Hadoop学习:深入解析MapReduce的大数据魔力之数据压缩(四)
Hadoop学习:深入解析MapReduce的大数据魔力之数据压缩(四)

Hadoop学习:深入解析MapReduce的大数据魔力之数据压缩(四)
4.1 概述
1)压缩的好处和坏处
压缩的优点:以减少磁盘IO、减少磁盘存储空间。 压缩的缺点:增加CPU开销。
2)压缩原则
(1)运算密集型的Job,少用压缩 (2)IO密集型的Job,多用压缩
4.2 MR 支持的压缩编码
1)压缩算法对比介绍
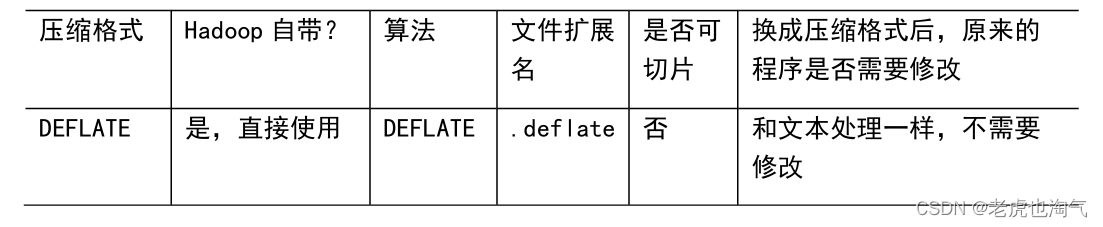
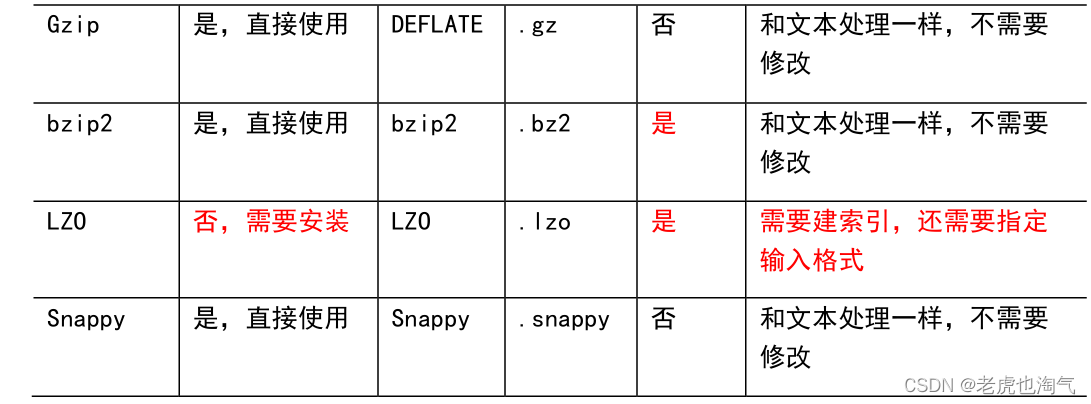
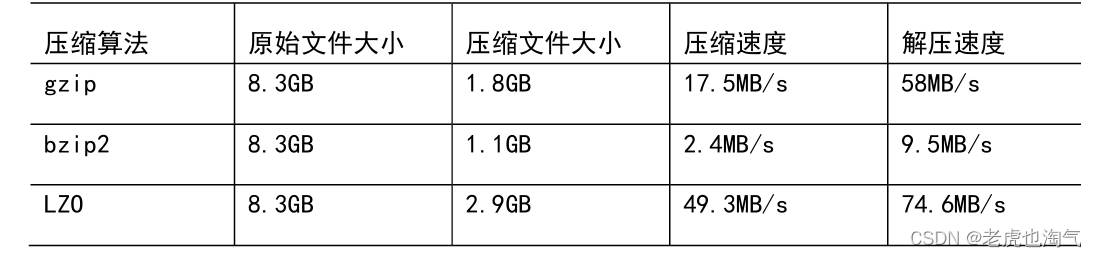
2)压缩性能的比较
4.3 压缩方式选择
压缩方式选择时重点考虑:压缩/解压缩速度、压缩率(压缩后存储大小)、压缩后是否 可以支持切片。
4.3.1 Gzip 压缩
优点:压缩率比较高; 缺点:不支持Split;压缩/解压速度一般;
4.3.2 Bzip2 压缩
优点:压缩率高;支持Split; 缺点:压缩/解压速度慢。
4.3.3 Lzo 压缩
优点:压缩/解压速度比较快;支持Split; 缺点:压缩率一般;想支持切片需要额外创建索引。
4.3.4 Snappy 压缩
优点:压缩和解压缩速度快; 缺点:不支持Split;压缩率一般;
4.3.5 压缩位置选择
压缩可以在MapReduce作用的任意阶段启用。

4.4 压缩参数配置
1)为了支持多种压缩/解压缩算法,Hadoop引入了编码/解码器
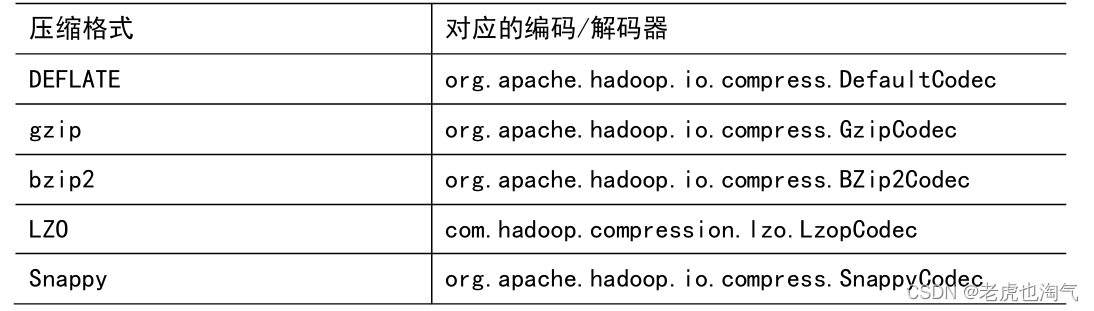
2)要在Hadoop中启用压缩,可以配置如下参数

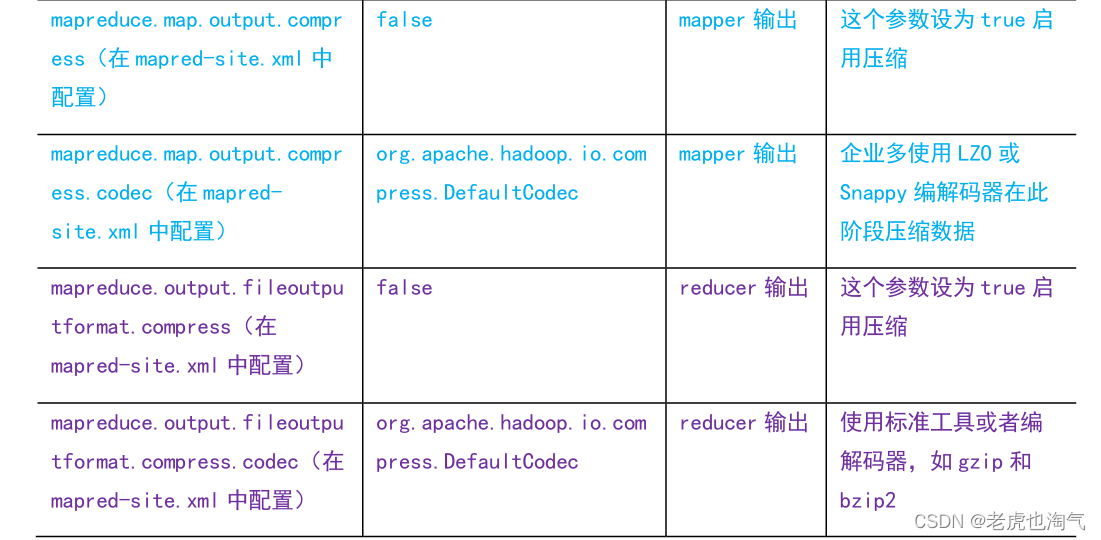
4.5 压缩实操案例
4.5.1 Map输出端采用压缩
即使你的MapReduce的输入输出文件都是未压缩的文件,你仍然可以对Map任务的中 间结果输出做压缩,因为它要写在硬盘并且通过网络传输到Reduce节点,对其压缩可以提 高很多性能,这些工作只要设置两个属性即可,我们来看下代码怎么设置。 1)给大家提供的Hadoop源码支持的压缩格式有:==BZip2Codec、DefaultCodec ==
package com.atguigu.mapreduce.compress;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.BZip2Codec;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountDriver {
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
// 开启map端输出压缩
conf.setBoolean("mapreduce.map.output.compress", true);
// 设置map端输出压缩方式
conf.setClass("mapreduce.map.output.compress.codec",
BZip2Codec.class,CompressionCodec.class);
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountDriver.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
} 2)Mapper保持不变
package com.atguigu.mapreduce.compress;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class WordCountMapper extends Mapper<LongWritable, Text, Text,
IntWritable>{
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context
context)throws IOException, InterruptedException {
// 1 获取一行
String line = value.toString();
// 2 切割
String[] words = line.split(" ");
// 3 循环写出
for(String word:words){
k.set(word);
context.write(k, v);
}
}
} 3)Reducer保持不变
package com.atguigu.mapreduce.compress;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountReducer extends Reducer<Text, IntWritable, Text,
IntWritable>{
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
// 1 汇总
for(IntWritable value:values){
sum += value.get();
}
v.set(sum);
// 2 输出
context.write(key, v);
}
} 4.5.2 Reduce输出端采用压缩
基于WordCount案例处理。 1)修改驱动
package com.atguigu.mapreduce.compress;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.compress.BZip2Codec;
import org.apache.hadoop.io.compress.DefaultCodec;
import org.apache.hadoop.io.compress.GzipCodec;
import org.apache.hadoop.io.compress.Lz4Codec;
import org.apache.hadoop.io.compress.SnappyCodec;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCountDriver {
public static void main(String[] args) throws IOException,
ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountDriver.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
// 设置reduce端输出压缩开启
FileOutputFormat.setCompressOutput(job, true);
// 设置压缩的方式
FileOutputFormat.setOutputCompressorClass(job, BZip2Codec.class);
//
FileOutputFormat.setOutputCompressorClass(job, GzipCodec.class);
//
FileOutputFormat.setOutputCompressorClass(job,
DefaultCodec.class);
boolean result = job.waitForCompletion(true);
System.exit(result?0:1);
}
} 2)Mapper和Reducer保持不变(详见4.5.1)
常见错误及解决方案
1)导包容易出错。尤其Text和CombineTextInputFormat。
2)Mapper 中第一个输入的参数必须是LongWritable或者NullWritable,不可以是IntWritable. 报的错误是类型转换异常。
3)java.lang.Exception: java.io.IOException: Illegal partition for 13926435656 (4),说明 Partition 和ReduceTask 个数没对上,调整ReduceTask个数。
4)如果分区数不是1,但是reducetask为1,是否执行分区过程。答案是:不执行分区过程。因为在MapTask的源码中,执行分区的前提是先判断ReduceNum个数是否大于1。不大于1 肯定不执行。
5)在Windows环境编译的jar包导入到Linux环境中运行, hadoop jar wc.jar /user/atguigu/output 报如下错误: Exception in com.atguigu.mapreduce.wordcount.WordCountDriver thread “main” /user/atguigu/ java.lang.UnsupportedClassVersionError: com/atguigu/mapreduce/wordcount/WordCountDriver : Unsupported major.minor version 52.0 原因是Windows环境用的jdk1.7,Linux环境用的jdk1.8。 解决方案:统一jdk版本。 6)缓存pd.txt小文件案例中,报找不到pd.txt文件 原因:大部分为路径书写错误。还有就是要检查pd.txt.txt的问题。还有个别电脑写相对路径 找不到pd.txt,可以修改为绝对路径。
7)报类型转换异常。 通常都是在驱动函数中设置Map输出和最终输出时编写错误。 Map 输出的key如果没有排序,也会报类型转换异常。
8)集群中运行wc.jar时出现了无法获得输入文件。 原因:WordCount案例的输入文件不能放用HDFS集群的根目录。 9)出现了如下相关异常 Exception in thread “main” java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO
Windows.access0(Native Method) at org.apache.hadoop.io.nativeio.NativeIO$Windows.access(NativeIO.java:609) at org.apache.hadoop.fs.FileUtil.canRead(FileUtil.java:977) java.io.IOException: Could not locate executable null\bin\winutils.exe in the Hadoop binaries. at org.apache.hadoop.util.Shell.getQualifiedBinPath(Shell.java:356) at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:371) at org.apache.hadoop.util.Shell.(Shell.java:364) 解决方案:拷贝hadoop.dll文件到Windows目录C:\Windows\System32。个别同学电脑 还需要修改Hadoop源码。 方案二:创建如下包名,并将NativeIO.java拷贝到该包名下

10)自定义Outputformat 时,注意在RecordWirter 中的 close 方法必须关闭流资源。否则输出的文件内容中数据为空。
@Override
public
void
close(TaskAttemptContext context) throws IOException,
InterruptedException {
if (atguigufos != null) {
atguigufos.close();
}
if (otherfos != null) {
otherfos.close();
}
}