nosql 数据库 mongodb 简述
原创nosql 数据库 mongodb 简述
原创
mongodb
提到关系型数据库,mysql 和 oralce 是这方面的主流,而缓存方面 memcached 和 redis ,当然 memcached 在多台服务器的下会出现缓存不一致问题,因此 redis 应运而生。
而随着互联网业务的扩展和数据量的增大,关系型数据库已经满足不了当前使用,关系型数据库大多是一对一,对一对多的数据处理较为困难,虽然我们可以用 join 来连接各种各样的数据,但是这种这种操作性能也会增大。
mongodb 就是基于这样的数据关系类型产生的。
当然当我们的数据中一个对象需要不只是一对多的数据,也需要跟他平级的多个对象时候,图关系就产生了,图数据库也就产生了。
简单操作
因为只有一篇文章,所以很多操作不能讲的太细,这里只是对于抛砖引玉,很多细节需要自己去操作。
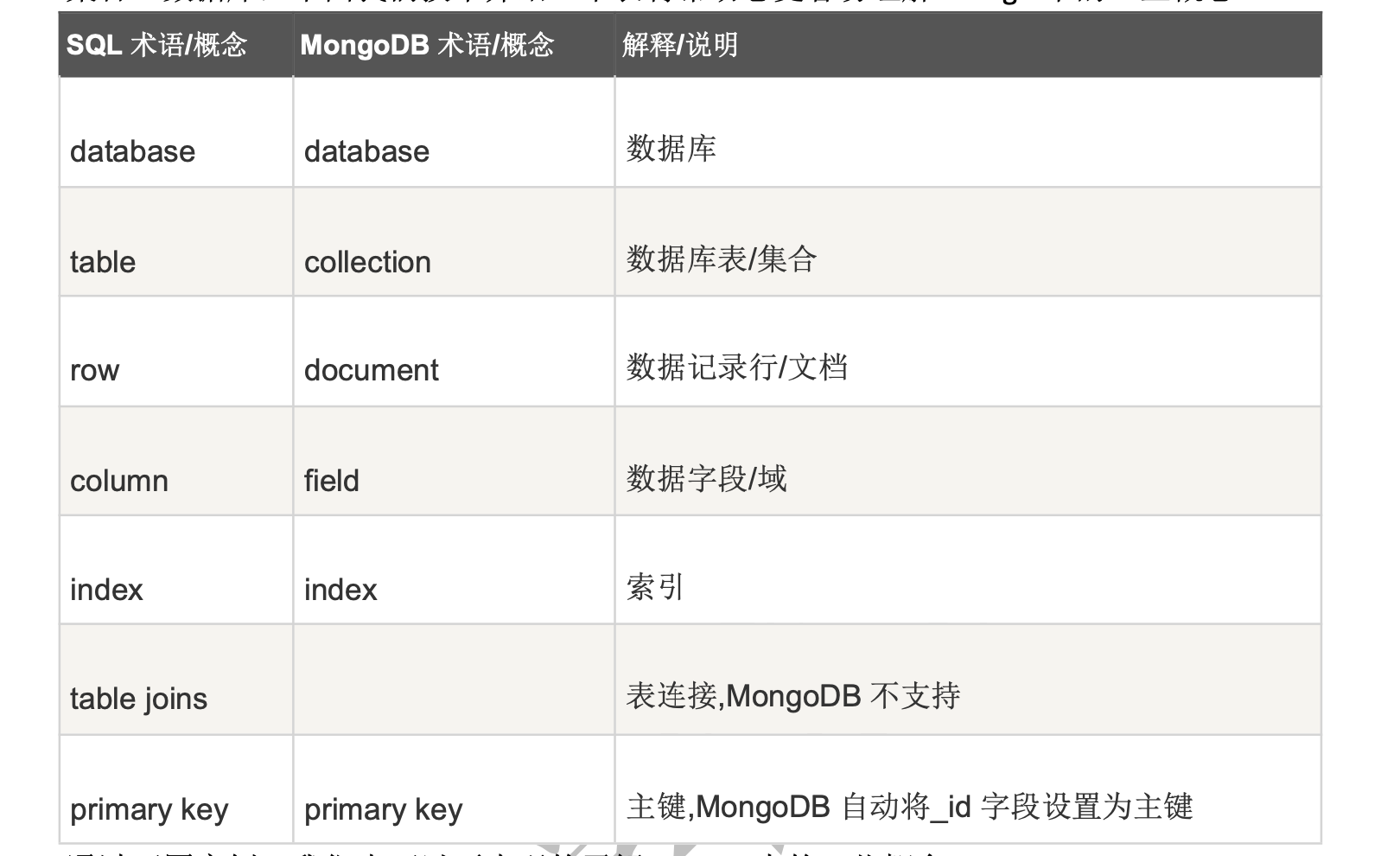
mongodb 中一些层级关系上跟关系型数据库很类似,只是数据的支持更加多样化。
具体语法就不说了,这里看一些我认为有用的东西。
URI连接
mongodb://[username:password@]host1[:port1][,host2[:port2],...[,hostN[:portN]]][/[database][?options]]上述是连接 mongodb 需要的 URI 的格式,其中带 [] 是可以省略的,其默认的连接端口是 27017
索引
mongodb 中索引使用 b tree 也叫 b- tree ,不过不同于 mysql 的 myisam 存储引擎的索引结构,mongodb 的所有数据结构和数据都在内存中,而mysql 的数据在磁盘中。
创建索引的的语法是:
//创建索引
db.col.createIndex({"title":1})
//查看集合索引
db.col.getIndexes()
//查看集合索引大小
db.col.totalIndexSize()
//删除集合所有索引
db.col.dropIndexes()
//删除集合指定索引
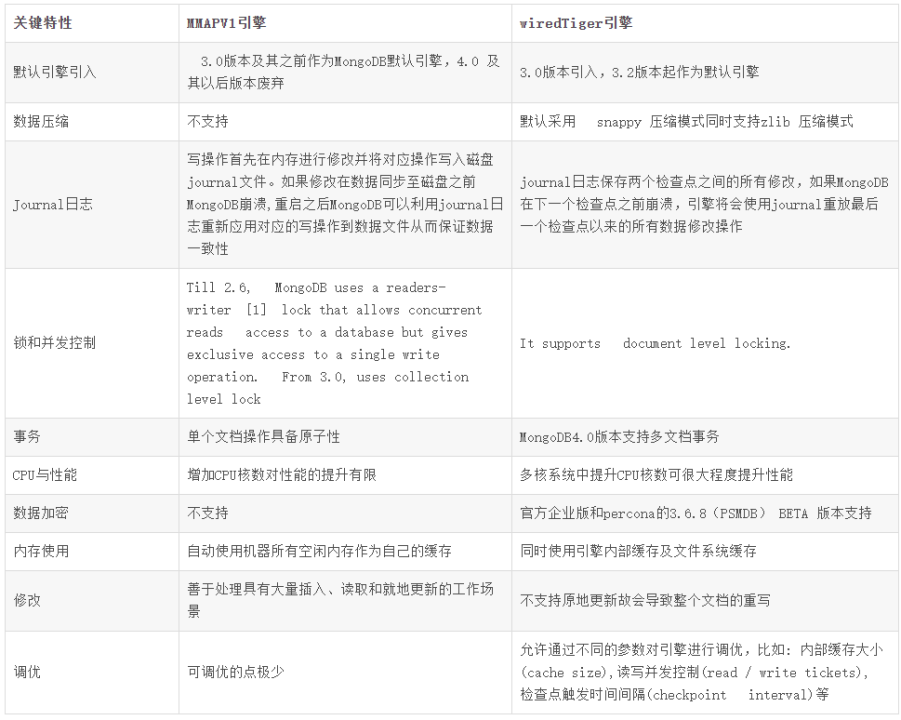
db.col.dropIndex("索引名称")3.0 是mongodb 的一个重大版本变更,其中存储引擎和一些语法都发生了变化。
这里放一张图,对比引擎区别:
复制和分片
分布式数据库都需要做数据同步,一般结构是主从复制,一个主节点,多个从节点,主节点负责各种数据写入,从节点从主节点同步各种数据。
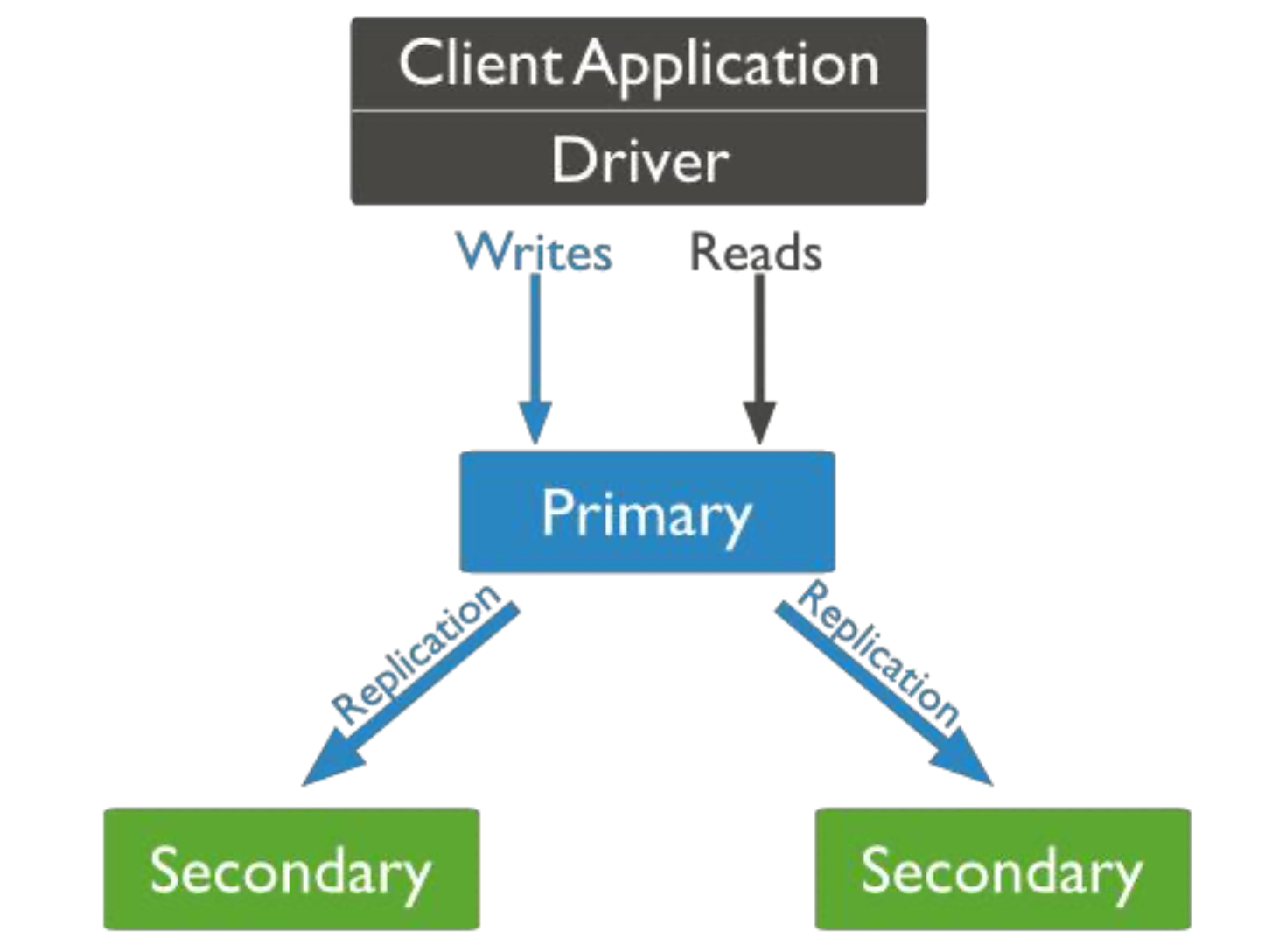
当然在后端开发中节点之间使用类似于 mysql 的主从复制。
我们的主节点主要负责一些数据的增删改操作,数据同步到从节点,从节点主要负责一些查找的操作。
不过由于数据同步需要时间,如果数据更改之后立刻进行查询就会出错,因此一般会在数据更改后弦设置一个过期时间,如果在过期时间内查询就将请求发送到主节点,如果超过过期时间就去从节点查询。
这一切的操作都有一个前提,就是我们一台服务器可以容纳我们这样的数据量,如果数据大到一台服务器无法容纳,那就需要对数据进行分割了。
这也就是分片的作用,在大数据领域,有 hdfs ,大概意思就是通过在数据库中存储元数据,我们每次查询数据,通过元数据定位数据位置,然后分步计算,最终汇总。
分片也差不多类似思想,将大量数据分布到不同服务器中。
持久化和加载
任何一个数据库都要考虑数据持久化和对持久化后数据加载到内存的事情。
持久化命令
mongodump -h dbhost -d dbname -o dbdirectory而数据加载的命令是:
mongorestore -h <hostname><:port> -d dbname <path>监控
监控最常见操作时可视化,可视化是所有程序成功的关键,面向业务的场景可视化是必不可上一部分。
不过,mongodb 没有自带可视化功能,他只是提供了两个个命令行工具。
mongostat
mongotop
不过对这两个命令封装一下,做点前端页面就可以很好的可视化了。
代码操作
终于到了代码操作了,很多语言都有一些外置的 mongodb 包,Java 有 jar 包,golang 有 GitHub 项目,不过因为使用了 c 语言,所以需要对其中驱动进行编译。
源码编译以及加载到项目中就不在这里赘述。
以下是保存数据到 mongodb 的函数
#include <mongoc.h>
#include <bson.h>
void saveLocationData(mongoc_collection_t *collection) {. //collection 是一个连接
//获取定位数据,JOSN
char json[4096] = {0}; //json数据
http_request(json); //这里是一个自定义函数,因为主要将 mongodb 就不展开,他的功能是获取服务器返回的 json
printf("%s\n", json);
bson_error_t error;
bson_t *bson;
char *string;
bson = bson_new_from_json((const uint8_t *)json, -1, &error); //将json 数据转化成 bson
if (!bson) {
printf("error\n");
}
//for (int i=0; i<100000; i++) {
bool r = mongoc_collection_insert(collection, MONGOC_INSERT_NONE, bson, NULL, &error); //保存到mongodb
if (!r) {
printf("insert failure %s\n", error.message);
}
//}
bson_destroy(bson); //销毁bson
}这里的逻辑比较清晰,整体来说就是获取请求返回的 json,将其转化为 bson ,存入mongodb 。 因为 mongodb 存入的数据为 bson ,所以需要转化。
那么这个 collection 怎么来的。
mongoc_collection_t *collection;
mongoc_database_t *database;
mongoc_client_t *client;
mongoc_init();
client = mongoc_client_new("mongodb://localhost:27017");
if (client == NULL) {
printf("error\n");
return -1;
}
collection = mongoc_client_get_collection(client, "database","collection");
....//dosomething
mongoc_collection_destroy(collection);
mongoc_client_destroy(client);
mongoc_cleanup();数据库创建有一定规范,只要按照相应的内容进行操作即可。
最后,从代码大家其实可以看出来,使用 c 语言操作 mongodb 远不如 Java golang 等语言操作简便,所以做后端开发,云计算还是用 Java golang 这些语言,只有做一些底层的时候在用 c,c++吧。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。