MOP 系列|MOP 三种主流数据库索引简介
MOP 系列|MOP 三种主流数据库索引简介

MOP 不用多说了,我这里指的就是 MySQL、Oracle、PostgreSQL 三种目前最主流的数据库,MOP 系列打算更新 MOP 三种数据库的索引知识、高可用架构及常用 SQL 语句等等,今天打算介绍一下这三种数据库的索引基础知识。
Oracle 索引类型
B 树索引
索引组织表
•索引组织表(IOT)在一个B树索引结构中存储表行的全部内容。使用索引组织表,能缩短 具有精确匹配和主键范围搜索的查询时间。
create table prod_sku (prod_sku_id number,sku varchar2(256),
constraint prod_sku_pk primary key(prod_sku_id,sku))
organization index;•B 树索引内部结构:B 树索引有两种类型的块:用于搜索的分支块和用于存储键值的叶块。B 树索引的上层分支块包含指向低层索引块的索引数据。 在索引扫描中,数据库使用语句指定的索引列值遍历索引来检索一行。如果数据库扫描索引寻找一个值,那么它将在 n 个 I/ o 中找到这个值,其中 n 是 B 树索引的高度。这是 Oracle 数据库索引背后的基本原则。

唯一索引
•唯一索引是组成索引的列上没有任何重复值的索引,如果尝试子啊包含重复值的表上创建唯一索引则会报错。当创建唯一约束时会自动创建唯一索引。
create unique index idx_cust_unq on cust(last_name,first_name);反向键索引
•反向键索引是一种 B 树索引,它在保持列顺序的同时物理地反转每个索引键的字节。对于平衡有大量顺序插入的索引的 IO 是非常有用的。 例如,如果索引键为 20,并且该键以十六进制形式存储的两个字节在标准 b 树索引中为 C1,15,则反向键索引将字节存储为15,C1。
create index idx_cust_id_rev on cust(cust_id) reverse;键压缩索引
•键压缩索引有助于减少前导列经常重复的组合索引的存储和IO要求。
create index idx_cust_comp on cust(last_name,first_name) compress 2;降序索引
•在升序索引中,Oracle数据库按升序存储数据。默认情况下,字符数据按照值的每个字节中包含的二进制值、数字数据从小到大、日期从早到晚排序。
create index idx_cust_iddesc on cust(cust_id desc);位图索引
在位图索引中,数据库为每个索引键存储一个位图。在传统的 b 树索引中,一个索引条目指向单行。在位图索引中,每个索引键存储指向多行的指针。
位图索引主要是为数据仓库或查询以特别方式引用许多列的环境而设计的。可能需要位图索引的情况包括: 索引列的基数较低,也就是说,与表的行数相比,不同值的数量很少。 被索引的表要么是只读的,要么不受DML语句的重大修改。
create table f_sales(sales_amt number,d_date_id number,d_product_id number,d_customer_id number);
create bitmap index bit_idx_f_sales_id on f_sales(d_date_id);位图连接索引
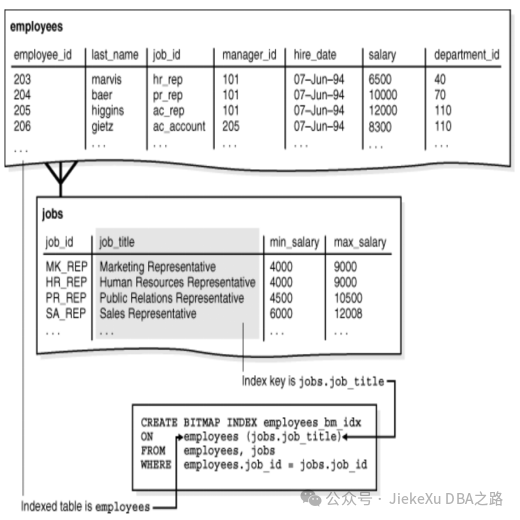
位图连接索引是两个或多个表连接的位图索引。 对于表列中的每个值,索引存储索引表中对应行的行号。相比之下,标准位图索引是在单个表上创建的。
位图连接索引是通过提前执行限制来减少必须连接的数据量的有效方法。对于位图连接索引何时有用的示例,假设用户经常查询具有特定工作类型的员工数量。典型的查询如下所示:
SELECT COUNT(*) FROM employees, jobs
WHERE employees.job_id = jobs.job_id
AND jobs.job_title = 'Accountant';
CREATE BITMAP INDEX idx_bm_employees ON employees (jobs.job_title)
FROM employees, jobs
WHERE employees.job_id = jobs.job_id;从概念上讲,idx_bm_employees 是工作的索引。如下查询所示的 SQL 查询中的 title 列(包括示例输出)。索引中的 job_title 键指向 employees 表中的行。查询会计人数可以使用索引来避免访问雇员和工作表,因为索引本身包含所请求的信息。
函数索引
function-based index 基于函数的索引计算涉及一个或多个列的函数或表达式的值,并将其存储在索引中。基于函数的索引既可以是 B 树索引,也可以是位图索引。
CREATE INDEX idx_cust_valid ON customers ( CASE cust_valid WHEN 'A' THEN 'A' END ); CREATE INDEX idx_emp_total_sal ON employees (12 * salary * commission_pct, salary, commission_pct);虚拟列索引
一种代替基于函数的索引的方法是在表中添加一个虚拟列,然后为虚拟列创建索引(11g 以上)。
create table inv(inv_id number,inv_count number, inv_status generated always as ( case when invcount <= 100 then 'GETTING LOW' when inv_count > 100 then 'OKAY end) );
create index idx_inv_stas on inv(inv_status);虚拟索引
通过关键字 Nosegment 子句可以指示 Oracle 创建永远不会被使用的索引,并且不会将任何去分配给它的索引。
alter session set "_use_no_segment_indexes"=true;
create index idx_cust_id on cust(cust_id) nosegment;如果我们想要创建一个大表的非常大的索引,但是我们也不确定优化器是否会用到它,那么就可以通过 nosegment 来创建索引进行测试,如果该索引有用,再删除该索引使用不带 nosegment 关键字的命令重新创建。
不可见索引
invisible 不可见索引是被优化器忽略的索引,但是对于表数据的插入、更新或删除时,数据库也会维护索引结构,除非在会话或系统级别显式地将 OPTIMIZER_USE_INVISIBLE_INDEXES 初始化参数设置为 TRUE。
CREATE INDEX idx_emp_ename ON emp(ename) TABLESPACE users STORAGE (INITIAL 20K NEXT 20k) INVISIBLE;
ALTER INDEX idx_emp_ename VISIBLE;
ALTER INDEX idx_emp_ename INVISIBLE;
SELECT INDEX_NAME, VISIBILITY FROM USER_INDEXES WHERE INDEX_NAME = 'IDX_EMP_ENAME';不可用索引
Unusable 当您使索引不可用时,优化器会忽略它,DML 也不会维护它。当您使分区索引的一个分区不可用时,该索引的其他分区仍然有效。在使用不可用的索引或索引分区之前,必须重建或删除并重建它。
ALTER INDEX idx_emp_email UNUSABLE;
--查询 idx_emp_email 段占用的空间,发现这两个段已经不存在了。
SELECT SEGMENT_NAME, BYTES FROM USER_SEGMENTS WHERE SEGMENT_NAME IN ('IDX_EMP_EMAIL');
no rows selected全局分区索引
全局分区索引是一个 B 树索引,它独立于创建它的基础表进行分区。单个索引分区可以指向任何或所有表分区,而在本地分区索引中,索引分区和表分区之间存在一对一奇偶校验。
CREATE INDEX cust_last_name_ix ON customers (cust_last_name) GLOBAL PARTITION BY HASH (cust_last_name) PARTITIONS 4;本地分区索引
在本地分区索引中,索引在与其表相同的列上进行分区,具有相同的分区数量和相同的分区边界。 每个索引分区只与基础表的一个分区相关联,因此索引分区中的所有键仅引用存储在单个表分区中的行。通过这种方式,数据库自动将索引分区与其关联的表分区同步,使每个表-索引对独立。
CREATE INDEX hash_sales_idx ON hash_sales(time_id) LOCAL;域索引
application domain index 应用程序域索引是特定于应用程序的自定义索引。 扩展索引可以: 在自定义的复杂数据类型(如文档、空间数据、图像和视频剪辑)上容纳索引(参见) 利用专门的索引技术
B 树聚簇索引
B 树索引是聚簇表键上定义的索引。B 树聚簇索引将一个聚簇键与一个数据库块地址相 关联。该索引类型与聚簇表一同使用。
散列聚簇索引
类似地,散列聚簇索引也用于聚簇表,散列聚簇索引与 B 树聚簇索引的差异是,前者使用散列函数取代了索引键。
索引其他操作
重命名索引
ALTER INDEX index_name RENAME TO new_name;删除索引
DROP INDEX idx_emp_ename;•不能仅删除与已启用的UNIQUE键或PRIMARY键约束关联的索引。要删除约束关联的索引,必须禁用或删除约束本身。如果删除一个表,所有关联的索引都会自动删除。
重建索引
ALTER INDEX idx_emp_name REBUILD;•您可以选择在线重建索引。联机重新构建使您能够在重新构建的同时更新基表。
ALTER INDEX idx_emp_name REBUILD ONLINE;改变索引存储特征
•使用Alter index语句修改任何索引的存储参数,包括数据库创建的用于强制执行主键和唯一键完整性约束的存储参数。 例如,下面的语句改变了emp_name索引:
ALTER INDEX idx_emp_ename STORAGE (NEXT 40);• 对于实现完整性约束的索引,可以通过发出包含 ENABLE 子句的 USING INDEX 子句的 ALTER TABLE 语句来调整存储参数。例如,下面的语句改变了在表 emp上创建的索引的存储选项,以强制执行主键约束:
ALTER TABLE emp ENABLE PRIMARY KEY USING INDEX;
MySQL 索引类型
索引原理
MySQL默认存储引擎 innodb 只显式支持 B-Tree( 从技术上来说是B+Tree)索引,对于频繁访问的表,innodb 会透明建立自适应 hash 索引,即在B树索引基础上建立hash索引,可以显著提高查找效率,对于客户端是透明的,不可控制的,隐式的。B+树索引是B+树在数据库中的一种实现,是最常见也是数据库中使用最为频繁的一种索引。B+树中的B代表平衡(balance),而不是二叉(binary),因为 B+ 树是从最早的平衡二叉树演化而来的。二叉树具有以下性质:左子树的键值小于根的键值,右子树的键值大于根的键值。
MySQL 默认 innodb 存储引擎就是使用B+树来实现索引结构的。由于内节点(非叶子节点)不存储 data,所以一个节点可以存储更多的内节点,每个节点能索引的范围更大更精确。也就是说使用B+树单次磁盘IO的信息量相比较B树更大,IO 效率更高。
非唯一索引
索引值可以出现多次(默认索引类型)
唯一索引
索引值必须唯一或为NULL
ALTER TABLE tab_name ADD UNIQUE (col_name);
CREATE UNIQUE INDEX idx_tname_2 ON tablename(col_name);主键
表的主键表示在最重要的查询中使用的列或列集。它有一个关联索引,用于快速查询性能。值必须唯一,并且不能包含 NULL。
ALTER TABLE tab_name ADD PRIMARY KEY (col1);全文索引
只有 InnoDB 和 MyISAM 存储引擎支持 FULLTEXT 索引,并且只支持 CHAR、VARCHA R和 TEXT 列。索引总是在整个列上进行,不支持列前缀索引。
CREATE TABLE opening_lines (FTS_DOC_ID BIGINT UNSIGNED AUTO_INCREMENT NOT NULL PRIMARY KEY,opening_line TEXT(500),author VARCHAR(200), title VARCHAR(200) ) ENGINE=InnoDB;
CREATE FULLTEXT INDEX idx ON opening_lines(opening_line);空间索引
MySQL允许在NOT NULL的几何值列上创建空间索引。优化器检查索引列的SRID属性,以确定要使用哪个空间参考系统(SRS)进行比较,并使用适合于SRS的计算
创建索引的 SQL 语句
CREATE TABLE geom (g GEOMETRY NOT NULL SRID 4326, SPATIAL INDEX(g));
CREATE TABLE geom (g GEOMETRY NOT NULL SRID 4326);
ALTER TABLE geom ADD SPATIAL INDEX(g);
CREATE TABLE geom (g GEOMETRY NOT NULL SRID 4326);
CREATE SPATIAL INDEX g ON geom (g);函数索引
对表中的列执行表达式或函数计算后的结果构成索引
ALTER TABLE tab_name ADD INDEX ((func(col)));
CREATE INDEX idx_t_f ON tab_name ((func(col_name)));降序索引
MySQL支持降序索引:索引定义中的DESC不再被忽略,而是导致键值按降序存储。以前,索引可以按相反的顺序扫描,但会降低性能。降序索引可以按正向顺序扫描,这样效率更高。降序索引还使优化器可以在最有效的扫描顺序混合了某些列的升序和其他列的降序时使用多列索引。
•考虑下面的表定义,它包含两个列和四个两列索引定义,用于列上升序和降序索引的各种组合:
CREATE TABLE t (c1 INT, c2 INT, INDEX idx1 (c1 ASC, c2 ASC), INDEX idx2 (c1 ASC, c2 DESC), INDEX idx3 (c1 DESC, c2 ASC), INDEX idx4 (c1 DESC, c2 DESC));ORDER BY c1 ASC, c2 ASC -- optimizer can use idx1
ORDER BY c1 DESC, c2 DESC -- optimizer can use idx4
ORDER BY c1 ASC, c2 DESC -- optimizer can use idx2
ORDER BY c1 DESC, c2 ASC -- optimizer can use idx3复合索引
MySQL可以创建复合索引(即多个列上的索引)。一个索引最多可以包含16列。注意多列索引的最左边前缀匹配原则。
CREATE TABLE test (id INT NOT NULL, last_name CHAR(30) NOT NULL, first_name CHAR(30) NOT NULL, PRIMARY KEY (id), INDEX name (last_name,first_name));SELECT * FROM tbl_name WHERE col1=val1;
SELECT * FROM tbl_name WHERE col1=val1 AND col2=val2;
SELECT * FROM tbl_name WHERE col2=val2;
SELECT * FROM tbl_name WHERE col2=val2 AND col3=val3;如果索引存在于 (col1, col2, col3), 只有前两个查询使用索引。第三和第四 查询确实涉及索引列,但不使用索引 执行查找,因为 (col2) 和 (col2, col3) 不是最左边的前缀 (col1, col2, col3)。
不可见索引
MySQL 支持不可见索引;也就是说,优化器不使用的索引。该特性适用于主键以外的索引(显式或隐式)。
CREATE TABLE t1 (i INT,j INT,k INT,INDEX i_idx (i) INVISIBLE ) ENGINE = InnoDB;
CREATE INDEX j_idx ON t1 (j) INVISIBLE;
ALTER TABLE t1 ADD INDEX k_idx (k) INVISIBLE;查看索引
show create table tab_name\G
show index from tab_name\G
SELECT INDEX_NAME,IS_VISIBLE FROM INFORMATION_SCHEMA.STATISTICS WHERE TABLE_SCHEMA = 'JiekeXu' AND TABLE_NAME = 't1';PostgreSQL 索引类型
PostgreSQL 提供了丰富的索引类型,除支持常规的数值类型、字符串类型数据的索引外,还支持时序、空间、JSON等类型数据的索引。PostgreSQL 提供了 B-tree、Hash、GiST、SP-GiST、GIN、BRIN 等多种索引类型,每种索引类型使用不同的算法来适应不同类型的查询。在默认情况下,创建的索引类型为 B-tree 索引。在索引类型名后面加上关键字 USING,可以选择其他的索引类型,例如,创建一个 HASH 索引:
CREATE INDEX name ON table USING HASH (column);
--创建索引的语法如下:
CREATE [ UNIQUE ] INDEX [ CONCURRENTLY ] [ name ] ON
table_name [ USING method ]
( { column_name | ( expression ) } [ COLLATE collation
] [ opclass ] [ ASC | DESC ] [ NULLS { FIRST | LAST } ]
[, ...] )
[ WITH ( storage_parameter = value [, ... ] ) ]
[ TABLESPACE tablespace_name ]
[ WHERE predicate ]在创建索引的时候 PostgreSQL 会锁定表以防止写入,然后对表做全表扫描,从而完成创建索引的操作。在此过程中,其他用户仍然可以读取表,但是插入、更新、删除等操作将一直被阻塞,直到索引创建完毕。如果这张表是更新较频繁且比较大的表,那么创建索引可能需要几十分钟,甚至数个小时,这段时间内都不能做任何插入、删除、更新操作,这在大多数的在线数据库中都是不可接受的。鉴于此,PostgreSQL 支持在不长时间阻塞更新的情况下建立创建索引,这是通过在 CREATE INDEX 中加 CONCURRENTLY 选项来实现的。当该选项被启用时,PostgreSQL 会执行表的两次扫描,因此该方法需要更长的时间来建索引。尽管如此,该选项也是很有用的。
修改索引的语法:
ALTER INDEX name RENAME TO new_name
ALTER INDEX name SET TABLESPACE tablespace_name
ALTER INDEX name SET ( storage_parameter = value [, ... ])
ALTER INDEX name RESET ( storage_parameter [, ... ] )
DROP INDEX [ IF EXISTS ] name [, ...] [ CASCADE |RESTRICT ]1、B-tree 索引
B-tree 索引使用 B-tree 数据结构来存储索引数据,可用于处理等值查询和范围查询,包括<、<=、=、>=、>等运算符,以及BETWEEN、IN、IS NULL、IS NOT NULL等条件。B-tree 还可以用于查询结果集排序,如 order by 排序。
B-Tree 索引结构参考自德哥 https://github.com/digoal/blog/blob/master/201605/20160528_01.md
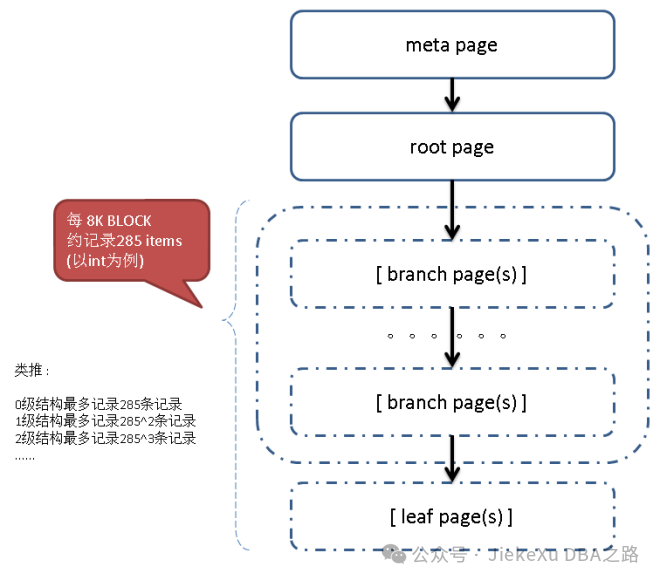
PostgreSQL 的 B-Tree索引页分为几种类别:
meta page root page # btpo_flags=2 branch page # btpo_flags=0 leaf page # btpo_flags=1
如果即是 leaf 又是 root 则 btpo_flags=3。
其中 meta page 和 root page 是必须有的,meta page 需要一个页来存储,表示指向 root page 的 page id。随着记录数的增加,一个 root page 可能存不下所有的 heap item,就会有 leaf page,甚至 branch page,甚至多层的 branch page。 一共有几层 branch 和 leaf,就用 btree page 元数据的 level 来表示。
jiekexu=# create table t_btree(id int, info text);
CREATE TABLE
jiekexu=# insert into t_btree select generate_series(1,100000), md5(random()::text);
INSERT 0 100000
jiekexu=# create index idx_t_btree_id on t_btree using btree (id);
CREATE INDEX
jiekexu=# explain (analyze,verbose,timing,costs,buffers) select * from t_btree where id=1;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------
Index Scan using idx_t_btree_id on public.t_btree (cost=0.29..2.91 rows=1 width=37) (actual time=0.190..0.193 rows=1 loops=1)
Output: id, info
Index Cond: (t_btree.id = 1)
Buffers: shared hit=1 read=2
Query Identifier: -5736424251407899887
Planning:
Buffers: shared hit=23 read=1
Planning Time: 0.672 ms
Execution Time: 0.241 ms
(9 rows)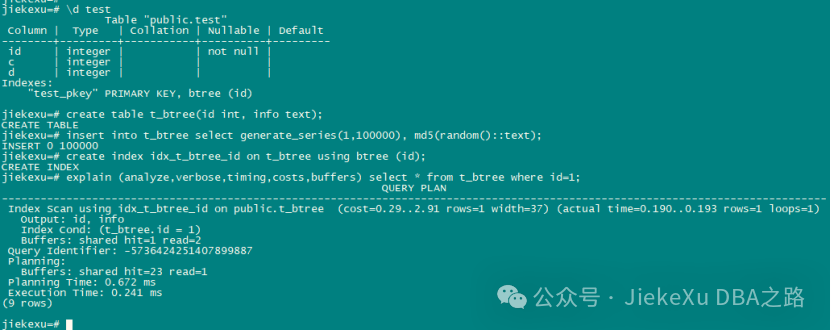
2、Hash 索引
HASH 索引存储一个由索引列计算出的 32 位的 hash code 值。因此,Hash 索引只能处理简单等值比较。每当索引列涉及到等值操作符的比较时,查询规划器将会使用 Hash 索引。
create table t_hash (id int, info text);
insert into t_hash select generate_series(1,100), repeat(md5(random()::text),100000);
create index idx_t_hash_info on t_hash using hash (info);
explain (analyze,verbose,timing,costs,buffers) select * from t_hash where info in (select info from t_hash limit 1);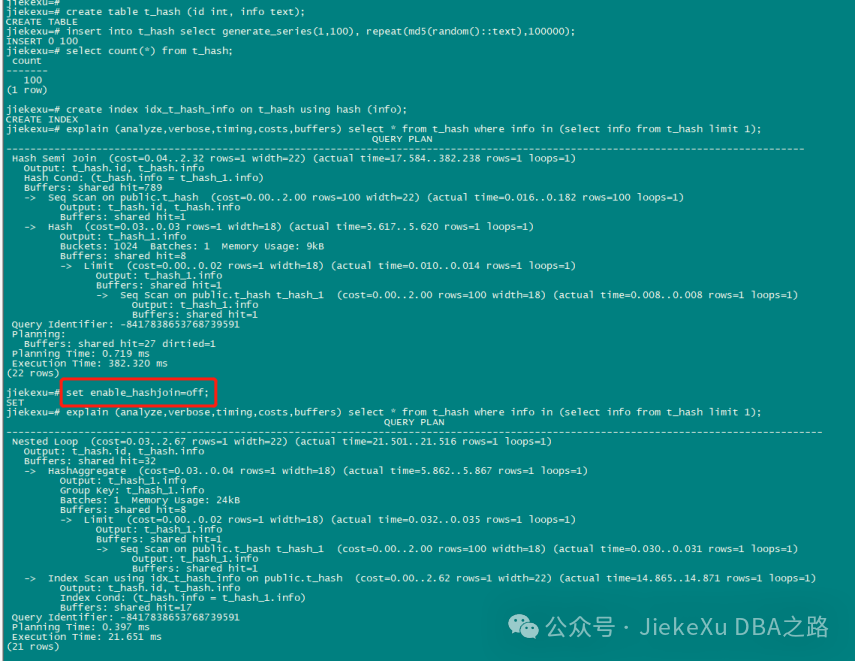
3、GiST 索引
GiST 是 Generalized Search Trees 的缩写,意思是通用搜索树。它不是单独一种索引类型,而是一种架构,可以在这种架构上实现很多不同的索引策略。GiST 索引定义的特定操作符可以用于特定索引策略。PostgreSQL 的标准发布中包含了用于二维几何数据类型的 GiST操作符类,比如,一个图形包含另一个图形的操作符“@>”,一个图形在另一个图形的左边且没有重叠的操作符“<<”,等等。
例如几何类型检索
create table t_gist (id int,pos point);
insert into t_gist select generate_series(1,100000),point(round((random()*1000)::numeric, 2),round((random()*1000)::numeric, 2));
create index idx_t_gist_pos on t_gist using gist (pos);
explain (analyze,verbose,timing,costs,buffers) select * from t_gist where circle '((100,10) 10)' @> pos;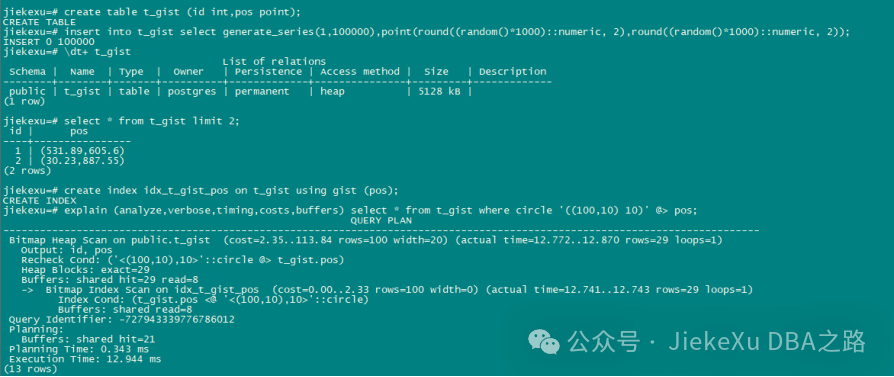
4、SP-GiST 索引
SP-GiST 是 “Space-Partitioned GiST” 的缩写,即空间分区 GiST 索引。它是 从PostgreSQL9.2 版本开始提供的一种新索引类型,和 GiST 相似,SP-GiST 索引为支持多种搜索提供了一种基础结构。SP-GiST 允许实现众多不同的非平衡的基于磁盘的数据结构,例如四叉树、k-d 树和 radix 树。主要是通过一些新的索引算法来提高 GiST 索引在某种情况下的性能。
例如 范围类型搜索
create table t_spgist (id int, rg int4range);
insert into t_spgist select id, int4range(id, id+(random()*200)::int) from generate_series(1,100000) t(id);
create index idx_t_spgist_rg on t_spgist using spgist (rg);
explain (analyze,verbose,timing,costs,buffers) select * from t_spgist where rg && int4range(1,100);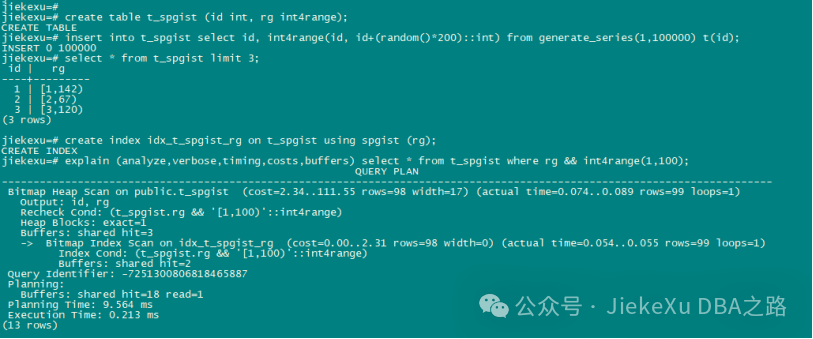
5、GIN 索引
GIN 索引是“倒排索引”,它适合于包含多个组成值的数据值,例如数组。倒排索引中为每一个组成值都包含一个单独的项,它可以高效地处理测试指定组成值是否存在的查询。
create table t_gin (id int, arr int[]);
do language plpgsql $$
declare
begin
for i in 1..10000 loop
insert into t_gin select i, array(select random()*1000 from generate_series(1,10));
end loop;
end;
$$;
select * from t_gin limit 2;
id | arr
----+------------------------------------------
1 | {674,655,48,87,908,745,268,950,655,736}
2 | {927,26,756,374,643,616,377,645,858,592}
(2 rows)
create index idx_t_gin_arr on t_gin using gin (arr);
explain (analyze,verbose,timing,costs,buffers) select * from t_gin where arr && array[1,2];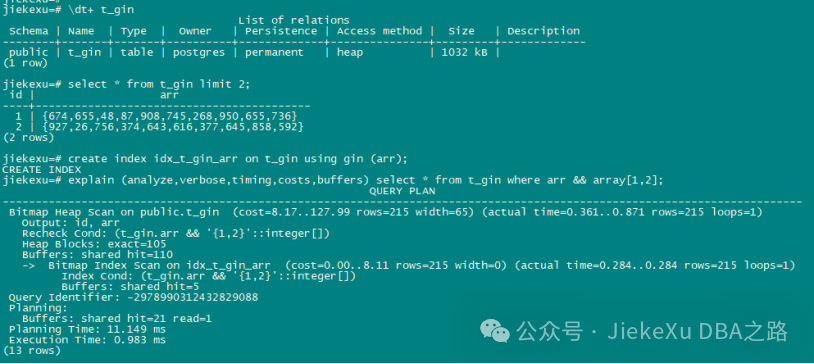
6、BRIN 索引
BRIN 索引(块范围索引的缩写)存储有关存放在一个表的连续物理块范围上的值摘要信息。因此,那些值和table中物理行存放顺序相关性更好的列更高效。与 GiST、SP-GiST 和 GIN 相似,BRIN 可以支持很多种不同的索引策略,并且可以与一个 BRIN 索引配合使用的特定操作符取决于索引策略。
BRIN索引是块级索引,它不同于B-tree等索引。BRIN索引在记录数据时,以数据块或每段连续的数据块为单位记录信息,而不是以行号为单位记录索引明细。如果块的边界范围很大,或者说块与块之间的重叠度很高,那么BRIN索引的过滤性就很差。因此,BRIN索引仅适合用于检索存储位置与取值线性相关性很强的字段。如时序数据,在时间或序列字段创建BRIN索引,进行等值、范围查询时效果很 Nice。
create table t_brin (id int,info text,crt_time timestamp);
insert into t_brin select generate_series(1,1000000), md5(random()::text), clock_timestamp();
select correlation from pg_stats where tablename='t_brin' and attname='id';
select correlation from pg_stats where tablename='t_brin' and attname='crt_time';
create index idx_t_brin_id on t_brin using brin (id) with (pages_per_range=1);
create index idx_t_brin_crt on t_brin using brin (crt_time) with (pages_per_range=1);
jiekexu=# \d t_brin
Table "public.t_brin"
Column | Type | Collation | Nullable | Default
----------+-----------------------------+-----------+----------+---------
id | integer | | |
info | text | | |
crt_time | timestamp without time zone | | |
Indexes:
"idx_t_brin_crt" brin (crt_time) WITH (pages_per_range='1')
"idx_t_brin_id" brin (id) WITH (pages_per_range='1')
explain (analyze,verbose,timing,costs,buffers) select * from t_brin where id between 100 and 200;
explain (analyze,verbose,timing,costs,buffers) select * from t_brin where crt_time between '2024-03-27 17:18:51.137224' and '2024-03-27 17:18:51.147224';
当然一个索引可以定义在表的多个列上,这样的索引称之为多列索引,CREATE INDEX idx_test_cc ON test2 (c1, c2);目前,只有 B-tree、GiST、GIN 和 BRIN 索引类型支持多列索引。是否可以有多个关键列与INCLUDE列是否可以被添加到索引中无关。索引最多可以有 32 列,包括 INCLUDE 列。
Currently, only the B-tree, GiST, GIN, and BRIN index types support multiple-key-column indexes. Whether there can be multiple key columns is independent of whether INCLUDE columns can be added to the index. Indexes can have up to 32 columns, including INCLUDE columns. (This limit can be altered when building PostgreSQL; see the file pg_config_manual.h.)7、表达式索引
一个索引列并不一定是底层表的一个列,也可以是从表的一列或多列计算而来的一个函数或 者标量表达式。和 Oracle 数据库一样,PostgreSQL 也支持函数索引。实际上,PostgreSQL 索引的键除了可以是一个函数外,还可以是从一个或多个字段计算出来的标量表达式。表达式上的索引并不是在索引查找时进行表达式的计算,而是在插入或更新数据行时进行计算,因此在插入或更新时,表达式上的索引会慢一些。
例子 如果我们经常进行如下的查询:
SELECT * FROM people WHERE (first_name || ' ' || last_name) = 'John Smith';那么值得创建一个这样的索引:
CREATE INDEX people_names ON people ((first_name || ' ' || last_name));如果我们经常进行如下的查询:
SELECT * FROM mytest WHERE lower(note) = 'hello world';那么需要创建一个大小写转换的索引:
CREATE INDEX mytest_lower_note_idx ON mytest (lower(note));8、部分索引
一个部分索引是建立在表的一个子集上,而该子集则由一个条件表达式(被称为部分索引 的谓词)定义。而索引中只包含那些符合该谓词的表行的项。部分索引是一种专门的特性, 但在很多种情况下它们也很有用。
create table test2(id int,info text,crt_time timestamp,active boolean);
create index idx_test2_id on test2(id) where active;
explain (analyze,verbose,timing,costs,buffers) select * from test where active and id=1;
9、全文索引
PostgreSQL 内置了全文检索功能,但内置的功能只能检索英文。PostgreSQL 全文检索的搜索过程实际上使用一个 tsvector 和 tsquery 进行匹配,tsvector 代表了文档,而 tsquery 代表了检索条件,匹配的运算符是“@@”。
postgres=# select 'We Love PostgreSQL Database'::tsvector;
tsvector
-------------------------------------
'Database' 'Love' 'PostgreSQL' 'We'
(1 row)当然还有 zhparser、rum 等索引插件可以用于全文检索,由于个人能力有限,这里就不介绍了,等以后有时间学习了再介绍。
参考链接
https://docs.oracle.com/en/database/oracle/oracle-database/23/cncpt/indexes-and-index-organized-tables.html#GUID-ACA0308E-5F01-4236-81D3-D0CDE5CB6695
https://docs.oracle.com/en/database/oracle/oracle-database/23/admin/managing-indexes.html#GUID-E637BC13-A2CA-454D-B680-07B95F7C4CE4
https://dev.mysql.com/doc/refman/8.0/en/optimization-indexes.html
https://www.postgresql.org/files/documentation/pdf/16/postgresql-16-A4.pdf全文完,希望可以帮到正在阅读的你,如果觉得有帮助,可以分享给你身边的朋友,同事,你关心谁就分享给谁,一起学习共同进步~~~