CVPR2024 | YOLO-World 检测一切对象模型
CVPR2024 | YOLO-World 检测一切对象模型

OpenCV学堂
发布于 2024-05-11 10:59:32
发布于 2024-05-11 10:59:32
模型概述
YOLO-World模型引入了先进的实时 UltralyticsYOLOv8对象检测模型,成为了开放词汇检测任务的最新SOTA实时方法。YOLO-World模型可根据提示与描述性文本实现检测图像中的任何物体。YOLO-World 可大幅降低计算要求,同时具有杰出的性能指标,是新一代的开放动词对象检测模型。
模型结构主要由两个部分组成分别是实现文本编码与解码的Clip结构模型与实现图像特征提取支持对象检测YOLOv8系列网络模型。
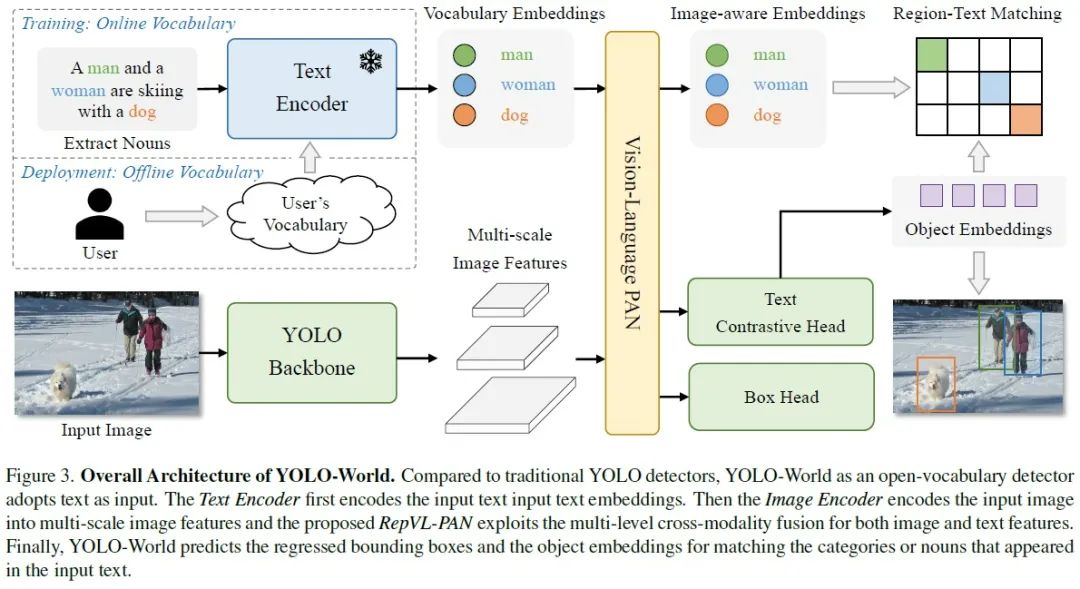
对比传统的深度学习YOLO系列对象检测网络与传统的开发动词对象检测,YOLO-World的优势如下图所示:
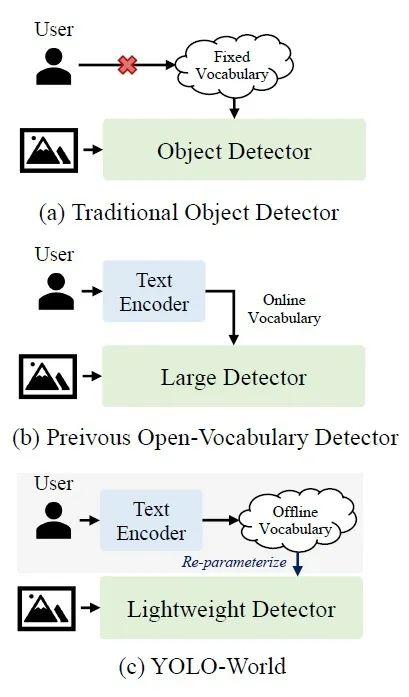
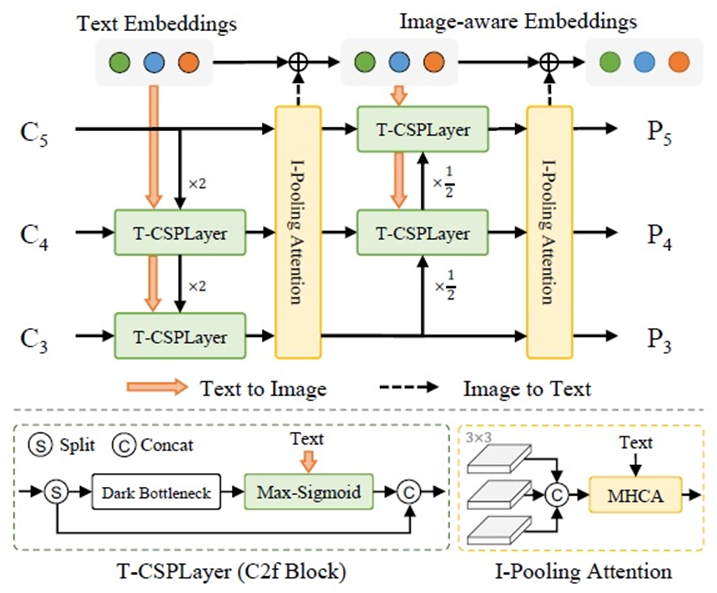
其中可参数化视觉语言PAN模块,作者对之前的VLP结构完成了两点改进分别是文本指南CSP模块与图像池化注意力模块,实现了图像特征与文本嵌入的高度融合。
Text-guided CSPLayer与Image-Pooling Attention 结构如下:
完成实现YOLO-World预训练模型在大规模对象检测、图像文本数据集训练策略方面主要有区域文本对比损失与基于自动标注实现的伪标签策略。
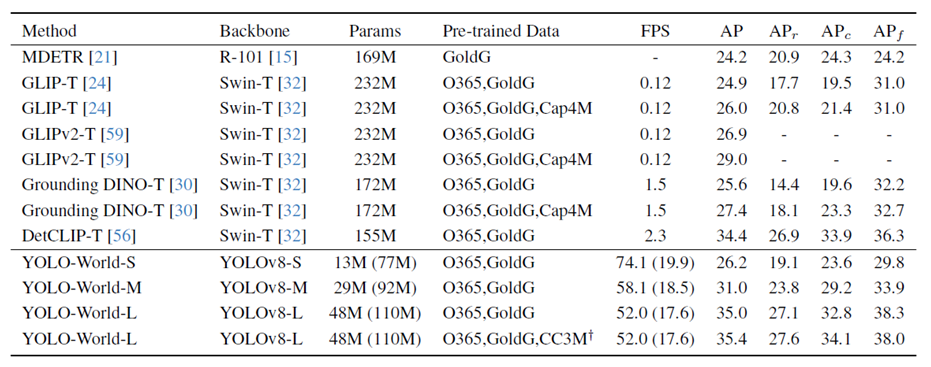
实验对比
对比其它的开放动词对象检测模型,YOLO-World参数更少,速度更快,显示出非常好的检测能力与推理速度。
安装与测试
YOLOv8 + CLIP版本的YOLO-World模型已经发布,而且被ultralytics框架所支持,首先下载yolov8s-worldv2.pt模型,然后直接通过下面的代码即可推理测试:
# Initialize a YOLO-World model
model = YOLO('yolov8s-worldv2.pt') # or choose yolov8m/l-world.pt
# Define custom classes
model.set_classes(["elephant"])
# Execute prediction for specified categories on an image
results = model.predict('D:/bird_test/elephant2.png')
# Show results
results[0].show()运行结果如下 (零样本训练,直接通过文本提示):

本文参与 腾讯云自媒体分享计划,分享自微信公众号。
原始发表:2024-05-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读