大语言模型--流水线并行原理及实现
原创
理论来源
Google 2019年发表的论文GPipe: Easy Scaling with Micro-Batch Pipeline Parallelism,1811.06965 (arxiv.org)
主要内容:
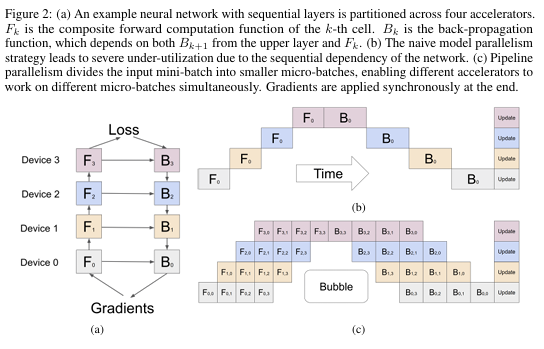
1.将网络分割成K个单元,并将第k个单元放在第k个加速器上,如下图a。在分割的边界,GPipe自动插入了通信原语,允许邻近分割之间的数据传输。
2.把推理或训练的batch划分成更小的micro_batch,micro_batch是流水线执行的基本数据单元
3.如下图b和c,b是直接把batch输入网络推理,使用率较低。c是把大batch分成四个micro_batch,当Device1计算F1,0时,Device0同时开始计算F0,1
微软2018年发表的论文PipeDream: Fast and Efficient Pipeline Parallel DNN Training,1806.03377 (arxiv.org)
主要内容:
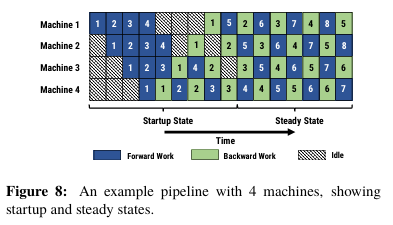
1.再GPipe中只有所有的micro_batch前向计算完,才开始反向,也就是说需要缓存所有micro_batch的前向中间结果。PipeDream提出了1F1B策略,尽量减少缓存activation。实现原理如下图Figure 8
2.再1F1B稳定运行之后,每个GPU上都会有一个micro_batch数据正在处理,获得更高的资源使用率。
3.使用不同版本的权重来确保训练的有效性
最新研究进展
2021年发表的论文Memory-Efficient Pipeline-Parallel DNN Training,2006.09503 (arxiv.org)
提出了PipeDream-2BW和其变体PipeDream-Flush,主要内容:
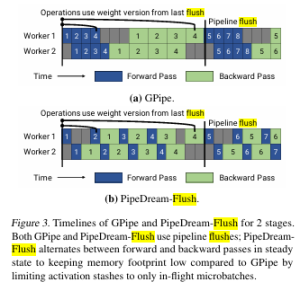
1.在调度上,还是采用和PipeDream一样的1F1B
2.在权重更新的粒度上,采用类似Gpipe的方式,每输入m个microbatch,这m个microbatch使用相同的参数做向前和反向,累积梯度之后更新一次参数。和PipeDream的本质区别也就是梯度更新的频率,PipeDream-2BW每m个microbatch更新一次,而PipeDream每个microbatch都更新一次。PipeDream-2BW这样的好处是只需要保存两个版本的梯度,节省内存。

3.PipeDream-Flush中只维护单个权重版本并引入定期流水线刷新(pipeline flush),以确保权重更新期间的权重版本保持一致,通过这种方式以执行性能为代价降低了峰值内存。
英伟达2021年发表的论文Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM,https://arxiv.org/abs/2104.04473
主要内容:
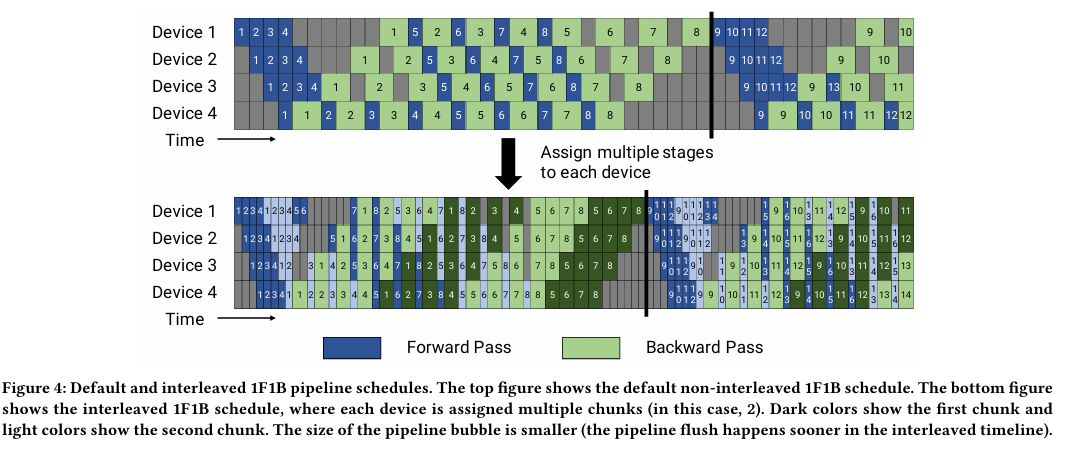
1.基于PipeDream-Flush提出了交错式调度,之前如果每个设备有 4 层(即设备 1 有 1 – 4 层,设备 2 有 5 – 8 层,依此类推),现在我们可以让每个设备对两个模型块执行计算(每个模型块有 2 层) ,即设备 1 有第 1、2、9、10 层;设备 2 有第 3、4、11、12 层,依此类推。通过这种方案,流水线中的每个设备都被分配多个流水线阶段(与以前相比,每个流水线阶段的计算量更少)。
2.对混合并行进行了性能分析,
张量并行和流水线并行:a.张量并行的数量不要超过单个服务器节点内的GPU数量, b.在服务器节点内使用张量并行,在服务器节点间使用流水线并行
数据并行和模型并行:数据并行的扩展效率明显优于模型并行,模型并行适用于模型过大GPU无法放下的情况。数据并行只需要在每一批数据训练完成后,对训练所获得的梯度进行一次all-reduce通信。对于一个环形的all-reduce通信来说,假设设备数量为d,它的通信时间和(d-1)/d成正比,因此数据并行数量的增加不会使得通信时间显著增加。
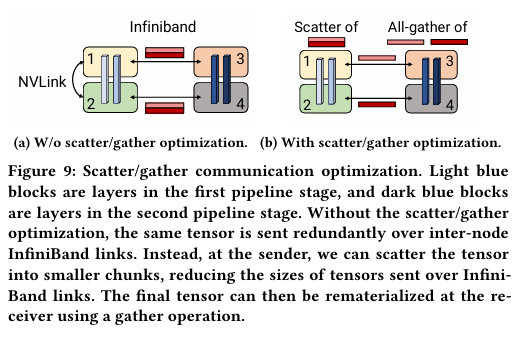
3.张量并行和流水线并行的通信优化
图中(a)是优化前,Device1和2是张量并行,Device1/2和Device3/4之间做流水线并行,分别计算完通过all_gather算子每张卡都有完整的输出,Device1把完整的输出给Device 3,Device 2把完整的输出给Device 4。
图中(b)是优化后,Device1和2分别计算完做一次Scatter,Device1把自己分配到的输出给Device 3,Device 2把自己分配到的输出给Device 4。Device 3/4先做一次all_gather,都拿到完整的数据。使得在流水线并行中每个相邻的设备之间的通信量减少到原来的1/t,t是张量并行的数量。
开源实现
torch.distributed
torch.distributed.pipeline对pipeline并行以及调度策略有较好的实现,且比较通用,可以低成本使用到自定义模型中。具体使用方法参考:给llama实现流水线并行 - 知乎 (zhihu.com)
Megatron-LM
Nvidia开源的模型并行训练框架,基于pytorch,支持Bert、GPT3、T5、VIT等模型的预训练。对pipeline并行以及调度有自己的实现,但并行实现不能快速适配到自定义模型中。
accelerate
huggingface开源的将Pytorch模型迁移到GPU / multi-GPUs / TPU上训练的工具,降低并行使用门槛,无需侵入式修改模型实现。并且支持DeepSpeed(还在测试中),目前transformers模型训练库基于accelerate实现并行。
DeepSpeed
微软开源的模型并行训练/推理框架,自动的结合数据并行、Pipeline并行、张量并行。但只对deepspeed支持的模型使用方便,新模型使用成本较高。
实现步骤
把模型的不同层放到不同的卡里
from accelerate import dispatch_model, infer_auto_device_map from accelerate.utils import get_balanced_memory device_map = 'auto' device_map_kwargs = { 'no_split_module_classes': [ 'DecoderLayer', "LlamaDecoderLayer", "QLlamaDecoderLayer", "PipeDecoderLayer", "PipeQLlamaDecoderLayer" ], 'special_dtypes': {} } max_memory = None max_memory = get_balanced_memory( model, dtype=target_dtype, low_zero=(device_map == "balanced_low_0"), max_memory=max_memory, **device_map_kwargs, ) device_map_kwargs["max_memory"] = max_memory device_map = infer_auto_device_map(model, dtype=target_dtype, **device_map_kwargs) # 整个模型不同的模块放入不同的gpu中 for param_name, param in checkpoint.items(): module_name = param_name while len(module_name) > 0 and module_name not in device_map: module_name = ".".join(module_name.split(".")[:-1]) if module_name in device_map: param_device = torch.device(device_map[module_name]) param = param.to(param_device) model.load_state_dict(checkpoint, strict=False) model.eval() device_map_kwargs = { "device_map": device_map, "offload_dir": None, "offload_index": None, 'skip_keys': 'past_key_values' } dispatch_model(model, **device_map_kwargs) |
|---|
构造Sequentail model和Pipe
可以理解为把模型分块放到一个列表里,以便Pipeline调度
from torch.distributed.pipeline.sync import Pipe seqmodel = torch.nn.Sequential() seqmodel.add_module(name="embedding", module=model.embed_tokens) for index in range(len(model.layers)): seqmodel.add_module(name=f"layer{index}", module=model.layers[index]) seqmodel.add_module(name="norm", module=model.norm) seqmodel.add_module(name="lm_head", module=model.lm_head) pipemodel = Pipe(seqmodel, chunks=chunks) pipemodel.eval() |
|---|
对模型层做适配
因为模型通过pipe调度,所以不会再执行forward函数。后面层需要的数据需要一层层往后传递,并且每层输入输出最好是tuple格式。下图是Decoder Layer示例。

原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。