RAT:检索增强的Transformer用于CTR估计
RAT:检索增强的Transformer用于CTR估计

1. 导读
本文针对ctr预估中如何进行有效的特征交互提出新的方法。目前的方法主要集中于对单个样本内的特征交互进行建模,而忽略了潜在的跨样本间的关系,这些关系可以作为增强预测的参考上下文信息。为本文提出了一种检索增强的Transformer(RAT),获取样本内部和样本之间的细粒度特征交互。
- 通过检索相似的样本,为每个目标样本构建增强输入。
- 然后,构建具有级联注意力的Transformer层,以捕捉样本内和样本间的特征交互。
2.方法
alt text
2.1 检索相似样本作为上下文
样本
有F个field的特征
,为当前样本从剩下的样本池
中检索相似相似样本,作者此处采用BM25进行检索。使用前面说的特征来计算相关性分数,公式如下,
表示指示函数只有候选样本中的特征为目标样本的特征时这个计算特征的计算得分才有效,
表示样本池
的大小,
表示样本池中包含特征
的样本数,。
当当前样本的特征在样本池中出现次数多的时候,说明这个特征并不是很重要,分数就低,反之就高,汇总所有特征后得到对应的分数。
得到分数后,从样本池中筛选出分数最大的topK个样本
避免信息泄露,如果有时间戳信息按时间顺序对样本进行排序,并将查询限制为只检索早于它出现的样本。
2.2 构建增强输入
通过emb层将离散的特征转化为D维的emb,并且对于检索得到的样本,标签也作为特征进行编码得到emb。因此输入为
,L的取值有三个,对于检索得到的样本,0/1表示是否点击,对于原本的训练样本是未知,可用UNK表示或其他表示方式。
对于K个检索样本和一个目标样本,经过emb table并且拼接后,可以得到
的输入
,其中
表示检索得到的样本数,
表示特征数(加1是因为有label作为特征),
表示emb维度。
2.3 样本内和样本间的特征交互
作者发现直接把检索的样本和目标样本的emb拼接(长度变成(K+1)*(F+1)),采用自注意力进行特征交互是低效的,复杂度
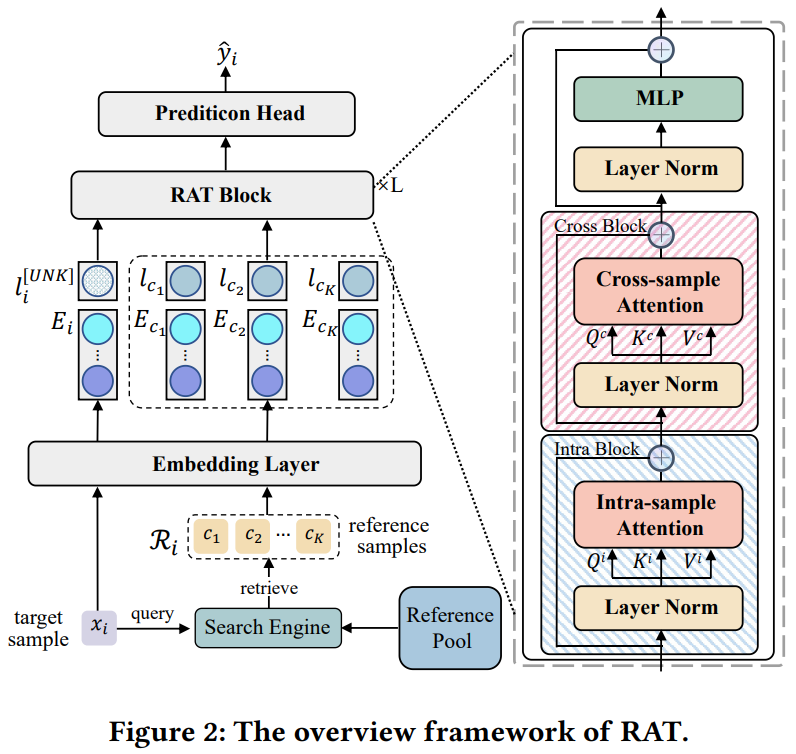
,做自注意力机制的复杂度高,并且效果也不好,可能是由于噪声特征交互的影响。因此作者解耦了不同样本的特征,设计了图2所示的transformer去建模样本内和样本间的特征交互。如下所示,分别是样本内,样本间交互,以及最后的mlp层,
表示第
个block的输入,
,ISA和CSA是自注意力层
修改后,样本内的特征交互是在field级别做的,所以是
,样本间的特征交互是在样本级别做的,所以是
。总体的复杂度降为
。详见代码
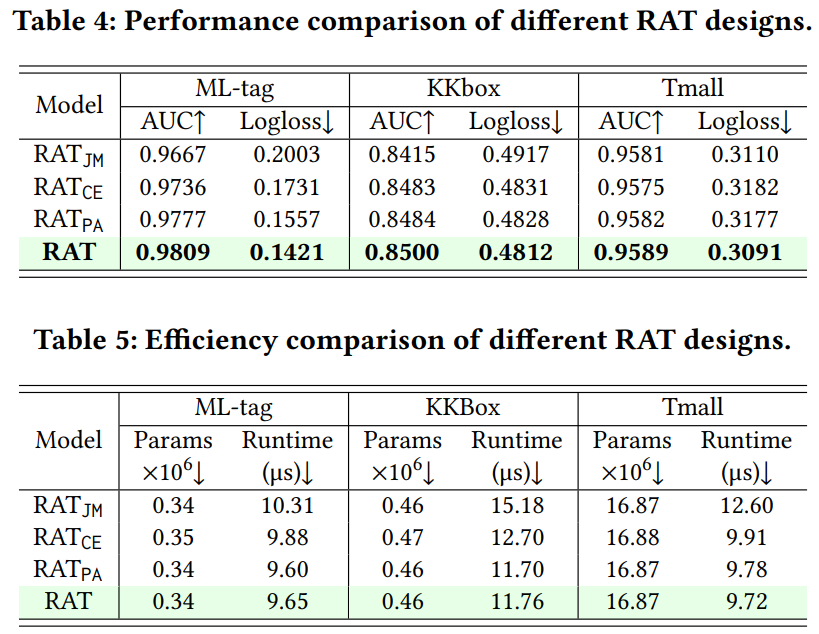
3. 结果
alt text