前端大文件写入MySQL怎么办,我给出了三种方案
原创前端大文件写入MySQL怎么办,我给出了三种方案
原创
前言
在多年的摸鱼工作中,从前台导出大文件的需求遇到过不少,但是将大文件从前台导入后台数据库的需求还真没遇到过,毕竟MySQL服务器权限在手,source执行导入所有,区区十万行、几秒斩于马下。也不用考虑网络延迟、程序效率的问题。
后端接收前端文件,上传和接收的快慢取决于服务器网络带宽,这个属于网络层面问题,我们今天主要是从应用处理层面来提高效率,而在后台程序中想要提高效率,无非就是多线程,但是在哪个环节、如何结合多线程?这就是我们需要考虑的。
前端
上一次写上传文件功能的时候,还是用的原生html的form表单来实现的。这里就是在vue项目中,受用element plus的el-upload组件来完成文件上传的前端开发。
实现代码如下:
<template>
<el-upload
class="upload-demo"
drag
action="http://localhost:8080/cartoon_web/upload"
multiple
>
<Icon name="el-icon-UploadFilled" size="48"></Icon>
<div class="el-upload__text">
Drop file here or <em>click to upload</em>
</div>
<template #tip>
<div class="el-upload__tip">
jpg/png files with a size less than 500kb
</div>
</template>
</el-upload>
</template>后台服务
使用springboot完成文件上传的后台处理逻辑,包括接收文件、读取文件、文件入库等操作,所以如果想要入库快,就要从这几个环节考虑如如多线程处理逻辑。
我们先实现文件上传的controller整体代码框架。
@PostMapping("/upload")
@CrossOrigin(origins = "*", maxAge = 3600)
public @ResponseBody Map<String, String> upload(MultipartFile file) throws IOException {
System.out.println(file.getName());
BufferedReader br = new BufferedReader(new InputStreamReader(file.getInputStream()));
String line = null;
long start = System.currentTimeMillis();
while ((line = br.readLine()) != null) {
// 实现插入逻辑
}
long end = System.currentTimeMillis();
System.out.println("插入数据库共用时间:" + (end -start) / 1000 + "s");
Map<String, String> res = new HashMap();
res.put("1", "success");
return res;
}使用CrossOrigin允许跨域访问,通过MultipartFile获取上传的文件,并获取文件的字节流。循环readLine,在while中实现不同的插入数据库方式,以此来测试效率。
因为MySQL使用的1c的vps,测试时使用的手机热点(很卡),。所以下面测试结果仅供参考,并非生产数据,毕竟,谁家生产用1c的服务器。。
根据自己寥寥的开发经验,一共列举了三种方案,方案一使用了1w条测试数据(节约时间),方案三使用了10w条测试数据。
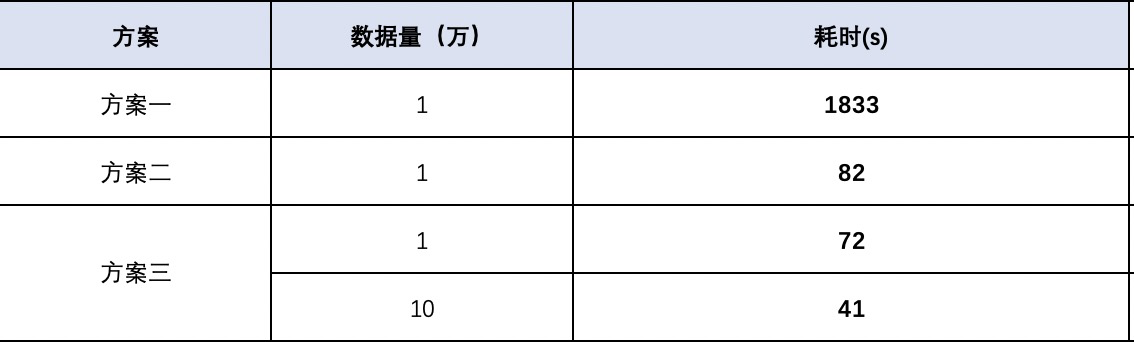
方案一
方案一就是常规的流程,每读取一行数据就插入到数据库中。
@Insert("insert into test values(#{a}, #{b}, #{c}, #{d})")
void insertFile(Test test);插入数据库共用时间:1833s
方案二
可以看出,逐条插入的话每次都要和数据库通信,非常消耗时间,在方案一的基础上我们可以考虑批量插入来提高效率,使用script来实现数据的批量插入。
@Insert("<script>" +
"insert into test values" +
"<foreach collection='list' item='test' separator=','>" +
"(#{test.a}, #{test.b}, #{test.c}, #{test.d})" +
"</foreach>" +
"</script>")
void insertBatch(List<Test> list);可以看到,这里batch插入的参数已经变成了List,通过foreach遍历实现批量插入,我们就在controller中将数据封装在List中。
List<Test> list = new ArrayList();
while ((line = br.readLine()) != null) {
String[] lines = line.split(",");
Test test = new Test(lines[0], lines[1], lines[2], lines[3]);
list.add(test);
count ++;
if (count % 100 == 0) {
fileUploadService.insertBatch(list);
list.clear();
}
}定义了一个count来计数,通过取余实现每批次插入100条。最后结果:插入数据库共用时间:82s
方案三
方案二在插入数据库的环节实现了批量处理,在方案二的基础上,我们在controller中使用多线程来将数据批量插入数据库。
多线程情况下,我们首先要考虑的是锁和并发的问题。如果加锁的话,并发性就降低了很多,所以这里就使用生产者/消费者模式,读取文件作为生产,多线程进行消费。
在这里我有两种技术选型,一个是并发队列ConcurrentLinkedQueue,一个是disruptor。这两种队列内部都是基于CAS + voilatile实现的。在性能上disruptor是略微优于ConcurrentLinkedQueue的,但是disruptor代码量要多一些,所以这里就用ConcurrentLinkedQueue为例。
ConcurrentLinkedQueue<String> queue = new ConcurrentLinkedQueue();
boolean[] isComplete = {true};
int[] count = {0};
CountDownLatch countDownLatch = new CountDownLatch(6);
AtomicInteger atomicSize = new AtomicInteger(0);
while ((line = br.readLine()) != null) {
queue.add(line);
count[0] = ++count[0];
if (count[0] == 500) {
for (int i = 0; i < 6; i++) {
new Thread(new Runnable() {
@Override
public void run() {
int num = 0;
List<Test> list = new ArrayList();
while (isComplete[0] == true && count[0] != atomicSize.get()) {
String line = queue.poll();
if (line != null) {
String[] lines = line.split(",");
Test test = new Test(lines[0], lines[1], lines[2], lines[3]);
atomicSize.incrementAndGet();
list.add(test);
num++;
}
if (num % 100 == 0) {
fileUploadService.insertBatch(list);
list.clear();
}
}
countDownLatch.countDown();
}
}).start();
}
}
}
isComplete[0] = true;
countDownLatch.await();因为是测试,在controller中使用的是原始的Thread构建方式,生产的话可以重构为线程池,而且可以修改一些默认配置。
这个方案需要考虑的因素有很多:
1. 如何确定文件读完了,线程何时终止while循环?
这里使用了两个变量来控制,一个是AtomicInteger原子变量,用来统计多个线程之间消费了多少条数据,与文件里的数据量count保持一致。除此之外,还定义了Boolean类型的isComplete,用来确定用来比较的count,是文件读取完之后的count,而不是因为消费速度 > 生产速度导致与AtomicInteger相等的count中间值。
同时,为了解决匿名内部类访问外部变量问题,这里的变量我都定义成了数组类型。
2. 如何正确统计使用的时间
主线程读取完文件放入queue之后,启动子线程开始消费数据,子线程是否消费完成主线程不管,就接着执行后面的代码。也就是说,子线程还未完成入库,时间已经统计出来了。
为了避免这种情况,使用CountDownLatch让主线程在等待子线程结束之后,在执行后面的代码。
3个线程测试结果:插入数据库共用时间:72s。修改为6个线程,测试结果:插入数据库共用时间:60s
然后我插入了10w条数据,数据库共用时间:41s,可能是手机热点不卡了,也可能是遇强则强。
问题总结
没怎么用springboot写过文件上传,在进行文件上传测试的时候,抛出异常提示“the request was rejected because its size (18889091) exceeds the configured maximum (10485760)”。
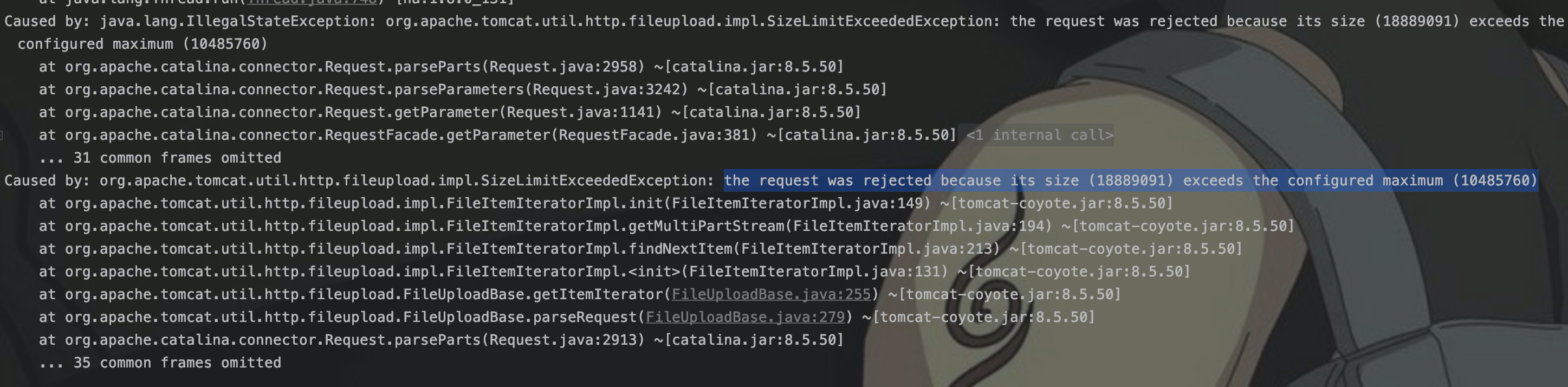
异常提示文件上传的请求,因为超出大小限制而被拒绝,在application.properties中修改默认限制即可。
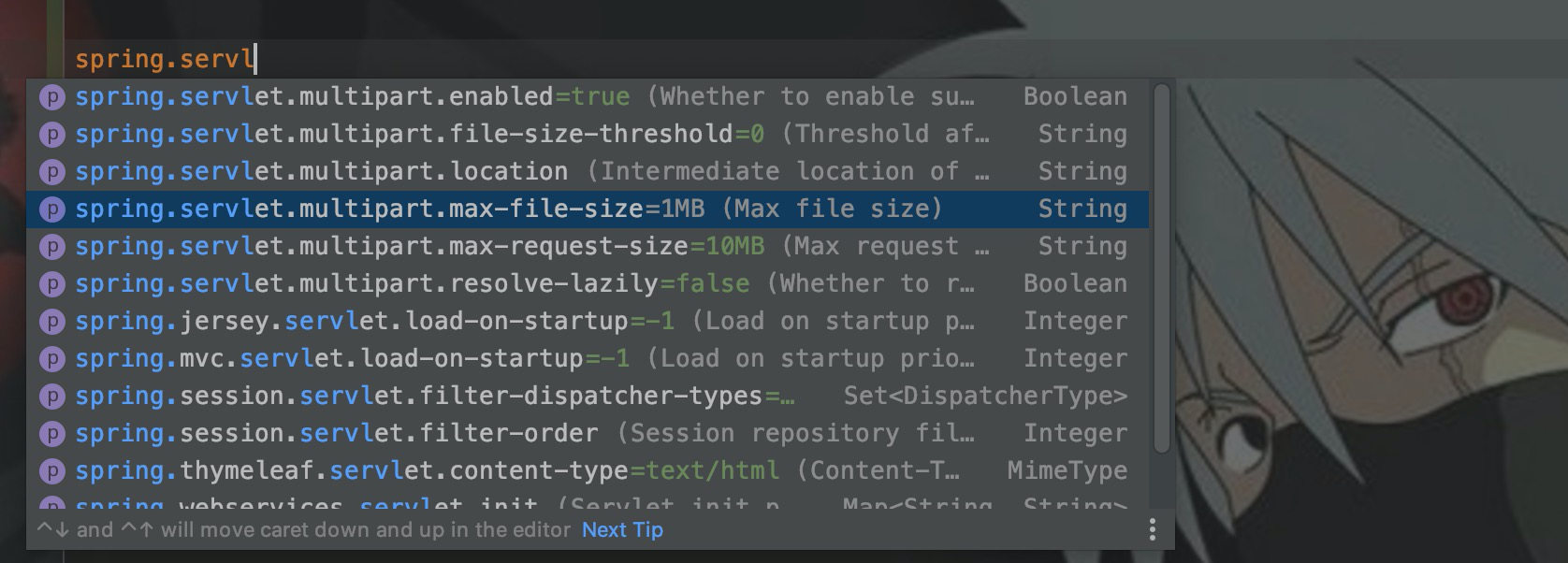
spring.servlet.multipart.max-file-size 用于设置单个文件上传的最大文件大小限制,spring.servlet.multipart.max-request-size 用于设置整个请求(包括所有文件和表单数据)的最大大小限制。
结语
本篇文章通过数据库批量插入和线程池的方式,与逐条插入数据库的方式做了一个对比,从结果看是提升了效率。因为我本身也是做大数据行业的,平时处理的数据量都是挺大的,对于大数据量的导入导出,还是建议使用后台命令行处理。
例如将10w+数据导入MySQL,可以使用LOAD DATA INFILE命令,直接将文件内容导入到表中,效率非常高。想要在Java中实现这种方案,可以在controller中与shell结合,复杂度稍微有点高,有兴趣的可以尝试。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。