CVPR 2024 | 面部+肢体动画,一个框架搞定从音频生成数字人表情与动作
CVPR 2024 | 面部+肢体动画,一个框架搞定从音频生成数字人表情与动作

- 论文地址:https://arxiv.org/abs/2401.00374
- 项目主页:https://pantomatrix.github.io/EMAGE/
- 视频结果:https://www.youtube.com/watch?v=T0OYPvViFGE
- hugging face space 链接:https://huggingface.co/spaces/H-Liu1997/EMAGE
EMAGE 研究论文包含 BEAT2 与 EMAGE 两部分。用户可以自定义动作的输入,在接受预定义的时序与空间的动作输入方面具有灵活性,最终可生成完整的、与音频相同步的结果,EMAGE 输出全身动作的效果属于业界 SOTA。
- BEAT2: 即 BEAT-SMPLX-FLAME,是语音与基于网格的动作数据的全身数据集,共有 60 小时的数据。BEAT2 将 SMPLX 的肢体与 FLAME 的面部参数相结合,并进一步解决了头部、颈部和手指等运动的模型问题,为研究社区提供了一个标准化且高质量的 3D 动捕数据集。


左:将精调后的 SMPLX 肢体参数结果(Refined Moshed)与 BEAT 的原始骨架数据(BEAT)、使用 AutoRegPro 的重定向数据(Retargeted)以及 Mosh++ 的初始结果(Moshed)进行比较,精调的结果拥有正确的颈部弯曲、适当的头颈形状比例和详细的手指弯曲。
右:将原始 BEAT 中的混合表情权重可视化,与 ARKit 的基础脸部模板(BEAT)、基于线性 Wrapped 的方法(Wrapped Optimum)以及人工 PCA 映射 FACs 的表情优化(Handcraft Optimum)进行比较。最终的人工映射优化基于 FLAME 混合表情,实现了准确的唇动细节和自然对话时的口型。
- EMAGE:在训练过程中利用了肢体动作掩码的先验知识来提高推理性能。EMAGE 使用了一个音频与动作掩码的转换器,有效提高了音频生成动作和动作掩码下的动作重建的联合训练的效率,从而有效地将音频和肢体动作的提示帧编码进网络。动作掩码的肢体提示帧分别被用于生成面部和肢体动作。此外,EMAGE 自适应地合并了音频的节奏和内容的语音特征,并利用身体各个部位 (共计四种) 的组合式 VQ- VAEs 来增强结果的真实性和多样性。
下图给出了 EMAGE 生成肢体动画的例子:

从上到下依次为:真实数据、不使用肢体提示帧生成的数据、使用肢体提示帧生成的数据、肢体提示帧的可视化:
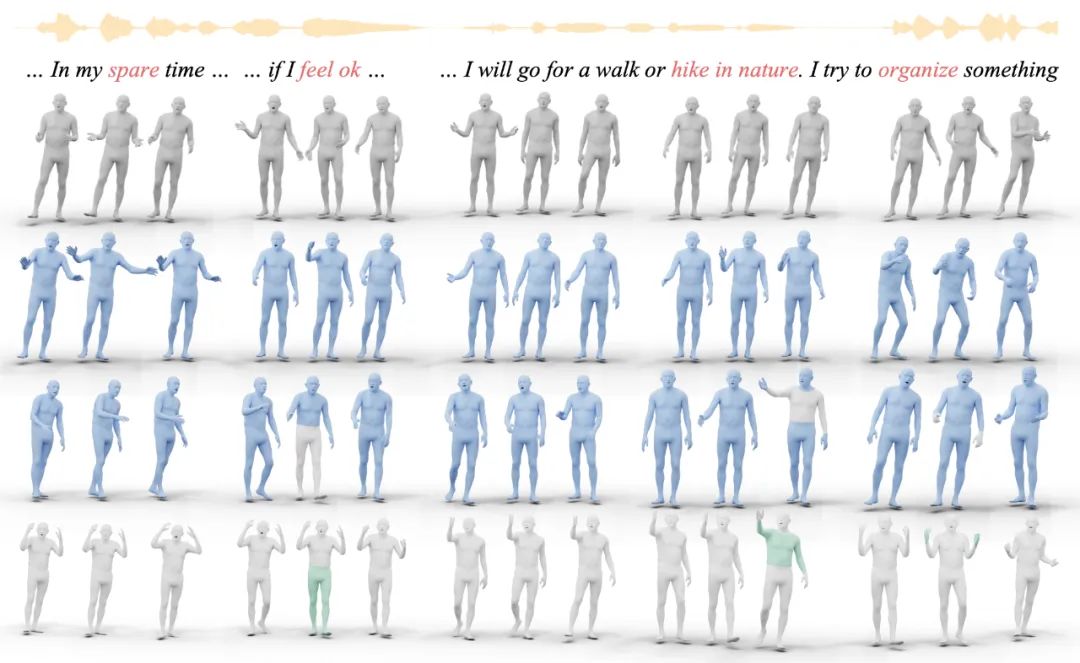
EMAGE 可以生成多样化、具有语义和与音频同步的肢体动作,例如,对于 “spare time” 这个提示词,可以同时举起双手,而对于 “hike in nature” 则可以采取放松的动作。
此外,如第三行和第四行所示,EMAGE 可以灵活地接受非音频同步的肢体提示帧,基于任意帧或关节,以此明确引导生成的动作。例如,重复类似的动作比如举起双手,或是改变行走方向等。注:此图中,第三列的生成结果的关节提示(灰色网格),与第四行的肢体提示帧的关节(绿色网格)并不一致。
下图是 EMAGE 生成面部动画的结果:

EMAGE 生成的面部运动与基线模型的对比。
分别是脸部单独生成的方法如 faceformer 与 codetalker、全身整体动作生成方法如 Habibie et al. 和 Talkshow。在 BEAT2 数据集中,因为 codetalker 具有离散的面部先验知识,所以即使 codetalker 的 MSE(均方误差)更高,即更偏离真实数据,但主观结果更好。而 EMAGE 则利用离散的面部先验知识和动作掩码的肢体提示帧,实现了更精准的唇动性能。
模型介绍
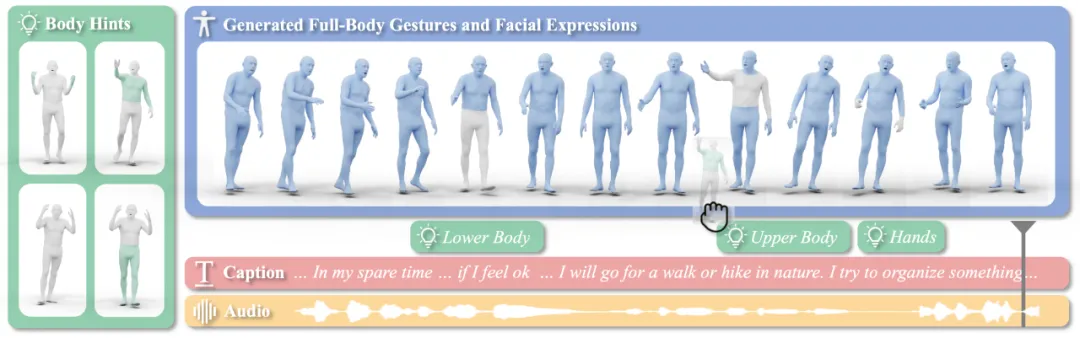
EMAGE 是一个支持用户自定义输入,带有动作掩码与音频输入的全身动作建模框架,使用新提出的数据集 BEAT2(BEAT-SMPLX-FLAME),生成面部表情、局部身体动作、手部动作和全局平移运动时,是以音频与动作掩码作为基准联合训练。灰色身体部位是用户输入的肢体提示帧,蓝色表示整体的网络输出。
算法细节
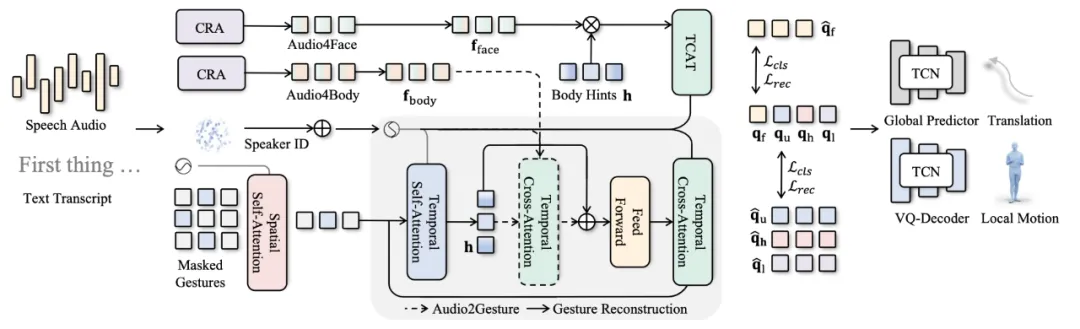
EMAGE 采取了两种训练路线:动作掩码重建(MaskedGesture2Gesture,即 MG2G)和使用音频的动作生成(Audio2Gesture,即 A2G)。
- MG2G:通过基于 Transformer 的动作的时空编码器与基于交叉注意力的动作解码器,来对肢体提示帧进行编码。
- A2G:利用输入的肢体提示与独立的的音频编码器,对于经过预训练的面部和肢体潜征进行解码。
可切换的交叉注意力层在上述过程中作为关键组件,对于合并肢体提示帧和音频特征起重要作用。此融合使特征被有效地解耦并可以被用于动作的解码。动作潜征被重建之后,EMAGE 使用预训练的 VQ-Decoder 来对于面部和局部肢体运动进行解码。
此外,预训练的全局运动预测器也被用来估计全身的全局平移,使得模型生成逼真并且连贯动作的能力得到加强。
CRA 和 VQ-VAEs 的与训练模型的细节
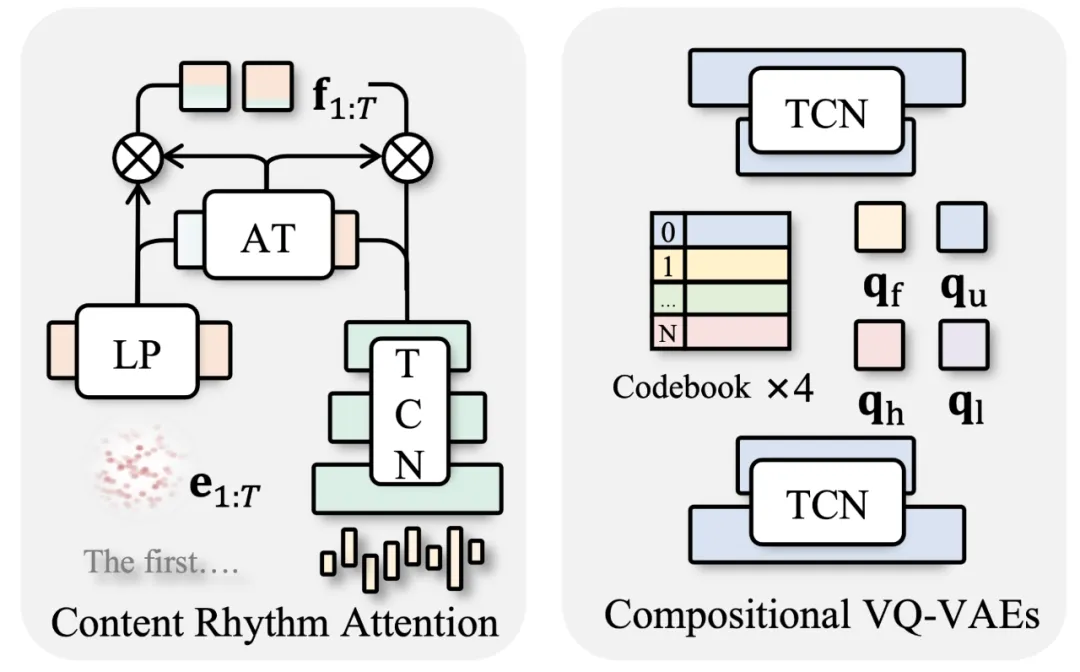
左图:内容节奏注意力模块 (CRA) 将音频的节奏(初始语音和振幅)与内容(来自文本的预训练词条嵌入)自适应地相融合。这种架构可以让特定帧更有效地基于音频的内容或节奏,生成更加具有语义的动作。
右图:通过对于面部、肢体上半身、手部和肢体下半身的分别重建,来预训练四个组合式 VQ-VAEs 模型,以更加明示地将与音频无关的动作相解耦。
前向传播网络对比
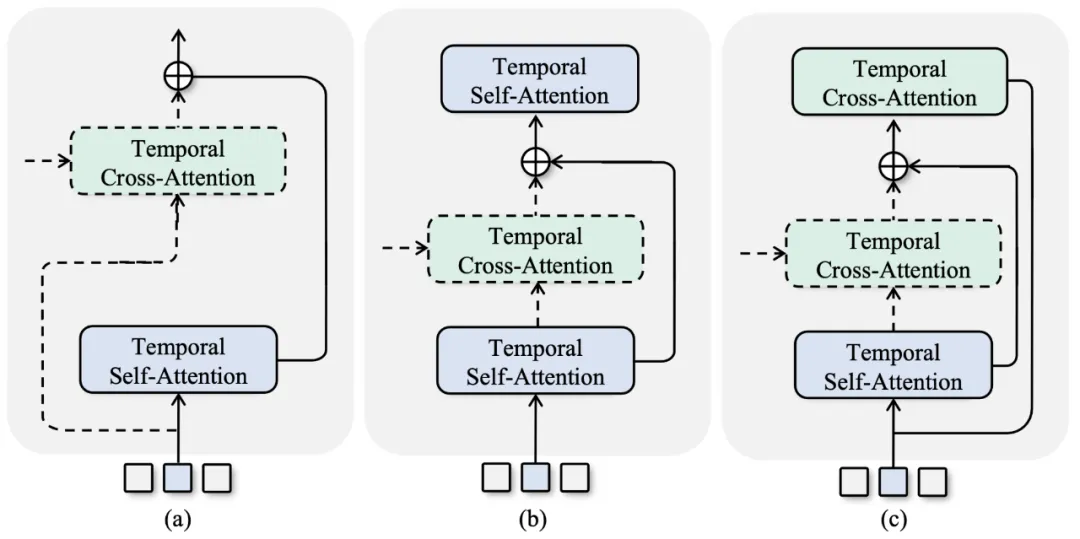
- 直接融合模块 (a) : 将音频特征与未精调的肢体特征合并,仅基于位置嵌入重组音频特征。
- 自注意力解码器模块 (b) : 为 MLM 模型中所采用的模块,只限于自回归推理的任务。
- EMAGE (c) : 融合 (a) 与 (b) 的长处,同时使音频特征融合更有效,且可以自回归解码。
再和大家说说我们之前做的《100个超强机器学习算法模型》。
一个人走的很快,但一群人会走的很稳,放假的小伙伴,趁着假期可以按照每一个算法模型,学习一番。