上交大提出 ZO-DARTS | 提高图像分类效率,性能SOTA的同时,搜索时间减少3倍!
上交大提出 ZO-DARTS | 提高图像分类效率,性能SOTA的同时,搜索时间减少3倍!


医学图像的准确分类对于现代诊断至关重要。深度学习的进步导致临床医生越来越多地使用复杂的模型来做出更快、更准确的决策,有时甚至取代了人类的判断。然而,模型开发成本高昂且重复性强。神经架构搜索 (NAS) 通过自动化深度学习架构设计来提供解决方案。 本文介绍了ZO-DARTS+,这是一种可微分的NAS算法,通过一种通过双级优化生成稀疏概率的新方法提高搜索效率。 对五个公共医学数据集的实验表明,ZO-DARTS+ 与最先进解决方案的准确性相匹配,同时将搜索时间缩短了多达 3 倍。
1 Introduction
随着深度学习模型的进步,它们在医学图像处理中的应用在当代诊断不可知过程中变得至关重要。事实上,这项技术使专家能够比以前更早、更准确地检测疾病。尽管这场革命跨越了多种数据类型和任务,但操作模型的设计仍然成本高昂。
虽然图像处理模型已经很成熟,但要实现最佳性能需要仔细选择适当的结构和操作。此外,医学图像的显著异质性和可变质量要求对这些模型进行特定领域的调整,这需要在神经网络设计方面付出大量的人力和专业知识。为了减轻人类重复性和要求苛刻的任务的负担,神经架构搜索(NAS)范式已被提出,如今被认为是模型设计过程自动化的灵丹妙药[1]。
由于这种方法在医学诊断领域相对较新,因此在医学图像处理中具有相当大的应用潜力,特别是在分类任务中。此外,鉴于初始NAS技术的复杂性,目前正在开发有关高效搜索策略和硬件感知技术的新趋势,以提高深度学习解决方案的性能和可访问性。
这种新算法通过结合稀疏最大值和适当的退火策略来扩展ZO-DARTS。这些增强功能允许算法在搜索过程中生成具有稀疏值的操作概率,从而提高可解释性。此外,ZO-DARTS+ 的收敛速度比其前身更快,在不牺牲和经常提高最终建筑结构的准确性的情况下,将平均搜索时间缩短了 17.2%。与其他最先进的解决方案相比,ZO-DARTS+达到了相当的准确度,同时将搜索时间缩短了三倍。
2 Background
基于单元的方法在NAS中很普遍,因为它可以将搜索空间从模型级缩小到单元级。在每个单元内,每第
和
数据块之间的操作使用一个共享的候选集
。DARTS引入了架构参数
,这些参数是连续的,并形成操作的加权和[7]。每个
作为操作集
的权重向量,并且必须被优化。混合操作由
定义,通过softmax函数进行归一化。这引入了一个双层优化问题,其中
是上层变量,模型参数
是下层变量:
这里,
和
分别是验证集和训练集上的损失函数。最终的离散架构是通过在
上应用argmax得到的。
为了准确求解方程(1),使用隐函数定理[8]推导
的解析梯度:
其中
由于计算方程(3)中的Hessian是不切实际的,Xie等人引入了ZO-DARTS[5]来绕过这个障碍。ZO-DARTS采用零阶近似技术[9]:
当
时,这近似于方向导数
。结合方程(2)和方程(4),作者有:
因此,可以使用这种方法有效地近似并快速计算
。
3 The proposed method
ZO-DARTS+ 是一个先进的神经结构搜索(NAS)算法,它通过将新颖的概率归一化函数与退火策略相结合,提高了效率。传统上,DARTS中使用softmax从一组架构变量生成概率参数,然后用于计算操作的加权和。然而,这种方法在处理双层NAS问题的复杂性时存在困难,因为softmax倾向于产生在不同操作之间不够发散且过于相似的概览。这种相似性对于选择离散操作是不利的,离散操作中更偏好稀疏概率分布。为了克服这些限制,ZO-DARTS+采用了sparsemax函数[6],它将输入向量
投影到概率单纯形上,以产生更稀疏的概率分布:
-维单纯形,
,确保概率之和等于一且每个概率为非负,这增加了获得稀疏结果的可能性。这种概率的稀疏分布在混合操作中如下使用:
Sparsemax旨在将架构参数推向极端(对于选择的操作接近1,对于其他操作接近0),但它并不总是完全消除非零元素。为了改进这一点,使用温度参数
来调节输入值,从而增加稀疏性:
随着
,这种方法与argmax函数非常相似,适合实现离散选择。为了进一步强化这一特性,作者提出了一个退火策略,每
个周期按手动选择的因子
减小
,引导系统向一个热向量发展。
其中
是总迭代次数,// 表示整数除法。通过调整因子
和
,算法有效地加速搜索过程同时促进稀疏性,紧密符合快速和自动模型生成的需求。
4 Experiments and Results
为了证明作者方法的有效性和效率,作者在来自MedMNIST [10]的五个医学图像数据集上进行了实验,这些数据集分别是PneumoniaMNIST、OCTMNIST、BreastMNIST、OrganAMNIST和OrganSMNIST。在作者的神经架构搜索(NAS)框架中,ZO-DARTS和ZO-DARTS+只在模型参数
发生变化时更新架构参数
,这种情况每
轮发生一次。
在搜索的早期阶段,使用初始温度
来鼓励探索。退火因子设置为
,间隔为
,以逐步精化模型配置。为了进行基准测试,作者使用ResNet18作为手动设计模型的标准,并将AutoKeras和Google AutoML Vision作为NAS模型的 Baseline 。
此外,作者还评估了三种DARTS风格的方法——DARTS [7]、MileNAS [11]和ZO-DARTS [5]——这些方法都在由NAS-Bench-201 [12]定义的搜索空间内操作,包含五种操作:Zeroise、Skip Connect、1x1 Conv、3x3 Conv和3x3 Avg Pooling。作者对每种方法进行了50轮搜索。每次搜索后,通过重新训练至完全收敛来确定最终模型的准确度。作者进行了三次实验以获得性能的平均值和标准差,以及平均搜索时间。
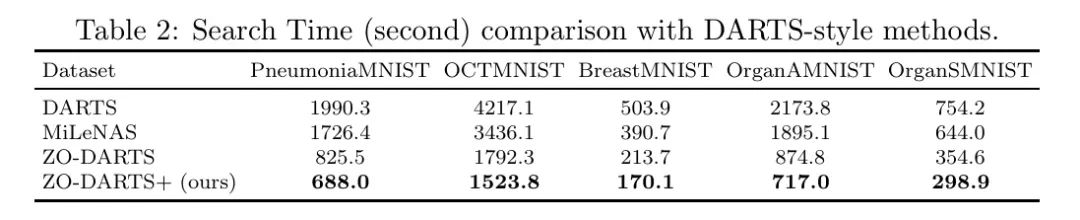
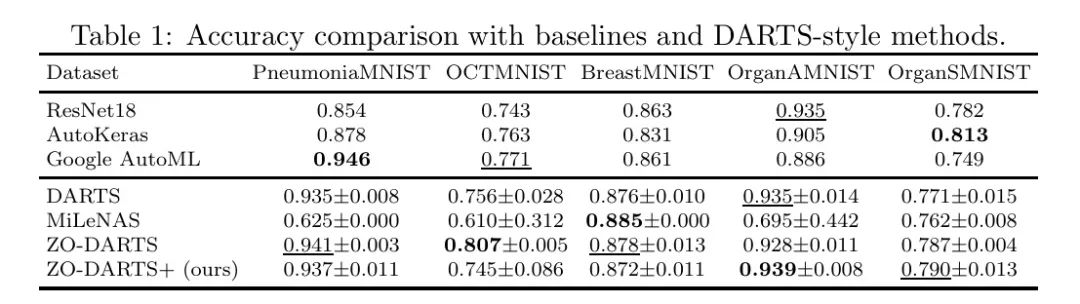
表1显示了每种算法在不同数据集上达到的最佳性能, Baseline 数据直接取自MedMNIST主页1。ZO-DARTS+在五个数据集上超过了ResNet-18,在三个数据集上超过了Google AutoML和AutoKeras。它还在DARTS风格的方法中一致排名第一/第二或接近最佳,展示了全面的稳健性能。尽管ZO-DARTS+与其他DARTS风格方法之间的准确度差距很小,但搜索时间显著减少。令人惊讶的是,ZO-DARTS+往往在搜索的第
个时期通过早停来收敛并停止搜索,进一步减少了搜索时间。如表2详细所示,这种效率凸显了ZO-DARTS+适用于医学图像分类模型的开发,平衡了最先进的准确度,同时将搜索时间最多减少三倍。作者分析了不同NAS方法中架构算子参数的进展情况,并在图1中绘制了这些进展。所有模型都从相同的初始概率权重开始优化。在整个搜索过程中,大多数NAS方法在这些权重上的变化有限,
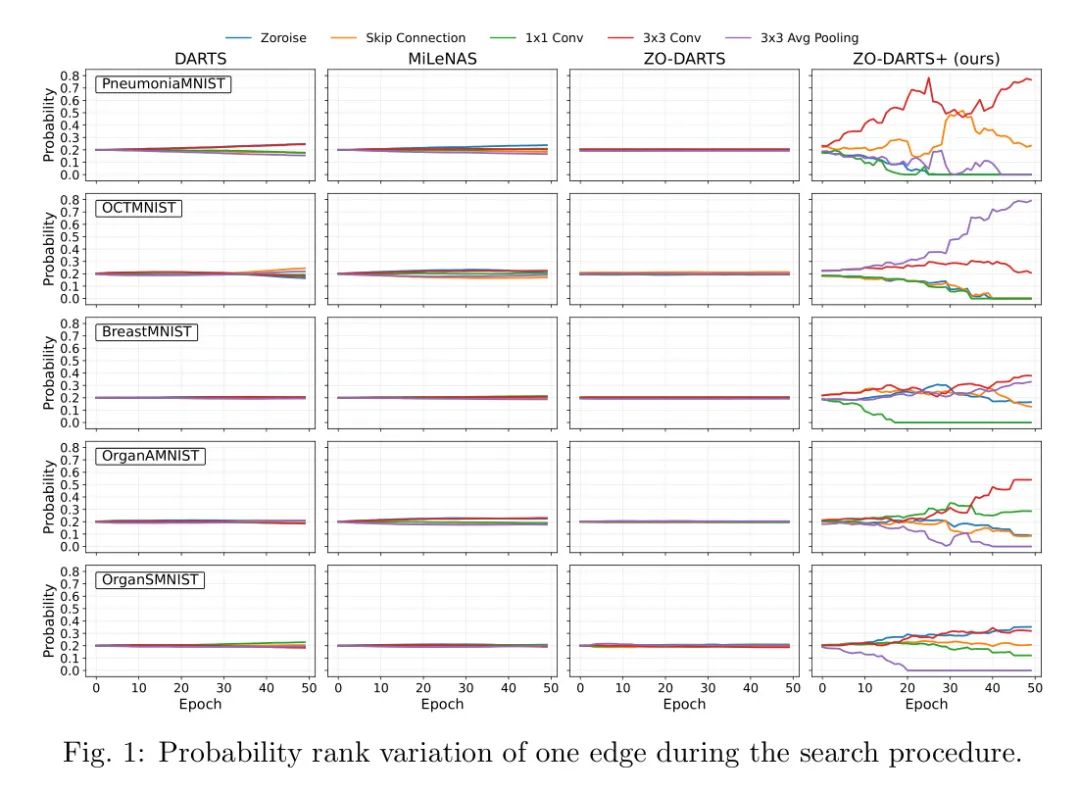
通过在算子选择期间引入退火策略和定制化退火策略,导致了更稀疏和更有效的解决方案。未来的研究将在此基础上,通过应用严格的限制条件来进一步减少计算资源和时间。此外,将在不同的NAS框架中探索应用稀疏感知退火策略,以验证该方法在不同设置中的有效性。
5 Conclusion and Discussion
本文介绍了 ZO-DARTS+,这是一种新颖的可微分 NAS 算法,与现有的领先 meth ods 相比,搜索时间提高了 3 倍,同时保持了医学图像数据集的准确性。
这些结果验证了我们的假设,并通过在算子选择过程中集成稀疏最大函数和定制的退火策略来实现,从而产生更稀疏和更高效的解决方案。
未来的研究将在此基础上,通过应用严格的约束来进一步减少计算资源和时间。此外,还将探索稀疏感知退火阶梯在不同NAS框架中的应用,以验证该方法在不同环境中的有效性。
参考
[1].A Lightweight Neural Architecture Search Model for Medical Image Classification.