华为进二面了,开冲了!

大家好,我是小林。
华为面试流程总共是 3 轮技术面+1 轮 hr 面,在约面之前,还得先进行机试,基本都是算法题,达到150分就算机试通过,然后就进行后面的技术面试。
华为的面试难度相比互联网公司会简单一点,不会问太深的技术原理,问的题目也不会很多,大概都是 10 -20 个问题,相比互联网大厂一场面试动不动就问 30 个问题,确实压力相对小一点。
今天给大家分享一位同学华为二面的面经,面试者的技术栈是Java,主要问了Spring、Java集合、并发、网络、mysql 方面的问题,并且还有手撕算法的过程。
八股
Spring中的事务的隔离级别有哪些?
Sping 中的事务隔离级别有 5 种,它们分别是:
- DEFAULT:Spring 中默认的事务隔离级别,以连接的数据库的事务隔离级别为准;
- READ_UNCOMMITTED:读未提交,也叫未提交读,该隔离级别的事务可以看到其他事务中未提交的数据。该隔离级别因为可以读取到其他事务中未提交的数据,而未提交的数据可能会发生回滚,因此我们把该级别读取到的数据称之为脏数据,把这个问题称之为脏读;
- READ_COMMITTED:读已提交,也叫提交读,该隔离级别的事务能读取到已经提交事务的数据,因此它不会有脏读问题。但由于在事务的执行中可以读取到其他事务提交的结果,所以在不同时间的相同 SQL 查询中,可能会得到不同的结果,这种现象叫做不可重复读;
- REPEATABLE_READ:可重复读,它能确保同一事务多次查询的结果一致。但也会有新的问题,比如此级别的事务正在执行时,另一个事务成功的插入了某条数据,但因为它每次查询的结果都是一样的,所以会导致查询不到这条数据,自己重复插入时又失败(因为唯一约束的原因)。明明在事务中查询不到这条信息,但自己就是插入不进去,这就叫幻读 (Phantom Read);
- SERIALIZABLE:串行化,最高的事务隔离级别,它会强制事务排序,使之不会发生冲突,从而解决了脏读、不可重复读和幻读问题,但因为执行效率低,所以真正使用的场景并不多。
所以,相比于 MySQL 的事务隔离级别,Spring 中多了一种 DEFAULT 的事务隔离级别。针对不同的隔离级别,并发事务时可能发生的现象也会不同。
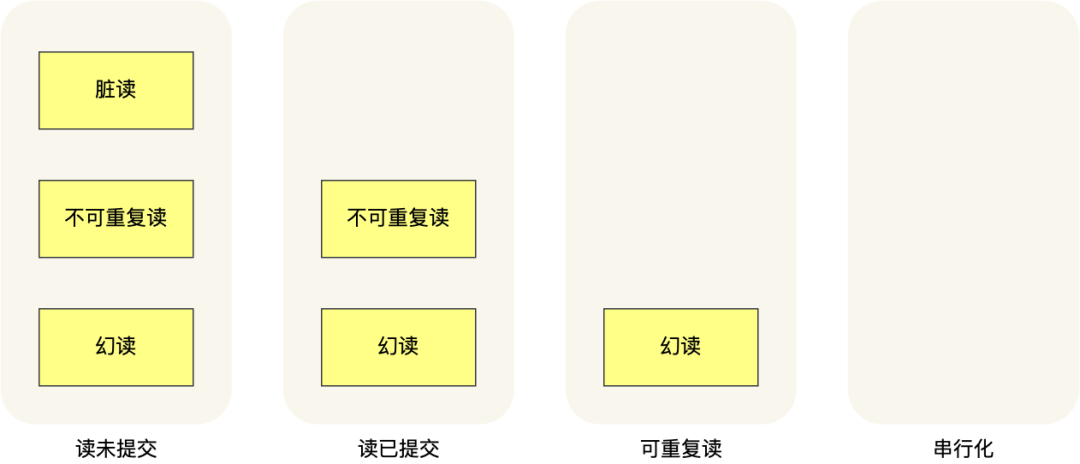
也就是说:
- 在「读未提交」隔离级别下,可能发生脏读、不可重复读和幻读现象;
- 在「读提交」隔离级别下,可能发生不可重复读和幻读现象,但是不可能发生脏读现象;
- 在「可重复读」隔离级别下,可能发生幻读现象,但是不可能脏读和不可重复读现象;
- 在「串行化」隔离级别下,脏读、不可重复读和幻读现象都不可能会发生。
Spring事务的传播行为有哪些?
在Spring中对于事务的传播行为定义了七种类型分别是:REQUIRED、SUPPORTS、MANDATORY、REQUIRES_NEW、NOT_SUPPORTED、NEVER、NESTED。
支持当前事务的:REQUIRED、SUPPORTS、MANDATORY;不支持当前事务的:REQUIRES_NEW、NOT_SUPPORTED、NEVER,以及嵌套事务 NESTED,其中 REQUIRED 是默认的事务传播级别。
事务传播行为类型 | 说明 |
|---|---|
PROPAGATION_REQUIRED | 如果当前没有事务,就新建一个事务,如果已经存在一个事务中,加入到这个事务中。这是最常见的选择。 |
PROPAGATION_SUPPORTS | 支持当前事务,如果当前没有事务,就以非事务方式执行。 |
PROPAGATION_MANDATORY | 使用当前的事务,如果当前没有事务,就抛出异常。 |
PROPAGATION_REQUIRES_NEW | 新建事务,如果当前存在事务,把当前事务挂起。 |
PROPAGATION_NOT_SUPPORTED | 以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。 |
PROPAGATION_NEVER | 以非事务方式执行,如果当前存在事务,则抛出异常。 |
PROPAGATION_NESTED | 如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则执行与PROPAGATION_REQUIRED类似的操作。 |
多态解决了什么问题?
多态是指子类可以替换父类,在实际的代码运行过程中,调用子类的方法实现。多态这种特性也需要编程语言提供特殊的语法机制来实现,比如继承、接口类。
多态可以提高代码的扩展性和复用性,是很多设计模式、设计原则、编程技巧的代码实现基础。比如策略模式、基于接口而非实现编程、依赖倒置原则、里式替换原则、利用多态去掉冗长的 if-else 语句等等
HashMap是线程安全的吗?
hashmap不是线程安全的,hashmap在多线程会存在下面的问题:
- JDK 1.7 HashMap 采用数组 + 链表的数据结构,多线程背景下,在数组扩容的时候,存在 Entry 链死循环和数据丢失问题。
- JDK 1.8 HashMap 采用数组 + 链表 + 红黑二叉树的数据结构,优化了 1.7 中数组扩容的方案,解决了 Entry 链死循环和数据丢失问题。但是多线程背景下,put 方法存在数据覆盖的问题。
如果要保证线程安全,可以通过这些方法来保证:
- 多线程环境可以使用Collections.synchronizedMap同步加锁的方式,还可以使用HashTable,但是同步的方式显然性能不达标,而ConurrentHashMap更适合高并发场景使用。
- ConcurrentHashmap在JDK1.7和1.8的版本改动比较大,1.7使用Segment+HashEntry分段锁的方式实现,1.8则抛弃了Segment,改为使用CAS+synchronized+Node实现,同样也加入了红黑树,避免链表过长导致性能的问题。
Java中的线程安全的集合是什么?
在 java.util 包中的线程安全的类主要 2 个,其他都是非线程安全的。
- Vector:线程安全的动态数组,其内部方法基本都经过synchronized修饰,如果不需要线程安全,并不建议选择,毕竟同步是有额外开销的。Vector 内部是使用对象数组来保存数据,可以根据需要自动的增加容量,当数组已满时,会创建新的数组,并拷贝原有数组数据。
- Hashtable:线程安全的哈希表,HashTable 的加锁方法是给每个方法加上 synchronized 关键字,这样锁住的是整个 Table 对象,不支持 null 键和值,由于同步导致的性能开销,所以已经很少被推荐使用,如果要保证线程安全的哈希表,可以用ConcurrentHashMap。
java.util.concurrent 包提供的都是线程安全的集合:
- 并发Map:
- ConcurrentHashMap:它与 HashTable 的主要区别是二者加锁粒度的不同,在JDK1.7,ConcurrentHashMap加的是分段锁,也就是Segment锁,每个Segment 含有整个 table 的一部分,这样不同分段之间的并发操作就互不影响。在JDK 1.8 ,它取消了Segment字段,直接在table元素上加锁,实现对每一行进行加锁,进一步减小了并发冲突的概率。对于put操作,如果Key对应的数组元素为null,则通过CAS操作(Compare and Swap)将其设置为当前值。如果Key对应的数组元素(也即链表表头或者树的根元素)不为null,则对该元素使用 synchronized 关键字申请锁,然后进行操作。如果该 put 操作使得当前链表长度超过一定阈值,则将该链表转换为红黑树,从而提高寻址效率。
- ConcurrentSkipListMap:实现了一个基于SkipList(跳表)算法的可排序的并发集合,SkipList是一种可以在对数预期时间内完成搜索、插入、删除等操作的数据结构,通过维护多个指向其他元素的“跳跃”链接来实现高效查找。
- 并发Set:
- ConcurrentSkipListSet:是线程安全的有序的集合。底层是使用ConcurrentSkipListMap实现。
- CopyOnWriteArraySet:是线程安全的Set实现,它是线程安全的无序的集合,可以将它理解成线程安全的HashSet。有意思的是,CopyOnWriteArraySet和HashSet虽然都继承于共同的父类AbstractSet;但是,HashSet是通过“散列表”实现的,而CopyOnWriteArraySet则是通过“动态数组(CopyOnWriteArrayList)”实现的,并不是散列表。
- 并发List:
- CopyOnWriteArrayList:它是 ArrayList 的线程安全的变体,其中所有写操作(add,set等)都通过对底层数组进行全新复制来实现,允许存储 null 元素。即当对象进行写操作时,使用了Lock锁做同步处理,内部拷贝了原数组,并在新数组上进行添加操作,最后将新数组替换掉旧数组;若进行的读操作,则直接返回结果,操作过程中不需要进行同步。
- 并发 Queue:
- ConcurrentLinkedQueue:是一个适用于高并发场景下的队列,它通过无锁的方式(CAS),实现了高并发状态下的高性能。通常,ConcurrentLinkedQueue 的性能要好于 BlockingQueue 。
- BlockingQueue:与 ConcurrentLinkedQueue 的使用场景不同,BlockingQueue 的主要功能并不是在于提升高并发时的队列性能,而在于简化多线程间的数据共享。BlockingQueue 提供一种读写阻塞等待的机制,即如果消费者速度较快,则 BlockingQueue 则可能被清空,此时消费线程再试图从 BlockingQueue 读取数据时就会被阻塞。反之,如果生产线程较快,则 BlockingQueue 可能会被装满,此时,生产线程再试图向 BlockingQueue 队列装入数据时,便会被阻塞等待。
- 并发 Deque:
- LinkedBlockingDeque:是一个线程安全的双端队列实现。它的内部使用链表结构,每一个节点都维护了一个前驱节点和一个后驱节点。LinkedBlockingDeque 没有进行读写锁的分离,因此同一时间只能有一个线程对其进行操作
- ConcurrentLinkedDeque:ConcurrentLinkedDeque是一种基于链接节点的无限并发链表。可以安全地并发执行插入、删除和访问操作。当许多线程同时访问一个公共集合时,ConcurrentLinkedDeque是一个合适的选择。
ConcurrentHashMap用了悲观锁还是乐观锁?
悲观锁和乐观锁都有用到。
添加元素时首先会判断容器是否为空:
- 如果为空则使用 volatile 加 CAS (乐观锁) 来初始化。
- 如果容器不为空,则根据存储的元素计算该位置是否为空。
- 如果根据存储的元素计算结果为空,则利用 CAS(乐观锁) 设置该节点;
- 如果根据存储的元素计算结果不为空,则使用 synchronized(悲观锁) ,然后,遍历桶中的数据,并替换或新增节点到桶中,最后再判断是否需要转为红黑树,这样就能保证并发访问时的线程安全了。
乐观锁是怎样实现的?
乐观锁假设多个事务之间很少发生冲突,因此在读取数据时不会加锁,而是在更新数据时检查数据的版本(如使用版本号或时间戳),如果版本匹配则执行更新操作,否则认为发生了冲突。
乐观锁适用于读多写少的场景,可以减少锁的竞争,提高并发性能。例如,数据库中的乐观锁机制可以用于处理并发更新同一行数据的情况。
乐观锁实现方式可以通过 CAS 来实现。
CAS叫做CompareAndSwap,比较并交换,主要是通过处理器的指令来保证操作的原子性,它包含三个操作数:
- 变量内存地址,V表示
- 旧的预期值,A表示
- 准备设置的新值,B表示
当执行CAS指令时,只有当V等于A时,才会用B去更新V的值,否则就不会执行更新操作。
Http1.0和2.0的区别是什么?
- 协议版本:Http/1.0 是较早的版本,采用文本格式进行通信,虽然支持长连接,但是默认是使用短连接。从 http/1.1版本开始,默认是用了长连接,Http/2.0 是较新的版本,引入了二进制格式,以及多路复用等新特性。
- 性能:Http/1.0 每次请求只能响应一个资源,多个资源需要多次请求,存在队头阻塞问题。Http/2.0 支持多路复用,可以在单个连接上同时传输多个请求和响应,提高性能。
- 头部压缩:Http/1.0 每次请求和响应都需要携带完整的头部信息,存在较大的开销。Http/2.0 引入了头部压缩机制,减少了重复头部信息的传输,提高了效率。
- 服务器推送:Http/1.0 需要等待客户端请求后才能发送响应,无法主动推送资源。Http/2.0 支持服务器推送,服务器可以在客户端请求之前将相关资源推送给客户端,减少等待时间。
MySQL中的bin log的作用是什么?
binlog 是 MySQL 的 Server 层实现的日志,用于备份恢复、主从复制。
binlog 有 3 种格式类型,分别是 STATEMENT(默认格式)、ROW、 MIXED,区别如下:
- STATEMENT:每一条修改数据的 SQL 都会被记录到 binlog 中(相当于记录了逻辑操作,所以针对这种格式, binlog 可以称为逻辑日志),主从复制中 slave 端再根据 SQL 语句重现。但 STATEMENT 有动态函数的问题,比如你用了 uuid 或者 now 这些函数,你在主库上执行的结果并不是你在从库执行的结果,这种随时在变的函数会导致复制的数据不一致;
- ROW:记录行数据最终被修改成什么样了(这种格式的日志,就不能称为逻辑日志了),不会出现 STATEMENT 下动态函数的问题。但 ROW 的缺点是每行数据的变化结果都会被记录,比如执行批量 update 语句,更新多少行数据就会产生多少条记录,使 binlog 文件过大,而在 STATEMENT 格式下只会记录一个 update 语句而已;
- MIXED:包含了 STATEMENT 和 ROW 模式,它会根据不同的情况自动使用 ROW 模式和 STATEMENT 模式;
算法
- 一个二叉树,给一个target,找出大于这个树中的节点的最大深度