充分发挥潜力!Google | 大模型(LLMs)的专属:多样本上下文学习(Many-shot ICL)
充分发挥潜力!Google | 大模型(LLMs)的专属:多样本上下文学习(Many-shot ICL)

引言
大语言模型非常擅长上下文学习(ICL),随着大模型上下文窗口的不断扩展,它可以让我们使用数百或者上千个样例,然而,当前多样本上下文学习(many-shot ICL)却受限于高质量人类生成示例。
为此,本文作者探索了两种新方法:强化上下文学习(Reinforced ICL)和无监督上下文学习(Unsupervised ICL),实验结果表明,它们对多样本上下文学习都非常有效,特别是在复杂的推理任务上。最后,作者指出相比few-shot,many-shot可以有效地克服预训练偏差,并且可以学习具有数值输入的高维函数。

https://arxiv.org/pdf/2404.11018.pdf
背景介绍
在上下文学习(ICL)方面,大型语言模型(LLMs)已经展现出了的卓越能力。它们仅通过输入输出示例(也称为“shots”),就能学习新任务。然而,LLM的上下文窗口(即它们每次处理的token化输入的Token数量)限制了ICL可以使用的shots数量,将先前的研究限制在了少样本学习领域。
然而随着大模型的发展,当前LLMs的上下文窗口至少增加了100倍,例如GPT-3和Llama 2从几千个token增加到了上万个token,尤其是最近刚刚发布的Gemini 1.5 Pro,上下文Token已经可以支持上百万个token。这可以让LLMs处理大量的shots,采用多样本上下文学习能够充分发挥LLMs的潜力,但是该种方法并没有进行充分的探索。
为此,本文作者详细研究了增加上下文示例(shots)的数量如何影响LLM在多种下游任务上的性能,与少样本学习相比,多样本学习在这些任务(机器翻译、摘要生成、动态规划、数学推理等)中带来了显著的性能提升。特别是,当上下文示例的数量达到数十万个token时,通常才能实现最大性能。然而,尽管多样本学习具有很大的应用前景,多样本ICL可能会受限于可用的高质量人类生成示例的数量。这对于需要大量资源和专业知识的复杂推理任务尤其具有挑战性。为了克服这一点,本文作者引入了增强ICL和无监督ICL。
强化ICL
"Reinforced ICL"(强化上下文学习)提供了一种有效的方法来生成大量高质量的示例,这些示例可以用于多样本ICL,而不需要依赖于人类生成的内容。增强ICL的核心思想是使用模型生成的基本原理来替代人类编写原理,旨在克服在复杂任务中生成大量人类示例的资源消耗和专业知识需求。
具体来说,增强ICL通过从一个或几个样本的思维链(chain-of-thought)提示开始,为每个训练问题生成多个理由,然后选择那些得到正确最终答案的理由,并将它们排列成包含(问题,理由)对的上下文示例。
然而,这种方法的局限性在于它依赖于模型能够生成足够好的理由,并且这些理由需要通过正确答案来筛选。未来的工作可以探索不同的方法来生成和筛选模型生成的理由,以进一步提升增强ICL的效率和效果。
无监督ICL
"Unsupervised ICL"(无监督上下文学习)是作为增强ICL(Reinforced ICL)的延伸提出的,旨在进一步减少对人类生成数据的依赖。当大语言模型(LLMs)已经具备解决特定任务所需的知识时,提示中插入的任何信息,只要能够帮助缩小任务所需的知识范围,都会有所帮助。无监督ICL提供了一种在不需要人类生成的解决方案或理由的情况下进行多样本ICL的方法。
在无监督ICL中,提示仅包含问题或未解决的输入,而不包含解决方案或理由。具体来说,无监督ICL的提示由三部分组成:
- 「前言」 例如,“你将被提供类似于下面的问题:”;
- 「问题」 一个未解决的输入或问题列表;
- 「提示」 一个零样本指令或几个样本提示,用于指明所需的输出格式。
多个任务上评估了无监督ICL,包括数学问题解决(如Hendrycks MATH和GSM8K)和问答(如GPQA)。在这些任务中,无监督ICL的表现有时比使用人类生成理由的ICL更好。尽管无监督ICL在某些情况下表现良好,但在输出对于指定任务至关重要的情况下,它可能表现不佳。
例如,在资源匮乏的机器翻译任务中,仅提供源句子而没有目标句子作为上下文示例,并不能改善任务性能。无监督ICL的局限性在于它可能不适用于那些输出对于任务指定至关重要的情况。未来的工作可以探索如何改进无监督ICL的方法,以及如何更好地理解和优化其性能。
实验结果
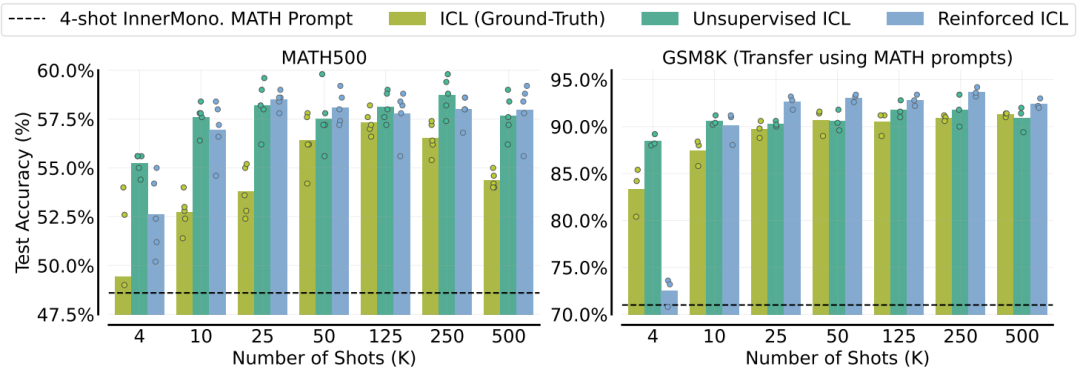
在Hendrycks MATH和GSM8K数据集上评估了增强ICL和无监督ICL,如下图所示增强ICL和无监督ICL在多样本情况下通常比使用人类生成解决方案的ICL更有效
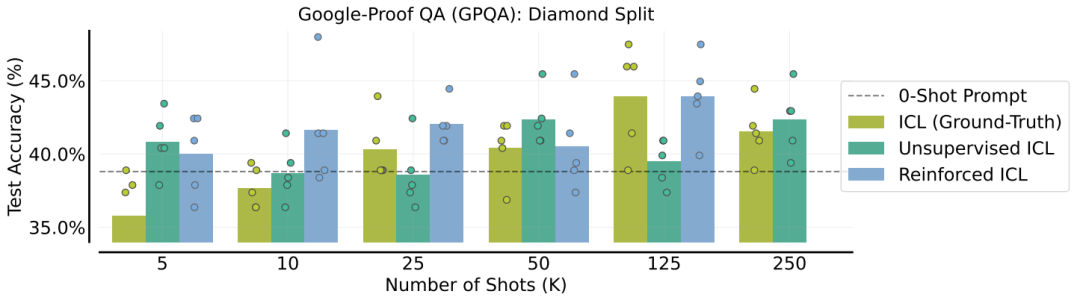
在GPQA数据集上评估了增强ICL和无监督ICL。增强ICL在少于25个样本时比人类编写的理由表现更好,而无监督ICL的性能则没有系统性趋势.
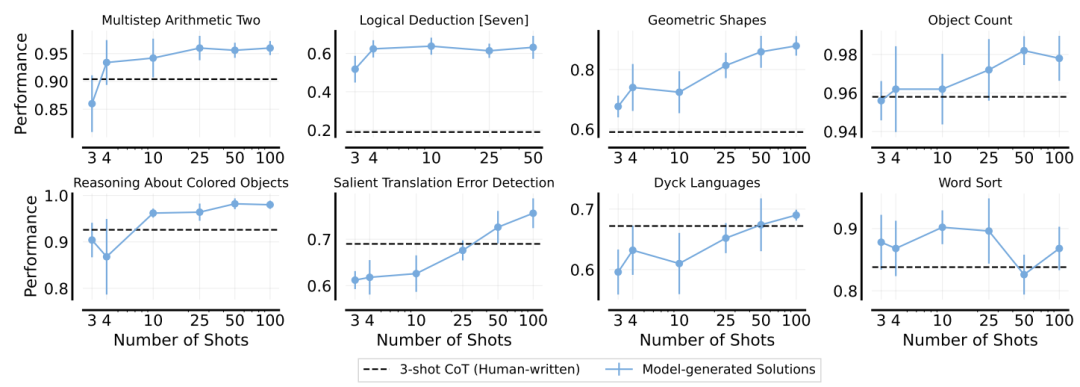
在BIG-Bench Hard数据集上评估了增强ICL。结果表明,增强ICL在大多数任务上都优于标准的人类编写的链式思考提示。