K8s 多集群思考、实践和探索

为什么需要多集群
- 多活建设:提高业务应用的可用性,避免单个集群或单个数据中心故障导致业务应用暂时不可用。
- 混合云建设:引入公有云弹性资源解决业务大促节假日资源洪峰
- 控制故障爆炸半径
建设多集群的前期准备
- 多集群生命周期管理(新建集群、新增节点等)kube on kube 实现思路分享
- 多集群应用的分发部署
- 多集群监控告警
- 南北流量如何管理
- 东西流量如何管理
- 多集群应用迁移
多集群探索(联邦)
Federation v1
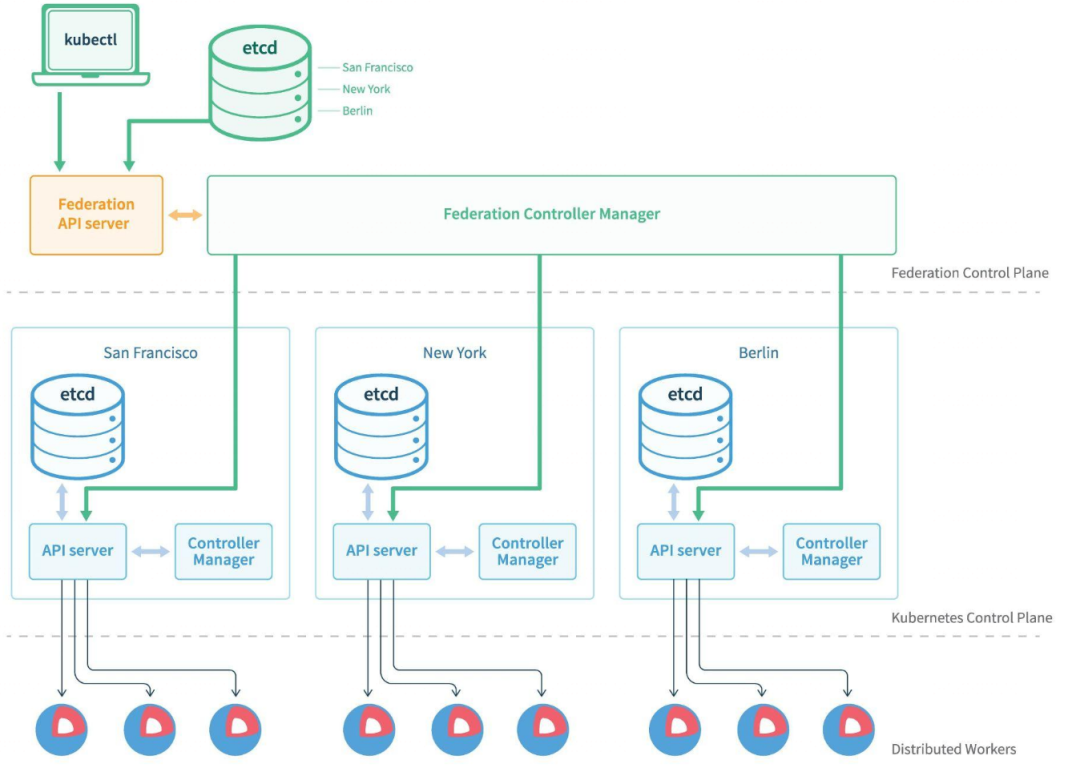
最早的多集群项目,由 K8s 社区提出和维护。
apiVersion: extensions/v1beta1
kind: ReplicaSet
metadata:
name: nginx-us
annotations:
federation.kubernetes.io/replica-set-preferences: |
{
"rebalance": true,
"clusters": {
"us-east1-b": {
"minReplicas": 2,
"maxReplicas": 4,
"weight": 1
},
"us-central1-b": {
"minReplicas": 2,
"maxReplicas": 4,
"weight": 1
}
}
}
把联邦的所有配置信息都写到 annotations 里,整个创建流程与 K8s 类似。配置信息先到 Federated API Server,Federated Controller 把应用创建到各子集群。
由于下面两个突出问题,在 K8s v1.11 左右正式被弃用。
- 基于 Annotation 的资源分发让整个 API 过于臃肿,不够优雅。
- 在 Kubernetes 里一个 API 是通过 Group/Version/Kind 确定的,但是 Federation v1 里面对于K8s 原生 API、GVK 固定,导致对不同版本的集群 API 兼容性很差。
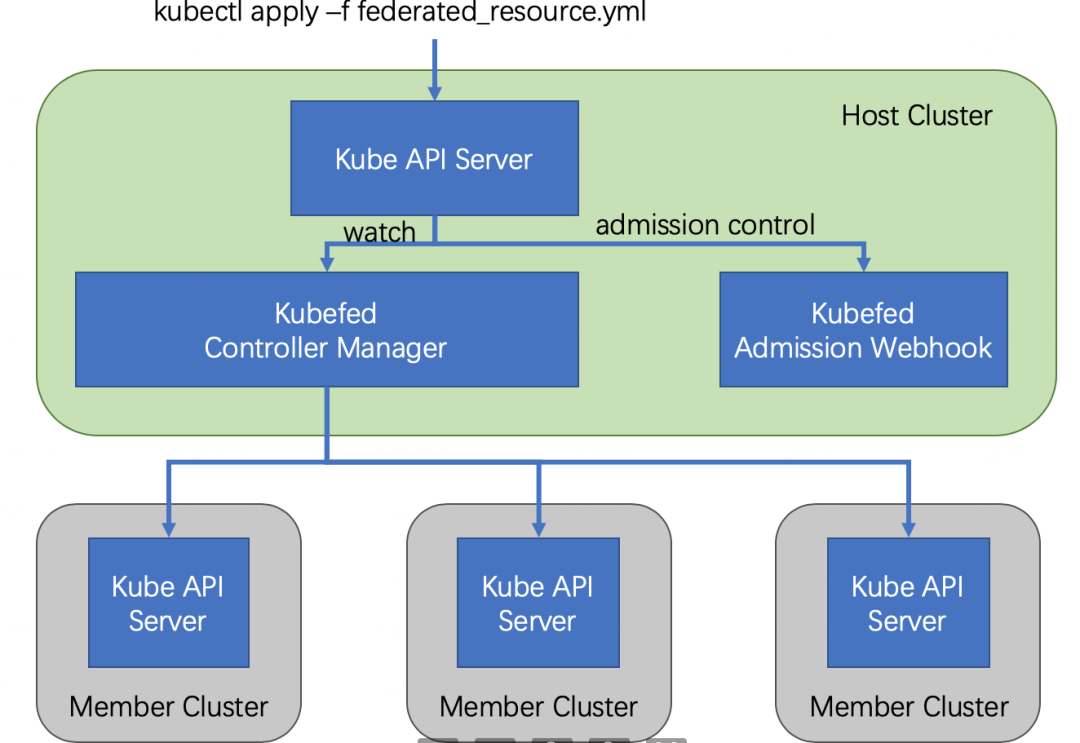
Federation v2
Federation v2 最大的特点就是基于 CRD 和 Controller 的方式替换掉了 Federation v1 基于 Annotation 分发资源的方案,没有侵入原生的 K8s API,也没有引入额外的 API Server。
主要由两个组件构成:
- admission-webhook 提供了准入控制
- controller-manager 处理自定义资源以及协调不同集群间的状态
用户通过kubefedctl enable命令生成指定该资源类型的 FederatedTypeConfig CRD,使用定义好的yaml文件对资源进行联邦部署。
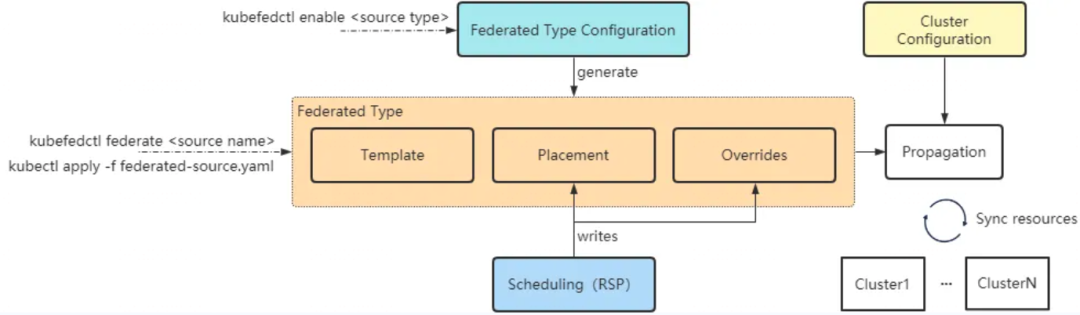
一个典型的 deployment 的 FederatedTypeConfig 示例如下:
apiVersion: types.kubefed.io/v1beta1
kind: FederatedDeployment
metadata:
name: fed-deploy
namespace: fed-ns
spec:
template:
{deployment-define}
overrides:
- clusterName: cluster-1
clusterOverrides:
- path: /spec/replicas
value: 10
- path: /spec/template/spec/containers/0/image
value: nginx:1.17.0-alpine
placement:
clusters:
- name: cluster-1
- name: cluster-2
Federated Type CRD包含三个部分:
Template: 该资源本身的定义,用于集群中该资源的创建
Placement: 分发策略,定义该资源部署于哪些集群中
Overrides:对 template 中的字段进行覆盖重写,用于对资源的配置更新。如示例中对名称为 cluster-1 的 member cluster 中 deployment 的副本数和镜像进行了重新配置。Override 中未选择的集群使用 template 的定义,保持不变。
可以发现,上面配置文件只指定了 分发到哪个集群,并没有具体的分配比例、数量等,可以利用RSP(ReplicaSchedulingPreference)对Federated Type CRD中placement和Overrides字段内容进行重写,rs重写数据来源于用户配置的调度文件。
一个典型的RSP文件定义示例如下,该RSP文件定义了一个deployment应用负载在部署时,各集群的部署策略。
apiVersion: scheduling.kubefed.io/v1alpha1
kind: ReplicaSchedulingPreference
metadata:
name: fed-deploy
namespace: fed-ns
spec:
targetKind: FederatedDeployment
totalReplicas: 20
clusters:
"*":
weight: 1
maxReplicas: 15
cluster-1:
weight:
minReplicas: 3
maxReplicas: 10
RSP 文件中主要包含以下字段:
targetKind:定义该RSP文件应用的联邦资源类型,目前仅支持 FederatedDeployment 和 FederatedReplicaSet。
totalReplicas:资源的总副本数,各个集群按照用户配置的权重或者比例进行资源计算时,会先根据总数进行计算得到一个初步结果,若集群中配置了最大值或最小值与计算得到的值冲突,则会使用用户配置的最大值或者最小值。因此实际的总副本数可能会和配置的总副本数不一致。
已经被社区废弃。
Karmada
此项目是在 Kubernetes Federation v1和v2基础之上开发的。某些基本概念从这两个版本继承而来。
Karmada 旨在为多云和混合云场景下的多集群应用程序管理提供即插即用的自动化,具有集中式多云管理、高可用性、故障恢复和流量调度等关键功能。
Karmada 是Cloud Native Computing Foundation(CNCF)的孵化项目。
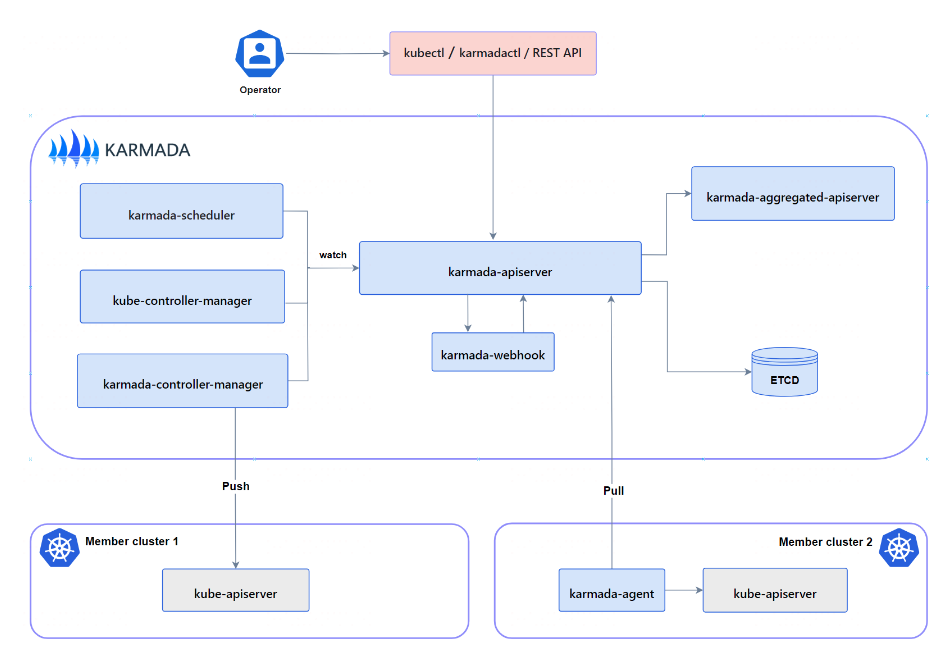
和 Federation v1 类似,我们下发一个资源也是要写入到 Karmada 自己的 API Server 中,之前 controller-manager 根据一些 policy 把资源下发到各个集群中;不过这个 API Server 直接使用 Kubernetes 的 kube-apiserver 实现的,所以支持任何资源,不会出现之前 v1 版本中的问题,然后联邦托管资源的分发策略也是由一个单独的 CRD 来控制的,也不需要配置 v2 中的 Federated Resource CRD 和 Type Configure。
分发应用程序 Demo
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx
labels:
app: nginx
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- image: nginx
name: nginx
---
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
metadata:
name: nginx-propagation
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
placement:
clusterAffinity:
clusterNames:
- member1
- member2
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- member1
weight: 1
- targetCluster:
clusterNames:
- member2
weight: 1
---
apiVersion: policy.karmada.io/v1alpha1
kind: OverridePolicy
metadata:
name: nginx-op
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: nginx
overrideRules:
- targetCluster:
clusterNames:
- member2
overriders:
labelsOverrider:
- operator: add
value:
env: skoala-dev
- operator: add
value:
env-stat: skoala-stage
- operator: remove
value:
for: for
- operator: replace
value:
bar: test
- targetCluster:
clusterNames:
- member1
overriders:
annotationsOverrider:
- operator: add
value:
env: skoala-stage
- operator: remove
value:
bom: bom
- operator: replace
value:
emma: sophia
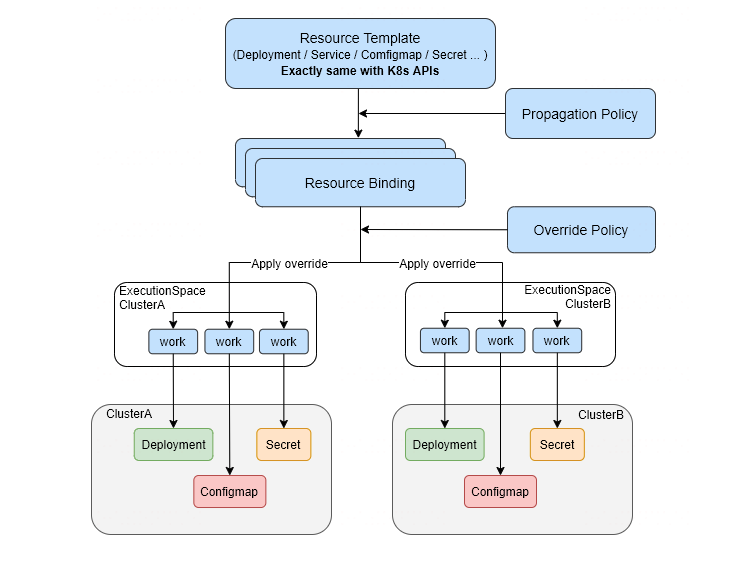
Policy Controller: 监听PropagationPolicy 对象,PropagationPolicy 对象被创建后,Policy Controller会选择一组匹配resourceSelector 的资源,然后为每个单独则资源创建ResourceBinding。
Binding Controller: 监听ResourceBinding 对象,然后创建每个集群对应的work 对象。work 对象里面包含了一个具体的资源。
Execution Controller: 监听work对象,然后在member cluster 里创建对应的资源
其他
以上多集群项目主要功能为资源分发和调度,还有如多云基础设施管理 cluster-api,多集群检索 Clusterpedia,多集群 pod 互通 submariner,multicluster-ingress 解决多集群的 ingress,服务治理和流量调度 Service Mesh,如 istio、cilium 等网络组件实现的 multi cluster mesh 解决跨集群的 mesh 网络管理,以及结合存储相关项目实现跨集群存储管理和迁移等。
多集群落地实践(非联邦)
介绍了半天联邦集群,但~~~~~是,我们落地用的非联邦方式 🤣
应用如何在多个集群部署
当单个集群时, 内部的 自动化运维平台 和 发布系统 已经支持了,单集群的 容器生命周期管理、Ingress 生命周期管理、升降配 & 扩缩容、HPA & HPC、滚动发布 & 灰度发布 等。
在多纳管几个集群,改动很小, 发布系统支持 多集群 容器编排发布即可 (串行 or 并行)等。
多集群监控告警
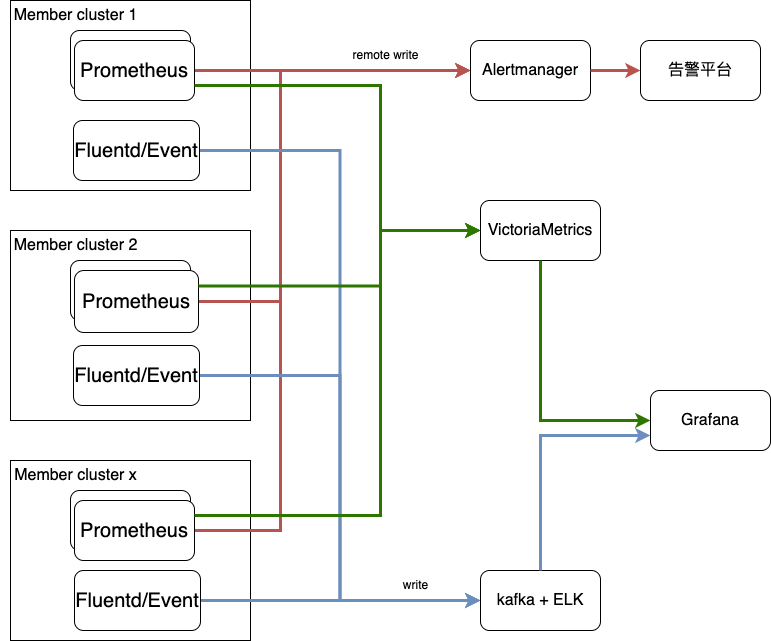
几个注意点:
修改默认 monitoring.coreos.com/v1 Prometheus 对象
# 修改 alertmanagers 为 外置 alertmanager 配置, 提前新建 svc 和 ep
alerting:
alertmanagers:
- apiVersion: v2
name: xxx
namespace: xxx
pathPrefix: /
port: xxx
# 添加集群唯一标识
externalLabels:
cluster: xxx
environment: xxx
zone: xxx
# 远端写入到 VictoriaMetrics, 配置多副本去重
remoteWrite:
- url: http://xxx/api/v1/write
writeRelabelConfigs:
- action: labeldrop
regex: prometheus_replica
南北流量如何管理
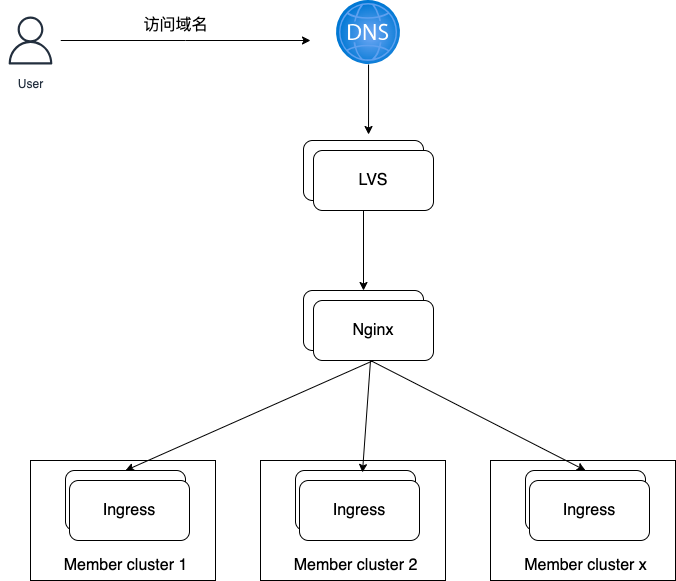
外层 Nginx 反向代理各集群 Ingress Node,Ingress Node 节点的权重会自动调整,当有容器和虚拟机混布时,规则如下,且 Ingress Node 会随 Pod 数量的变化和 Ingress Node 数量的变化自动调整权限,在内存中调整,无需 reload 外层Nginx:
1个 pod = 1个 kvm 基础权重都为10,每个 ingress node 权重 为 (pod 数量 * 10 / ingress 节点数) 取整,最小为1。
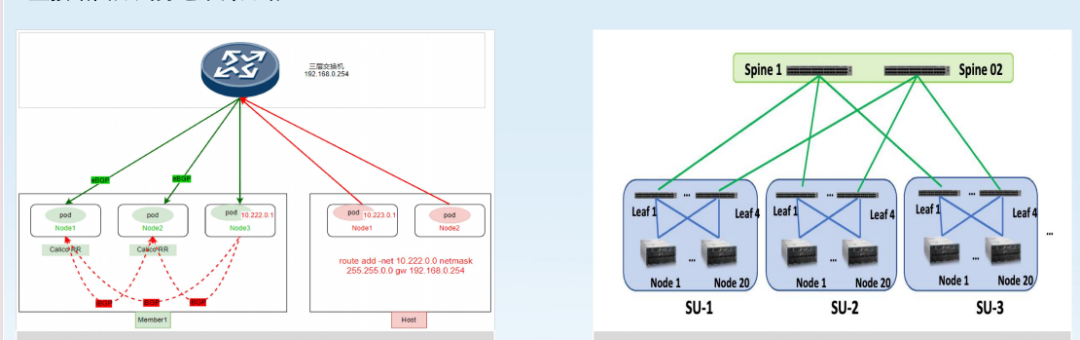
东西流量如何管理
三层网络走 Calico BGP 拉平打通, 多集群 Pod 之间,网络可以直连, 容器和虚拟机之间,也可以直连。
服务发现用的 Nacos,没走 Coredns。
多集群应用迁移
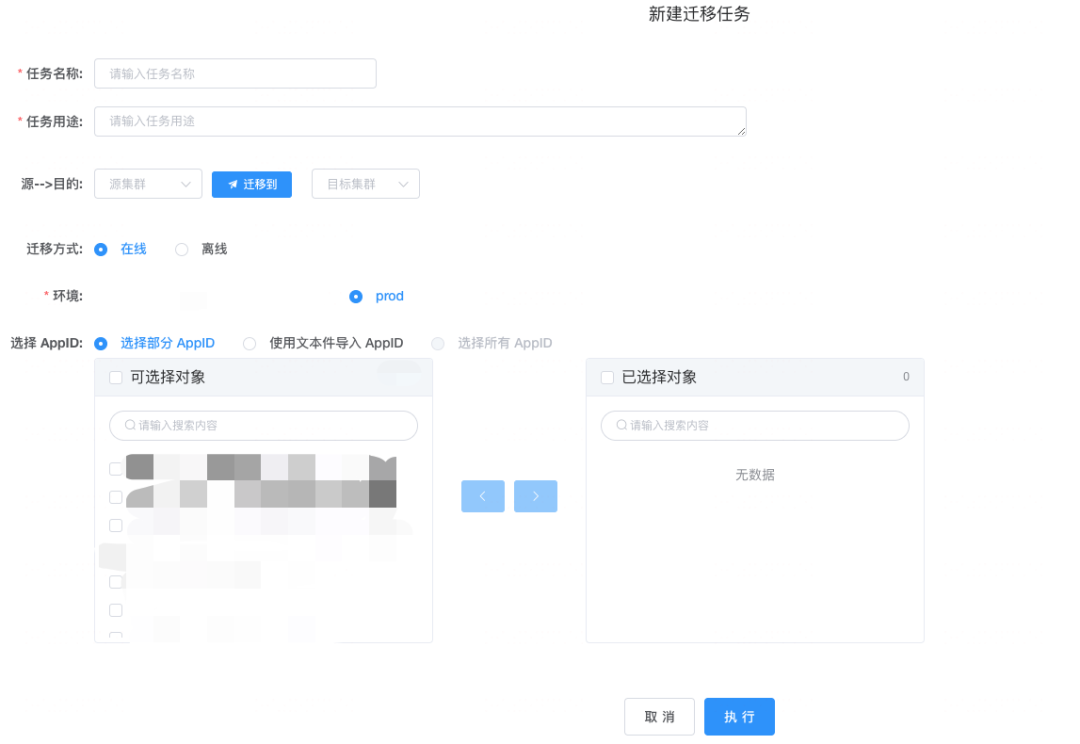
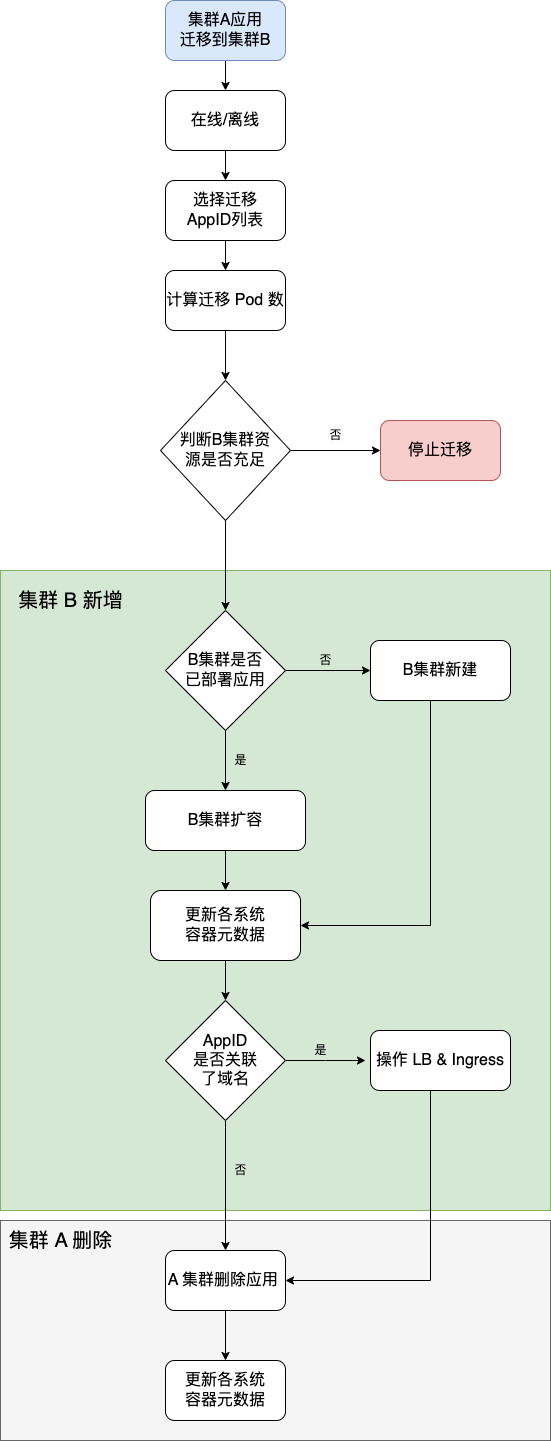
前置条件,所有集群备份通过 Velero 工具,备份到了 统一的 S3 桶里面。 当 A 集群发生 集群层故障时, 且 B 集群 没有足够的资源下, 还要考虑降级方案, 比如各 AppID 迁移副本数减半,优先迁移核心服务等策略。
核心伪代码如下:
// Handlek8sMigrate 处理 K8s 迁移
func Handlek8sMigrate(r migration.K8sMigrationRequest, k *K8sController, l *store.LogTask) {
l.WriteNewLog("从 %s 集群 %s 环境%s迁移如下 AppID %s 到 %s 集群", r.MigrationData.SrcCluster, r.MigrationData.Env, r.MigrationData.MigrateType, strings.Join(r.MigrationData.Appid, ", "), r.MigrationData.DestCluster)
if r.MigrationData.MigrateType == "离线" {
// velero 下载解压
var cluster string
if r.MigrationData.Env == "xxx" || r.MigrationData.Env == "xx" {
cluster = "xxxx"
}
commandStr := fmt.Sprintf("mkdir -p /tmp/backupdownload/ && cd /tmp/backupdownload/ && velero backup download $(velero backup get | grep " + cluster + "-k8s-" + r.MigrationData.Env + "| head -1 | awk '{print $1}') && tar -xvf *.tar.gz")
_, err := executeSSHCommand(commandStr)
if err != nil {
fmt.Println(err)
}
}
// 获取 k8sclient
srcK8sClient := k.store.GetK8sClient(r.MigrationData.SrcCluster, r.MigrationData.Env)
destK8sClient := k.store.GetK8sClient(r.MigrationData.DestCluster, r.MigrationData.Env)
// 计算迁移 Pod 数
var podNumSum int32
for _, appid := range r.MigrationData.Appid {
replicas, _, err := getReplicasAndAppid(srcK8sClient, appid, r.MigrationData.Env, r.MigrationData.MigrateType)
if err != nil {
l.WriteNewLog(appid + " 获取副本数储出错" + err.Error())
}
podNumSum = podNumSum + replicas
}
l.WriteNewLog("总共需要迁移 %d 个 Pod", podNumSum)
// 获取目标集群剩余可创建 pod 数
destRemainingData, err := getRemainingData(r)
if err != nil {
l.WriteFineshedLog("failed", "获取不到目标集群可创建 Pod 数, 任务结束"+err.Error())
return
}
l.WriteNewLog("目标集群可创建 Pod 数为 %d", destRemainingData)
// 判断资源是否充足
if destRemainingData > int(podNumSum) {
l.WriteNewLog("目标集群资源充足, 继续进行迁移")
} else {
l.WriteFineshedLog("failed", "目标集群资源不足, 迁移终止")
return
}
// 资源充足,开始迁移 rollout、service、ingress 对象
var wg sync.WaitGroup
wg.Add(len(r.MigrationData.Appid)) // 在迁移开始之前增加 WaitGroup 的计数
for _, appid := range r.MigrationData.Appid {
go func(appid string) {
defer wg.Done() // 在 Goroutine 完成时减少 WaitGroup 的计数
// rollout 迁移
l.WriteNewLog(appid + " 迁移中...")
msg, err := rolloutMigrate(appid, r.MigrationData.Env, srcK8sClient, destK8sClient, r.MigrationData.MigrateType)
if err != nil {
l.WriteNewLog(appid + " 在目标集群中新增 Rollouts 失败")
return
}
l.WriteNewLog(appid + " " + msg)
// 更新元数据
count, orginAppid, _ := getReplicasAndAppid(destK8sClient, appid, r.MigrationData.Env, r.MigrationData.MigrateType)
err = UpdateDockerData(orginAppid, r.MigrationData.Env, strconv.Itoa(int(count)), destZone, typeID, destClusterID)
if err != nil {
l.WriteNewLog(appid + " 更新元据失败" + err.Error())
return
}
l.WriteNewLog(appid + " 更新元据失败数据成功")
// service 迁移
err = serviceMigrate(appid, r.MigrationData.Env, srcK8sClient, destK8sClient, r.MigrationData.MigrateType)
if err != nil {
l.WriteNewLog(appid + " 在目标集群中新增 Service 失败" + err.Error())
return
}
l.WriteNewLog(appid + " 在目标集群中新增 Service 成功")
// 判断是否关联域名
var isExists bool
var lbupstreamID []string
isExists, lbupstreamID, err = IsAssociateDomain(orginAppid, r.MigrationData.Env)
if err != nil {
l.WriteNewLog(appid + " 判断是否关联域名出错" + err.Error())
return
}
// ingress 迁移 & upstream 更新
if isExists {
l.WriteNewLog(appid + " 关联了 upstream")
for _, upstreamID := range lbupstreamID {
if err := ingressMigrate(destClusterID, upstreamID); err != nil {
l.WriteNewLog(appid + " 在目标集群中新增 Ingress 失败" + err.Error())
return
}
l.WriteNewLog(appid + " 在目标集群中新增 Ingress & 更新 Upstream 成功")
}
}
// upstream 更新 & 删除 ingress
srcClusterID, srcZone := getClusterIDAndZone(r.MigrationData.SrcCluster, r.MigrationData.Env)
if isExists {
err := deleteIngress(orginAppid, r.MigrationData.Env, srcZone, srcClusterID)
if err != nil {
l.WriteNewLog(appid + " 在源集群中删除 Ingress 失败" + err.Error())
return
}
l.WriteNewLog(appid + " 在源集群中删除 Ingress 成功")
}
// 删除 service
err = srcK8sClient.Clientset.CoreV1().Services(r.MigrationData.Env).Delete(context.TODO(), appid, metav1.DeleteOptions{})
if err != nil {
l.WriteNewLog(appid + " 在源集群中删除 Service 失败" + err.Error())
} else {
l.WriteNewLog(appid + " 在源集群中删除 Service 成功")
}
// 删除 rollout
err = srcK8sClient.RolloutsClientset.ArgoprojV1alpha1().Rollouts(r.MigrationData.Env).Delete(context.TODO(), appid, metav1.DeleteOptions{})
if err != nil {
l.WriteNewLog(appid + " 在源集群中删除 Rollouts 失败" + err.Error())
} else {
l.WriteNewLog(appid + " 在源集群中删除 Rollouts 成功")
}
// 删除源集群 cmdb 中数据
err = UpdateDockerData(orginAppid, r.MigrationData.Env, r.MigrationData.SrcCluster, srcClusterID)
if err != nil {
l.WriteNewLog(appid + " 删除源集群元数据失败" + err.Error())
}
l.WriteNewLog(appid + " 删除源集群元数据成功")
// 迁移完成
l.WriteNewLog(appid + " 迁移成功")
// 换行
l.WriteNewLog("")
}(appid)
}
wg.Wait() // 等待所有 Goroutine 完成
if r.MigrationData.MigrateType == "离线" {
// 删除 velero 解压数据
commandStr := fmt.Sprintf("rm -rf /tmp/backupdownload/*")
_, err := executeSSHCommand(commandStr)
if err != nil {
fmt.Println(err)
}
}
// 迁移完成
l.WriteFineshedLog("success", "本次迁移完成")
}
结束语
结合公司实际情况,适合自己的,就是最好的。
参考链接:
- Kubernetes多集群管理架构探索 | 徐信钊 KubeSphere Maintainer
- Kubernetes多集群架构的思考、实践和探索 | 段朦 移动云
- 混合云下的 Kubernetes 多集群管理与应用部署 | 李宇: https://mp.weixin.qq.com/s/ohZ-kSbU5AgxaksRt5rkCw
- 智汇华云 | Kubernetes多集群管理方案kubefed原理解析:https://mp.weixin.qq.com/s/_LjH6H-y63MPqwgF8pC0sg
- K8s 多集群实践思考和探索 | vivo互联网技术:https://mp.weixin.qq.com/s/vztX73tqfrx1r4suDQa9kw
- karmada官方文档:https://karmada.io/zh/docs