CVPR 2024 | SC-GS: 可编辑动态场景中的系数控制高斯溅射
CVPR 2024 | SC-GS: 可编辑动态场景中的系数控制高斯溅射

作者:Yi-Hua Huang, Yang-Tian Sun, Ziyi Yang 等 来源:CVPR 2024 论文题目:SC-GS: Sparse-Controlled Gaussian Splatting for Editable Dynamic Scenes 论文链接:https://arxiv.org/abs/2312.14937 内容整理:王秋文
引言
最近,高斯溅射作为一种表示场景为 3D 高斯点的方法,显示出在渲染质量、分辨率和速度方面的显著性能。然而,现有的高斯溅射公式只适用于静态场景,将对象运动整合到高斯表示中而不损害渲染质量和速度仍然是一个挑战。
作者观察到现实世界的运动通常是稀疏的、空间上连续的和局部刚性的,因此提出了一种方法,通过与高斯点相比数量更少的可学习稀疏控制点来丰富高斯溅射。这些控制点与时间变化的 6 自由度(6 DoF)变换相关联,可以通过学习到的插值权重进行局部插值,从而得到密集高斯点的运动场。作者使用一个基于时间和位置的 MLP 来预测每个控制点的时间变化 6 DoF 变换,这种策略减少了学习复杂性,增强了模型能力,并提供了具有改进的空间和时间连续性的运动。在训练过程中,作者引入了自适应策略来调整控制点的数量,以适应不同区域的运动复杂性,并采用了 ARAP 损失函数,以鼓励学习到的运动在空间上尽可能刚性。由于运动和外观的有效表示,该方法不仅能够进行高质量的动态视角合成,还能进行运动编辑,这在现有方法中是不存在的。
方法
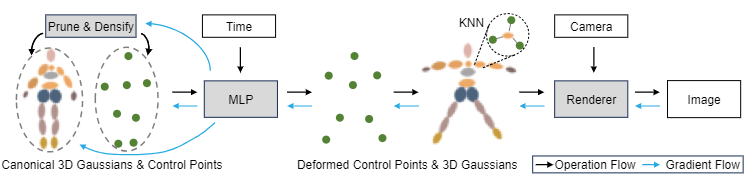
图1 算法整体框架图
稀疏控制点
- 目标:重建单目视频中的动态场景,使用高斯函数在规范空间中表示场景的几何和外观,同时通过控制点和 MLP 预测的时间变化 6DoF 变换来模拟运动。
- 稀疏控制点:引入一组稀疏控制点
,每个控制点由其在规范空间中的坐标
和控制点对高斯影响范围的半径参数
组成。控制点的数量
远少于高斯的数量,因此能够形成一组紧凑的运动基。
- 时间变化的 6DoF 变换:每个控制点学习随时间变化的 6DoF 变换,包括旋转矩阵
和平移向量
。使用 MLP
来预测每个控制点在每个时间步长
的变换:
动态场景渲染
- 变换参数获取:使用MLP预测的控制点的时间变化6DoF变换参数
,形成一组紧凑的运动基。
- Linear blend Skinning(LBS):通过局部插值控制点的变换来推理高斯的密集运动场。对于每个高斯
,使用 k-最近邻(KNN)搜索找到其在规范空间中的 K 个邻近控制点,然后使用高斯核径向基函数(RBF)计算插值权重:
- 更新高斯参数:使用插值权重和 LBS 计算变形后的高斯中心
和旋转
:
随后,可以使用更新后的高斯参数进行渲染。
优化
- 预训练和联合优化:首先,作者采用预训练策略,独立地训练控制点
和 MLP
,以模拟粗略的场景运动,而保持高斯
的参数固定。预训练完成后,整个模型(包括控制点、高斯和 MLP)将被联合优化。
- ARAP 损失:为了从局部极小值中恢复出来并规范非结构化的控制点,我们引入了一个ARAP(As Rigid As Possible,尽可能刚性)损失项
,它鼓励控制点的运动在局部上保持刚性,遵循 “尽可能刚性” 的原则。在计算控制点的 ARAP 损失之前,首先需要识别出连接这些点的边。为了避免将不相关的点连接起来,我们选择连接在场景运动中轨迹紧密对齐的点。具体来说,对于控制点
,我们首先计算其轨迹
,该轨迹包括在
个随机采样的时间步长上的控制点位置:
其中⊕表示向量连接操作。基于获得的轨迹,我们执行球查询,并使用所有在预定义半径内控制点
来定义一个局部区域。然后,为了计算Larap,我们随机采样两个时间步长
和
。对于半径内每个点
(即k ∈
),其通过学习到的平移参数
和
变换后的位置分别是:
和
,因此旋转矩阵
可以按照刚性运动假设估计为:
这里
的计算方式与上面的
类似,通过将高斯位置
替换为控制点位置
来计算,这根据它们对
的影响对不同的邻近点
进行加权。然后,
被设计为:
它评估了学习到的运动与局部刚性假设偏离的程度。通过惩罚
,鼓励学习到的运动在局部上保持刚性。刚性正则化显著增强了学习到的运动。对于优化,除了
外,渲染损失
通过使用L1损失和D-SSIM损失的组合,将不同时间步长下的渲染图像与真实参考图像进行比较来得到。最后,整体损失构建为:
在训练过程中,作者还开发了一种自适应密度调整策略,以添加和剪枝控制点,这允许调整它们的分布以模拟不同区域的运动复杂性。以下是该策略的两个主要步骤:
- 控制点的剪枝:
为了确定是否应该剪枝控制点
,计算它对包含
作为 K 个最近邻的高斯集合
的总体影响:
如果
接近零,表明控制点对 3D 高斯的运动贡献很小,那么将剪枝
。
- 控制点的克隆:
为了确定是否应该克隆控制点
,计算集合
中高斯相对于控制点的梯度范数之和:
如果 的值很大,表明重建效果不佳。因此,克隆 并在相关高斯的期望位置添加一个新的控制点来改善重建:
通过这种自适应策略,模型能够根据场景的运动复杂性动态调整控制点的分布,从而在保持渲染质量的同时,提高模型的表达能力和训练效率。
运动编辑
控制点图的构建
- 利用训练好的控制点
和 MLP
,构建一个控制点图
,该图基于控制点的运动轨迹将它们连接起来。
- 对于图中的每个顶点(即控制点
),首先计算其从 MLP
获得的轨迹
。
- 然后,根据这些轨迹,将顶点连接到在预定义半径内落入的其它顶点,以构建控制图。
运动编辑的实现
- 通过用户定义的控制点图上的约束,可以对场景的运动进行编辑。
- 用户可以指定一些控制点(称为手柄点)的新位置,然后通过最小化ARAP(As Rigid As Possible)能量来调整控制点图
,以满足这些约束。
ARAP变形
- ARAP变形是一种保持局部刚性的变形方法,它通过最小化控制点图上的变形能量来实现。
- 给定一组用户定义的手柄点集合
,控制图
可以通过最小化ARAP能量来变形。
- 用户定义点位置
被固定,而其他控制点的位置通过优化过程调整,以满足整体的运动约束。
优化过程
- 该优化问题可以通过交替优化局部旋转
和变形后的控制点位置
来有效求解。
- 解得的旋转
和平移
形成了每个控制点的 6DoF 变换,这与模型的运动表示一致。
通过使用变形后的控制点替换原方程中的变换,高斯函数可以被变形,进而渲染成高质量的编辑图像。由于控制点的显式和稀疏表示,该方法允许通过控制点的操作来高效、直观地进行运动编辑。学习到的高斯和控制点之间的相关性和权重使得模型即使在训练序列之外的运动上也具有很好的泛化能力。
实验
作者在两个数据集上进行了测试,包括D-NeRF和NeRF-DS。通过展示了与D-NeRF、TiNeuVox、K-Planes和4D-GS等方法的定性和定量比较,作者的方法在合成图像的细节和质量上更接近于真实场景。
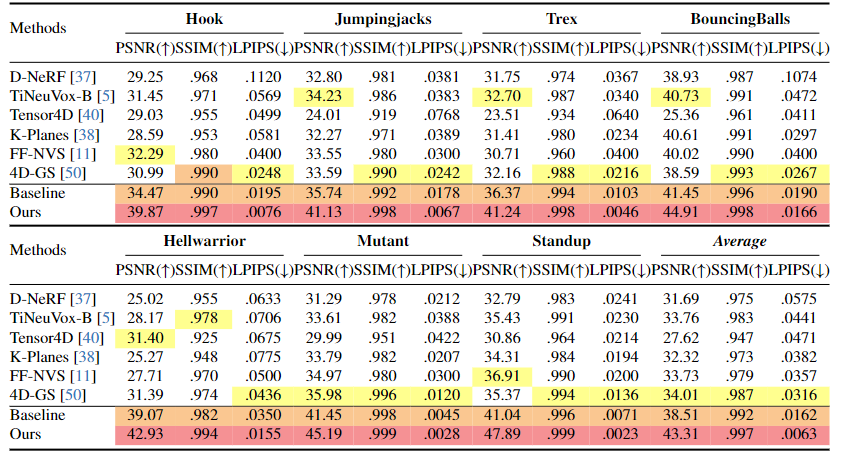
图2 在D-NeRF数据集上进行客观比较的结果
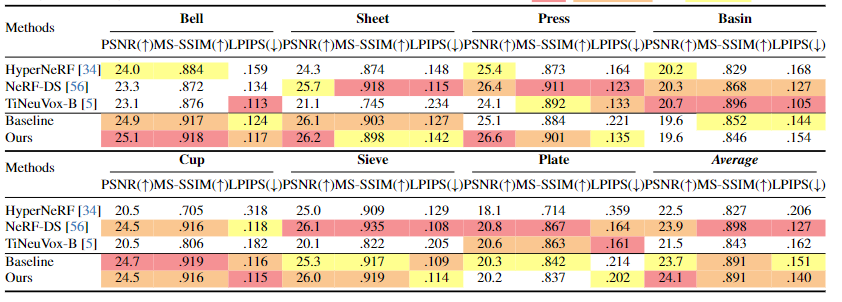
图3 在NeRF-DS数据集上进行客观比较的结果

图4 在D-NeRF数据集上进行主观比较的结果
作者还进行了消融实验。首先,对控制点展开消融实验,通过结果可知如果不使用控制点,直接通过MLP预测每个高斯的运动,会导致高斯轨迹中的噪声,并且难以达到全局最优解。其次,对ARAP损失展开消融实验,如果没有ARAP损失,即使控制点提供了有效的正则化,模型仍然可能在某些情况下违反刚性约束,导致运动重建的不连贯。
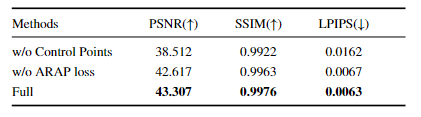
图5 消融实验定量结果
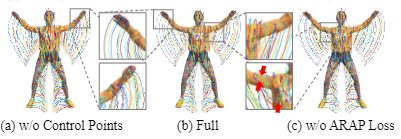
图6 消融实验定性结果
最后,作者展示了运动编辑的效果。

图7 运动编辑展示