为啥我敢说Python是数据分析界的扛把子语言?
为啥我敢说Python是数据分析界的扛把子语言?

首先声明下这篇文字不是卖课的,也不是无脑吹Python,咱只讲事实,认认真真讨论下Python是不是数据分析领域最好的语言。
因为我在知乎上看到非常多人在问这个问题,想必大家是关心的。


我的观点是,目前来看所有编程语言里,做数据分析Python是最好的选择,没有之一。
列举几个事实:
1、Kaggle、天池等数据比赛用的最多的语言是Python,其次是R语言。
2、最新4月TIOBE编程语言排名,Python断层第一,流行度16.41%,第二是C语言,约10.21%。
3、NASA处理黑洞图片所用的工具是Python,Python在NASA内部被广泛用于航天数据处理分析。
4、Chatgpt算法和后端大规模使用Python,其官方接口就有Python api。
Python作为数据分析的热门语言有它的必然性,我理解有三个方面原因。
一、Python拥有大量数据科学第三方库
这些第三方库拿来即用,广泛用于数学计算、数据处理、数据建模、数据可视化、机器学习等等,极大的节省了数据分析的软硬件成本。

- pandas:python中的Excel,用于数据处理、分析,非常方便。
- numpy:用于数组计算的库,大部分机器学习、深度学习都基于numpy。
- scipy:用于数学和工程计算的库,堪比Matlab。
- Scikit-Learn:集合了几乎所有机器学习模型的库,拿来即用,非常方便。
- Matplotlib:用于绘制可视化图表的库,没有什么是它画不了的图。
其他的就更多了,不一一赘述。
二、Python有Jupyter notebook这样专门用于数据科学的开发平台
Kaggle、天池就是基于notebook提供数据分析服务,很多公司的数据分析平台也是基于notebook,搭建在私有或公有云上。
Jupyter是集编程、笔记、数据分析、机器学习、可视化、教学演示、交互协作等于一体的超级web应用,而且支持python、R、Julia、Scala等超40种语言。
虽然说支持这么多语言,但Python是Jupyter最好的搭档,因为Python有IPython。
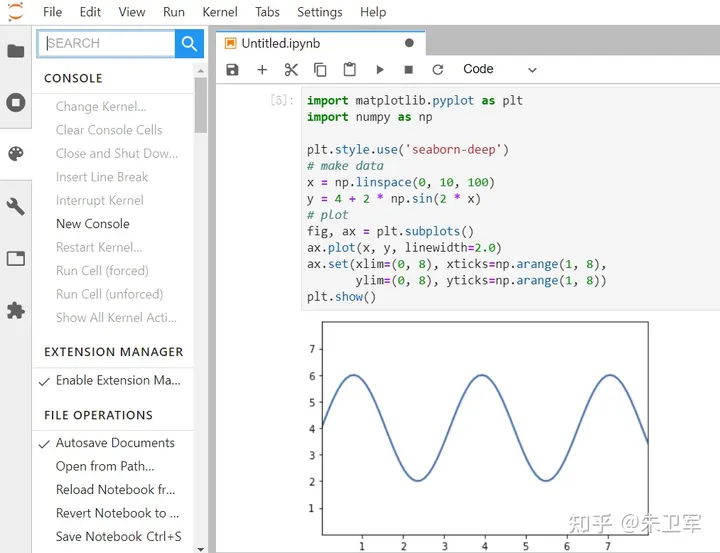
Jupyter最大的特点是代码即写可即运行,其可被应用于全过程计算:开发、文档编写、运行代码和展示结果。
比如我用matplotlib绘制一张曲线图,只需要输入脚本代码并执行,便可以在Jupyter上显示相应图表。
Jupyter中所有交互计算、编写说明文档、数学公式、图片以及其他富媒体形式的输入和输出,都是以文档的形式体现的。
这些文档是保存为后缀名为.ipynb的JSON格式文件,不仅便于版本控制,也方便与他人共享。

此外,文档还可以导出为:HTML、LaTeX、PDF等格式。
Jupyter还支持安装插件,和VsCode类似。插件类型也很丰富,包括了代码调试、可视化、文本编辑等等。
既然同样是编程工具,那Jupyter和Pycharm、VsCode的使用场景有什么区别呢?
Jupyter主要是用来做数据科学,其包含数据分析、数据可视化、机器学习、深度学习、机器人等等,任何Python数据科学第三方库都能在Jupyter上得到很好的应用和支持。
现在几乎所有的数据比赛平台都以Jupyter作为编辑工具,在上面实现各种数据分析场景。
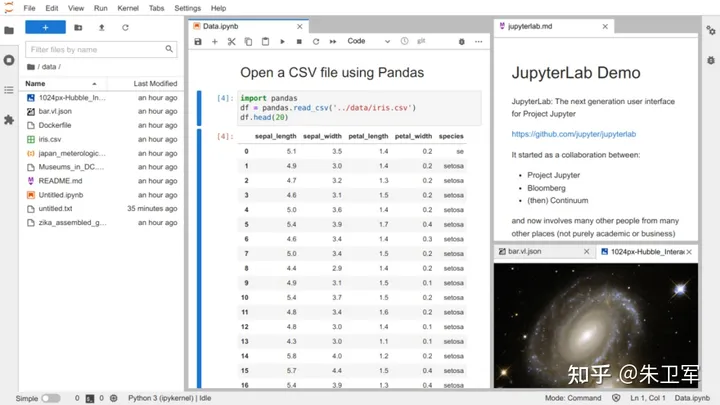
在产品上,Jupyter不仅有简洁的Notebook ,还有工作台式的Lab,甚至线上平台化部署的Hub,对个人、团队、企业都可以完美支持。
三、最重要的原因,Python易学、易用、易读
这实在太关键了,做数据分析不会太去关注编程语言本身的复杂特性,越是简单越有利于提高效率。
首先,我不需要关注代码的细节,比如申明类型、编译、调试等,因为我只是用来分析处理数据,又不要开发大型软件,运行他个十几年。
其次能用第三方库,就不需要自己去开发工具,能极大地提升数据分析效率。
只要结果完美,其他的并不重要。
Python就是有这样的优势,代码简洁,有上千个数据科学相关第三方库供你使用。
所以相比其他语言,python最大程度上降低了使用门槛。
比如说构建一个简单的分类模型。
这是Python代码:
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
# 示例数据
X = np.array([[1, 2], [2, 3], [3, 1], [2, 1], [3, 3], [4, 4], [5, 5]])
y = np.array([0, 0, 1, 1, 0, 1, 1])
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 创建逻辑回归模型
model = LogisticRegression()
# 训练模型
model.fit(X_train, y_train)
# 预测测试集
y_pred = model.predict(X_test)
# 评估模型
print("Accuracy:", metrics.accuracy_score(y_test, y_pred))
这是Java代码:
import weka.classifiers.Classifier;
import weka.classifiers.functions.SMO;
import weka.core.Instances;
import weka.core.converters.ConverterUtils.DataSource;
public class ClassificationExample {
public static void main(String[] args) throws Exception {
// 加载数据
DataSource source = new DataSource("data.csv");
Instances data = source.getDataSet();
// 设置类别索引(通常是最后一列)
if (data.classIndex() == -1)
data.setClassIndex(data.numAttributes() - 1);
// 构建分类器(这里使用SMO,一种支持向量机算法)
Classifier cls = new SMO();
// 训练模型
cls.buildClassifier(data);
// 测试模型
double[] testInstance = {4.5, 4.5}; // 一个新的测试实例
Instances test = new Instances(data, 1); // 创建一个只包含一个实例的数据集
test.add(testInstance);
// 对测试实例进行分类
double predictedClass = cls.classifyInstance(test.firstInstance());
String className = data.classAttribute().value((int) predictedClass);
// 输出预测结果
System.out.println("Predicted class for instance [4.5, 4.5]: " + className);
}
}
这是C++代码:
import weka.classifiers.Classifier;
import weka.classifiers.functions.SMO;
import weka.core.Instances;
import weka.core.converters.ConverterUtils.DataSource;
public class ClassificationExample {
public static void main(String[] args) throws Exception {
// 加载数据
DataSource source = new DataSource("data.csv");
Instances data = source.getDataSet();
// 设置类别索引(通常是最后一列)
if (data.classIndex() == -1)
data.setClassIndex(data.numAttributes() - 1);
// 构建分类器(这里使用SMO,一种支持向量机算法)
Classifier cls = new SMO();
// 训练模型
cls.buildClassifier(data);
// 测试模型
double[] testInstance = {4.5, 4.5}; // 一个新的测试实例
Instances test = new Instances(data, 1); // 创建一个只包含一个实例的数据集
test.add(testInstance);
// 对测试实例进行分类
double predictedClass = cls.classifyInstance(test.firstInstance());
String className = data.classAttribute().value((int) predictedClass);
// 输出预测结果
System.out.println("Predicted class for instance [4.5, 4.5]: " + className);
}
}
对比下,很明显地能看出来,Python代码会更加简洁,少了很多语法上的规则限制,其第三方库的使用也更加容易。
综上来说,从事数据分析想要选一个编程语言,Python是最好的选择,会让你少走一些弯路。