三范式详解

引言
在数据库设计中,三范式(3NF)是一种关系型数据库设计规范,通过消除数据冗余和依赖,旨在提高数据库的数据存储效率和数据完整性。本文将深入讨论数据库的三范式,包括每一范式的定义、优点以及在实际数据库设计中的应用。
数据库的三范式设计是数据库规范化的一种重要方法,它有助于减少数据冗余、提高数据的一致性和完整性。以下是关于三范式的详细解释:
第一范式(1NF):属性不可分割
第一范式是数据库表设计的最基本要求,即每个属性(字段)都是不可分割的原子项。这意味着每个字段都应该有一个唯一的名字,而且每个字段的数据类型应该是一个单一类型,如整数、字符串、日期等。
例如,如果我们有一个“员工”表,那么每个员工都有一个唯一的“员工编号”字段,这个字段是不可再分的。同时,表中可能还包括其他字段,如姓名、性别、出生日期等,这些字段也都是不可再分的。
第二范式(2NF):满足第一范式;且不存在部分依赖
第二范式是在满足第一范式的基础上,要求每个非主属性都完全依赖于主属性。这意味着非主属性必须完全依赖于主键,而不是仅仅依赖于主键的一部分。
例如,如果我们有一个“订单”表和一个“订单详情”表,其中“订单”表有一个主键“订单编号”,而“订单详情”表有一个外键“订单编号”和一个非主属性“商品数量”。在这个例子中,“商品数量”完全依赖于“订单编号”,因此符合第二范式的要求。
第三范式(3NF):满足第二范式;且不存在传递依赖
第三范式是在满足第二范式的基础上,要求非主属性之间不存在传递依赖。这意味着非主属性必须直接依赖于主属性,而不是间接依赖于主属性。
例如,如果我们有一个“部门”表和一个“员工”表,其中“部门”表有一个主键“部门编号”,“员工”表有一个外键“部门编号”和一个非主属性“工资”。在这个例子中,“工资”直接依赖于“部门编号”,因此符合第三范式的要求。但是,如果存在一个“工资等级”表,其中有一个外键“部门编号”和一个非主属性“工资标准”,那么这个“工资标准”就间接依赖于“部门编号”,不符合第三范式的要求。
三范式是数据库规范化的一种重要方法,它有助于减少数据冗余、提高数据的一致性和完整性。第一范式要求每个属性都是不可分割的原子项;第二范式要求每个非主属性都完全依赖于主属性;第三范式要求非主属性之间不存在传递依赖。在设计数据库时,应该尽量遵守三范式的要求,以避免出现数据冗余、数据不一致等问题。
1. 第一范式(1NF)
1.1 定义
第一范式要求数据库表中的所有列都是不可再分的原子值,即每个单元格中只能存储一个值。
1.2 优点
- 消除重复的数据: 避免了在一个字段中存储多个值,减少了数据冗余。
- 简化查询: 使得查询操作更加直观和简单。
1.3 示例
考虑一个包含学生信息的表:
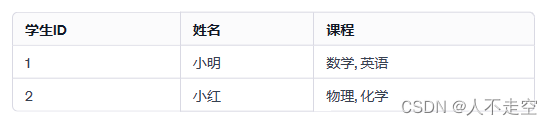
转换为第一范式:

2. 第二范式(2NF)
2.1 定义
第二范式要求数据库表中的非主键列完全依赖于主键,即非主键列不能部分依赖于主键。
2.2 优点
- 减少数据冗余: 消除了非主键列对主键的部分依赖,减少了数据冗余。
- 提高数据一致性: 通过确保每个非主键列都完全依赖于主键,增强了数据一致性。
2.3 示例
考虑一个订单表:

转换为第二范式:
订单表(Orders)

产品表(Products)

3. 第三范式(3NF)
3.1 定义
第三范式要求数据库表中的非主键列之间不存在传递依赖关系,即非主键列不能依赖于其他非主键列。
3.2 优点
- 进一步减少数据冗余: 消除了非主键列之间的传递依赖,减少了数据冗余。
- 提高数据更新效率: 数据更新时,不会影响到不相关的列。
3.3 示例
考虑一个学生信息表:

转换为第三范式:
学生信息表(Students)

专业信息表(Majors)

结论
通过理解和遵循三范式,数据库设计能够更好地保障数据的完整性、减少冗余,并且提高数据库的性能和可维护性。在实际应用中,根据具体情况,可以适度地牺牲一些范式来满足实际需求,但保持良好的数据库设计原则是确保系统稳定和可扩展的关键。
希望通过本文的介绍,读者能够更深入地理解数据库设计中的三范式原理和应用,从而在实际工作中更加合理地设计和优化数据库结构。