2000字,探讨SparkStreaming窗口计算window的起源
原创2000字,探讨SparkStreaming窗口计算window的起源
原创
前言
在大数据流数据实时开发中,常用的技术就是SparkStreaming和Flink。在初学实时处理技术时,总是围绕着处理数据的实时性,来对不同技术做一个比较。
但是在实际应用开发场景中,很多时候都需要window(窗口)操作,这就相当于数据在窗口”形成的过程“中不处理数据,当窗口形成之后,才会触发窗口计算。所以,这时候的实时处理就变成了基于窗口微批处理。
关于窗口
在Spark中是基于RDD(Resilient Distributed Dataset)计算的,RDD是一个数据的集合,所以说SparkStreaming本身就是基于微批计算的,在构造SparkContext时设置批次间隔,最小值为50毫秒。这里的批次,就可以理解为窗口
当达到批次设定的时间时,Spark就会开始执行开发基于RDD实现的计算逻辑,所以,SparkStreaming是自带”窗口“的,而且计算逻辑是基于RDD实现的。
Flink中的数据计算是以事件为驱动的,这里的事件是指数据流中的单个数据元素,所以在Flink中每个事件都可以触发相应的处理逻辑,而不是按照固定的时间间隔进行处理。所以说,在Flink中如果想实现窗口处理,就必须使用窗口函数来实现。
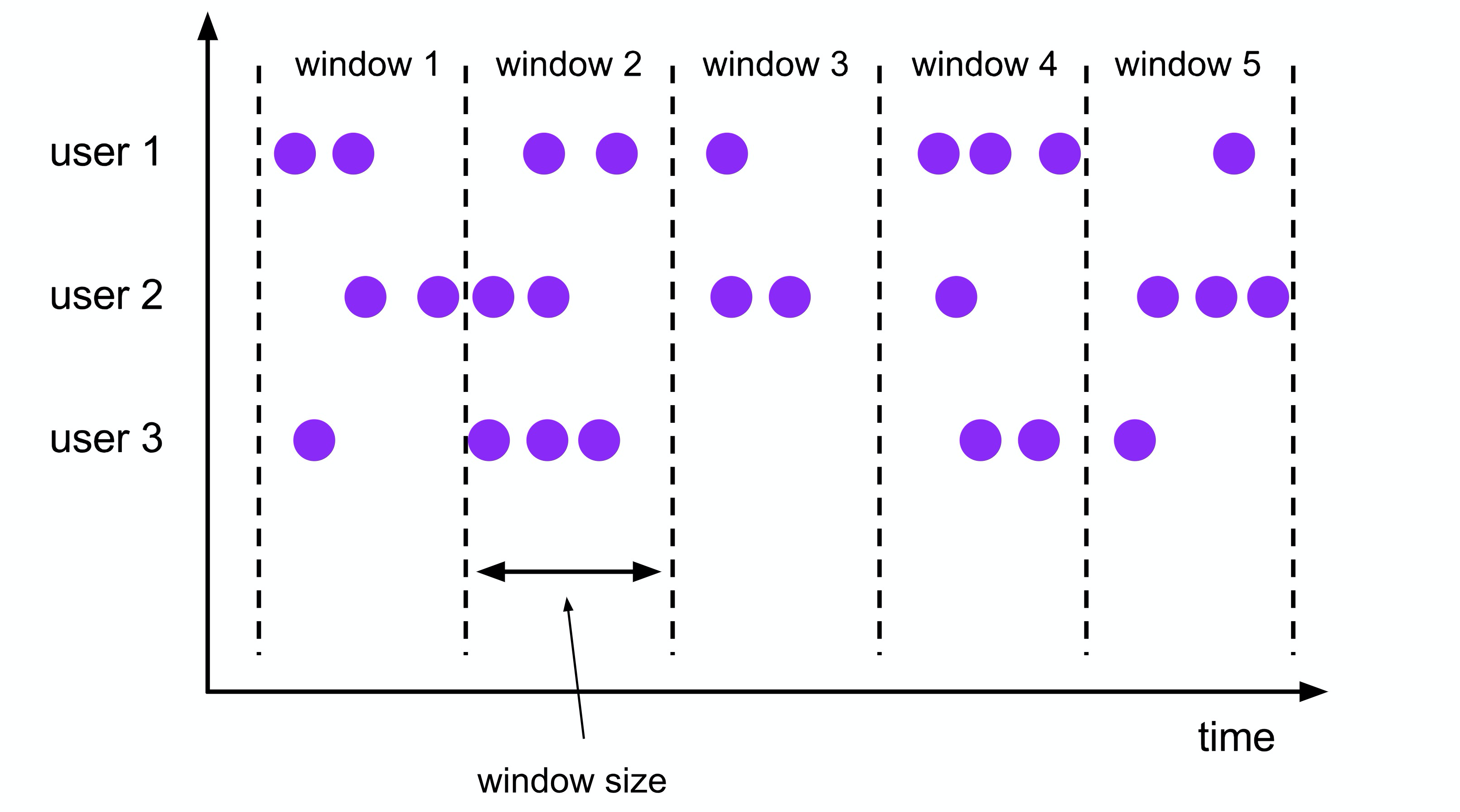
什么场景下会用到窗口计算?
例如数据的一分钟去重(reduceByKey),计数(count)、关联(join)等操作,就需要用到窗口计算。今天就先看看如何玩转SparkStreaming的窗口操作。
SparkStreaming窗口计算
上面SparkStreaming就是自带时间窗口的,一个批次中的RDD就代表着一个窗口,对RDD的计算就是窗口计算,所以SparkStreaming没有提供普通窗口的算子。
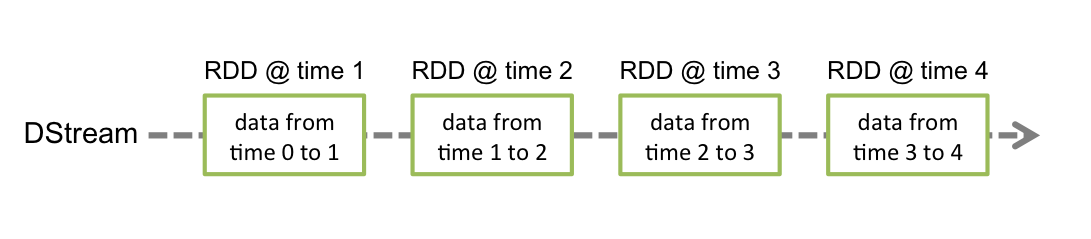
如图,RDD中数据的获取时间time 0 to 1就是一个时间窗口,数据间隔就是设置的批次间隔。既然SparkStreaming都有了RDD这个”时间窗口“了,那还有什么窗口好讲的?
在RDD计算中,一个窗口通常只能计算一个RDD的数据,当本批次RDD计算完之后,默认就会被回收,然后再拉取下一个时间批次的数据生成RDD进行计算。当我们需要对多个RDD即多个时间窗口进行计算时,就必须要借助滑动窗口的算子来实现。
滑动窗口
在SparStreaming中,提供了滑动窗口window算子用来一次计算多个窗口的数据。
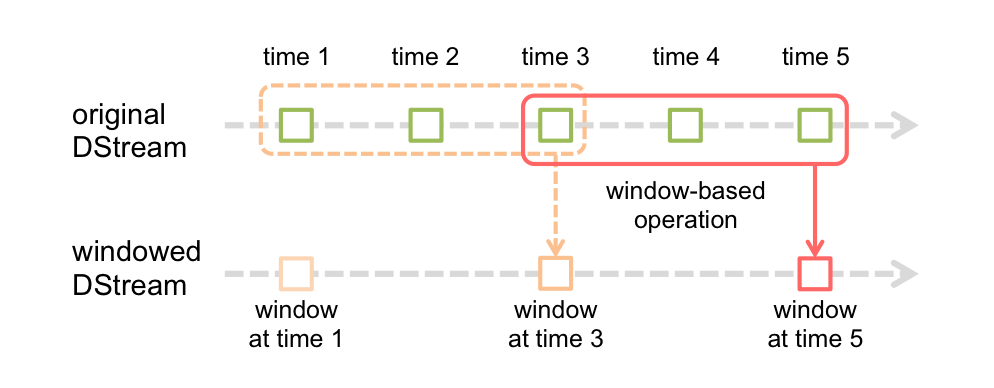
如图,原始Dstream中的time1、time2是根据我们设置的批次时间生成的RDD,也就是”自带的窗口“。下面窗口Dstream的每个window就是通过算子来生成的。
在程序启动时会根据第一个RDD生成第一个window,至于后面的window是如何生成的,每个window包含几个RDD,这个接着看窗口算子的定义。
window算子
SparkStreaming中提供了window算子,用来定义滑动窗口。
window(windowLength, slideInterval)window算子要求两个参数,windowLength表示窗口的长度,即一个窗口要包含几个RDD。slideInterval表示窗口滑动的间隔,每次滑动都会触发window的生成。windowLength和slideInterval必须设置为批次时间的倍数。
假如一个RDD生成时间为1,则上面图片中的windowLength为3,所以每个窗口都包含3个RDD,slideInterval为2,每生成两个RDD都会滑动,生成一个窗口。因为windowLength - slideInterval = 1,所以图中两个window会重复计算time3的RDD。
代码测试
开发一个单位时间内(windowLength)统计单词出现次数的SparkStreaming程序测试window算子。
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local[4]").setAppName("windows")
val ssc = new StreamingContext(conf, Seconds(10))
val streams = ssc.socketTextStream("localhost", 9999)
streams.print
streams.window(Seconds(30), Seconds(20))
.map(x => {
val s = x.split(" ")
(s(0), s(1).toInt)
})
.reduceByKey((x, y) => x + y)
.print
ssc.start
ssc.awaitTermination
}使用socketTextStream作为实时数据源,监听9999端口。每个批次10s,windowLength设置为30s,即三个RDD,slideInterval设置为20s,即两个RDD的间隔滑动一次。
我们通过nc启动端口,输入”hello 1“格式的数据被SparkStreaming读取,然后window算子生成窗口,并处理成(k,v)形式,通过reduceByKey进行窗口内单词次数统计。
我们在nc中每10s输入一条数据。

通过streams.print输出SparkStreaming中每个RDD的值,再输出window处理后的窗口计算结果。

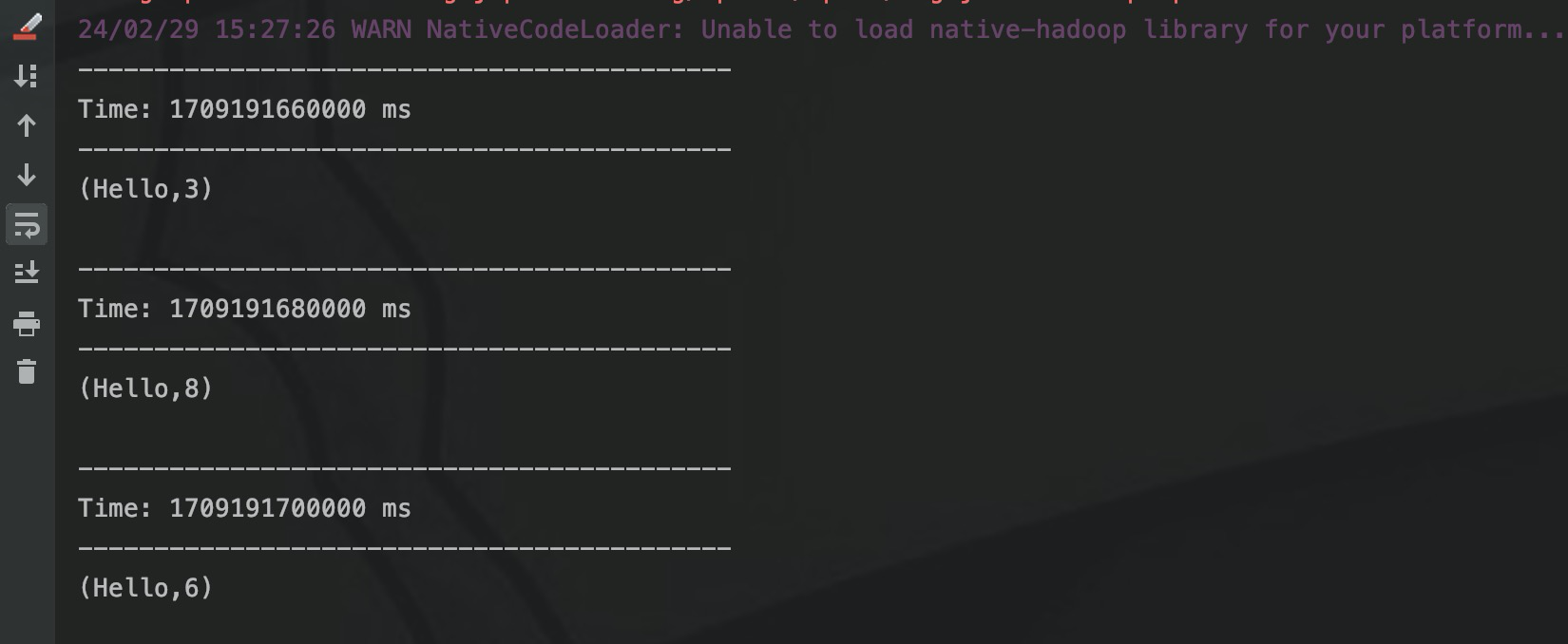
第一个RDD输出了”hello 1“,第二个RDD输出了”hello 2“,两个RDD的时间是20s = slideInterval,所以滑动生成窗口触发计算,但是这个时候只有两个RDD,所以对RDD1和RDD2的数据通过reduceByKey进行累加,输出"(hello,3)。
RDD3和RDD4都输出”hello 3“, 20s滑动生成window,这时候一共有4个RDD,windowLength设置为30s,所以要对3个RDD进行计算,累加输出"(hello, 8)。
后面的窗口依次类推,每个window都会计算3个RDD,相邻的窗口都会计算重复一个重复的RDD。
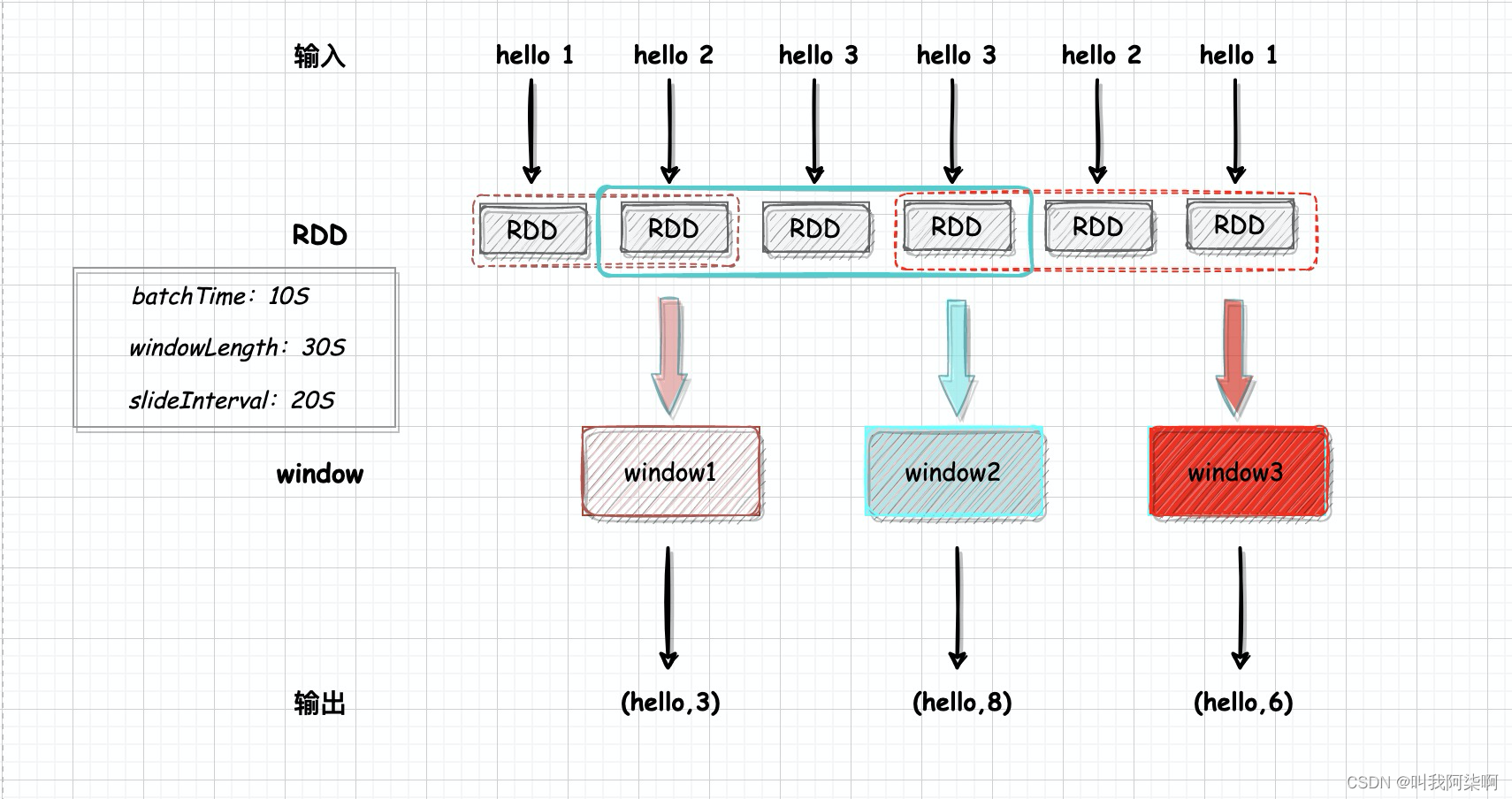
上面是根据上面程序画的一张架构图。同样,通过SparkStreaming webui的DAG也能看出来窗口的计算逻辑。
在job 0(即RDD1)时,只调用makeRDD创建了RDD,没有进行计算。
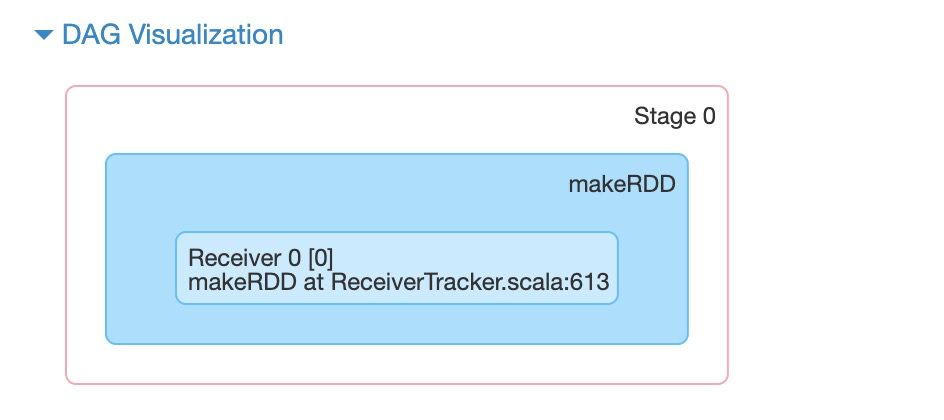
在job 1(RDD2)时,对RDD1和RDD2进行了计算,此时一个job被reduceByKey分成了两个stage。
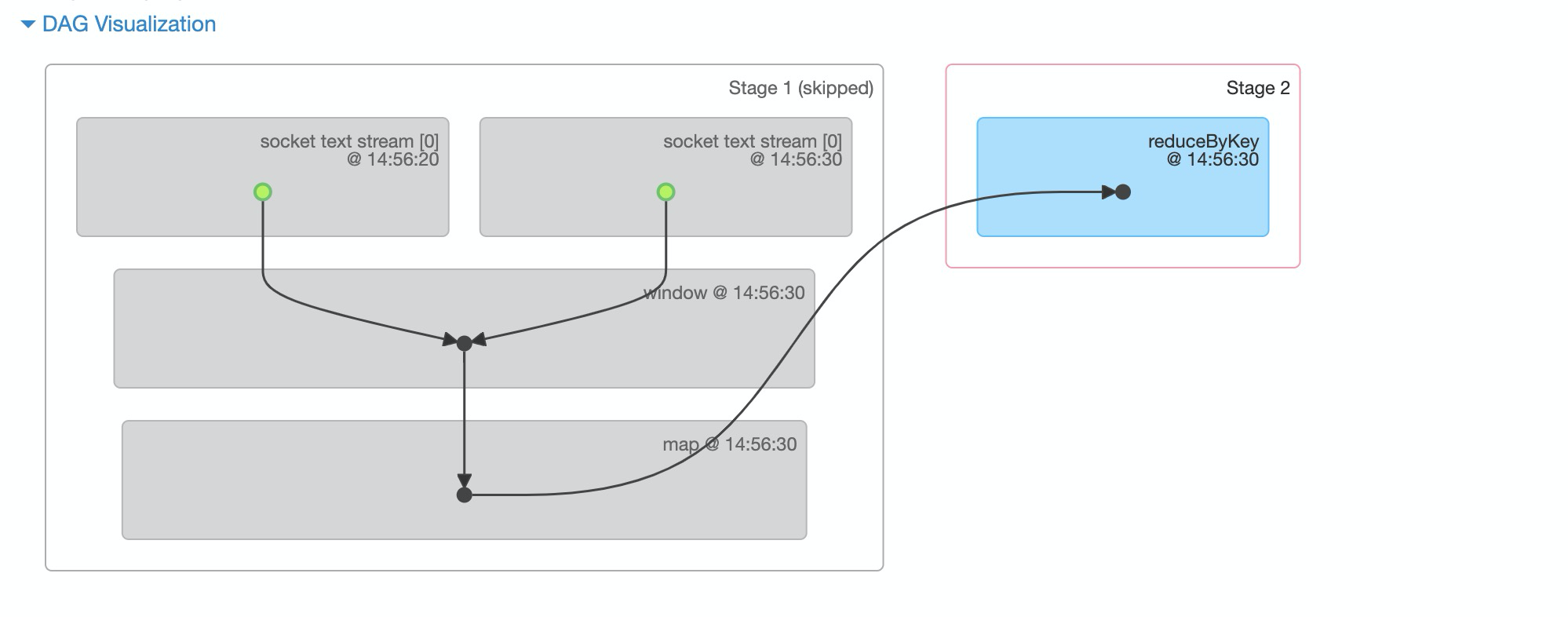
通过时间戳,可以看RDD的生成时间。在job 3时,对RDD2、3、4进行了窗口计算。
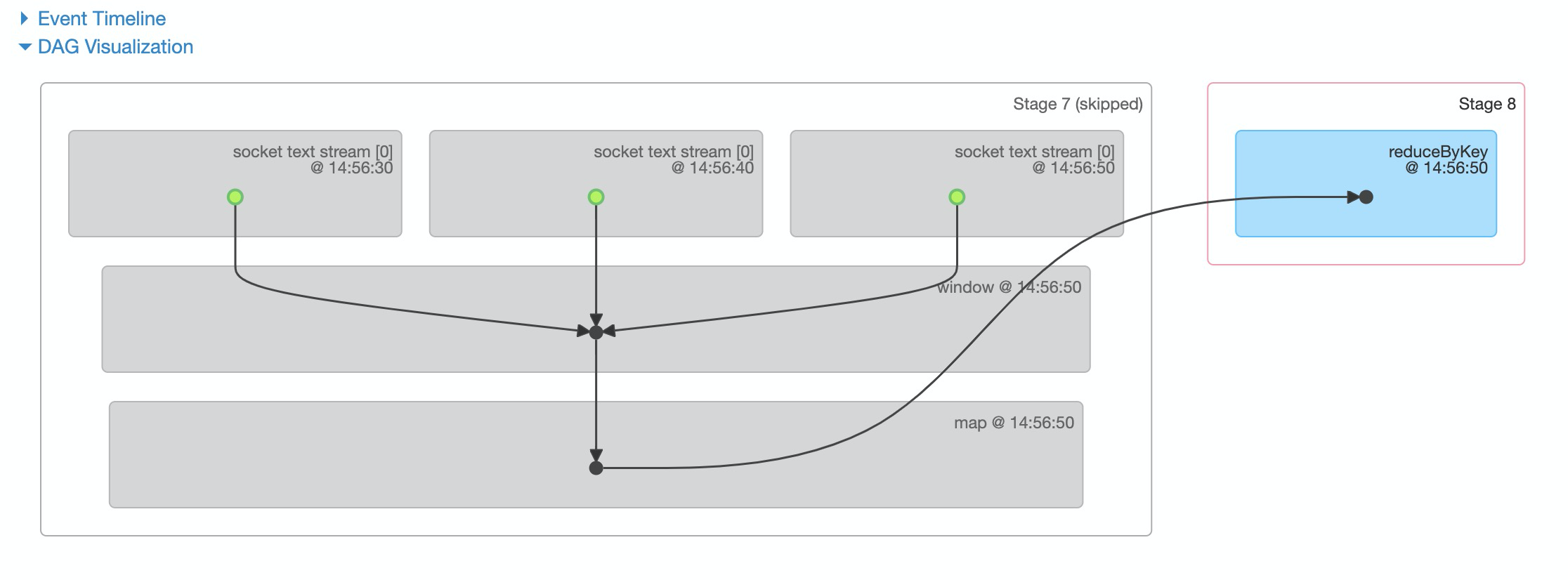
通过上面几张图可以看到,job1和job2没有触发窗口计算,job1和job3都对14:46:30的RDD进行了计算。 那么,14:46:30的RDD就进行window后面map的重复计算,而且后面每两个窗口都会有一个RDD重复计算。
所以可以对上面的代码进行优化,将所有的数据粗处理放在window之前,这样RDD在被不同的window都不会重复之前的计算。
优化
在之前代码的基础上,将map算子放在window之前。
val conf = new SparkConf().setMaster("local[4]").setAppName("windows")
val ssc = new StreamingContext(conf, Seconds(10))
ssc.socketTextStream("localhost", 9999)
.map(x => {
val s = x.split(" ")
(s(0), s(1).toInt)
})
.window(Seconds(30), Seconds(20))
.reduceByKey((x, y) => x + y)
.print然后查看DAG。
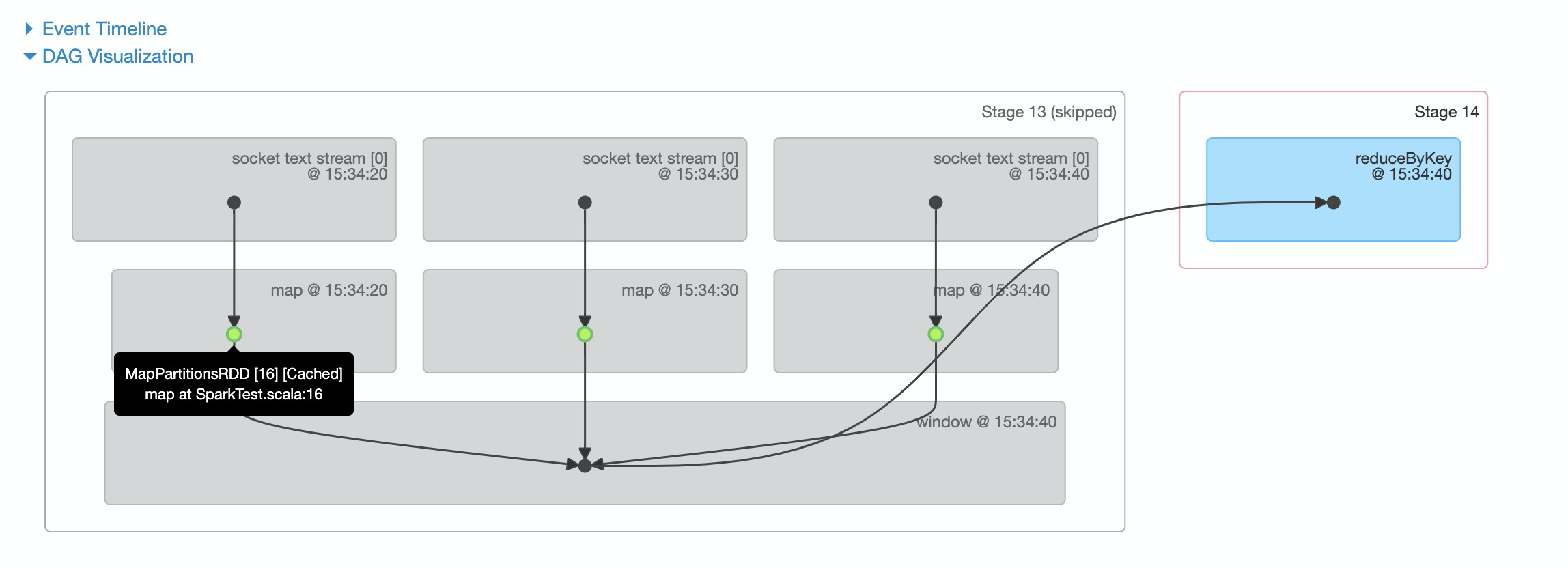
图中绿点部分表示,原始的RDD在经过map算子处理之后,生成MapPartitionsRDD,然后被cache缓存。这样,在当前窗口计算过的RDD,如果在下一个窗口如果用到,就会从cache取出MapPartitionsRDD放入window,就避免了一次map计算。
反观之前的DAG,cache的是原始BlockRDD,而且map计算是在window之后,所以当RDD每次被放入窗口,都会重新再进行map计算。
这样的思路就是在RDD层面做数据预处理,在window做聚合等操作。如果实在大数据量且逻辑复杂的计算场景下,一定程度上会提升处理效率和节约计算资源。
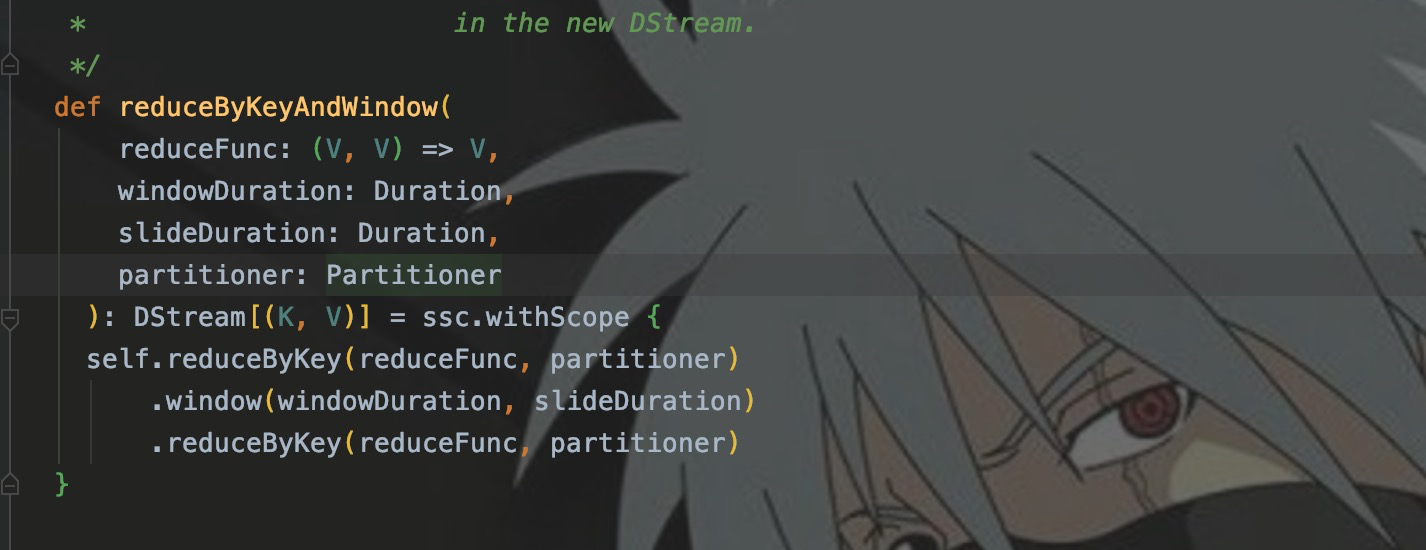
同样,贴心的SparkStreaming也提供了一些复合算子的窗口,例如reduceByKeyAndWindow、reduceByWindow、countByValueAndWindow等。这里就以reduceByKeyAndWindow为例。
reduceByKeyAndWindow
我们在之前的代码中,使用window和reduceByKey算子,实现了单词统计。使用reduceByKeyAndWindow,就可以替代window和reduceByKey。
ssc.socketTextStream("localhost", 9999)
.map(x => {
val s = x.split(" ")
(s(0), s(1).toInt)
})
.reduceByKeyAndWindow((x:Int, y:Int) => x + y, Seconds(30), Seconds(20))
.print使用与之前相同的输入测试,输出结果:
去查看reduceByKeyAndWindow的源码你也会发现,其实就是对多个算子的整合。
结语
本篇文章主要从窗口的概念和实时数据处理的应用场景入手,结合程序代码详细地介绍了在SparkStreaming中window算子的使用。后面会补一篇关于Flink的窗口计算。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。