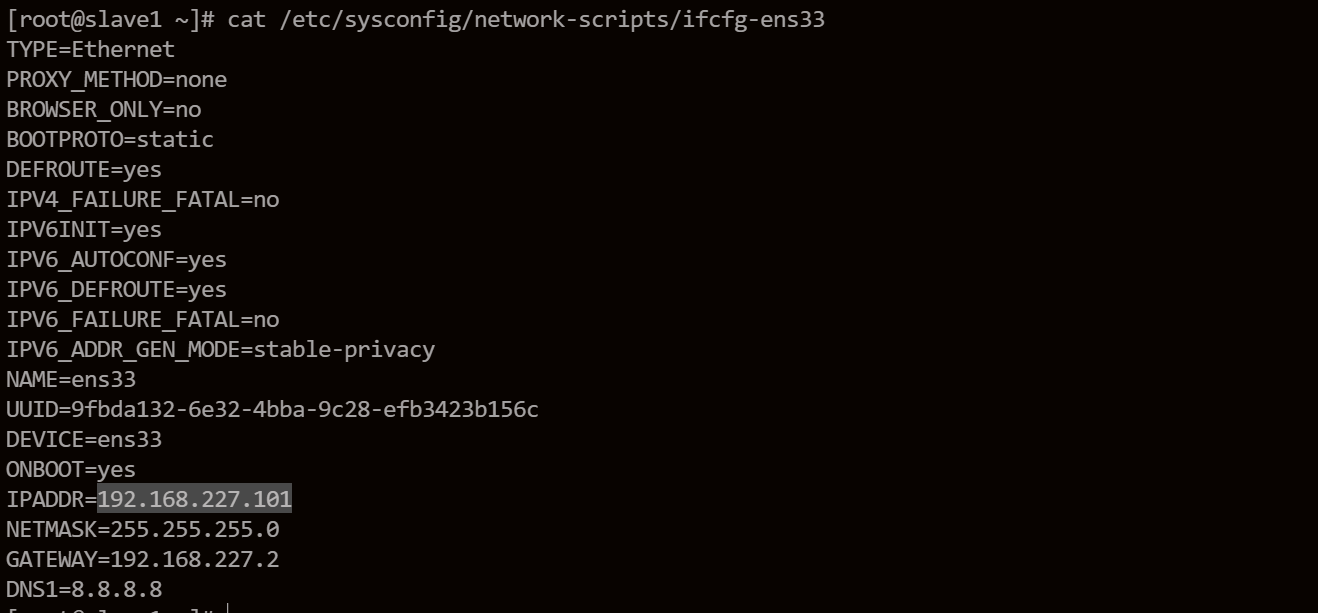
修改保存之后重启网络。
5. 配置互信免密
我们在各个节点之间互相登录时,都需要输入密码。但DataNode之间同步副本的时候,他也不会输入密码。所以需要各个节点进行免密登录。
在三台机器上使用下面命令,在 ~/.ssh 目录下生成公钥和私钥。
ssh-keygen就一路按回车,直到创建成功。
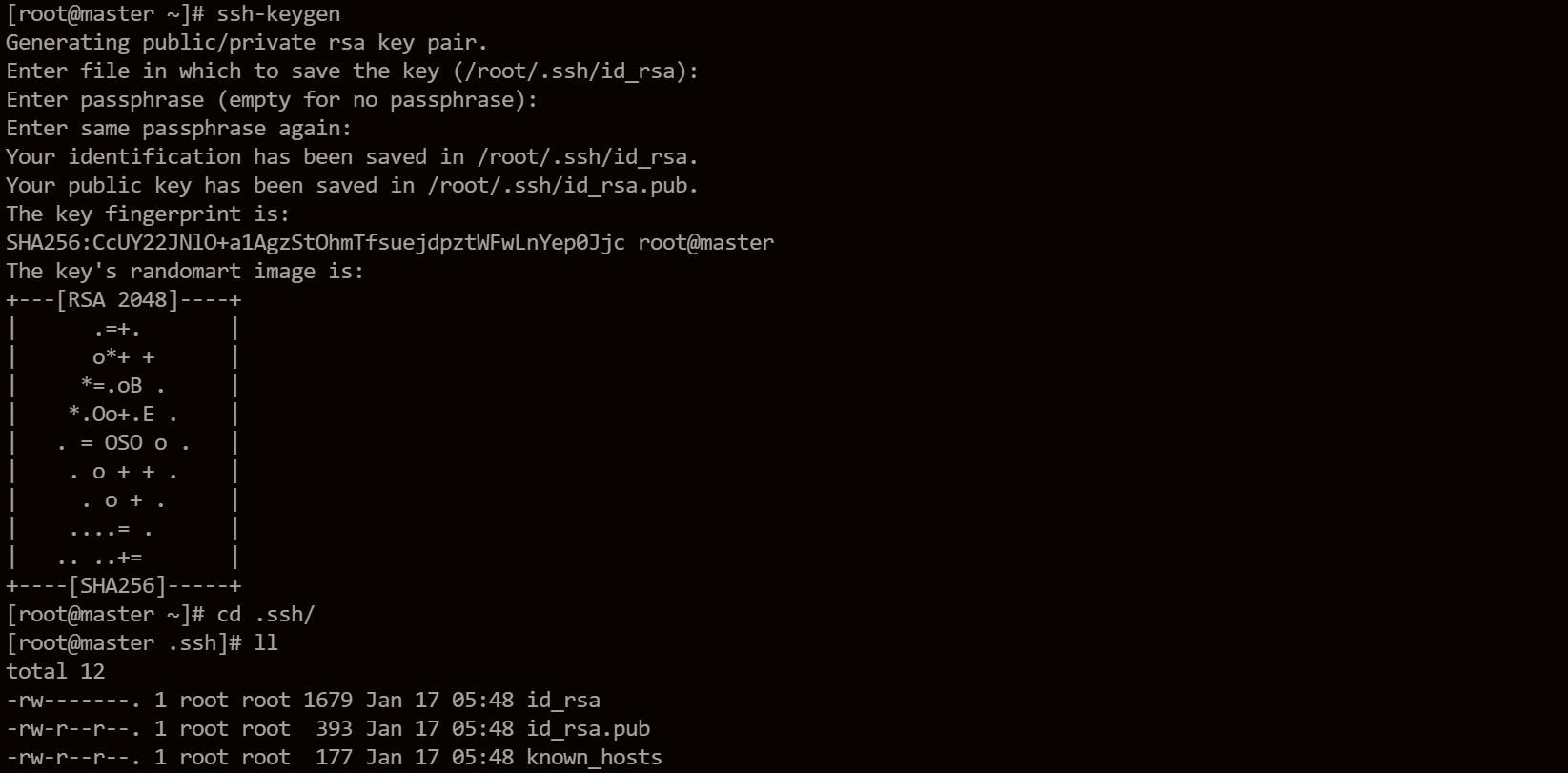
最终的操作就是将三个节点的公钥 id_rsa.pub内容,拷贝到authorized_keys中,然后分发到三个节点的/root/.ssh目录中。
使用ssh-copy-id就能将本机公钥,拷贝到目标主机authorized_keys(没有会自动生成)中,就完成了本机到目标主机的单向免密登录。
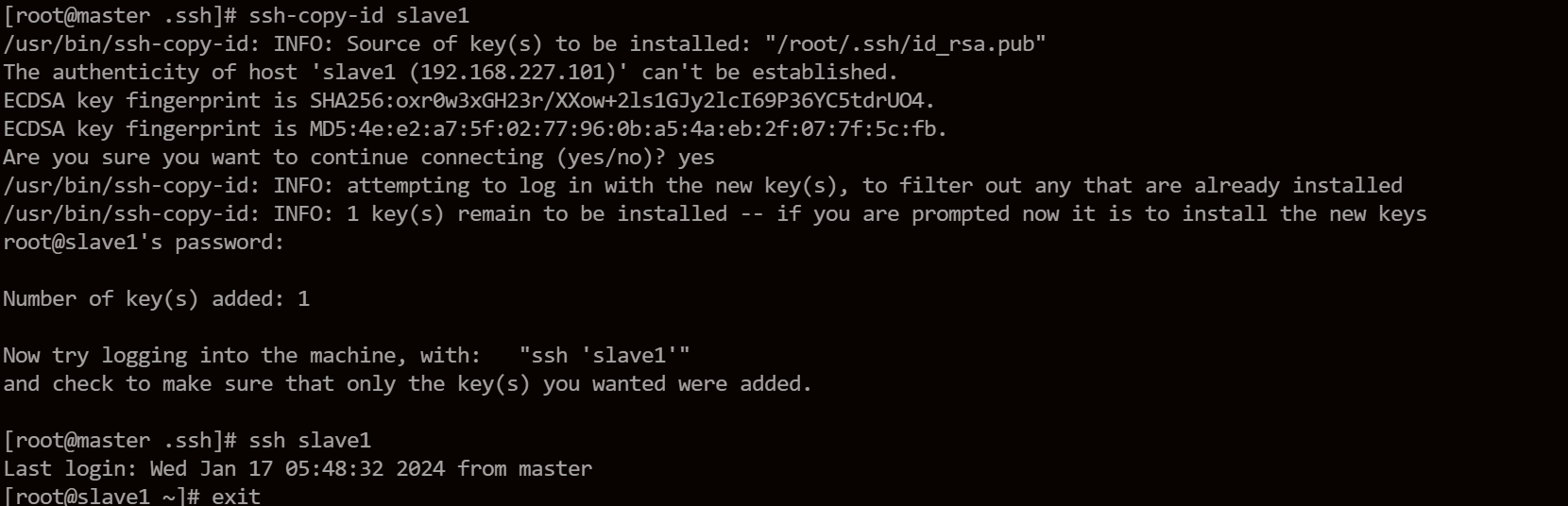
我将master和slave2公钥通过ssh-copy-id放到slave1中,然后在slave1上将slave1的公钥在粘贴到authorized_keys,然后将authorized_keys分发到master和slave2,这样三个节点互信就完成了。

然后登录测试,已经不需要密码。

启动Hadoop集群
然后就是启动Hadoop集群,Hadoop集群的功能主要是存储和计算。存储对应的是HDFS,计算是Yarn,启动Hadoop集群就是启动这两个组件。
1. 格式化
第一次启动集群时必须对其进行格式化,将新的分布式文件系统格式化为HDFS。
hdfs namenode -format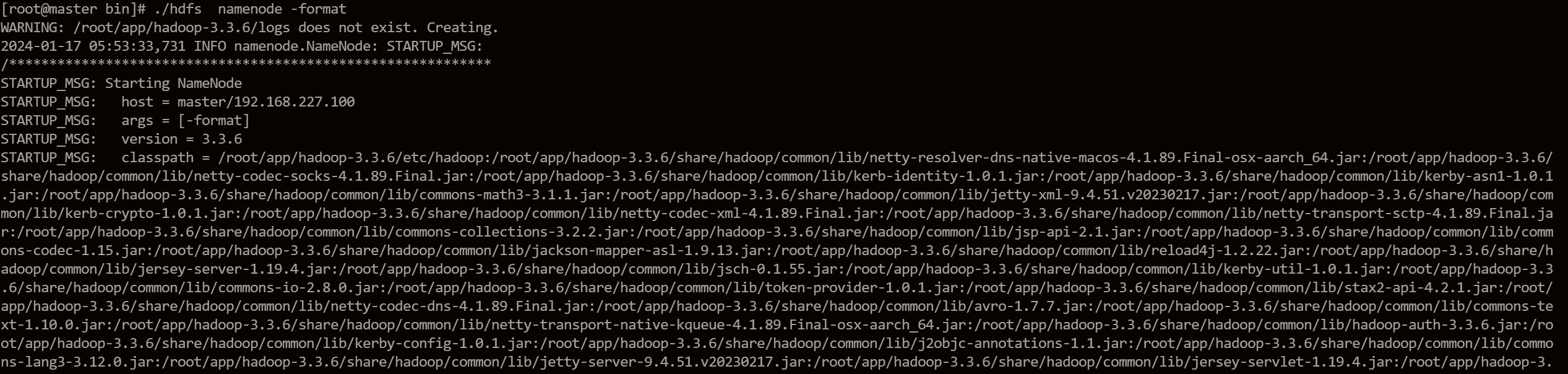
等待格式化完成。在NameNode的dfs.namenode.name.dir目录下,会生成集群信息和元数据信息。
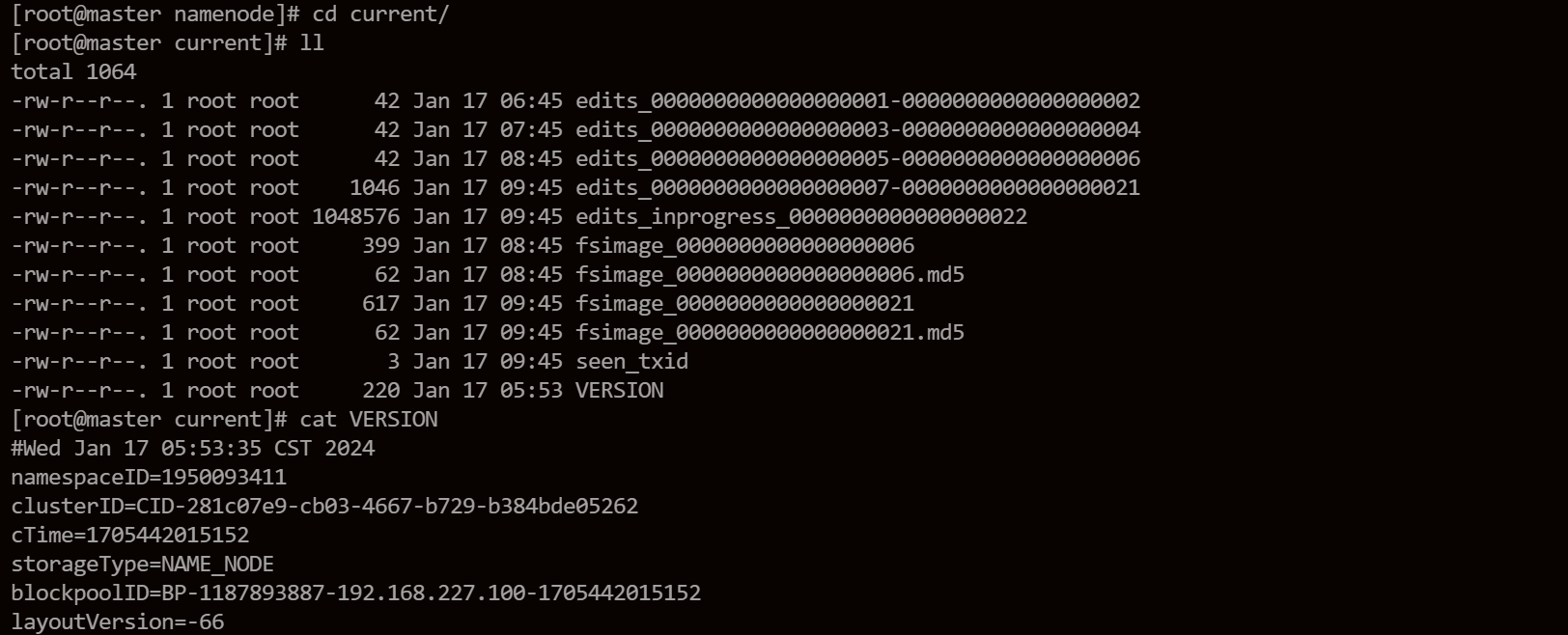
2. 启动集群
使用start-dfs.sh启动HDFS。

使用start-yarn.sh启动YARN。

查看各个节点的启动情况。
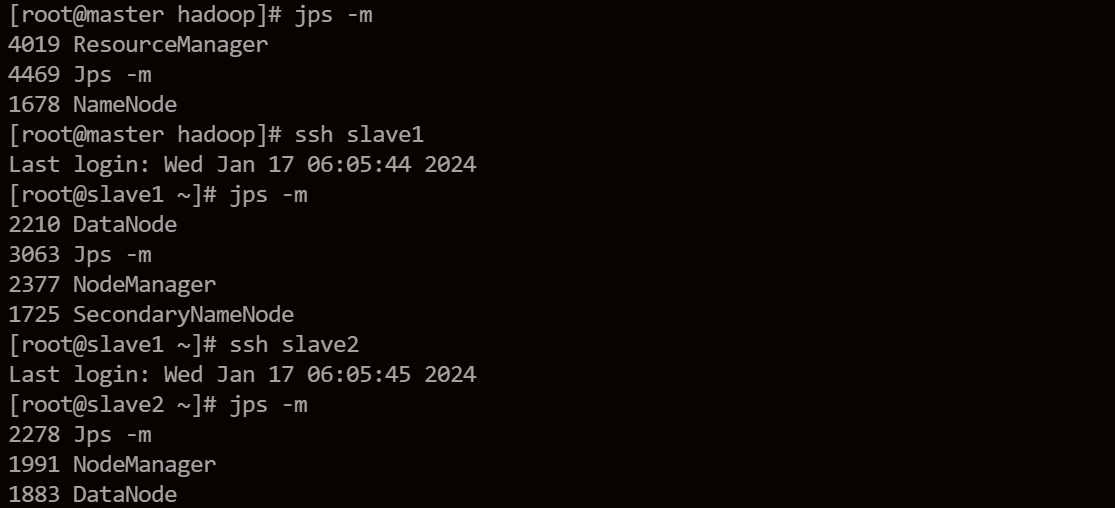
master上启动了HDFS和YARN的主节点,slave上启动了集群的从节点。
3. webui
通过master的50070,可以访问HDFS的webui。
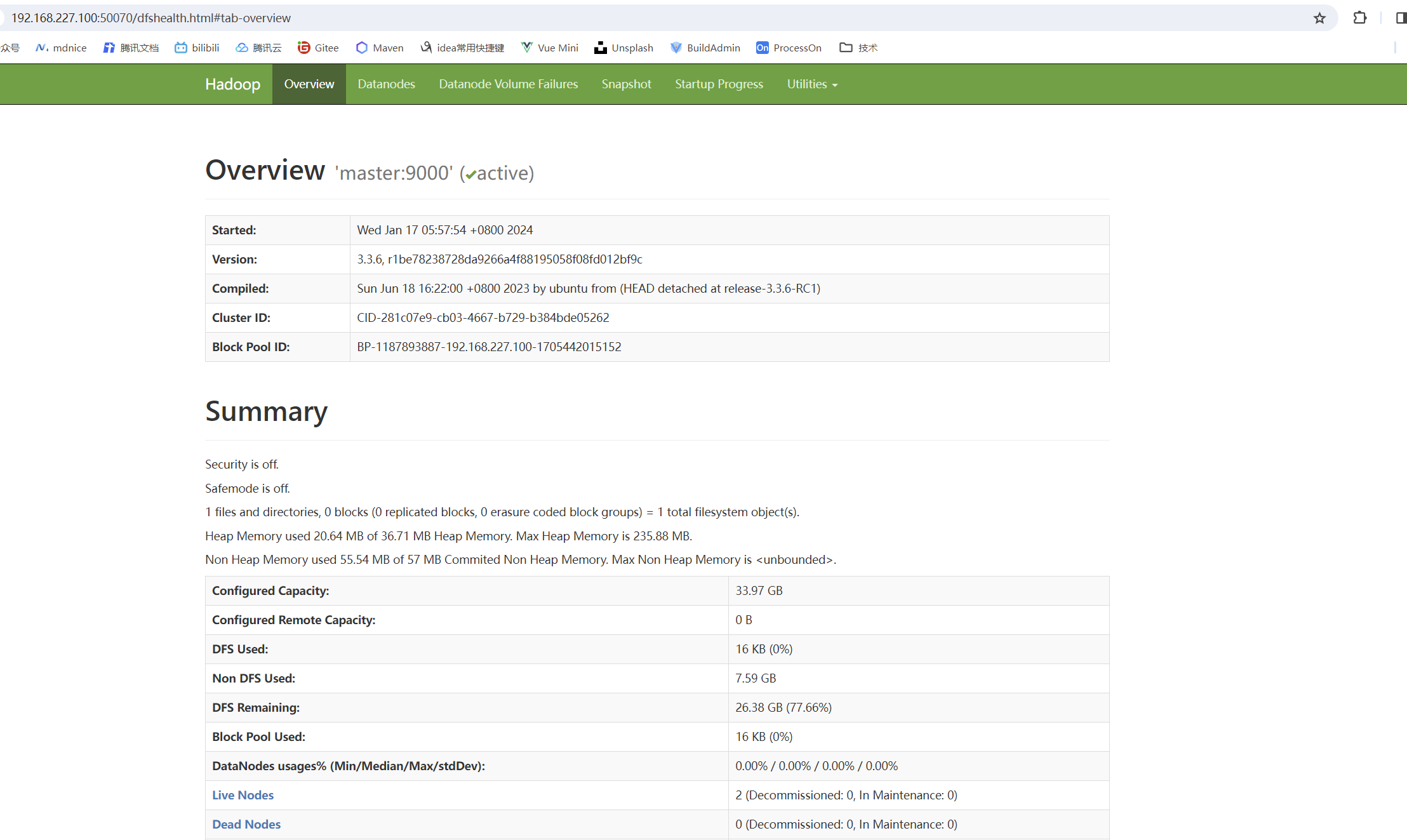
master的8088端口,可以看到yarn的集群资源、程序运行状态的webui。
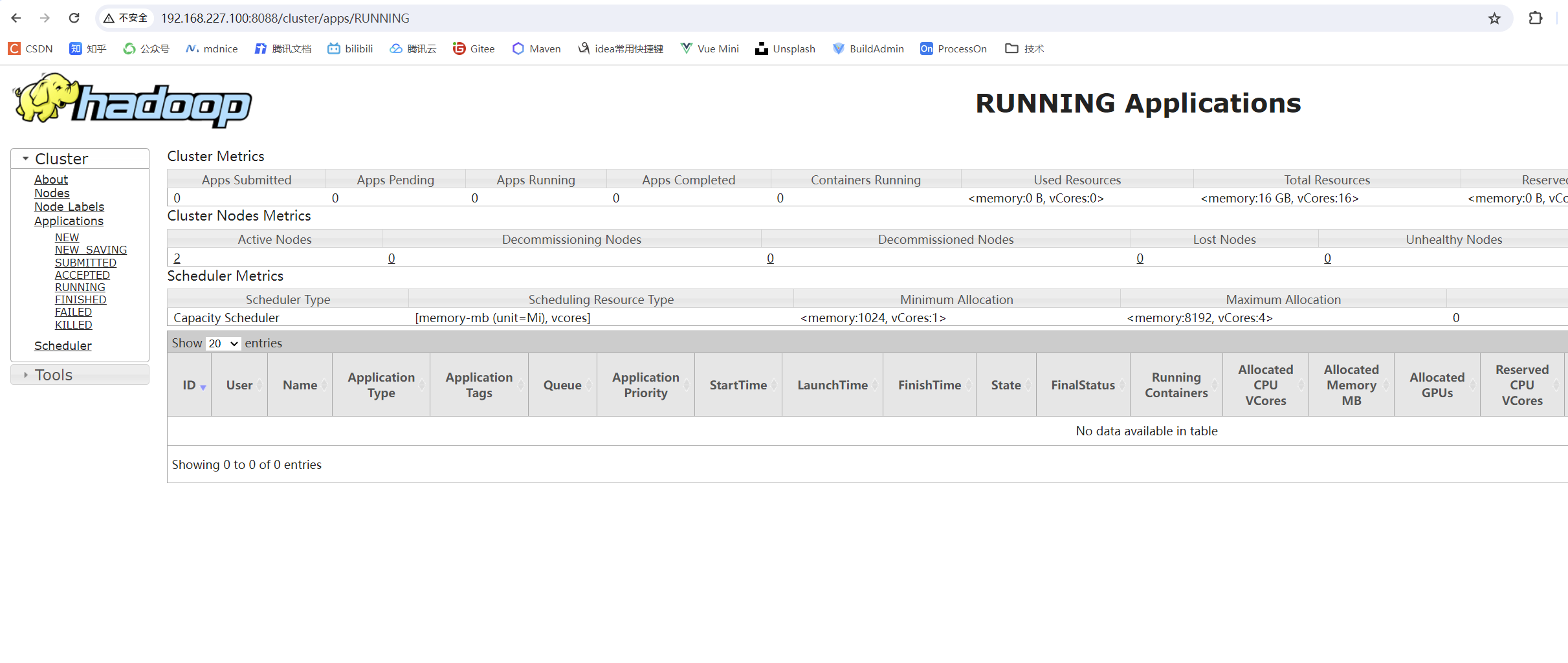
4. 测试HDFS
这里就通过客户端命令上传文件到HDFS。
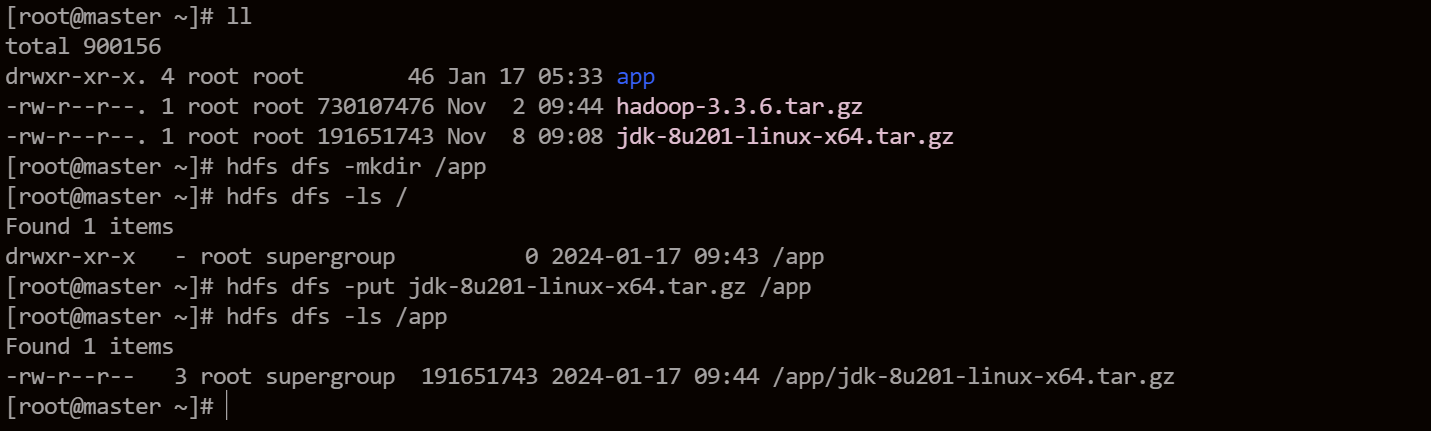
通过hdfs命令的mkdir、put、ls命令,完成了数据上传。至于yarn,后续会提交Spark任务来进行使用。
结语
这就是我在虚拟机上搭建Hadoop3的步骤,有兴趣的同学不妨试试!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。