大模型相关技术-为什么要用RAG不用全文检索?
原创
全文检索
搜索引擎我们接触比较多的人工智能技术,大家更为熟悉的elasticsearch就是一种企业级全文检索引擎,如果用es去实现企业内部知识库的检索大概需要5个步奏去实现。
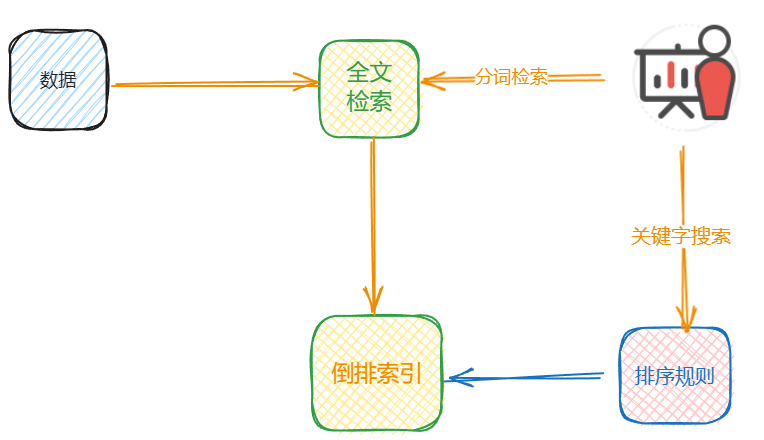
- 索引创建:首先,将需要被搜索的数据进行预处理,如分词、去除停用词等,然后将处理后的数据建立倒排索引。倒排索引是一种特殊的索引结构,它将文档中的关键词作为键,包含该关键词的文档列表作为值,这样可以快速定位到包含特定关键词的文档。
- 数据存储:将创建好的索引存储在磁盘上,以便于后续的检索操作。
- 用户检索:当用户输入查询语句时,首先对查询语句进行预处理,如分词、去除停用词等,然后根据预处理后的查询语句在倒排索引中查找相关的文档。
- 排序:根据一定的排序算法(如TF-IDF、BM25等)计算每个文档与查询语句的相关性得分,然后按照得分从高到低对文档进行排序。
- 返回结果:最后,将排序后的文档列表返回给用户,完成搜索过程。
全文检索的弊端
- 全文检索效果的好坏比较依赖分词器的分词效果,这就需要无所不包的标准词库尤其是专业术语词库以及更新及时的热词词库,以及各类停止词词库。
- 搜索引擎返回给用户的是相关联的top N个数据,搜索引擎并不完全知道这些数据哪些符合用户需求,例如我们百度搜索一个东西,百度会给我们提供很多页的备选结果,我们需要在不同页面之间点开链接去查找符合要求的数据。
传统全文检索无能为力的地方
- 语义理解能力较弱
全文检索的准确度严重依赖分词器的分词结果,因此用户关键词的匹配程度决定了搜索结果,这在一定程度上在某些领域要求用户要掌握一定的搜索小技巧,例如程序员搜索一个异常“NullPointerExcepiton com.tencent.cloud.controller.staffController.getUid() ”,作为一个程序员一定知道搜索的过程中需要将自己的包名去掉搜索才能搜到关键信息“NullPointerExcepiton”
例如索引库中有“李四的电话是13333333333”,当用户搜索李四的手机号是什么的时候,电话和手机号在本语境下其实是同义词,如果要实现这个效果需要不断扩充同义词的词库
- 混合检索能力较弱
当用户输入中英文混杂、中文数字混杂情况下搜索准确度下降太快,例如007之金手指,搜索结果就会很混乱,一般解决这种问题的方法还是已添加词库来实现此类检索。
下一篇我们将详细分析RAG的两大关键技术。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读