【他山之石】CVPR 2024|NTU联合UM提出InteractDiffusion,即插即用的HOI交互扩散模型!!!
【他山之石】CVPR 2024|NTU联合UM提出InteractDiffusion,即插即用的HOI交互扩散模型!!!

“他山之石,可以攻玉”,站在巨人的肩膀才能看得更高,走得更远。在科研的道路上,更需借助东风才能更快前行。为此,我们特别搜集整理了一些实用的代码链接,数据集,软件,编程技巧等,开辟“他山之石”专栏,助你乘风破浪,一路奋勇向前,敬请关注!
近一段时间以来,扩散模型在各大厂商以及众多学术顶会上都受到了广泛的关注,尤其是大规模文本到图像(text-to-image,T2I)扩散模型,在生成富含语义的连贯图像方面展现出了惊人的效果。最近的一些工作开始尝试在扩散模型中引入对象定位、姿态和图像轮廓等因素的控制,这对于个性化图像生成任务具有重要意义。但是目前的方法对于生成图像中对象之间的交互关系控制的并不是很好,本文介绍一篇来自南洋理工大学和马来亚大学合作完成的论文。
本文提出了一种全新的可控扩散模型框架InteractDiffusion,InteractDiffusion重点研究了如何利用人与物体交互(HOI)信息来扩展现有的扩散模型,该信息由三元组标签(人、动作、物体)和相应的边界框组成,可以灵活的嵌入到各种扩散模型中生成复杂的交互图像。本文方法生成的图像在 HOI 检测分数以及 FID 和 KID 的保真度方面均大幅优于现有基线。

论文题目:
InteractDiffusion: Interaction Control in Text-to-Image Diffusion Model
论文链接:
https://arxiv.org/abs/2312.05849
项目主页:
https://jiuntian.github.io/interactdiffusion/
一、引言
虽然现有的扩散模型可以生成各种高质量图像来重建原始数据分布,但从用户使用的角度来看,如何有效的控制生成的内容要比图像本身的质量更加重要。现有的一些方法通过图像边缘信息,例如线条、布局和骨架等因素来控制图像生成。然而这些因素仍然无法完整的表述用户的意图,特别是对象之间的交互关系。下图展示了GLIGEN的扩散生成效果,其通过添加布局作为条件来控制对象的生成位置,但是可以看到,在物体交互细节上仍然有所欠缺(例如女子手提包的部分)。
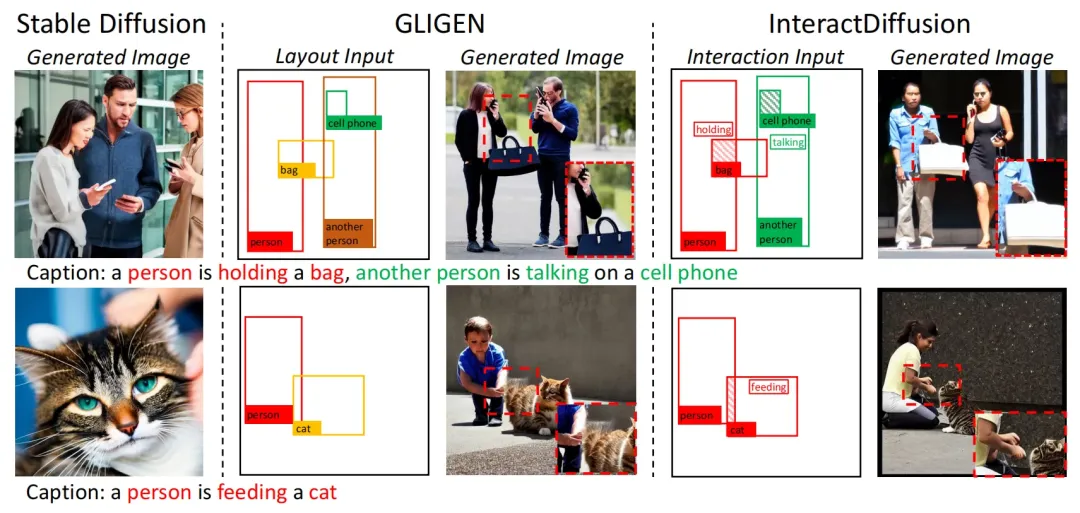
因而本文将物体交互作为一个图像生成任务中的另一个重要控制信息,提出了一种称为InteractDiffusion的交互扩散模型,InteractDiffusion可以灵活的插入到现有的T2I扩散模型中,能够准确的识别用户输入prompt中的交互信息,并使用富含语义的token来将其表示为HOI三元组〈主体,动作,客体〉,这种形式提高了模型对于复杂交互的表示能力。InteractDiffusion的生成效果如上图右侧所示,可以看到,相比GLIGEN,InteractDiffusion可以完美的描绘出女子手挎包动作的细节。
二、本文方法
本文提出的InteractDiffusion整体框架如下图所示,为了实现在现有T2I扩散模型实现即插即入的功能,作者将交互模块独立定义为扩散模型中的一个子模块(Interaction Module)。作者首先为每个HOI三元组生成三个不同的主体、动作和客体token。其中主体和客体token包含有关位置、大小和对象类别的信息,动作token主要包含交互的位置及其类别标签。由于现有的Transformer 块由自注意力层和交叉注意力层组成,因而作者在它们之间设计了一个新的交互自注意力层,以将交互token嵌入到现有的T2I模型中。
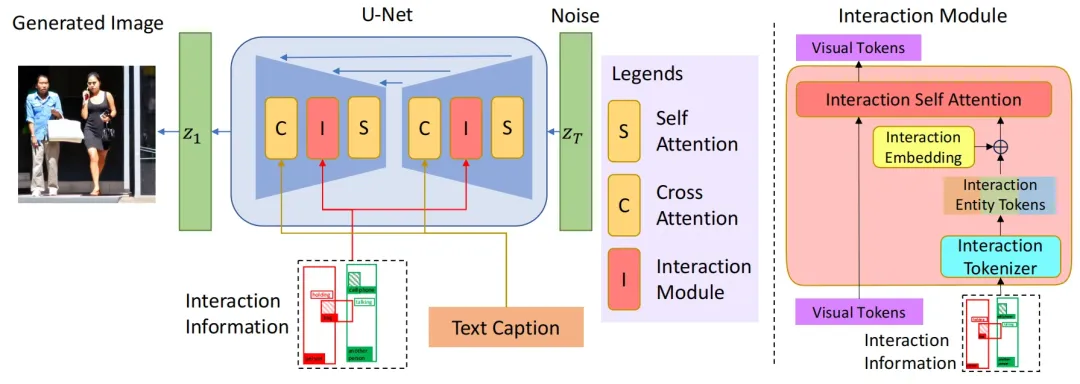
2.1 交互Tokenizer(InToken)
、、
为了获得完整的交互边界框,作者额外定义了一个 “between”操作,同时作用于于主体和客体的边界框之上来获取交互边界。
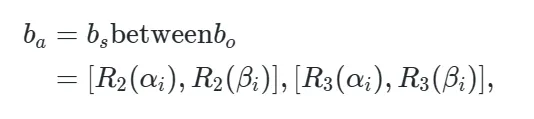
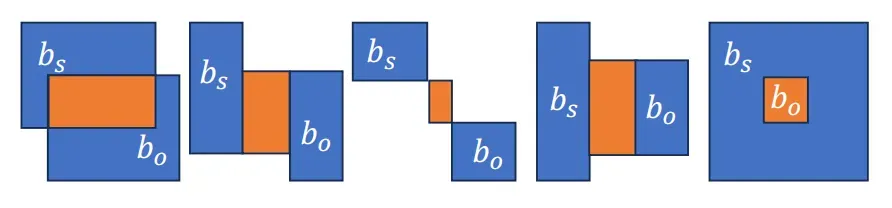
当执行完between操作后,我们可以得到完整的交互实例
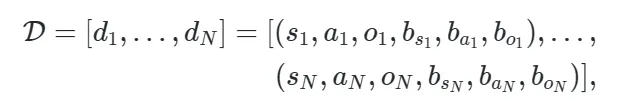
随后就可以对交互实例执行tokenize操作,整体流程如下图所示,作者首先将文本标签和边界框预处理为中间特征表示,其中文本嵌入使用CLIP 文本编码器,边界框编码使用傅里叶嵌入。
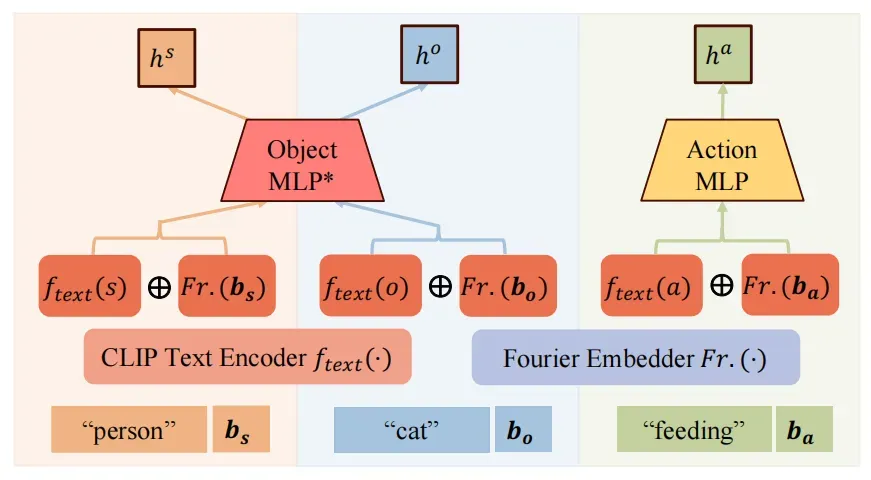
为了分别生成主体、客体的token,作者设置了不同的MLP进行特征融合,融合过程如下:
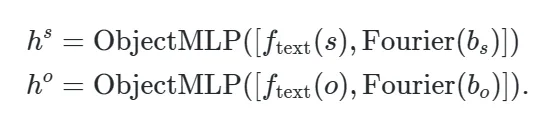
对于交互动作token,考虑到交互动作在语义上应该与主体和客体分开,因而作者训练了一个单独的多层感知机进行处理:
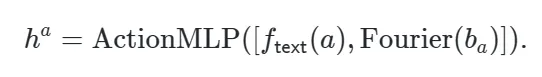
2.2 交互Embedding(InBedding)
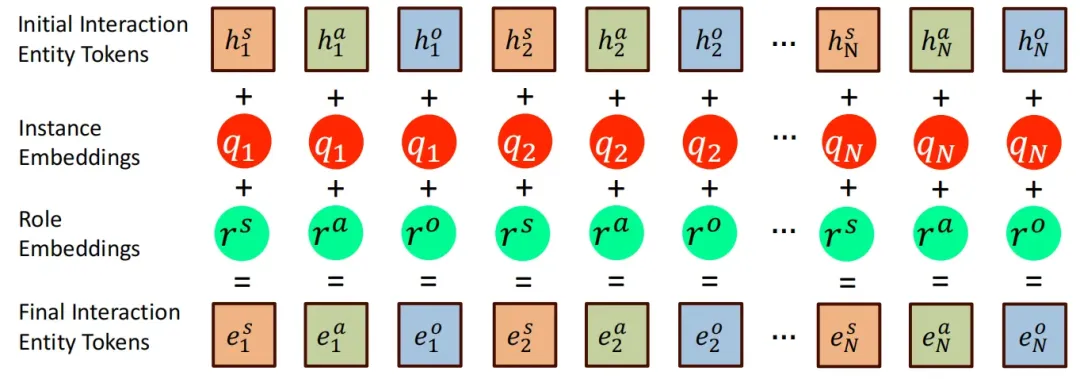
对于多个交互实例的主体、客体和交互动作的tokens,首先需要进行分组,并转换为对应语义的 embeddings,
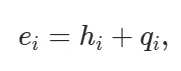
其中同一实例中的所有token共享相同的新嵌入,因此对于三元组中的每个token,都需要添加新的共享嵌入以形成最终的token:
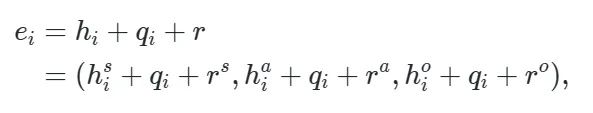
、
通过将共享嵌入添加到整体token中,可以有效的对用户提示中复杂的交互关系进行编码
2.3 Interaction Transformer(InFormer)
因此需要保证在注入过程中不损失原有模型蕴含的先验知识
,
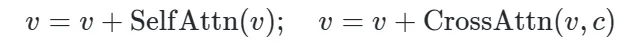
在本文中,作者冻结了上述两个原始注意力层,并在它们之间引入了一个新的门控自注意力层,即交互注意力机制,如下图所示。
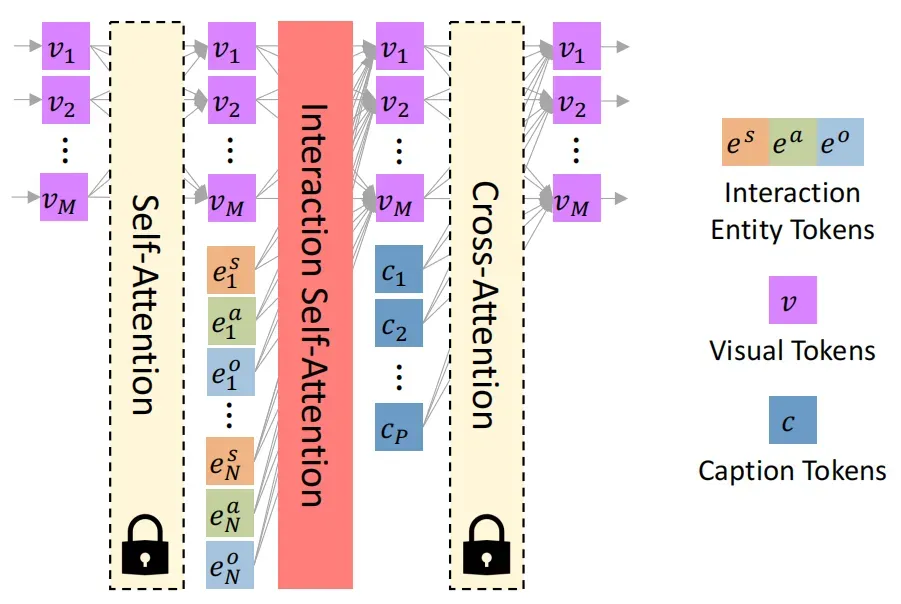
随后作者将InToken、InBedding 和 InFormer 结合起来形成即插即用的交互模块,
三、 实验效果
本文的实验在HOI检测领域中的标准数据集HICO DET上进行,该数据集包含了47776 张图像,HICO-DET 包括 600 种 HOI 三元组,由 80 个宾语类别和 117 个动词类别构成。作者以512x512的分辨率训练和评估模型,并且使用基于 StableDiffusion v1.4 的预训练 GLIGEN 模型来初始化模型。batchsize大小设置为 8,在 2 个 NVIDIA GeForce RTX4090 GPU 上训练大约 160 小时。实验评估指标使用FID、MMD和HOI Score三种指标,其中前两者可以用来评估生成图像与标签图像之间的距离。HOI Score主要通过图像中交互区域的检测精确率来作为生成模型对交互可控性的度量,为了对模型的HOI鲁棒性进行评估,作者还设置了两类HOI Score,即对默认对象和已知对象进行检测,其中默认设置更具挑战性,因为它需要区分不相关的图像。
下图展示了本文InteractDiffusion方法与其他基线方法的生成效果展示,从结果我们可以看出,InteractDiffusion相比其他模型更好的呈现了对象之间的交互关系,更加吻合用户提供的交互指令。而其他模型在一些复杂的情况中,会误解交互指令的语义信息。虽然GLIGEN方法中也加入了布局控制信息来定位对象,但是其对交互细节的生成往往会出现错误。例如下图(a)-(c)的交互细节均出现了明显的细节错误。而本文方法可以保持人与物体之间交互的连贯性和自然性。

下表展示了本文方法与其他方法在质量和交互可控性方面的定量对比结果,从表中可以看出,本文方法在FID、KID 和 HOI Score三种评估指标上均取得了SOTA性能。
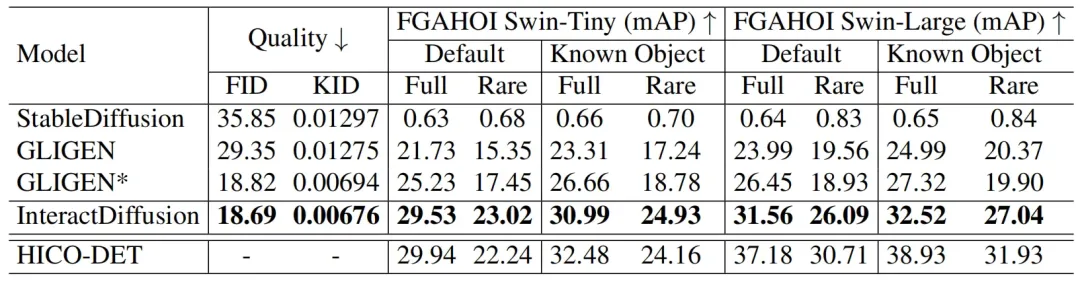
对于图像生成质量(FID、KID指标),InteractDiffusion的提升相比其他方法并不明显,但是在HOI检测方面,本文方法的性能远远超过了其他方法,这是由于本文方法将交互控制信息作为扩散生成的核心条件,因而在生成过程中能够精确的定位目标的位置,同时生成较好的交互细节。
四、总结
本文针对现有条件T2I扩散模型进行了改进,提出了一种即插即用的交互模块,称为InteractDiffusion。具体来说,作者首先对用户输入指令中的HOI信息进行tokenize处理,并通过设置交互嵌入来构建主体、客体和交互动作的token。此外,本文还针对HOI信息引入了一种新的交互注意力机制,可以将HOI信息映射到主体、客体的嵌入空间中,从而引导扩散模型更加关注物体之间的交互信息,提高交互生成质量。
参考资料
[1] Yuheng Li, Haotian Liu, Qingyang Wu, Fangzhou Mu, Jian- wei Yang, Jianfeng Gao, Chunyuan Li, and Yong Jae Lee. Gligen: Open-set grounded text-to-image generation. In CVPR, pages 22511–22521, 2023.
本文目的在于学术交流,并不代表本公众号赞同其观点或对其内容真实性负责,版权归原作者所有,如有侵权请告知删除。
收藏,分享、在看,给个三连击呗