Linux| Awk 中“next”命令奇用
Linux| Awk 中“next”命令奇用

科学冷冻工厂
发布于 2024-04-15 15:32:24
发布于 2024-04-15 15:32:24
简介
本文[1]介绍了在Linux中使用Awk的next命令来跳过剩余的模式和表达式,读取下一行输入的方法。
next命令
在 Awk 系列教程中,本文要讲解如何使用 next 命令。这个命令能让 Awk 跳过所有你已经设置的其他模式和表达式,直接读取下一行数据。
使用 next 命令可以避免执行那些我认为在命令执行过程中会浪费时间的步骤。
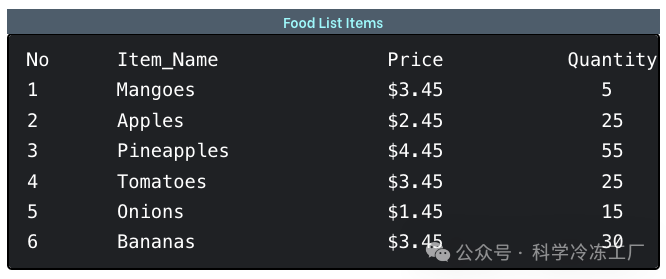
为了更好地理解其工作原理,本文以一个名为 food_list.txt 的文件为例,文件内容如下:
想象一下执行这样一个命令:它会在每一行的末尾加上 (*) 符号,这样做是为了标出那些数量不超过 20 的食品项目。
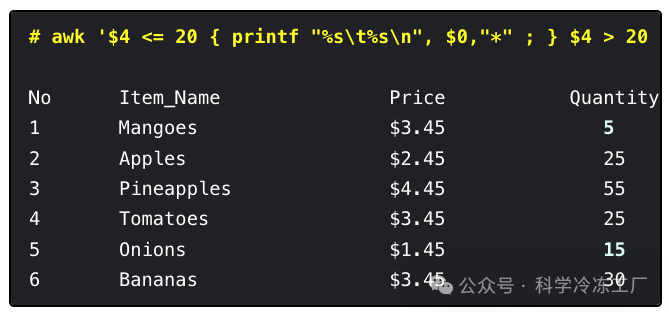
具体来说,上面的命令是这样执行的:
- 首先,它会检查每一行的第四个数据(即数量)是否不超过 20。如果符合这个条件,这条记录就会被打印出来,并且在行尾加上 (*) 符号,这一步骤通过表达式 $4 <= 20 来实现。
- 接下来,命令会判断每一行的第四个数据是否大于 20,如果是的话,这条记录也会被打印出来,这一步是通过另一个表达式 $4 > 20 来完成的。
但这里存在一个问题:在执行第一个表达式、通过 { printf "%s\t%s\n", $0,"**" ; } 打印并标记本文想要的行之后,程序还会去检查第二个表达式,这实际上是在浪费时间。
既然使用第一个表达式已经打印并标记了相关行,那么就没必要再去执行第二个表达式 $4 > 20 了。
要解决这个问题,本文可以使用 next 命令,操作如下:
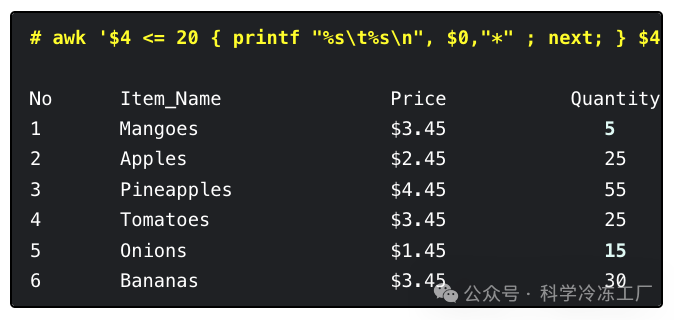
在通过 4 <= 20 { printf "%s\t%s\n",
next 命令对于提高命令的执行效率至关重要,当需要时,它可以显著加快脚本的运行速度。
本文参与 腾讯云自媒体分享计划,分享自微信公众号。
原始发表:2024-04-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录