完全汇总,十大机器学习算法!!
完全汇总,十大机器学习算法!!

Hi,我是Johngo~
不知道你认为的十大机器学习算法是什么?
今天我来谈谈我认为的十大机器学习算法,这个一定是适合小白的。
评论区给出你认为最重要的算法模型有哪些?~
接下来我会从每个算法模型的介绍、基本原理、优缺点以及适用场景注意叙述,最后会基于开源数据集给出一个比较入门型的案例供大家学习~
那么,先聊聊我认为比较重要的十大机器学习算法模型有哪些:
- 线性回归(Linear Regression)
- 逻辑回归(Logistic Regression)
- 决策树(Decision Trees)
- K近邻算法(K-Nearest Neighbors,KNN)
- 支持向量机(Support Vector Machines,SVM)
- 朴素贝叶斯(Naive Bayes)
- K均值聚类(K-Means Clustering)
- 主成分分析(Principal Component Analysis,PCA)
- 随机森林(Random Forest)
- 神经网络(Neural Networks)
以上这些算法覆盖了机器学习中的基本概念和常用技术,对于初学者以及复习的同学来说,已经非常全面了。
本文非常的详细,需要本文PDF版本的,文末可以获取~
一起来看看吧~
线性回归
一点介绍
线性回归是一种用于建立输入变量(特征)与连续目标变量之间关系的线性模型。它是机器学习和统计学中最简单、最常见的回归方法之一。线性回归假设特征与目标之间存在线性关系,并试图找到一条最佳拟合的直线(或超平面)来描述数据之间的关系。
基本原理
线性回归基于以下基本原理:
- 线性关系假设:假设目标变量与特征之间存在线性关系。
- 最小化误差:通过最小化实际观测值与模型预测值之间的误差来确定最佳拟合直线。
核心公式
给定一个训练集
,其中
是特征,
是对应的目标值。
假设我们的模型是线性的,形式为
。
为了找到最佳拟合的直线,我们需要确定最佳的参数
和
。通常使用最小二乘法来实现这一点,最小化观测值与模型预测值之间的平方误差。
- 线性模型:
- 平方误差:
为了找到最小化误差的参数
和
,我们可以对
求偏导数并令其等于零,然后解出参数的值。推导过程是一个标准的最小二乘法问题。
优缺点
优点:
- 简单易懂:线性回归是一种简单且直观的建模方法,易于理解和解释。
- 计算效率高:计算成本较低,适用于大规模数据集。
- 可解释性强:模型的参数具有很好的可解释性,可以清晰地理解特征与目标之间的关系。
缺点:
- 对非线性关系的拟合能力有限:线性回归无法捕捉非线性关系,因此在特征与目标之间存在复杂非线性关系时表现不佳。
- 对异常值敏感:线性回归对异常值比较敏感,可能会对模型的性能产生较大影响。
适用场景
线性回归适用于以下场景:
- 当特征与目标之间存在线性关系时,线性回归是一种简单且有效的建模方法。
- 需要快速建立一个基准模型或进行初步探索性分析时,线性回归是一个不错的选择。
- 当数据集较大且特征与目标之间的关系大致为线性时,线性回归可以提供高效的模型。
总之,线性回归是一种简单但功能强大的建模技术,尤其适用于特征与目标之间存在线性关系的情况。然而,在处理非线性问题时,就需要考虑其他更复杂的模型了。
一个通透的案例
下面咱们给出的是一个基于开源数据集的线性回归实例代码,使用的数据集是加利福尼亚房价数据集(California Housing Prices)。
这个数据集包含了加州不同地区的房屋价格以及一些相关特征。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 加载加州房价数据集
housing = fetch_california_housing()
X = pd.DataFrame(housing.data, columns=housing.feature_names)
y = housing.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练线性回归模型
lr = LinearRegression()
lr.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = lr.predict(X_test)
# 计算均方误差
mse = mean_squared_error(y_test, y_pred)
print("Mean Squared Error:", mse)
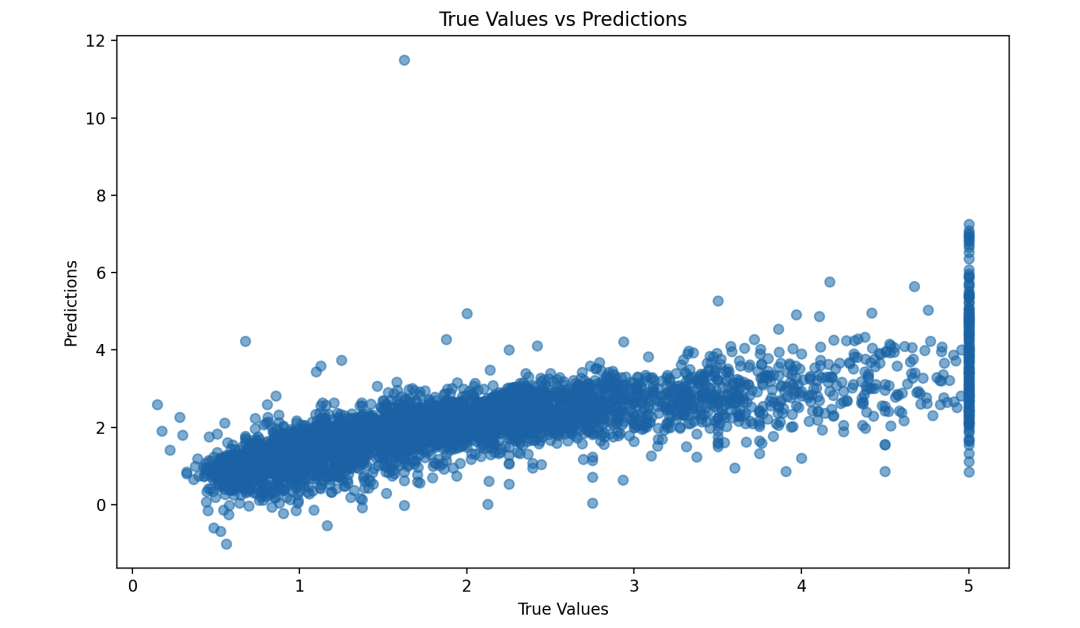
# 绘制预测值与真实值的散点图
plt.figure(figsize=(10, 6))
plt.scatter(y_test, y_pred, alpha=0.5)
plt.xlabel("True Values")
plt.ylabel("Predictions")
plt.title("True Values vs Predictions")
plt.show()
我们首先加载了加州房价数据集,然后划分成训练集和测试集。接着,我们训练了一个线性回归模型,并在测试集上进行了预测。
最后,我们计算了预测结果的均方误差,并绘制了预测值与真实值的散点图,以便观察模型的拟合效果。
逻辑回归
一点介绍
逻辑回归是一种用于解决分类问题的统计学习方法,尽管名字中包含“回归”一词,但它实际上是一种分类算法。逻辑回归主要用于预测二分类问题,它通过对输入特征的线性组合应用一个逻辑函数(也称为Sigmoid函数)来进行分类。
基本原理
逻辑回归的基本原理如下:
- 假设数据服从一个二项分布。
- 使用线性回归模型的线性组合来建模数据的对数几率。
- 对线性组合应用逻辑函数(Sigmoid函数),将连续的输出转换为概率值。
- 根据概率值进行分类,通常设置一个阈值来决定类别。
核心公式
给定一个训练集
,其中
是特征,
是对应的类别标签。
逻辑回归模型的基本公式如下:
其中,
是预测类别为 1 的概率,
是模型的参数向量,
是输入特征向量,
是逻辑函数(Sigmoid 函数)。
为了训练模型,我们需要最大化似然函数或最小化对数损失函数。推导过程可以通过最大似然估计或梯度下降等方法进行。
优缺点
优点:
- 实现简单:逻辑回归是一种简单且易于实现的分类算法。
- 计算效率高:训练速度快,适用于大规模数据集。
- 输出结果具有概率意义:可以得到样本属于某个类别的概率,而不仅仅是一个硬分类结果。
缺点:
- 仅适用于二分类问题:逻辑回归通常只适用于解决二分类问题。
- 对特征空间的线性边界限制:逻辑回归假设特征之间的关系是线性的,对于非线性问题效果不佳。
适用场景
逻辑回归适用于以下场景:
- 二分类问题:当需要解决二分类问题时,逻辑回归是一个简单而有效的选择。
- 需要得到概率输出的场景:逻辑回归可以输出样本属于某个类别的概率,适用于需要概率预测的任务,如风险评估、客户流失预测等。
- 需要快速建立基准模型的情况下,逻辑回归也是一个不错的选择。
逻辑回归是一种简单而强大的分类算法,尤其适用于二分类问题和需要概率输出的场景。
然而,在处理非线性问题时,逻辑回归的表现可能不如一些复杂的非线性模型。
一个通透的案例
下面使用鸢尾花数据集(Iris dataset)。这个数据集包含了三种不同种类的鸢尾花的花萼长度和宽度。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, confusion_matrix
from matplotlib.colors import ListedColormap
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data[:, :2] # 只选择前两个特征用于可视化
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练逻辑回归模型
lr = LogisticRegression()
lr.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = lr.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
# 绘制决策边界
x_min, x_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5
y_min, y_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.01),
np.arange(y_min, y_max, 0.01))
Z = lr.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 绘制结果
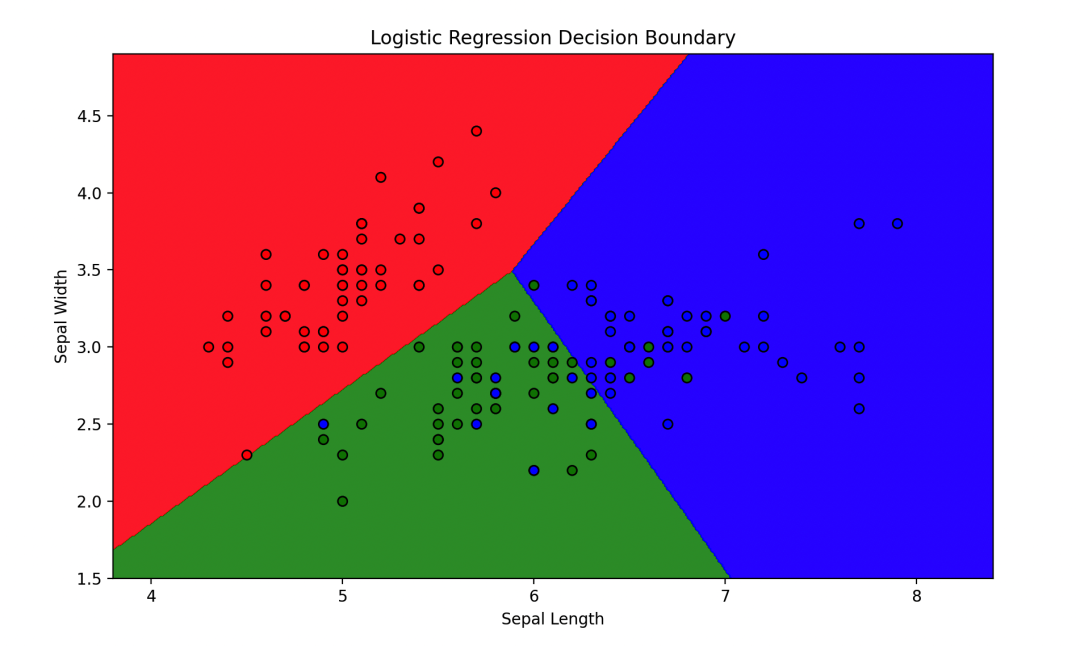
plt.figure(figsize=(10, 6))
plt.contourf(xx, yy, Z, alpha=0.8, cmap=ListedColormap(('red', 'green', 'blue')))
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=ListedColormap(('red', 'green', 'blue')), edgecolors='k')
plt.xlabel('Sepal Length')
plt.ylabel('Sepal Width')
plt.title('Logistic Regression Decision Boundary')
plt.show()
首先加载了鸢尾花数据集,并选择了其中的两个特征(花萼长度和宽度)。然后我们训练了一个逻辑回归模型,并在测试集上进行了预测。接着,我们计算了模型的准确率,并绘制了决策边界,以便可视化模型的分类效果。
决策树
一点介绍
决策树,用于解决分类和回归问题。它通过对数据集进行递归划分,构建一棵树,每个节点表示一个特征,每个叶节点表示一个类别或一个数值。决策树的主要思想是通过一系列简单的决策来对数据进行分类或预测。
基本原理
决策树的基本原理如下:
- 根据数据集中的特征,选择最优的特征进行划分。
- 递归地将数据集划分为子集,直到满足停止条件。
- 每个叶节点表示一个类别或一个数值。
具体而言,树的构建过程可以用以下公式表示:
- 特征选择:根据某个度量标准(如信息增益、基尼不纯度等),选择最优的特征进行划分。
- 划分规则:根据选定的特征和阈值,将数据集划分为子集。
推导决策树的构建过程通常基于信息论,常用的指标包括信息增益(ID3算法)、增益率(C4.5算法)、基尼不纯度(CART算法)等。
优缺点
优点:
- 简单直观:决策树易于理解和解释,不需要复杂的数学知识。
- 适用于非线性数据:决策树能够处理非线性关系,对数据的分布和特征之间的关系没有严格要求。
- 能够处理混合类型特征:决策树能够处理同时包含数值型和类别型特征的数据。
缺点:
- 容易过拟合:决策树容易过拟合训练数据,特别是对于高维数据集。
- 对噪声敏感:决策树对噪声和异常值比较敏感,可能导致不稳定的模型。
- 难以处理缺失值:决策树在处理缺失值时可能会出现问题,需要进行额外的处理。
适用场景
决策树适用于以下场景:
- 数据集包含混合类型的特征(数值型和类别型)。
- 需要建立一个可解释性强的模型,便于理解和解释模型的决策过程。
- 数据集的特征之间存在非线性关系或交互作用。
决策树是一种简单而强大的分类和回归算法,尤其适用于处理非线性数据和需要可解释性的情况。然而,在处理高维数据和噪声较多的情况下,可能需要采用一些改进的决策树算法或集成方法来提高模型的性能。
一个通透的案例
使用鸢尾花数据集(Iris dataset)。这个数据集包含了三种不同种类的鸢尾花的花萼和花瓣的长度和宽度。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, plot_tree
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 构建决策树模型
dt = DecisionTreeClassifier()
dt.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = dt.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
# 绘制决策树
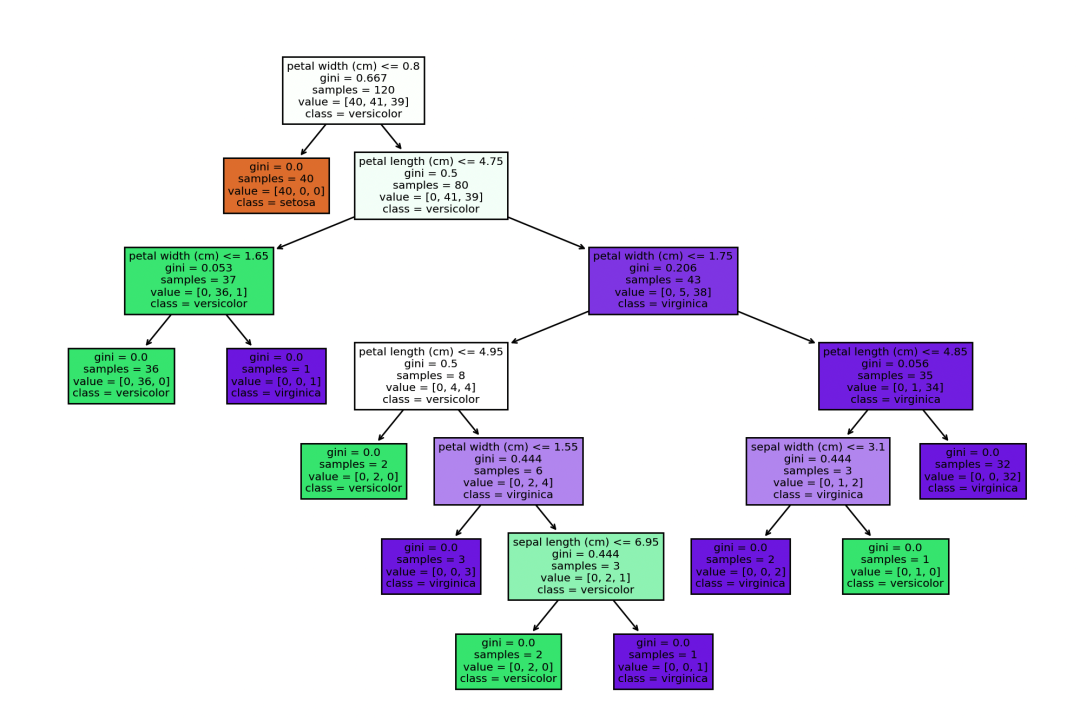
plt.figure(figsize=(12, 8))
plot_tree(dt, filled=True, feature_names=iris.feature_names, class_names=iris.target_names)
plt.show()
首先加载了鸢尾花数据集,并划分了训练集和测试集。然后我们构建了一个决策树分类器,并在测试集上进行了预测。最后,我们计算了模型的准确率,并绘制了决策树的结构图。
K近邻算法
一点介绍
K近邻算法是一种基于实例的监督学习算法,用于解决分类和回归问题。在K近邻算法中,每个样本都表示为特征空间中的一个点,分类或回归的结果取决于其 k 个最近邻居的投票或加权平均值。
基本原理
K近邻算法的基本原理如下:
- 对于每个待分类或预测的样本,计算其与训练集中所有样本的距离。
- 选择与待分类样本距离最近的 k 个训练样本。
- 对于分类问题,根据这 k 个样本中最常见的类别来决定待分类样本的类别;对于回归问题,根据这 k 个样本的平均值或加权平均值来估计待预测样本的数值。
核心公式
K近邻算法的核心公式是距离度量和投票机制。具体而言,K近邻算法中常用的距离度量是欧式距离(Euclidean distance):
其中,
和
是两个样本点,
是特征的数量。
推导 K近邻算法的过程主要涉及到对待分类样本与训练集中所有样本的距离进行计算,并选取距离最近的 k 个样本进行投票或加权平均。
优缺点
优点:
- 简单直观:K近邻算法易于理解和实现,无需对模型进行训练。
- 适用于多类别问题:K近邻算法可以处理多类别问题,并且对类别不平衡的数据集也比较有效。
- 适用于非线性数据:K近邻算法适用于非线性关系的数据。
缺点:
- 需要大量内存:K近邻算法需要保存整个训练集,因此对内存消耗较大。
- 预测速度较慢:对于大型数据集,预测速度较慢,因为需要计算待预测样本与所有训练样本的距离。
- 对异常值敏感:K近邻算法对异常值较为敏感,可能会影响预测结果。
适用场景
K近邻算法适用于以下场景:
- 数据集较小:当数据集规模较小且特征维度不高时,K近邻算法表现较好。
- 非线性数据集:对于非线性关系的数据集,K近邻算法通常表现良好。
- 需要解释性强的模型:K近邻算法能够提供直观的解释,因此适用于需要可解释性强的场景。
K近邻算法是一种简单而强大的监督学习算法,尤其适用于小型数据集和非线性数据集。然而,在处理大型数据集和高维数据时,K近邻算法的性能可能不如一些更复杂的算法。
一个通透的案例
使用手写数字识别数据集(MNIST dataset)。这个数据集包含了大量的手写数字图片及其对应的标签,我们将使用K近邻算法来对这些手写数字进行分类。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, confusion_matrix
# 加载手写数字数据集
digits = load_digits()
X = digits.data
y = digits.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 构建K近邻模型
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = knn.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
# 绘制混淆矩阵
conf_matrix = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(8, 6))
plt.imshow(conf_matrix, cmap='Blues')
plt.colorbar()
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
plt.title('Confusion Matrix')
plt.show()
# 随机选择一些样本并展示预测结果
plt.figure(figsize=(10, 8))
for i in range(10):
idx = np.random.randint(0, len(X_test))
image = X_test[idx].reshape(8, 8)
plt.subplot(2, 5, i+1)
plt.imshow(image, cmap='binary')
plt.title(f'Predicted: {y_pred[idx]}, Actual: {y_test[idx]}')
plt.axis('off')
plt.show()
首先加载了手写数字数据集,并划分了训练集和测试集。然后我们构建了一个K近邻分类器,并在测试集上进行了预测。接着,我们计算了模型的准确率,并绘制了混淆矩阵来评估模型的性能。
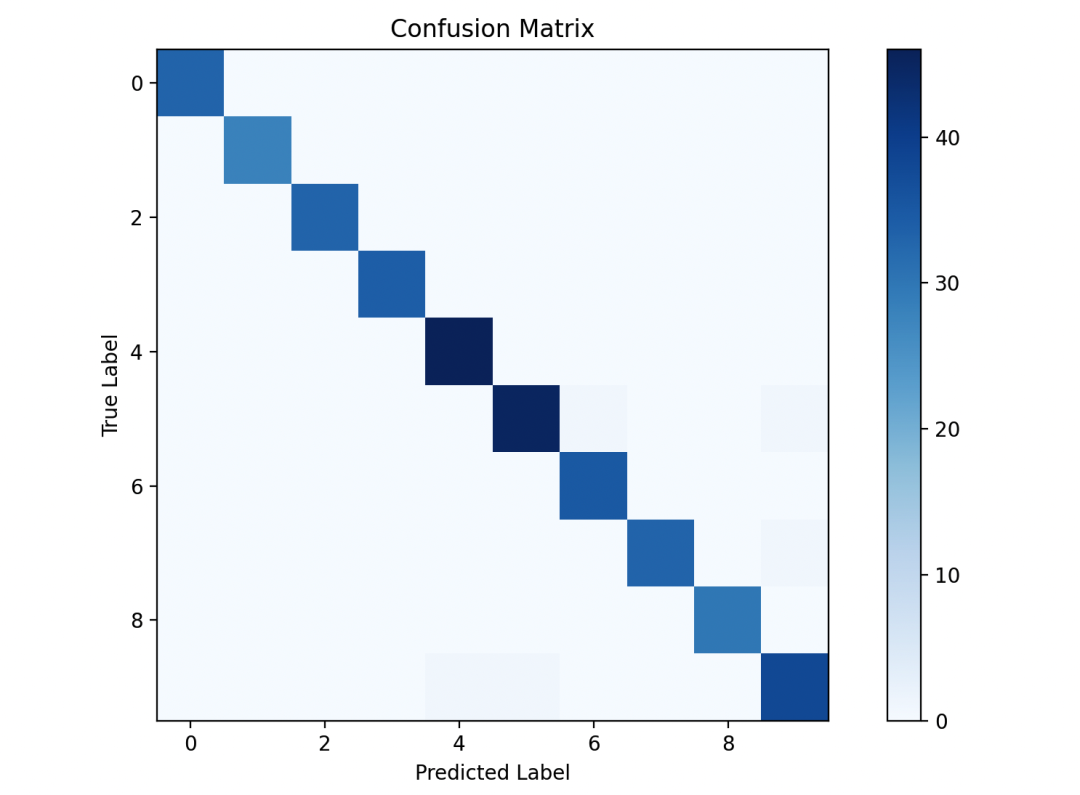
最后,我们随机选择了一些样本并展示了它们的预测结果。

支持向量机
一点介绍
支持向量机是一种监督学习算法,用于解决分类和回归问题。它通过在特征空间中找到一个最优的超平面来进行分类或回归,使得两个不同类别的样本点之间的间隔最大化。
基本原理
支持向量机的基本原理如下:
- 对于二分类问题,支持向量机试图找到一个超平面,将两个不同类别的样本点分隔开来。
- SVM选择的超平面是使得两个不同类别的样本点到该超平面的距离(间隔)最大化的平面。
- 支持向量机还引入了核函数的概念,可以将非线性问题转化为线性问题,从而在更高维的特征空间中进行分类或回归。
核心公式
支持向量机的核心公式是间隔最大化的优化问题。对于线性可分的情况,支持向量机的目标函数为:
其中,
是超平面的法向量,
是偏置项,
是训练样本,
是样本的类别标签。
推导支持向量机的过程主要涉及到最大化间隔和解决对偶问题,可以通过拉格朗日对偶性得到支持向量机的优化问题。
优缺点
优点:
- 有效处理高维数据:支持向量机在高维特征空间中表现良好,适用于处理高维数据。
- 泛化能力强:支持向量机通过最大化间隔,具有较好的泛化能力,对于避免过拟合有一定的帮助。
- 适用于非线性问题:支持向量机引入了核函数的概念,能够处理非线性关系的数据。
缺点:
- 计算复杂度高:支持向量机的训练时间复杂度较高,尤其是在处理大型数据集时。
- 对参数调节和核函数选择敏感:支持向量机的性能高度依赖于参数调节和核函数的选择,需要进行较多的调优工作。
- 不适用于大规模数据集:由于计算复杂度高,支持向量机对大规模数据集的处理能力较差。
适用场景
支持向量机适用于以下场景:
- 二分类和多分类问题:支持向量机可以应用于二分类和多分类问题。
- 高维数据集:支持向量机在处理高维数据集时表现良好。
- 非线性问题:支持向量机能够处理非线性关系的数据,并通过选择合适的核函数来实现。
支持向量机是一种强大的监督学习算法,尤其适用于处理高维数据和需要泛化能力强的情况。然而,在处理大规模数据集和参数调节方面,需要谨慎选择,并进行适当的调优工作。
一个通透的案例
以下是一个基于开源数据集的支持向量机(SVM)实例代码,使用的数据集是手写数字识别数据集(MNIST dataset)。我们将使用SVM算法来对手写数字进行分类。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, confusion_matrix
# 加载手写数字数据集
digits = load_digits()
X = digits.data
y = digits.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 构建支持向量机模型
svm = SVC(kernel='rbf', gamma='scale')
svm.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = svm.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
# 绘制混淆矩阵
conf_matrix = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(8, 6))
plt.imshow(conf_matrix, cmap='Blues')
plt.colorbar()
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
plt.title('Confusion Matrix')
plt.show()
# 随机选择一些样本并展示预测结果
plt.figure(figsize=(10, 8))
for i in range(10):
idx = np.random.randint(0, len(X_test))
image = X_test[idx].reshape(8, 8)
plt.subplot(2, 5, i+1)
plt.imshow(image, cmap='binary')
plt.title(f'Predicted: {y_pred[idx]}, Actual: {y_test[idx]}')
plt.axis('off')
plt.show()
在这个例子中,我们首先加载了手写数字数据集,并划分了训练集和测试集。然后我们构建了一个支持向量机分类器,并在测试集上进行了预测。接着,我们计算了模型的准确率,并绘制了混淆矩阵来评估模型的性能。
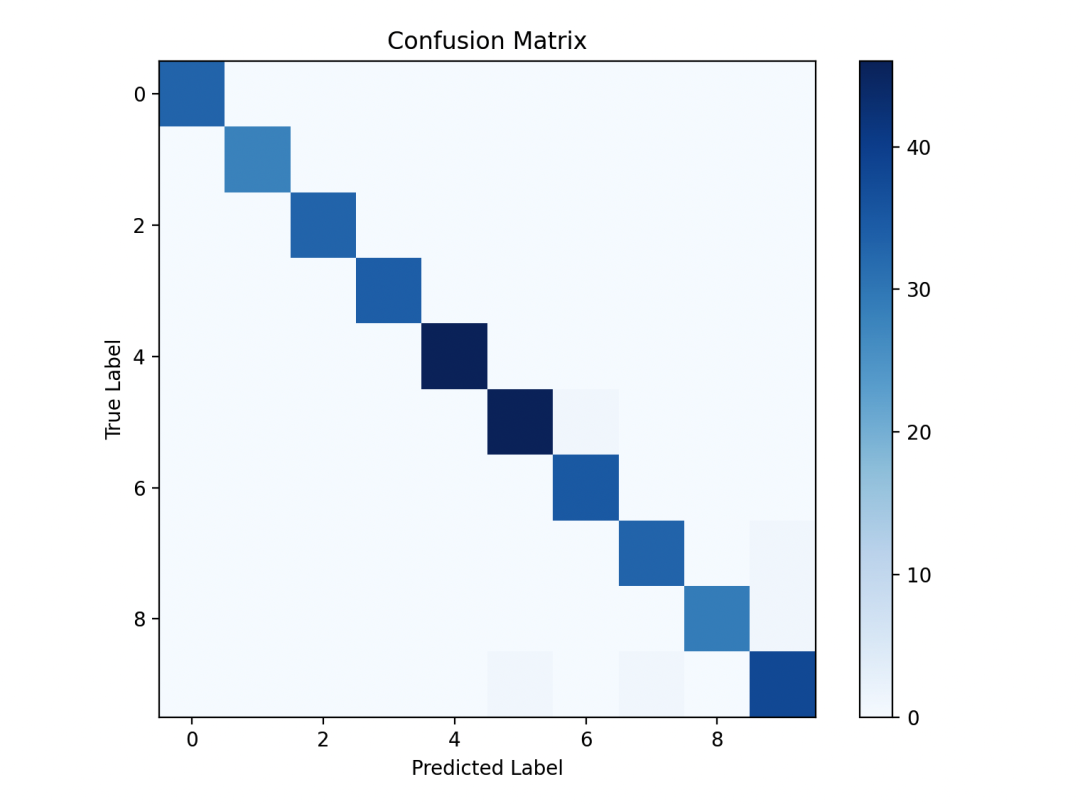
最后,我们随机选择了一些样本并展示了它们的预测结果。

朴素贝叶斯
一点介绍
朴素贝叶斯是一种基于贝叶斯定理的分类算法,它假设特征之间是独立的(即朴素假设),并利用贝叶斯定理来进行分类。朴素贝叶斯广泛应用于文本分类、垃圾邮件过滤、情感分析等领域。
基本原理
朴素贝叶斯的基本原理如下:
- 根据训练数据计算每个类别的先验概率和每个特征在各个类别下的条件概率。
- 对于给定的输入样本,计算其在各个类别下的后验概率。
- 根据后验概率选择最可能的类别作为样本的分类结果。
核心公式
朴素贝叶斯的核心公式是贝叶斯定理:
其中,
是类别
的先验概率,
是给定类别
下特征
的条件概率,
是特征
的先验概率。
推导朴素贝叶斯的过程主要涉及到条件概率的计算,通过朴素假设(特征之间相互独立)简化了条件概率的计算。
优缺点
优点:
- 简单高效:朴素贝叶斯算法简单易懂,计算效率高。
- 对小规模数据表现良好:在小规模数据集上,朴素贝叶斯通常表现很好,且不容易过拟合。
- 适用于多分类问题:朴素贝叶斯可以处理多分类问题,并且对类别不平衡的数据集也比较有效。
缺点:
- 对特征之间的依赖关系做了过强的假设:朴素贝叶斯假设特征之间是相互独立的,这在某些情况下可能不成立,导致分类性能下降。
- 对输入数据的分布假设较强:朴素贝叶斯通常假设输入特征的分布是正态分布,这在实际应用中可能不成立。
- 无法处理连续型特征:由于朴素贝叶斯算法基于概率模型,因此不能直接处理连续型特征,需要进行离散化处理。
适用场景
朴素贝叶斯适用于以下场景:
- 文本分类:朴素贝叶斯在文本分类任务中表现优异,尤其是处理大规模的文本数据。
- 垃圾邮件过滤:朴素贝叶斯可以有效地过滤垃圾邮件,减少用户收到的垃圾邮件数量。
- 多分类问题:朴素贝叶斯适用于多分类问题,对类别不平衡的数据集也有一定的鲁棒性。
朴素贝叶斯是一种简单而有效的分类算法,尤其适用于文本分类和多分类问题。然而,在处理特征之间存在依赖关系的情况下,朴素贝叶斯的性能可能会受到影响。
一个通透的案例
以下是一个基于开源数据集的朴素贝叶斯实例代码,使用的数据集是鸢尾花数据集(Iris dataset)。我们将使用朴素贝叶斯算法来对鸢尾花进行分类。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score, confusion_matrix
import seaborn as sns
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 构建朴素贝叶斯模型
nb = GaussianNB()
nb.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = nb.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
# 绘制混淆矩阵
conf_matrix = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(8, 6))
sns.heatmap(conf_matrix, annot=True, cmap='Blues', fmt='d')
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
plt.title('Confusion Matrix')
plt.show()
# 绘制特征的概率密度估计图
plt.figure(figsize=(10, 8))
for i in range(4):
plt.subplot(2, 2, i+1)
sns.histplot(X_train[:, i], kde=True, color='skyblue', label='Train', alpha=0.6)
sns.histplot(X_test[:, i], kde=True, color='salmon', label='Test', alpha=0.6)
plt.title(f'Feature {i+1} Distribution')
plt.xlabel('Feature Value')
plt.ylabel('Density')
plt.legend()
plt.tight_layout()
plt.show()
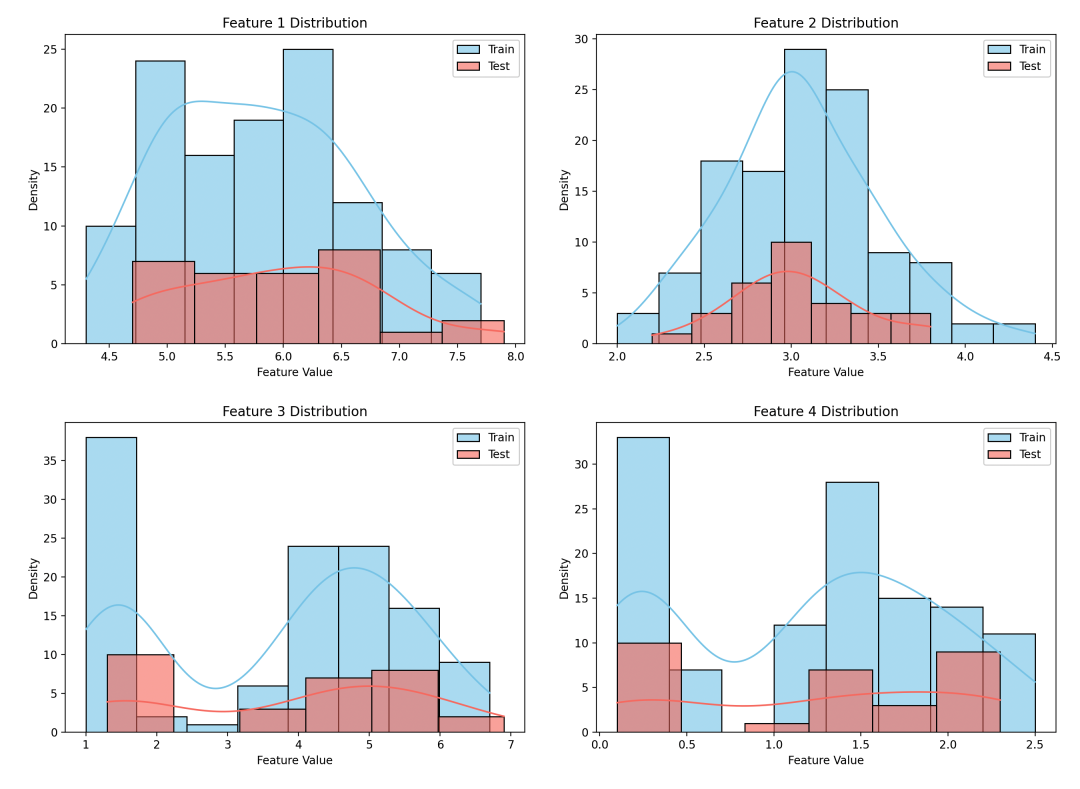
在这个例子中,我们首先加载了鸢尾花数据集,并划分了训练集和测试集。然后我们构建了一个朴素贝叶斯分类器,并在测试集上进行了预测。接着,我们计算了模型的准确率,并绘制了混淆矩阵来评估模型的性能。
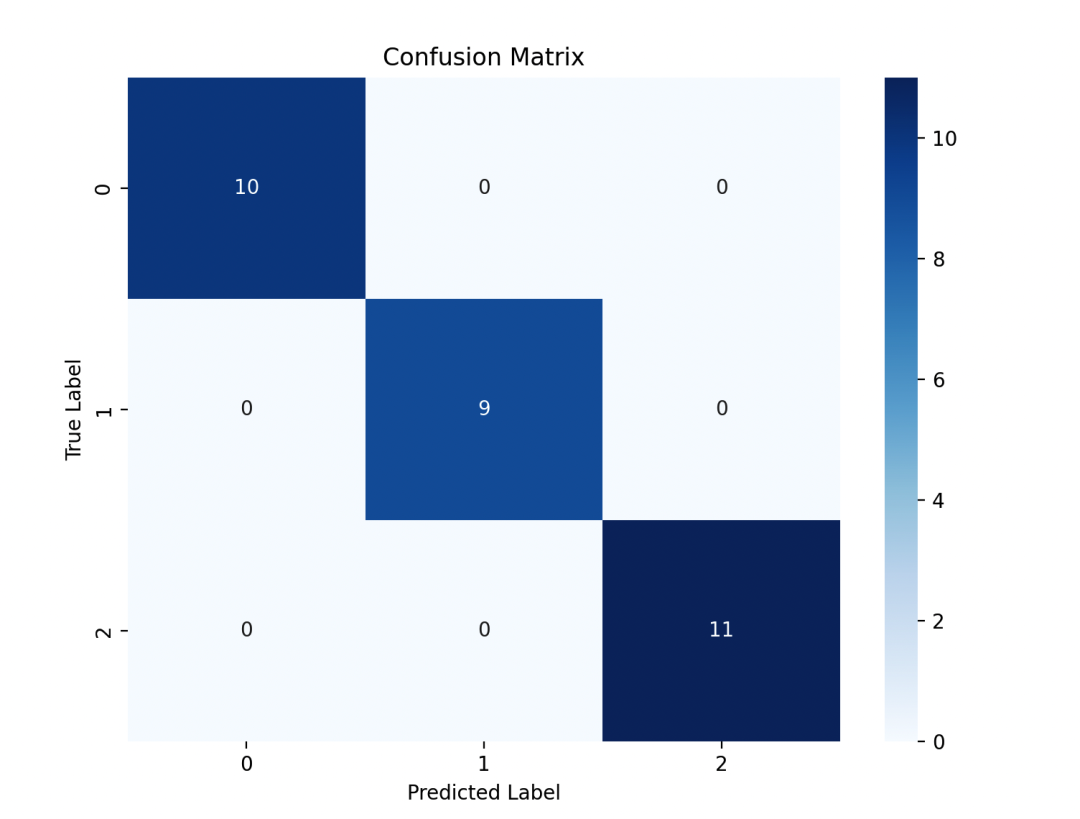
最后,我们绘制了特征的概率密度估计图,展示了训练集和测试集中特征的分布情况。
K均值聚类
一点介绍
K均值聚类是一种常用的无监督学习算法,用于将数据集分成 K 个不同的类别(簇),使得同一类别内的样本点彼此距离最近,不同类别之间的样本点距离最远。K均值聚类算法通过迭代优化来实现聚类,是一种简单而有效的聚类算法。
基本原理
K均值聚类的基本原理如下:
- 首先随机选择 K 个点作为初始的聚类中心。
- 对于每个样本点,计算其到每个聚类中心的距离,并将其归类到距离最近的聚类中心所属的类别。
- 更新每个类别的聚类中心,使得每个类别内的样本点到其聚类中心的距离最小化。
- 重复步骤2和步骤3,直到聚类中心不再发生变化或达到最大迭代次数。
核心公式
K均值聚类的核心公式包括计算样本点到聚类中心的距离以及更新聚类中心的公式。具体而言,距离的计算通常采用欧式距离:
其中,
是样本点,
是聚类中心,
是特征的数量。
推导K均值聚类的过程涉及到对样本点进行聚类并更新聚类中心,通过最小化每个类别内样本点到聚类中心的距离来优化聚类结果。
优缺点
优点:
- 简单高效:K均值聚类算法简单易懂,计算效率高。
- 可扩展性强:K均值聚类算法适用于大规模数据集,并且可以方便地进行分布式计算。
- 容易解释结果:K均值聚类产生的聚类结果直观,易于解释和理解。
缺点:
- 对初始聚类中心敏感:K均值聚类对初始聚类中心的选择较为敏感,不同的初始值可能导致不同的聚类结果。
- 需要指定聚类数K:K均值聚类算法需要事先指定聚类数K,对K的选择需要一定的领域知识或者通过试验确定。
- 对异常值敏感:K均值聚类对异常值较为敏感,可能会影响聚类结果的准确性。
适用场景
K均值聚类适用于以下场景:
- 数据集中类别的数量已知或者可以通过领域知识估计。
- 数据集的特征相对均匀分布,各个类别内样本点的方差相差不大。
- 需要快速对大规模数据集进行聚类。
K均值聚类是一种简单而有效的聚类算法,尤其适用于类别数量已知且数据集相对均匀分布的情况。然而,在处理异常值和需要确定聚类数量的情况下,K均值聚类的性能可能会受到一定影响。
一个通透的案例
下面是一个基于开源数据集的K均值聚类实例代码,使用鸢尾花数据集(Iris dataset)进行聚类,并展示聚类结果的可视化。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
from sklearn.preprocessing import StandardScaler
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 特征标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 使用PCA进行降维
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X_scaled)
# 构建K均值聚类模型
kmeans = KMeans(n_clusters=3, random_state=42)
kmeans.fit(X_scaled)
# 获取聚类中心和预测类别
cluster_centers = kmeans.cluster_centers_
y_pred = kmeans.labels_
# 可视化聚类结果
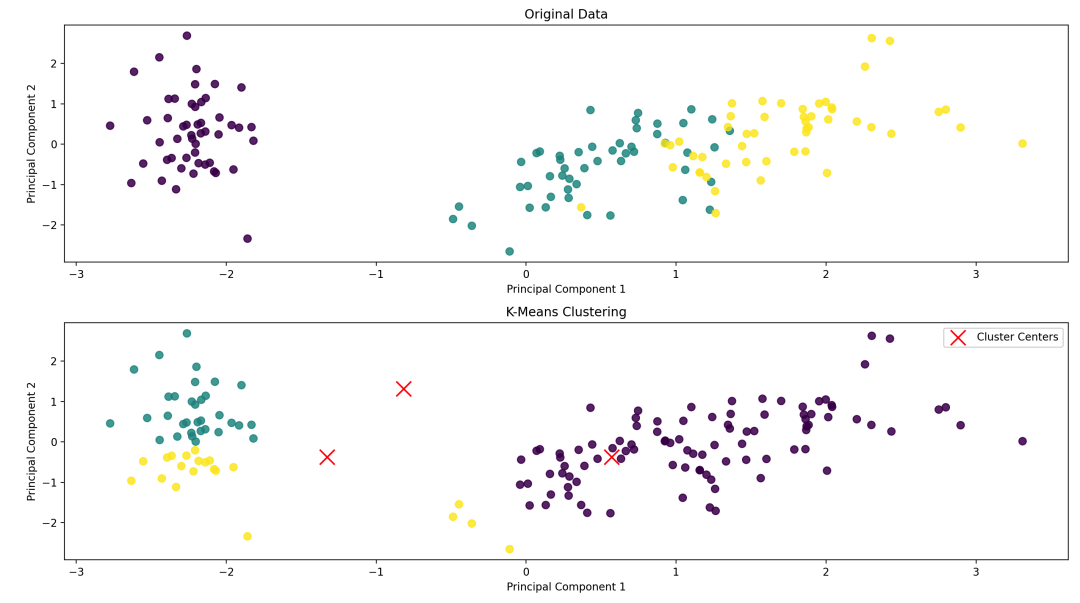
plt.figure(figsize=(10, 8))
# 绘制原始数据的散点图
plt.subplot(2, 1, 1)
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=y, cmap='viridis', s=50, alpha=0.8)
plt.title('Original Data')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
# 绘制聚类结果的散点图
plt.subplot(2, 1, 2)
plt.scatter(X_pca[:, 0], X_pca[:, 1], c=y_pred, cmap='viridis', s=50, alpha=0.8)
plt.scatter(cluster_centers[:, 0], cluster_centers[:, 1], c='red', marker='x', s=200, label='Cluster Centers')
plt.title('K-Means Clustering')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.legend()
plt.tight_layout()
plt.show()
在这个例子中,我们首先加载了鸢尾花数据集,并对数据进行了特征标准化和降维(使用PCA进行降维)。然后我们构建了一个K均值聚类模型,并在降维后的数据上进行了聚类。最后,我们通过绘制散点图展示了原始数据和聚类结果。
主成分分析
一点介绍
主成分分析是一种常用的降维技术,用于将高维数据集投影到低维空间中,同时保留数据集的主要特征。PCA通过寻找数据中最重要的方向(主成分),并将数据投影到这些方向上来实现降维。
基本原理
主成分分析的基本原理如下:
- 寻找数据集中最重要的方向(主成分),即数据集中方差最大的方向。
- 将数据投影到主成分所构成的低维空间中,实现数据的降维。
核心公式
PCA的核心公式是通过特征值分解来找到数据的主成分。设有样本集
,其中每个样本是一个列向量
,样本均值为
,样本协方差矩阵为
。则数据的主成分可通过以下步骤推导得到:
- 计算样本均值向量:
- 计算样本中心化矩阵:
- 计算样本协方差矩阵:
- 对协方差矩阵进行特征值分解:
- 特征向量
即为数据的主成分,对应的特征值
表示数据在该主成分上的方差。
优缺点
优点:
- 降低数据维度:PCA能够将高维数据降维到较低维度,减少数据存储和计算成本。
- 保留数据主要特征:PCA通过保留数据集中方差最大的方向,尽可能地保留了数据的主要特征。
- 减少数据噪音:PCA可以将数据投影到主成分上,减少数据中的噪音和冗余信息。
缺点:
- 对线性关系敏感:PCA假设数据是线性相关的,对非线性关系的数据降维效果可能不佳。
- 可解释性差:PCA得到的主成分通常难以解释其含义,因为它是数据的线性组合。
- 对异常值敏感:PCA对异常值较为敏感,可能会影响主成分的计算结果。
适用场景
主成分分析适用于以下场景:
- 数据维度较高:当数据维度较高时,可以使用PCA将数据降维到较低维度。
- 数据存在多重共线性:当数据中存在多重共线性(即特征之间存在线性相关性)时,PCA可以减少特征之间的冗余信息。
- 数据可视化:PCA可以将高维数据可视化到二维或三维空间中,帮助人们理解数据的结构和特征。
主成分分析可以帮助我们减少数据的维度并保留数据的主要特征。然而,在使用PCA时需要注意数据的线性关系和异常值的影响。
一个通透的案例
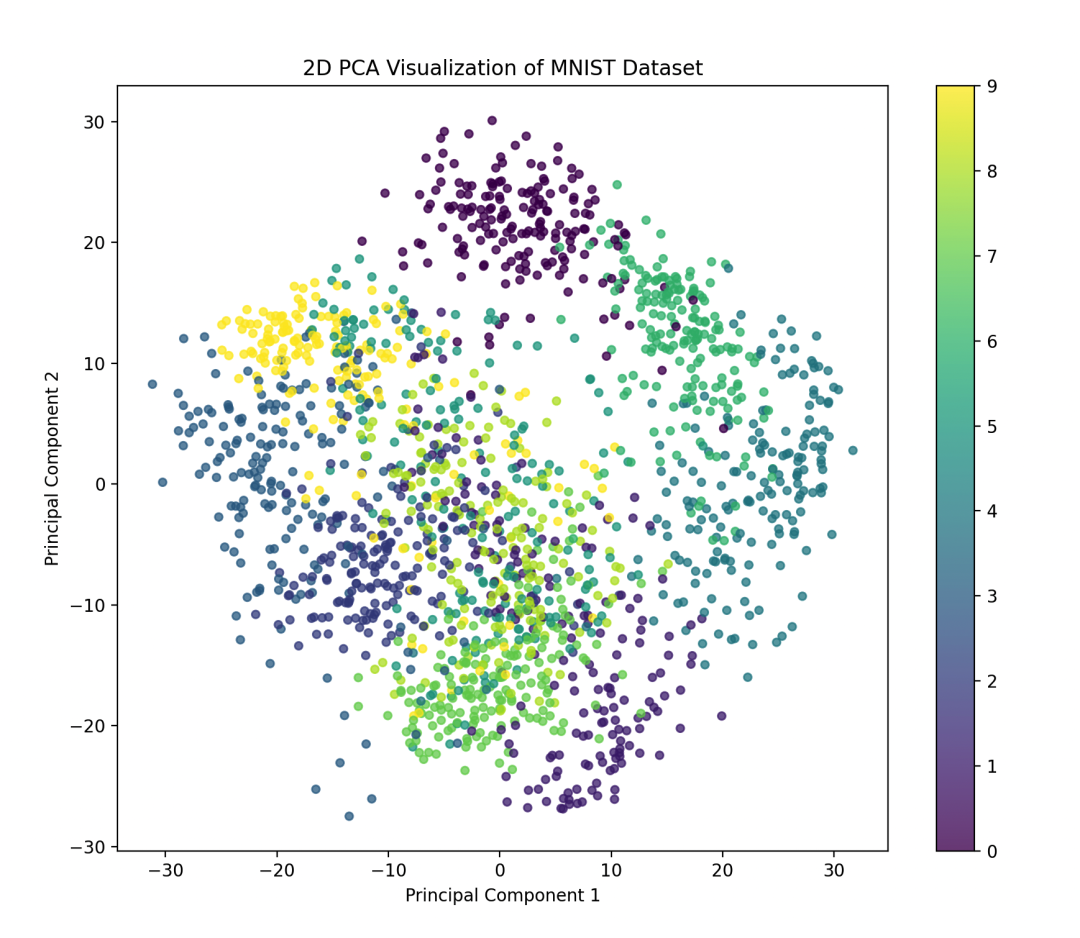
我们使用手写数字识别数据集(MNIST dataset)进行主成分分析,并展示降维后的数据可视化结果。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.decomposition import PCA
# 加载手写数字识别数据集
digits = load_digits()
X = digits.data
y = digits.target
# 构建PCA模型并拟合数据
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X)
# 可视化降维后的数据
plt.figure(figsize=(10, 8))
scatter = plt.scatter(X_pca[:, 0], X_pca[:, 1], c=y, cmap='viridis', s=20, alpha=0.7)
plt.colorbar(scatter)
plt.title('2D PCA Visualization of MNIST Dataset')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.show()
在这个例子中,我们首先加载了手写数字识别数据集,并使用PCA将数据降维到2维空间。然后我们绘制了降维后的数据的散点图,其中每个点代表一个手写数字样本,不同颜色代表不同的数字类别。
随机森林
一点介绍
随机森林通过构建多个决策树来完成分类或回归任务。随机森林的核心思想是通过多个弱学习器(决策树)的集成来构建一个强学习器,从而提高模型的泛化能力和稳定性。
基本原理
随机森林的基本原理如下:
- 从训练集中随机抽取一定数量的样本(有放回抽样),构建一个决策树(称为自助采样法或bootstrap采样)。
- 在每个决策树的节点上,随机选择一部分特征进行划分。
- 对每棵树进行训练,直到达到指定的树的数量。
- 对于分类问题,采用投票法来确定最终的分类结果;对于回归问题,采用平均法来确定最终的回归结果。
优缺点
优点:
- 高准确性:随机森林能够取得较高的准确性,在许多数据集上都有良好的表现。
- 抗过拟合能力强:随机森林能够有效地降低过拟合的风险,因为它对多个决策树的预测结果进行了集成。
- 能够处理高维数据:随机森林能够处理高维数据和大规模数据集,并且不需要进行特征选择。
缺点:
- 模型解释性较差:由于随机森林是一个集成模型,因此难以解释单个决策树的预测过程。
- 训练时间较长:由于需要构建多棵决策树并集成它们的结果,随机森林的训练时间较长。
- 对噪声敏感:随机森林对噪声和异常值比较敏感,可能会影响模型的性能。
适用场景
随机森林适用于以下场景:
- 分类和回归问题:随机森林适用于分类和回归问题,并且在许多不同类型的数据集上都有良好的表现。
- 大规模数据集:随机森林能够处理大规模数据集,并且不需要进行特征选择,因此适用于处理高维数据和大规模数据集。
- 数据特征具有复杂交互关系:随机森林能够有效地处理数据特征之间的复杂交互关系,因此适用于处理特征之间存在较强关联性的问题。
总之,随机森林是一种强大的集成学习算法,具有高准确性和抗过拟合能力强的优点,适用于处理多种类型的分类和回归问题。然而,在解释模型结果和训练时间方面可能存在一些挑战。
一个通透的案例
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from matplotlib.colors import ListedColormap
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data[:, [2, 3]] # 取特征的后两个维度
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 构建随机森林模型
rf_clf = RandomForestClassifier(n_estimators=100, random_state=42)
rf_clf.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = rf_clf.predict(X_test)
# 计算模型准确率
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
# 可视化决策边界
def plot_decision_regions(X, y, classifier, test_idx=None, resolution=0.02):
markers = ('s', 'x', 'o', '^', 'v')
colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan')
cmap = ListedColormap(colors[:len(np.unique(y))])
x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1
x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution), np.arange(x2_min, x2_max, resolution))
Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T)
Z = Z.reshape(xx1.shape)
plt.contourf(xx1, xx2, Z, alpha=0.4, cmap=cmap)
plt.xlim(xx1.min(), xx1.max())
plt.ylim(xx2.min(), xx2.max())
for idx, cl in enumerate(np.unique(y)):
plt.scatter(x=X[y == cl, 0], y=X[y == cl, 1], alpha=0.8, c=[cmap(idx)], marker=markers[idx], label=cl, edgecolor='black')
if test_idx:
X_test, y_test = X[test_idx, :], y[test_idx]
plt.scatter(X_test[:, 0], X_test[:, 1], c='', edgecolor='black', alpha=1.0, linewidth=1, marker='o', s=100, label='Test Set')
plot_decision_regions(X_train, y_train, classifier=rf_clf)
plt.title('Random Forest Classifier - Decision Boundary (Training Set)')
plt.xlabel('Petal Length (cm)')
plt.ylabel('Petal Width (cm)')
plt.legend(loc='upper left')
plt.show()
在这个例子中,我们首先加载了鸢尾花数据集,并将特征选取为后两个维度以便在二维平面上可视化。然后我们构建了一个随机森林分类器,并在训练集上训练模型。接着,我们使用plot_decision_regions函数绘制了训练集的决策边界,其中不同颜色的区域表示不同类别的决策区域。
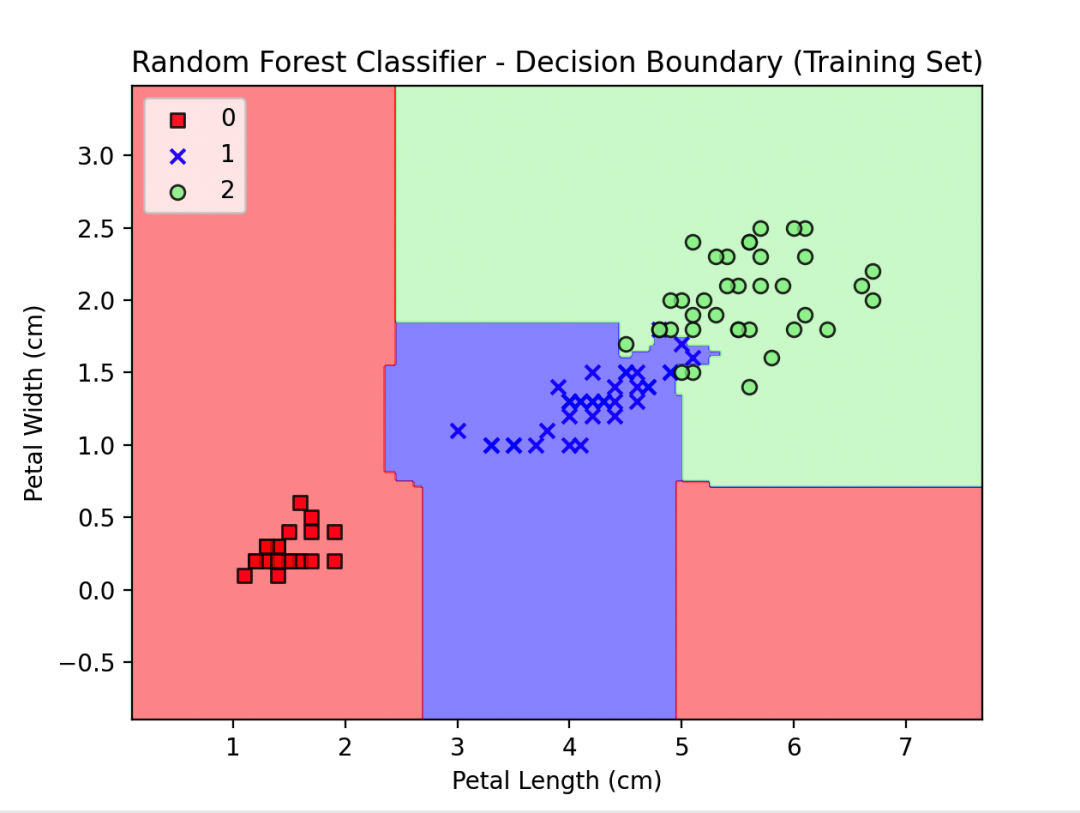
这个实例展示了如何使用随机森林算法对复杂的开源数据集进行分类,并通过绘制决策边界的可视化结果来展示模型的性能。
神经网络
一点介绍
神经网络是一种受到生物神经网络启发的机器学习模型,它由多层神经元组成,每一层都与下一层全连接。
神经网络通过学习数据之间的复杂关系来完成各种任务,如分类、回归、聚类等。
基本原理
神经网络的基本原理如下:
- 前向传播(Forward Propagation):从输入层开始,通过每一层的权重和激活函数,计算得到输出值。
- 反向传播(Backward Propagation):根据输出值和真实标签之间的误差,通过梯度下降算法,更新每一层的权重,使得误差最小化。
核心公式
神经网络的核心公式包括前向传播和反向传播的过程。在前向传播过程中,每一层的输出可以通过以下公式计算得到:
其中,
是第
层的加权输入,
是第
层的激活值,
是第
层的权重,
是第
层的偏置,
是激活函数。
在反向传播过程中,通过计算损失函数对权重和偏置的梯度,然后利用梯度下降算法更新权重和偏置,使得损失函数最小化。
优缺点
优点:
- 可以处理复杂关系:神经网络能够学习和表示复杂的非线性关系,适用于处理各种复杂的数据模式。
- 适用于大规模数据:神经网络可以有效地处理大规模数据集,具有较强的扩展性。
- 具有自适应性:神经网络能够通过学习数据自动调整权重和偏置,具有较强的自适应能力。
缺点:
- 需要大量数据和计算资源:神经网络需要大量的数据和计算资源来训练模型,尤其是深度神经网络。
- 可解释性差:神经网络通常是黑箱模型,难以解释模型的预测过程和结果。
- 容易过拟合:神经网络容易在训练集上过拟合,需要通过调整模型结构和正则化等方法来缓解过拟合问题。
适用场景
神经网络适用于以下场景:
- 图像识别和处理:神经网络在图像处理领域表现出色,如图像分类、目标检测、图像生成等。
- 自然语言处理:神经网络能够处理文本数据,包括文本分类、情感分析、机器翻译等任务。
- 预测和回归:神经网络能够处理时间序列数据和回归问题,如股票预测、销售预测等。
神经网络能够学习和表示复杂的数据关系,适用于处理各种类型的任务。然而,在使用神经网络时需要考虑到数据量、计算资源、模型结构等因素。
一个通透的案例
使用手写数字识别数据集(MNIST dataset)进行图像分类,并展示训练过程中的损失曲线和模型的分类准确率。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import accuracy_score
# 加载手写数字识别数据集
digits = load_digits()
X = digits.data
y = digits.target
# 数据标准化
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# 构建神经网络模型
mlp = MLPClassifier(hidden_layer_sizes=(100, 50), activation='relu', solver='adam', max_iter=500, random_state=42)
# 训练模型
history = mlp.fit(X_train, y_train)
# 预测并计算准确率
y_pred = mlp.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
# 绘制训练过程中的损失曲线
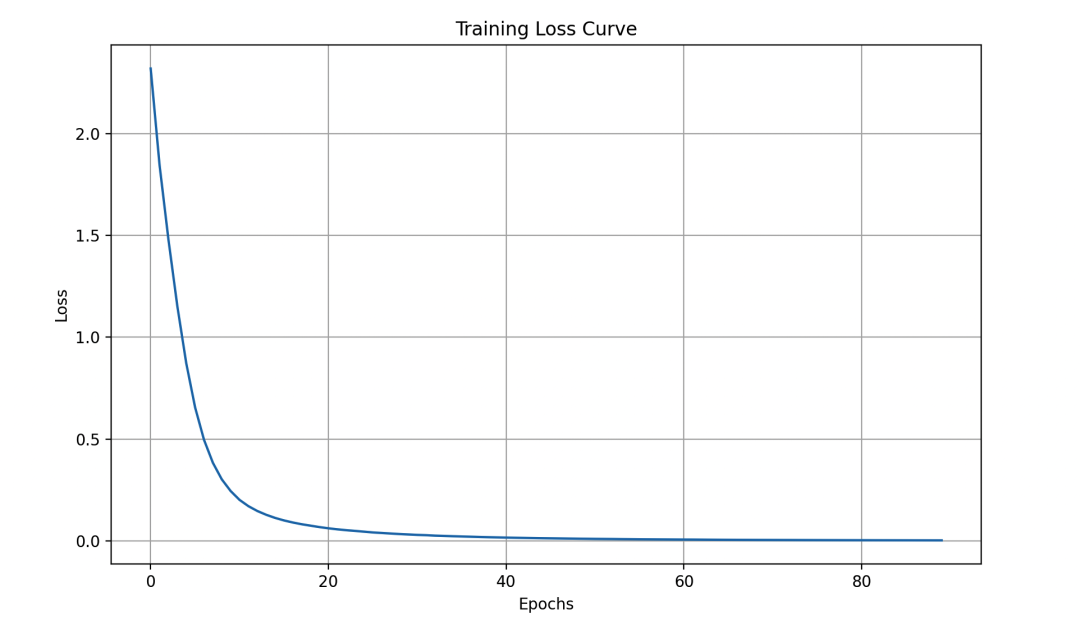
plt.figure(figsize=(10, 6))
plt.plot(history.loss_curve_)
plt.title('Training Loss Curve')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.grid(True)
plt.show()
在这个例子中,我们首先加载了手写数字识别数据集,并对数据进行了标准化处理。然后,我们构建了一个具有两个隐藏层的神经网络模型,并在训练集上训练了模型。接着,我们使用测试集对模型进行评估,并计算了模型的分类准确率。最后,我们绘制了训练过程中的损失曲线,以便观察模型的收敛情况。