实施 AI:加速自动化、数据运营和 AIOps

译自 Operationalizing AI: Accelerating Automation, DataOps, AIOps 。
尽管技术是许多人在实施AI时最先注意的部分,但人员和流程元素实际上是最具挑战性的。
如今AI无处不在,这在很大程度上要归功于ChatGPT的影响。但在IT和技术从业者中,大多数讨论都集中在开发团队从中获得的生产力收益上。关于产品构建和交付后应该做什么的具体信息较少。这让几个问题悬而未决:其他技术角色会怎样?在由AI生成的代码作为客户依赖的服务的功能发布后会发生什么?在基于大型语言模型的功能投入生产后会发生什么?实施AI意味着几件不同的事。
要开始实施,通过围绕三个经典概念——人员、流程和技术来构建讨论很有帮助。尽管技术是许多人首先注意的部分,但人员和流程元素实际上最具挑战性。
AI的潜力
即使在ChatGPT展示了大型语言模型的变革潜力之前,AI已经以相当快的速度被嵌入产品和业务流程中。在2022年底,麦肯锡估计每个组织使用的平均AI功能数量在过去三年中增长了一倍,达到3.8个。机器人流程自动化(RPA)领先,其次是计算机视觉、自然语言文本理解、会话界面、深度学习等等。这些各种AI能力有助于优化服务运营、产品/服务开发、销售、营销和风险管理。
我们无法高估生成AI对更广泛市场的影响。预测估计这项技术每年可能增加2.6万亿至4.4万亿美元,使所有AI的经济影响增加15%至40%。即使是这个估计,如果将生成AI嵌入用于其他任务的软件中,增长潜力可能会加倍。那么,我们如何将其实施呢?
使AI利益均沾普惠
关于AI抢走工作岗位的担忧,经济分析和历史表明,提高劳动者生产力比工作流失更有可能发生。但是哪些劳动者呢?我们先来看开发者。一些案例研究显示,开发者生产力提高了25-50%,这是一个巨大的提升。但是他们会在哪里花费额外的时间呢?他们可能不会有时间解决自己明知一直在积累的技术债务。相反,企业会要求开发更多功能,这可能影响其他团队。可以把它想象成一个气球。当你用力挤压气球的一端时,必须考虑另一端会发生什么。你不想让它爆炸。
关键是要考虑这种生产力提升对其他团队的影响。运维和基础设施团队会怎样?平台团队、站点可靠性工程师(SRE)和网络运维中心(NOC)员工又会怎样?如果开发者向生产环境交付更多代码并更快积累技术债务,这可能会压垮支持生产环境中代码的团队。
解决方案的一部分是流程(我们将在下一节讨论),但另一部分是解决生成AI收益的不公平。所以问题变成如何确保这些非开发人员团队也能分享25-50%的生产力提升。生成AI肯定可以成为答案的一部分,它可以帮助自动化标准化脚本等运维任务,更轻松地将bash脚本转换为Python等。
下面是一个例子,展示平台团队和站点可靠性工程师如何通过自动生成 runbook 来提高生产力。
DataOps:支持现代数据架构
其次是流程。工程团队很容易陷入自己功能的关注,而忽视更广泛的体验。而从提示工程到定价,投产LLM需要考虑的因素众多。但是为了高效交付高质量输出,组织还必须看到更大的画面:整个产品的端到端体验。这意味着构建生成AI或任何其他AI功能时,LLM输出只是整体体验的一部分。
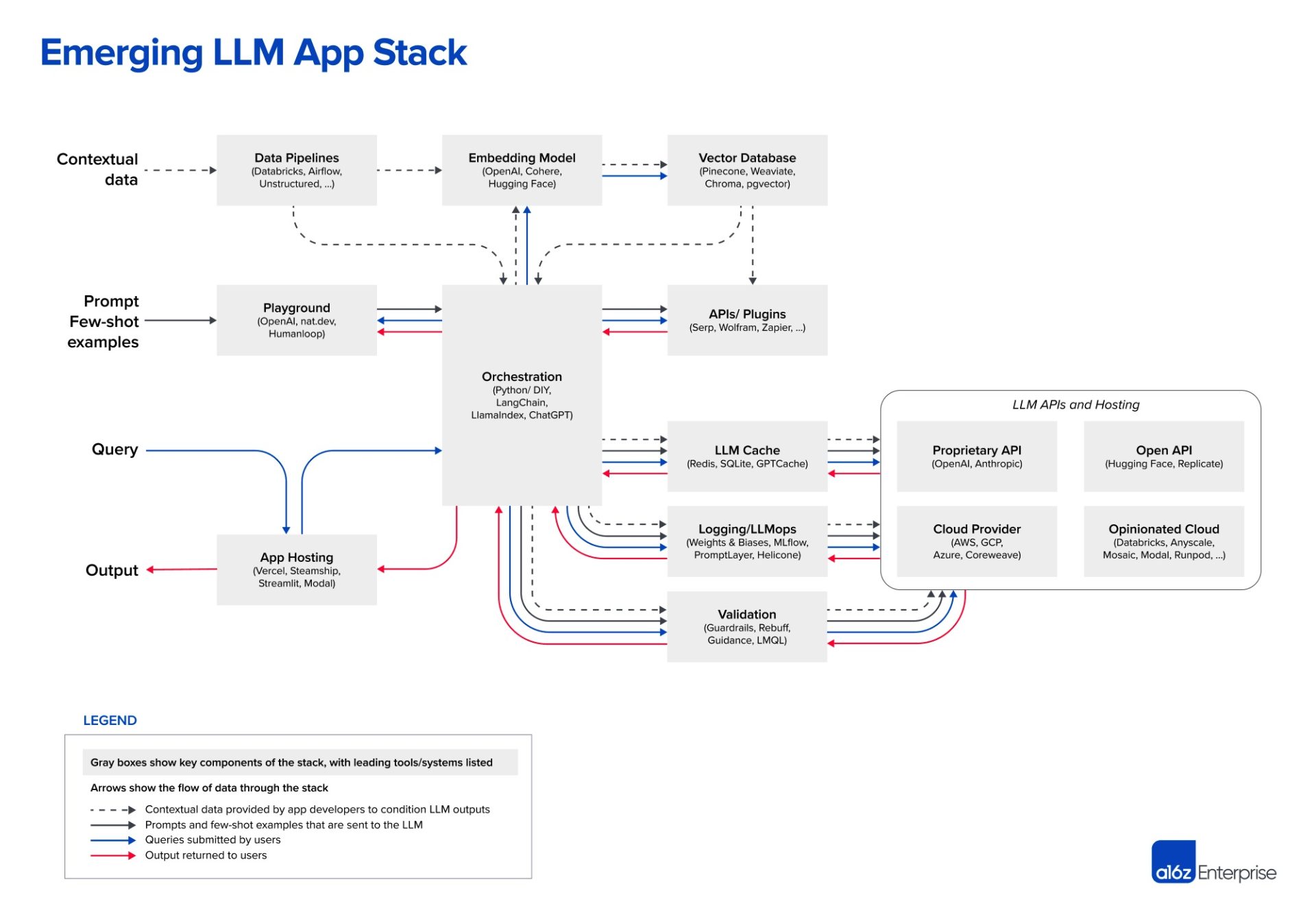
2023年6月,Andreesen Horowitz 发布了新兴LLM架构的有用概述(如上图所示)。它很复杂。即使在添加LLM复杂性之前,数据管道已经变得更加复杂。数据工程团队正处理不同的云服务,通常还有内部系统。根据PagerDuty的数据与分析高级总监Manu Raj透露,该ServiceOps平台提供商从20到25个不同来源获取数据。现代DataOps栈中还增加了数据集成工具、数据仓库、商业智能工具,现在又加上了大型语言模型组件。
现代数据架构中可能出现许多问题。更多复杂性意味着不同组件之间存在更多依赖。与此同时,风险远高于过去几个内部人员耐心访问相对静态报表的时代。如今,数据应用由流数据提供,并嵌入到面向客户的体验生态系统中。
Raj解释说:“故障至关重要”。然而,使用LLM构建的团队不必重头开始支持这些新架构。他们遇到的一些问题将是老问题,一些则可能是LLM领域经典主题的新变种。
例如,团队必须确保在数据进入模型之前对其进行适当准备,并实施治理、安全性和可观察性。数据库可用性是熟悉的实践,即使向量数据库对许多团队来说比较新。 数据密集型应用中的延迟问题一直存在,但现在团队还需考虑数据新鲜度对LLM输出的影响。 从安全角度看,我们长期面临SQL注入等攻击,现在需要防止提示注入。
简而言之,在运营LLM的非功能方面,可以并应该应用来自DevOps、数据库和站点可靠性工程以及安全领域的许多有价值经验和实践。在测试、监控、漏洞管理、制定服务级指标和管理错误预算等方面遵循最佳实践,以支持实时变更。着眼大局,你的LLM功能更有可能按照承诺实现高性能和可用性。
使用AI来运营AI
最后是技术部分。好消息是我们可以使用AI来运营AI。事实上,考虑到LLM应用栈的复杂性,这是必需的。在某些方面,计算机优于人类,我们需要承认这一点,利用机器的力量提高效率。
机器学习可以在哪里提供最大帮助?想想这些复杂的、可检测系统生成的大量事件数据。某处的故障可能影响多个系统,触发大量警报。但是机器学习可以通过压缩和关联来减少警报噪音,并识别问题根源。它还通过丰富事件数据为响应者提供上下文,以更快、更高效地找到根本原因并解决问题。
机器学习不仅可以提供上下文、关联和压缩等功能,在这方面它也优于人类。但为何就此打住呢?我们可以获取识别结果的输出,并自动执行后续步骤,如状态捕获、重启、重置和运维人员运行的无数任务,以收集更多数据和恢复服务。通过将事件处理连接到条件逻辑以应用预定义任务,可以加速复杂系统中事件的解决。即使服务无法完全自我修复,需要介入的团队也可以有更好的上下文和故障排除起点。
前景一片光明
就生成AI而言,我们才刚刚触及可能性的表面。但是当有趣的项目成为重要的面向客户服务时,艰苦的工作才刚刚开始。为确保所有人都能共享AI的好处,我们需要有效实施AI。我们不是从零开始。加速我们对自动化、DataOps和AIOps的利用可以提供帮助。