Hive CBO优化剖析
原创
背景介绍
Hive是较早的SQL on Hadoop系统,对大数据SQL执行有广泛和深远的影响。它最初由Facebook开发,后来成为Apache软件基金会的一个开源项目。用户可以通过SQL来读取、写入和管理存储在分布式存储系统中的大规模数据集。
除了Hive SQL外,Hive Metastore也对大数据系统的元数据体系也着广泛影响,已成为大数据领域下元数据定义的事实标准。无论是Spark、Presto都扩展对应的Metastore Catalog。后续文章将会针对Hive Metastore进行详细介绍。
解析流程
Hive SQL核心解析流程如下,语义解析获取逻辑计划树的算子树(Operator Tree),使用Logical Optimizer(Optimizer#optimize)获取最优的算子树。
- Parser:将HiveSQL语句基于ANTLR4编译解析为AST抽象语法树 ASTNode;
- Semantic Analyzer:基于SemanticAnalyzer#genResolvedParseTree方法,以Visitor模式进行语法分析(ContextVisitor),递归遍历AST语法树,经过doPhase1和getMetaData抽象出SQL的基本组成单元QB(QueryBlock,即一个子查询,查询块),QB包括三部分:输入源、计算过程、输出;
- Logical Plan Generator:基于SemanticAnalyzer#genOPTree方法,实现QB获取逻辑计划算子树Operator Tree,Operator(算子树对象)的数据传递是流式过程,父Operator操作会传递给子Operator计算;
- Logical Optimizer:基于Optimizer#optimize 对逻辑算子树Operator进行优化,对指定运算过程执行内置的transform操作,如:合并操作符,减少执行的MapReduce作业,减少shuffle梳理量,计算下推等;
- Physical Plan Generator:基于TaskCompiler#compile,从逻辑算子树Operator的根节点进行自顶向下的深度优化遍历,转换生成物理计划算子树Task;
- Physical Optimizer:基于TaskCompiler#optimizeOperatorPlan 根据不同的执行引擎优化物理计划,TaskCompiler目前有MapReduceCompiler、SparkCompiler、TezCompiler。

对应SQL解析的数据对象流转如下所示:
- HiveSQL解析转为ASTNode 抽象语法树对象
- ASTNode转为QB(QueryBlock) 子查询块
- QB转为Operator逻辑计划树,便于后续关系代数的逻辑优化
- Operator转为Task物理计划树,实现逻辑计划到物理计划的转换

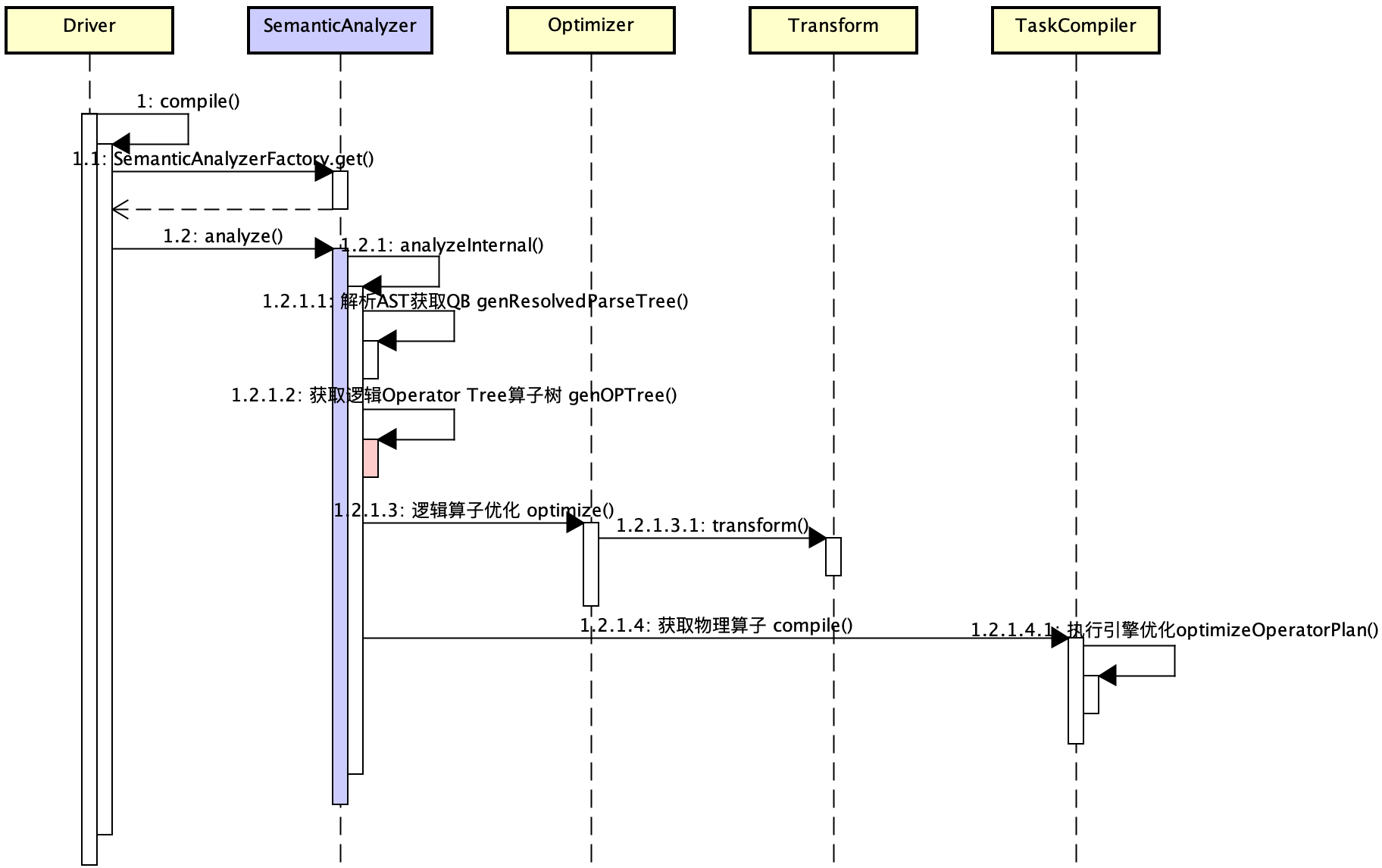
SQL解析及执行的时序图如下:核心在于SemanticAnalyzer处理,包括:
- 基于AST获取QB
- 基于QB转为Operator,基于逻辑计划树(算子树) 实现逻辑优化
- 基于Operator转为Task,基于物理计划树(算子树) 实现物理优化
CBO优化
实现原理
Hive使用HiveVolcanoPlanner 继承原生的Calcite VolcanoPlanner 实现CBO优化器,CalcitePlanner继承Hive的SemanticAnalyzer(语义解析),Override重写了基于QB获取逻辑算子树Operator的genOPTree方法。时序图如下所示,CalcitePlannerAction实现Calcite PlannerAction,调用apply方法获取优化后的Calcite逻辑算子树 RelNode,基于ASTConverter转换RelNode为Hive的优化后的ASTNode,基于优化后的ASTNode生成Hive逻辑算子树Operator,并执行后续解析操作。
CBO的统计和系统信息在创建CalcitePlannerAction对象时传入,包括:partitionCache、colStatsCache、columnAccessInfo。
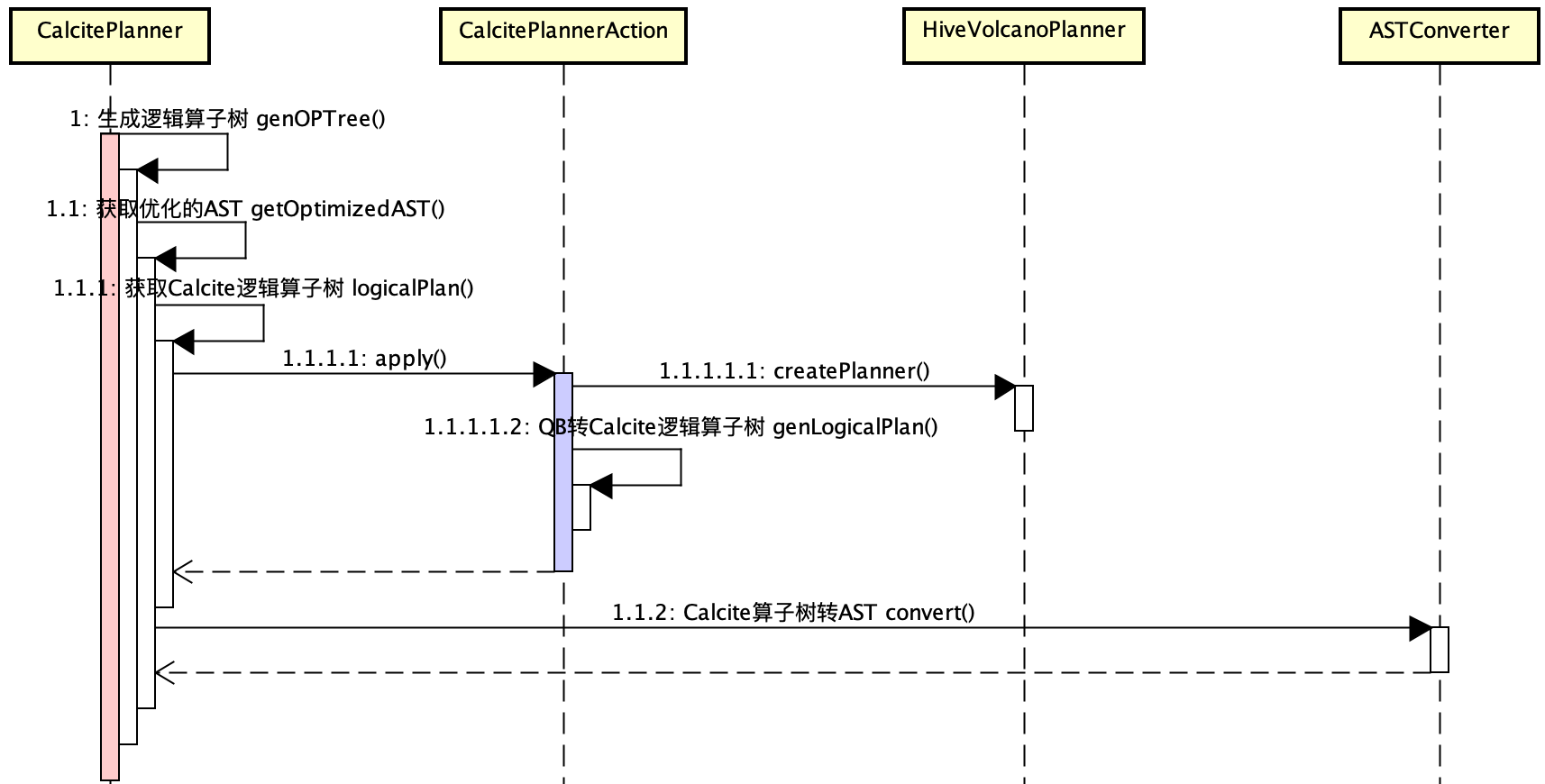
Hive基于CBO优化的解析数据对象流转如下所示:
Hive CBO实现内核:在QB转Operator逻辑计划时进行扩展处理,QB → Calcite CBO优化 → Operator。

Hive中RelOptHiveTable类扩展Calcite的RelOptTable,内部维护行数和字段统计值,提供统计方法:
- getRowCount:获取行数
- getColStat:获取字段统计信息,底层调用元数据统计RPC接口:get_table_statistics_req、get_partitions_statistics_req
统计信息
触发统计元数据更新的时机,对于ALTER和INSERT操作,需要保证 hive.stats.autogather = true;
- ANALYZE:AnalyzeTableCommand、AnalyzeColumnCommand、AnalyzePartitionCommand;
- ALTER:AlterTableMergeFileCommand、TruncateTableCommand;
- INSERT:LoadDataCommand;
Statistics 统计信息,参考:org.apache.hadoop.hive.ql.plan.Statistics
字段 | 字段名称 |
|---|---|
numRows | 行数量 |
runTimeNumRows | 运行时行数量 |
dataSize | 数据文件大小 |
basicStatsState | 表统计状态:NONE、PARTIAL、COMPLETE |
columnStats | 字段统计信息,Map<String,ColStatistics> |
columnStatsState | 字段统计状态:NONE、PARTIAL、COMPLETE |
runtimeStats | 是否是允许时统计 |
ColStatistics 字段级别统计信息
字段 | 字段名称 |
|---|---|
colName | 字段名称 |
colType | 字段类型 |
countDistinct | 不同字段值的个数统计 |
numNulls | nulls个数 |
avgColLen | 字段平均长度 |
numTrues | True个数 |
numFalses | False个数 |
range | 字段最大最小值范围 |
isPrimaryKey | 是否是主键 |
isEstimated | 是否是预估值 |
统计元数据查询:扩展Calcite的RelOptTable,调用Hive Metastore RPC接口获取元数据信息;
统计元数据更新:
- 表和分区统计元数据:基于RPC客户端调用Metastore接口,alterTable、alterPartitions更新对应的parameters属性;
- 字段元数据:基于RPC客户端调用Metastore接口,setPartitionColumnStatistics 更新字段/分区的统计信息;
ANALYZE执行
Hive CBO统计信息主要由ANALYZE执行获取,对应的ANALYZE 语法定义如下:
ANALYZE TABLE [db_name.]tablename [PARTITION(partcol1[=val1], partcol2[=val2], ...)]
COMPUTE STATISTICS
[FOR COLUMNS] -- (Note: Hive 0.10.0 and later.)
[CACHE METADATA] -- (Note: Hive 2.1.0 and later.)
[NOSCAN];统计元数据执行:使用物理算子StatsTask,调用IStatsProcessor#process方法执行元数据统计,IStatsProcessor实现子类:
- BasicStatsTask:基本的表元数据统计,遍历Location下的HDFS文件列表(List<FileStatus>),统计出数据文件的总个数和总存储大小,其中StatsAggregator统计信息汇总,对多任务的统计结果聚合;
- BasicStatsNoJobTask:不触发任务执行的统计操作,如ORC数据文件在文件属性中存储列统计信息,该方式计算更快,启动多线程执行文件统计信息汇总;
- ColStatsProcessor:列、每个分区的统计信息,基于FetchOperator迭代读取表的行数据,ColumnStatisticsObjTranslator进行字段级统计信息拼装;
总结
随着大数据蓬勃发展,Hive计算引擎作为先行者,由于执行框架限制和执行耗时长等因素逐步被其他引擎替代。但Hive作为SQL on Hadoop的事实标准却一直影响着大数据SQL发展,且企业大量的存量业务都以Hive SQL构建。
本文通过背景介绍、解析流程、CBO优化三部分详述Hive CBO原理。Hive SQL核心解析流程包括解析、语义分析、逻辑优化、物理优化步骤。Hive CBO优化依赖Calcite 火山模型优化器实现,本文介绍了相关的CBO实现原理,CBO统计元数据和ANALYZE执行实现。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。