基于NVIDIA Jetson AGX Orin和Audio2Face做一个AI聊天数字人
基于NVIDIA Jetson AGX Orin和Audio2Face做一个AI聊天数字人

本文教程来自:
在当今的数字化时代,逼真会说话的虚拟形象(或称为“avatar”)已经成为一种全新的交流和表达方式。在本篇文章里,博主介绍如何利用NVIDIA Jetson AGX Orin 开发者套件、NVIDIA Omniverse平台以及强大的Unreal Engine虚幻引擎制作一个的逼真会说话的avatar。
原文地址:www.hackster.io/shahizat/ai-powered-photorealistic-talking-avatar-abac41
项目背景
想象一下,拥有一个栩栩如生的数字化身(avatar),它不仅看起来像真人,而且听起来和行动起来也像真人。这不再是科幻小说的领域,而是由NVIDIA Jetson AGX Orin Developer Kit、NVIDIA Omniverse和Unreal Engine等尖端技术实现的现实。
在这个项目中,我们将深入探索逼真的会说话的化身世界,并探讨这些技术是如何结合在一起,创造出一种真正身临其境的体验的。基本上,我们可以使用化身来构建对话代理、虚拟助手、聊天机器人等。无论您是开发者还是技术爱好者,这个项目都适合您。
项目架构
以下是该系统的工作原理:
系统从麦克风的音频输入开始。该输入由运行在NVIDIA Jetson AGX Orin开发者套件上的OSC客户端捕获。客户端利用Nvidia Riva文本转语音技术(TTS)、Nvidia Riva自动语音识别(ASR)以及大型语言模型进行推断。处理后的音频数据随后通过由达斯汀·富兰克林(@dusty-nv)开发的名为Llamaspeak的Python应用程序传递到OSC服务器。OSC服务器使用Audio2Face从音频生成面部动画。最后,在配备RTX显卡的PC上运行的虚幻引擎5(Unreal Engine 5)会渲染出最终的面部动画输出。
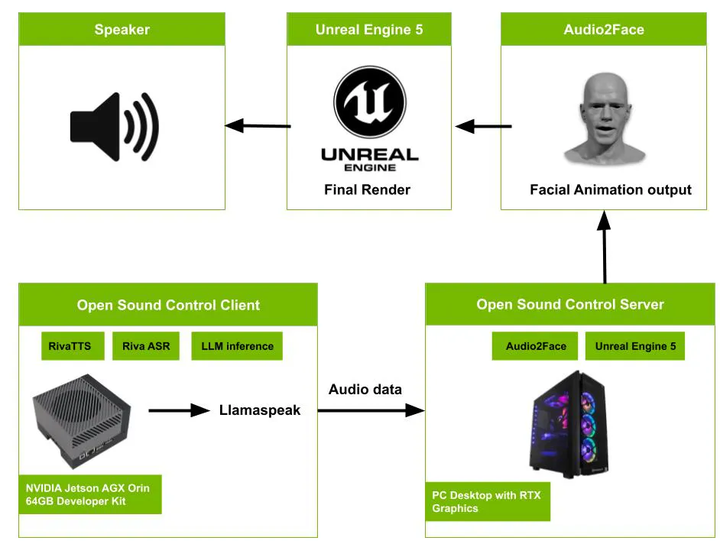
此架构展示了一个复杂的工作流程,该流程将音频输入转换为面部动画。它利用了语音识别、文本转语音和唇音同步等先进技术,以及强大的计算硬件(NVIDIA Jetson AGX Orin)和先进的渲染软件(虚幻引擎5)。
Nvidia Omniverse Audio2Face
让我们首先讨论Nvidia Omniverse Audio2Face,这是一项革命性的技术,它能够创建具有逼真面部表情和动作的逼真数字化身。它是一种基于音频输入为3D角色生成面部动画的AI工具。它可以处理预先录制的语音或实时音频馈送,使其适用于各种应用。Omniverse Audio2Face最好的地方在于它易于使用。您只需提供一个音频文件或实时音频馈送,该工具即可自动生成逼真的面部表情。
此外,此工具可以与第三方渲染应用程序(如虚幻引擎5)集成。开发人员可以轻松地将面部动画集成到Metahuman角色中,从而简化动画工作流程。
Audio2Face适用于配备Nvidia RTX GPU的Windows和Linux用户。可以从Nvidia Omniverse平台下载它。
请从此处下载Omniverse启动器。www.nvidia.com/en-us/omniverse/download/
下载后,双击安装程序文件。
点击“Exchange”选项卡。 在“应用”区域中搜索Audio2Face。 点击Audio2Face的“安装”按钮。

安装完毕后,您可以点击“Exchange”选项卡中的“启动”来打开Audio2Face。
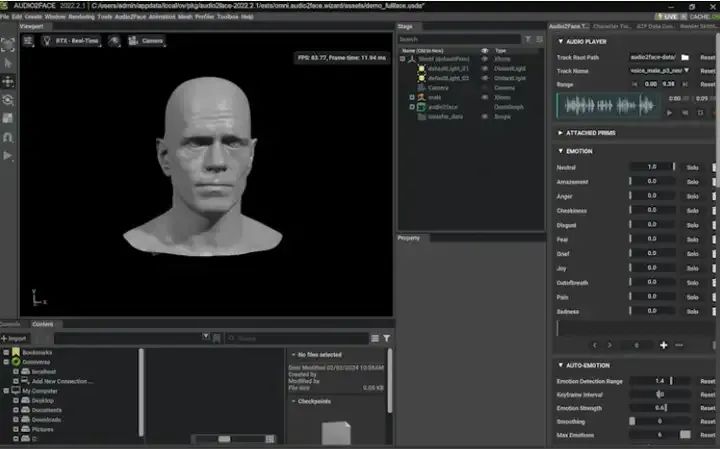
导航到Audio2Face安装目录下的exts\omni.audio2face.exporter\config文件夹。 在文本编辑器中打开extension.toml文件。 将以下内容添加到文件底部:
[python.pipapi]
requirements=['python-osc']
use_online_index=truePython-osc是一个简单的Python中的OpenSoundControl实现,为简单的OSC客户端和OSC服务器提供支持。Open Sound Control(OSC)是音频行业中许多领域常用的开放协议。它主要用于在客户端之间网络传输通用音频数据,尽管它也可以用于非音频数据。 运行以下代码以检查python-osc库是否已在Audio2Face环境中正确安装。

然后导航到安装目录下的exts\omni.audio2face.exporter\omni\audio2face\exporter\scripts文件夹。 在文本编辑器中打开facsSolver.py脚本。此脚本用于使用Open Sound Control协议在Audio2Face和虚幻引擎之间建立通信通道。 在脚本中,添加此行代码以创建一个UDP客户端:
from pythonosc import udp_client
self.client = udp_client.SimpleUDPClient('127.0.0.1', 5008)然后添加以下代码片段。
mh_ctl_list = [
['CTRL_expressions_browDownR', "browLowerR", 1.0],
['CTRL_expressions_browDownL', "browLowerL", 1.0],
['CTRL_expressions_browLateralR', "browLowerR", 1.0],
['CTRL_expressions_browLateralL', "browLowerL", 1.0],
['CTRL_expressions_browRaiseinR', "innerBrowRaiserR", 0.5],
['CTRL_expressions_browRaiseinL', "innerBrowRaiserL", 0.5],
['CTRL_expressions_browRaiseouterR', "innerBrowRaiserR", 0.5],
['CTRL_expressions_browRaiseouterL', "innerBrowRaiserL", 0.5],
['CTRL_expressions_eyeLookUpR', "eyesLookUp", 1.0, "eyesLookDown", -1.0],
['CTRL_expressions_eyeLookDownR', "eyesLookUp", 1.0, "eyesLookDown", -1.0],
['CTRL_expressions_eyeLookUpL', "eyesLookUp", 1.0, "eyesLookDown", -1.0],
['CTRL_expressions_eyeLookDownL', "eyesLookUp", 1.0, "eyesLookDown", -1.0],
['CTRL_expressions_eyeLookLeftR', "eyesLookLeft", 1.0, "eyesLookRight", -1.0],
['CTRL_expressions_eyeLookRightR', "eyesLookLeft", 1.0, "eyesLookRight", -1.0],
['CTRL_expressions_eyeLookRightL', "eyesLookLeft", 1.0, "eyesLookRight", -1.0],
['CTRL_expressions_eyeLookRightL', "eyesLookLeft", 1.0, "eyesLookRight", -1.0],
['CTRL_expressions_eyeBlinkR', "eyesCloseR", 1.0, "eyesUpperLidRaiserR", -1.0],
['CTRL_expressions_eyeBlinkL', "eyesCloseR", 1.0, "eyesUpperLidRaiserR", -1.0],
['CTRL_expressions_eyeSquintinnerR', "squintR", 1.0],
['CTRL_expressions_eyeSquintinnerL', "squintL", 1.0],
['CTRL_expressions_eyeCheekraiseR', "cheekRaiserR", 1.0],
['CTRL_expressions_eyeCheekraiseL', "cheekRaiserL", 1.0],
['CTRL_expressions_mouthCheekSuckR', "cheekPuffR", 0.5],
['CTRL_expressions_mouthCheekBlowR', "cheekPuffR", 0.5],
['CTRL_expressions_mouthCheekSuckL', "cheekPuffL", 0.5],
['CTRL_expressions_mouthCheekBlowL', "cheekPuffL", 0.5],
['CTRL_expressions_noseNostrilDilateR', "noseWrinklerR", 1.0],
['CTRL_expressions_noseNostrilCompressR', "noseWrinklerR", 1.0],
['CTRL_expressions_noseWrinkleR', "noseWrinklerR", 1.0],
['CTRL_expressions_noseNostrilDepressR', "noseWrinklerR", 1.0],
['CTRL_expressions_noseNostrilDilateL', "noseWrinklerL", 1.0],
['CTRL_expressions_noseNostrilCompressL', "noseWrinklerL", 1.0],
['CTRL_expressions_noseWrinkleL', "noseWrinklerL", 1.0],
['CTRL_expressions_noseNostrilDepressL', "noseWrinklerL", 1.0],
['CTRL_expressions_jawOpen', "jawDrop", 1.0, "jawDropLipTowards", 0.6],
['CTRL_R_mouth_lipsTogetherU', "jawDropLipTowards", 1.0],
['CTRL_L_mouth_lipsTogetherU', "jawDropLipTowards", 1.0],
['CTRL_R_mouth_lipsTogetherD', "jawDropLipTowards", 1.0],
['CTRL_L_mouth_lipsTogetherD', "jawDropLipTowards", 1.0],
['CTRL_expressions_jawFwd', "jawThrust", -1.0],
['CTRL_expressions_jawBack', "jawThrust", -1.0],
['CTRL_expressions_jawRight', "jawSlideLeft", -1.0, "jawSlideRight", 1.0],
['CTRL_expressions_jawLeft', "jawSlideLeft", -1.0, "jawSlideRight", 1.0],
['CTRL_expressions_mouthLeft', "mouthSlideLeft", 0.5, "mouthSlideRight", -0.5],
['CTRL_expressions_mouthRight', "mouthSlideLeft", 0.5, "mouthSlideRight", -0.5],
['CTRL_expressions_mouthDimpleR', "dimplerR", 1.0],
['CTRL_expressions_mouthDimpleL', "dimplerL", 1.0],
['CTRL_expressions_mouthCornerPullR', "lipCornerPullerR", 1.0],
['CTRL_expressions_mouthCornerPullL', "lipCornerPullerL", 1.0],
['CTRL_expressions_mouthCornerDepressR', "lipCornerDepressorR", 1.0],
['CTRL_expressions_mouthCornerDepressL', "lipCornerDepressorL", 1.0],
['CTRL_expressions_mouthStretchR', "lipStretcherR", 1.0],
['CTRL_expressions_mouthStretchL', "lipStretcherL", 1.0],
['CTRL_expressions_mouthUpperLipRaiseR', "upperLipRaiserR", 1.0],
['CTRL_expressions_mouthUpperLipRaiseL', "upperLipRaiserL", 1.0],
['CTRL_expressions_mouthLowerLipDepressR', "lowerLipDepressorR", 1.0],
['CTRL_expressions_mouthLowerLipDepressL', "lowerLipDepressorR", 1.0],
['CTRL_expressions_jawChinRaiseDR', "chinRaiser", 1.0],
['CTRL_expressions_jawChinRaiseDL', "chinRaiser", 1.0],
['CTRL_expressions_mouthLipsPressR', "lipPressor", 1.0],
['CTRL_expressions_mouthLipsPressL', "lipPressor", 1.0],
['CTRL_expressions_mouthLipsTowardsUR', "pucker", 1.0],
['CTRL_expressions_mouthLipsTowardsUL', "pucker", 1.0],
['CTRL_expressions_mouthLipsTowardsDR', "pucker", 1.0],
['CTRL_expressions_mouthLipsTowardsDL', "pucker", 1.0],
['CTRL_expressions_mouthLipsPurseUR', "pucker", 1.0],
['CTRL_expressions_mouthLipsPurseUL', "pucker", 1.0],
['CTRL_expressions_mouthLipsPurseDR', "pucker", 1.0],
['CTRL_expressions_mouthLipsPurseDL', "pucker", 1.0],
['CTRL_expressions_mouthFunnelUR', "funneler", 1.0],
['CTRL_expressions_mouthFunnelUL', "funneler", 1.0],
['CTRL_expressions_mouthFunnelDL', "funneler", 1.0],
['CTRL_expressions_mouthFunnelDR', "funneler", 1.0],
['CTRL_expressions_mouthPressUR', "lipSuck", 1.0],
['CTRL_expressions_mouthPressUL', "lipSuck", 1.0],
['CTRL_expressions_mouthPressDR', "lipSuck", 1.0],
['CTRL_expressions_mouthPressDL', "lipSuck", 1.0]
]
facsNames = [
"browLowerL",
"browLowerR",
"innerBrowRaiserL",
"innerBrowRaiserR",
"outerBrowRaiserL",
"outerBrowRaiserR",
"eyesLookLeft",
"eyesLookRight",
"eyesLookUp",
"eyesLookDown",
"eyesCloseL",
"eyesCloseR",
"eyesUpperLidRaiserL",
"eyesUpperLidRaiserR",
"squintL",
"squintR",
"cheekRaiserL",
"cheekRaiserR",
"cheekPuffL",
"cheekPuffR",
"noseWrinklerL",
"noseWrinklerR",
"jawDrop",
"jawDropLipTowards",
"jawThrust",
"jawSlideLeft",
"jawSlideRight",
"mouthSlideLeft",
"mouthSlideRight",
"dimplerL",
"dimplerR",
"lipCornerPullerL",
"lipCornerPullerR",
"lipCornerDepressorL",
"lipCornerDepressorR",
"lipStretcherL",
"lipStretcherR",
"upperLipRaiserL",
"upperLipRaiserR",
"lowerLipDepressorL",
"lowerLipDepressorR",
"chinRaiser",
"lipPressor",
"pucker",
"funneler",
"lipSuck"
]
for i in range(len(mh_ctl_list)):
ctl_value = 0
numInputs = (len(mh_ctl_list[i])-1) // 2
for j in range(numInputs):
weightMat = outWeight.tolist()
poseIdx = facsNames.index(mh_ctl_list[i][j*2+1])
ctl_value += weightMat[poseIdx] * mh_ctl_list[i][j*2+2]
print(mh_ctl_list[i][0], ctl_value)
self.client.send_message('/' + mh_ctl_list[i][0], ctl_value)
return outWeight总的来说,此代码片段会根据音频输入转换各种面部表情的权重值,并向虚幻引擎发送控制信号,以便相应地驱动3D角色的面部动画。
然后,将“male_bs_arkit.usd”文件拖放到插件窗口中。该文件包含男性角色脸部的混合变形数据。
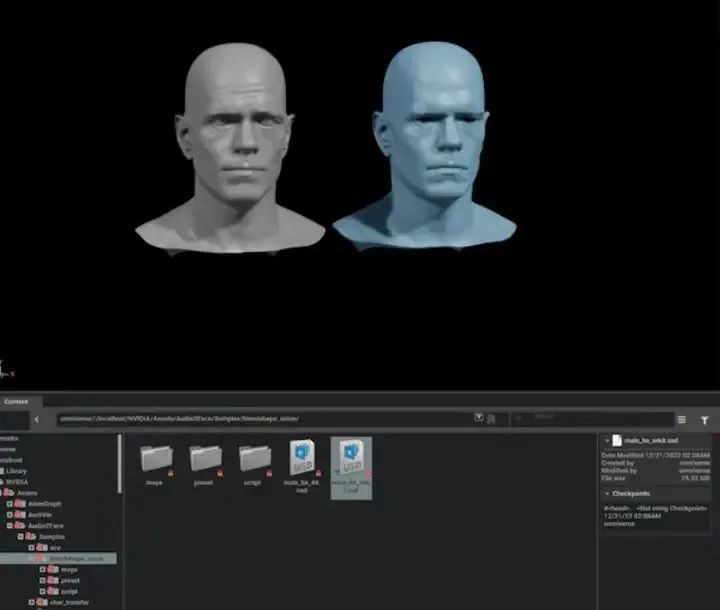
现在请进入Audio2Face插件中的“A2F数据转换”部分,这个区域能让您为角色设定输入的动画数据和混合变形网格。
在“A2F数据转换”区域中,请从下拉菜单里选择“输入动画”以及“混合变形网格”。这样设置后,Audio2Face就能利用“male_bs_arkit.usd”文件中的混合变形数据来生成一个可由音频输入驱动的网格了。

最后,点击“设置混合变形解决方案”按钮,将混合变形数据应用到网格上并启用动画。点击此按钮后,您应该会看到角色的脸部开始根据男性形状产生动画效果。
在Audio2Face中播放音频文件,观察角色的脸部是否会随着音频进行相应的动画响应。
Unreal Engine与MetaHumans
Unreal Engine是由Epic Games开发的一款功能强大且多功能的实时3D创作工具。它主要用于视频游戏的开发。
MetaHuman Creator是一个在线的、用户友好的3D设计工具,用于创建高度逼真的数字人,这些数字人可以在Unreal Engine中进行动画处理。它允许任何人在短短几秒钟内创建出定制的、逼真的AI头像。
打开Unreal Engine并创建一个新的Unreal Engine项目。
然后转到“编辑”->“插件”,并启用OSC服务器和Apple ARKit插件。
OSC插件支持应用与设备之间的通信,这对于从外部源接收动画数据至关重要。
Apple ARKit可在引擎内提供增强现实体验,有可能会提升您的项目效果。

OSC服务器充当了发送给Unreal Engine本地实例的消息的监听端点。
重新启动Unreal Engine。然后访问Quixel Bridge。
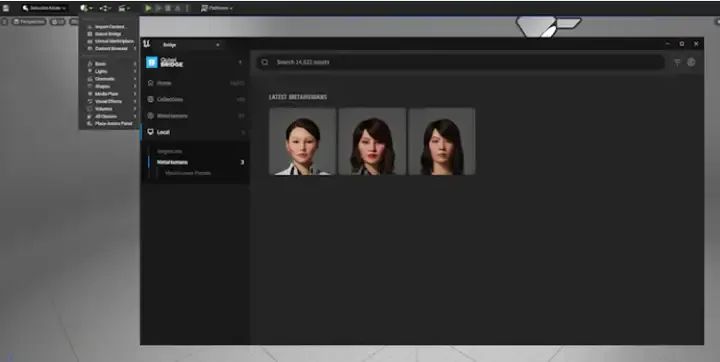
Quixel Bridge是连接Unreal Engine和各种内容库(包括MetaHuman Creator)的桥梁。
导入您的MetaHuman。

您可以导入在MetaHuman Creator中创建的MetaHuman,也可以从Quixel Bridge中提供的50多个预制模型中进行选择。
按“添加”按钮将MetaHuman模型导入到场景中。

将模型从内容浏览器拖放到角色蓝图中。
然后打开MetaHuman蓝图。这涉及创建定义角色运动和行为的可视化脚本。

蓝图是Unreal Engine中的可视化脚本工具,它允许您定义角色的行为和功能。

根据蓝图的类型,每个蓝图可以包含一个或多个图表,这些图表定义了蓝图特定方面的实现。在这里,我们创建了一个OSC服务器,用于从端口5008的远程节点接收输入数据。

此蓝图专门处理MetaHuman角色的面部动画和控制。编译并保存动画蓝图。
您已成功将MetaHumans集成到您的Unreal Engine项目中。现在,我们可以在项目中为它们添加动画,将它们添加到场景中,并赋予它们生命。
整合所有内容
llamaspeak是由英伟达(Nvidia)的达斯汀·富兰克林(Dustin Franklin)开发的一种基于网络的语音助手实现。它能够通过RIVA ASR理解口语,使用LLM处理它,并通过RIVA TTS生成语音响应,为在NVIDIA Jetson板上使用类似ChatGPT的大型语言模型的用户提供对话体验。
现在我们可以将所有部分组合在一起并运行它。
要在带有RTX显卡的Windows机器上运行Audio2Face,请按照以下步骤操作:
在Windows机器上打开命令提示符。通过运行以下命令导航到包含Audio2Face应用程序的目录:
cd C:\Users\admin\AppData\Local\ov\pkg\audio2face-2022.2.1通过执行以下命令在无头模式下启动Audio2Face
audio2face_headless.kit.bat无头模式是Audio2Face的一项功能,它允许您无需图形用户界面即可运行程序。
执行命令后,您将看到几行输出,指示Audio2Face运行所需的各种扩展的启动。启动过程完成后,Audio2Face管道就可以使用了。
接下来,在Nvidia Jetson AGX Orin 64GB上,通过运行以下命令登录到您的Docker帐户:
docker login然后,在终端中运行命令bash riva来启动Nvidia Riva服务器。
bash riva执行以下命令来启动text-generation-webui服务:
./run.sh --workdir /opt/text-generation-webui $(./autotag text-generation-webui:1.7) \
python3 server.py --listen --verbose --api \
--model-dir=/data/models/text-generation-webui \
--model=mistral-7b-instruct-v0.2.Q4_K_M.gguf \
--loader=llamacpp \
--n-gpu-layers=128 \
--n_ctx=4096 \
--n_batch=4096 \
--threads=$(($(nproc) - 2))这将使用指定的Mistral 7B Instruct模型和配置启动text-generation-webui服务。
运行以下命令来执行Llamaspeak应用程序的run.sh脚本:
./run.sh --workdir=/opt/llamaspeak \
--env SSL_CERT=/data/cert.pem \
--env SSL_KEY=/data/key.pem \
$(./autotag llamaspeak) \
python3 chat.py --verbose之后,系统会提示您是否拉取一个兼容的容器。请按照提示操作。
Found compatible container dustynv/llamaspeak:r35.4.1 (2023-12-05, 5.0GB) - would you like to pull it? [Y/n] n
Couldn't find a compatible container for llamaspeak, would you like to build it? [y/N]y如果未找到容器,当提示构建容器时,请输入y进行构建。
running ASR service (en-US)
-- running TTS service (en-US, English-US.Female-1)
-- running AudioMixer thread
-- starting webserver @ 0.0.0.0:8050
-- running LLM service (mistral-7b-instruct-v0.2.Q4_K_M.gguf)
* Serving Flask app 'webserver'
* Debug mode: on
WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead.
* Running on all addresses (0.0.0.0)
* Running on https://127.0.0.1:8050
* Running on https://10.1.199.193:8050构建成功后,您将看到表示音频混合器线程、Web服务器和LLM服务正在运行的消息。
打开Web浏览器并导航到https://127.0.0.1:8050以访问text-generation-webui应用程序。

音频输入提示将由Llamaspeak处理,并在我们的Windows PC上的Unreal Engine项目中使用以驱动动画过程。Windows上的Unreal Engine根据处理后的音频和文本从管道接收动画数据。
在Windows PC上的Unreal Engine选项卡中,点击“播放”按钮来启动动画过程。
观看Avatar的实际操作演示!在下面的演示中,您将看到用户与Unreal Engine中的MetaHuman角色进行互动。
如您在演示中所见,这些MetaHumans不仅在视觉上令人惊叹,它们还可以与用户进行实时交流和互动。上述演示展示了用户使用英伟达Omniverse Audio2Face和英伟达Jetson AGX Orin开发者工具包,在Unreal Engine中与MetaHuman角色进行互动。想象一下,创建可以与用户进行对话的聊天机器人、教育助手,甚至是游戏中的角色。请根据您的需求自由定制应用程序。
整个代码:GitHub - shahizat/jetson_avatar: AI-Powered Photorealistic Talking Avatar