VLDB 2024 | TFB: 一个全面公平的时间序列预测方法评测基准
VLDB 2024 | TFB: 一个全面公平的时间序列预测方法评测基准

时间序列出现在经济、交通、健康和能源等多个领域,对未来值的预测具有许多重要应用。因此,人们提出了许多预测方法。为了确保研究的进展,有必要以全面和可靠的方式对这些方法进行研究和比较。
近期,来自华东师范大学决策智能实验室、华为云算法创新实验室和丹麦奥尔堡大学的研究团队,为了实现上述目标,提出了TFB,这是一个用于时间序列预测方法的自动化基准。TFB通过解决与数据集、比较方法和评估流程相关的缺陷来推动最新技术的发展。通过实验,论文得出了一些关键发现,包括传统统计方法在某些数据集上的表现优于最新方法,以及不同方法在处理具有不同特征的数据集时的优缺点。此外,论文中还表明,改变批次大小会影响方法的性能,因此建议在评估时间序列预测方法时,应该采用一致的批次处理策略,呼吁testing不使用Drop-last操作,这一影响多个时序Baselines性能的代码bug。这种设计有助于提高评估的一致性和公平性,从而得到更准确的方法性能比较结果。

【论文标题】TFB: Towards Comprehensive and Fair Benchmarking of Time Series Forecasting Methods
【论文地址】https://arxiv.org/abs/2403.20150
【论文源码】https://github.com/decisionintelligence/TFB
论文概述
这篇论文提出了一个名为TFB(Time Series Forecasting Benchmark)的自动化基准测试,旨在全面和公正地评估时间序列预测(TSF)方法。研究者识别并解决了现有评估框架中的三个问题,从而提高了评估能力。
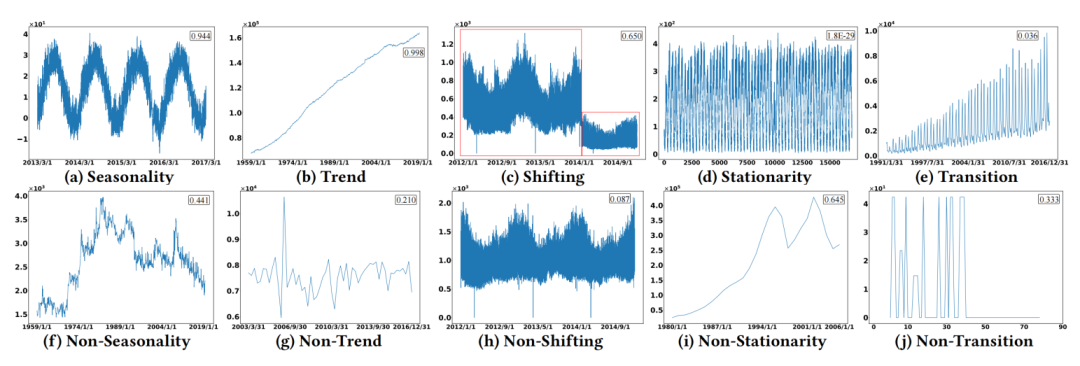
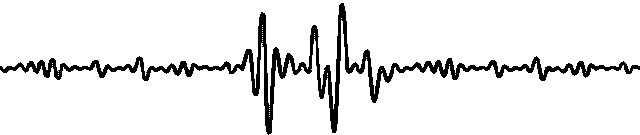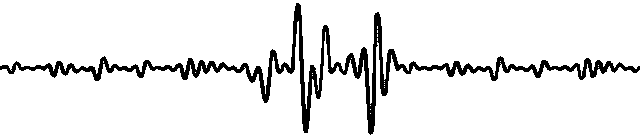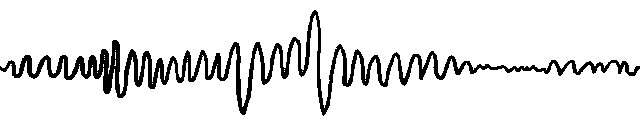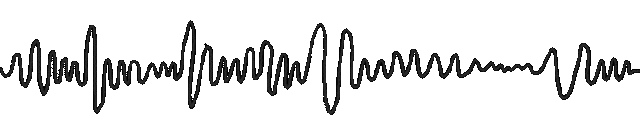
图1:具有不同特征的数据的可视化
问题1:数据领域覆盖不足:来自不同领域的时间序列可能具有各种不同的特征。然而,很少有实证研究和基准涵盖广泛的数据领域。
问题2:对传统方法的刻板影响:早期的评估往往忽略了传统方法,如统计学习方法,而只关注基于机器学习和深度学习的方法。
问题3:缺乏一致和灵活的流程:不同方法的性能会随着实验设置的变化而变化,如训练/验证/测试数据的划分、归一化方法的选择以及超参数设置的选择,这使得跨基准的比较变得困难。
为解决上述问题,研究者提出了时间序列预测基准(TFB),更全面地对TSF方法进行实证评估和比较,并提高评估的公平性。TFB提供了一系列具有挑战性和现实性的数据集,并提供了用户友好、灵活和可扩展的评估流程,提供了强大的评估支持。TFB具有以下关键特性:
- 根据数据集特征分类方法进行全面的数据集收集(解决问题1)
- 广泛覆盖现有方法并扩展对评估策略和指标的支持(解决问题2)
- 灵活和可扩展的流程(解决问题3)
总体来看,论文主要有以下4个主要贡献:
- 提出了TFB,这是一个专门设计用于进一步提高时间序列预测(TSF)方法公平比较的基准,包括单变量时间序列预测(UTSF)和多变量时间序列预测(MTSF)。TFB在8,068个单变量时间序列上测评了超过20种UTSF方法以及在25个多变量数据集上对14种MTSF方法进行了测评。
- 确定、收集和处理先前提出的TSF数据集,以确定涵盖不同领域和特征的全面的数据集,并以标准化格式组织它们。然后设计实验来研究不同方法在不同特征数据集上的表现。
- TFB提供了一个自动化的端到端流程,用于评估预测方法,简化和标准化加载时间序列数据集、配置实验和评估方法的步骤,这简化了研究人员的评估过程。
- 使用TFB评估和比较了一系列方法,涵盖了统计学习、机器学习和深度学习方法以及丰富多样的评估任务和策略。
Drop last现象说明
现有的一些方法在测试阶段使用“Drop last”的技巧。为了加速测试,通常将数据分成批次。然而,如果我们丢弃最后一个不完整批次,其中包含的样本数量少于批次大小,这会导致不公平的比较。
例如,在图2中,ETTh2具有长度为2,880的测试序列长度,使用大小为512的回溯窗口预测336个未来时间步。如果我们选择批次大小为32、64和128,那么最后一个批次中的样本数量分别为17、49和113。除非所有方法都使用相同的批次大小,否则丢弃这些最后一个批次的测试样本是不公平的,因为测试集的实际使用长度不一致。表1显示了在ETTh2上使用不同批次大小和“Drop last”技巧的PatchTST、DLinear和FEDformer的测试结果。研究者观察到,在变化批次大小时,方法的性能会发生变化。
因此该论文呼吁testing不使用Drop-last操作,该论文在testing中没有使用Drop-last操作。
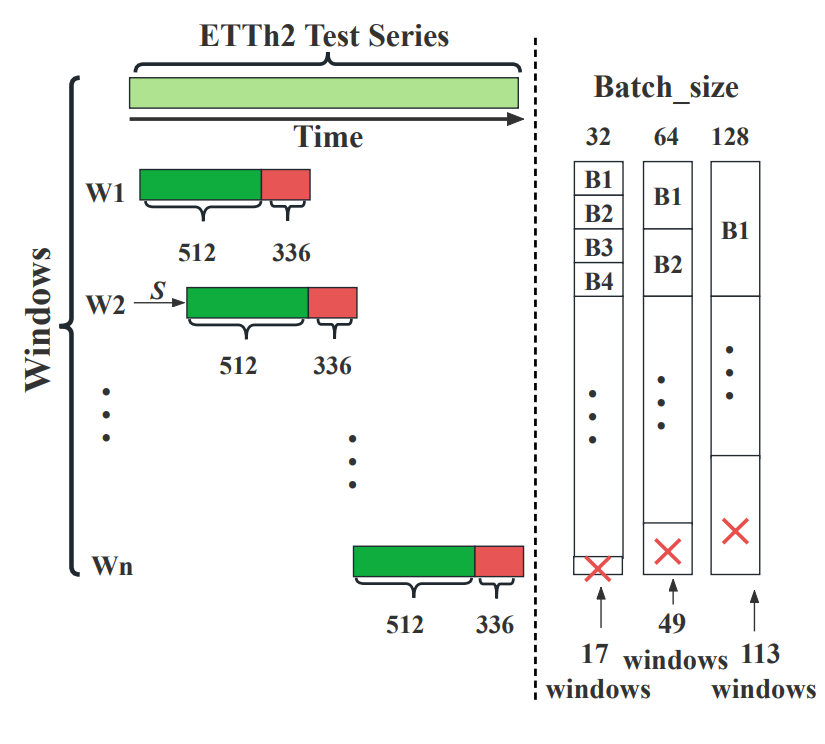
图2:Drop last 情况说明
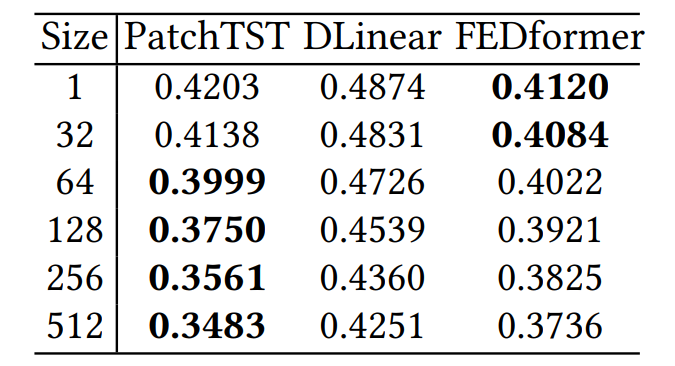
表1:使用“Drop last”时批量大小对实验结果影响
相关定义
研究者提供了时间序列和时间序列预测的定义,并涵盖了关键的数据集特征,包括趋势性、季节性、平稳性、漂移性、转移和相关性。
时间序列: 时间序列是一个面向时间的N维时间点序列,其中是时间点的数量,是变量的数量。当时,时间序列称为单变量。当时,它被称为多变量。
时间序列预测: 给定个时间点的历史时间序列,时间序列预测旨在预测个未来时间点,即。其中称为预测步长。
趋势性(Trend):趋势性是指时间序列随着时间的推移而发生的长期变化或模式。直观地说,它代表了数据漂移的大致方向。
季节性(Seasonality):季节性是指时间序列中的变化以特定的间隔重复的现象。
平稳性(Stationarity):平稳性是指时间序列的各阶统计特征(如均值、方差)不随时间的变化而变化。
漂移性(Shifting):漂移性是指时间序列的概率分布随时间变化的现象。这种行为可能源于系统内部的结构变化、外部影响或随机事件的发生。
转移(Transition):转移捕捉了时间序列中存在的规律性和可识别的固定特征,例如趋势、周期性的明确表现,或者季节性和趋势同时存在。
相关性(Correlation):相关性是指多变量时间序列中不同变量可能共享的可能性共同的趋势或模式,表明它们受到相似的因素或具有某种潜在的关系。
TFB:基准细节
在数据集方面,研究者为TFB配备了25个多变量和8,068个单变量数据集,做到了所有数据集都格式一致,数据集收集全面,涵盖了多种领域和特性。这标志着这项改进解决了不同格式、文档不同和数据集收集耗时的挑战。
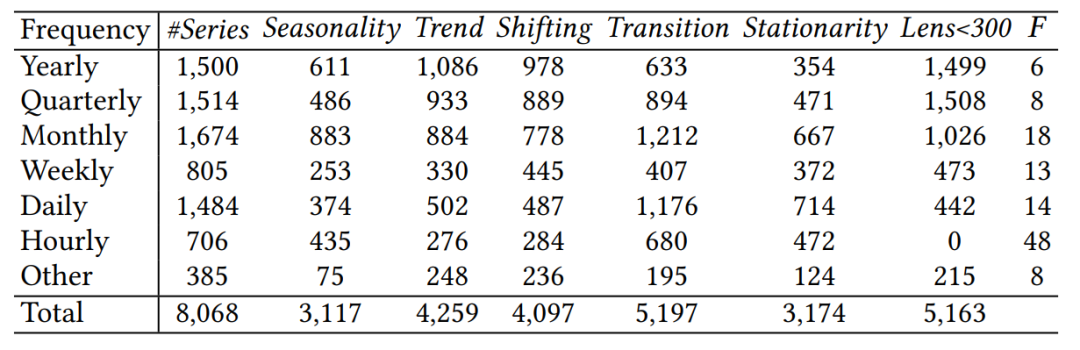
表2:单变量数据集的统计数据
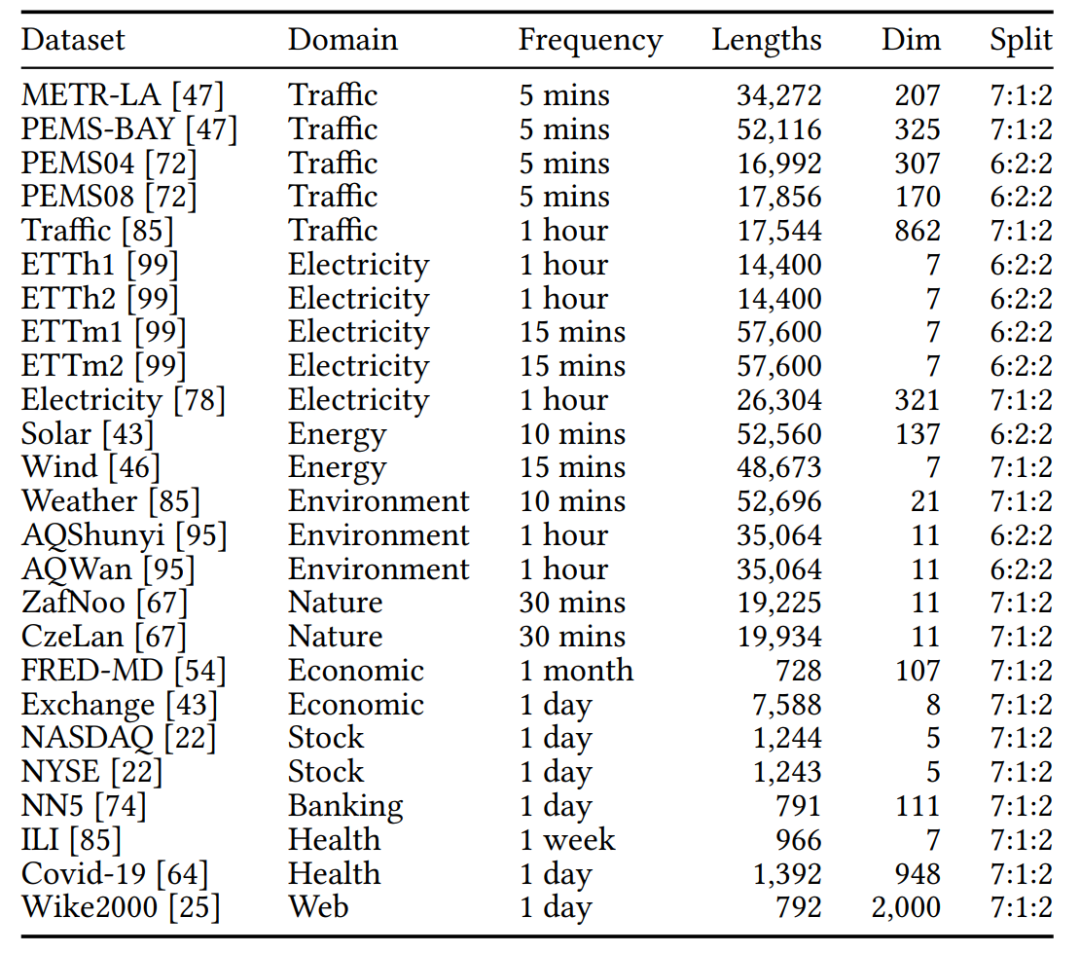
表3:多变量数据集的统计数据
01
对比方法
研究者使用了22种方法,支持包括统计学习、机器学习和深度学习在内的多种时间序列预测方法。图3概述了基准涵盖的方法的多样化技术方法。这种广泛选择的比较方法旨在提供对不同方法的技术细微差别和性能变化的深入理解。
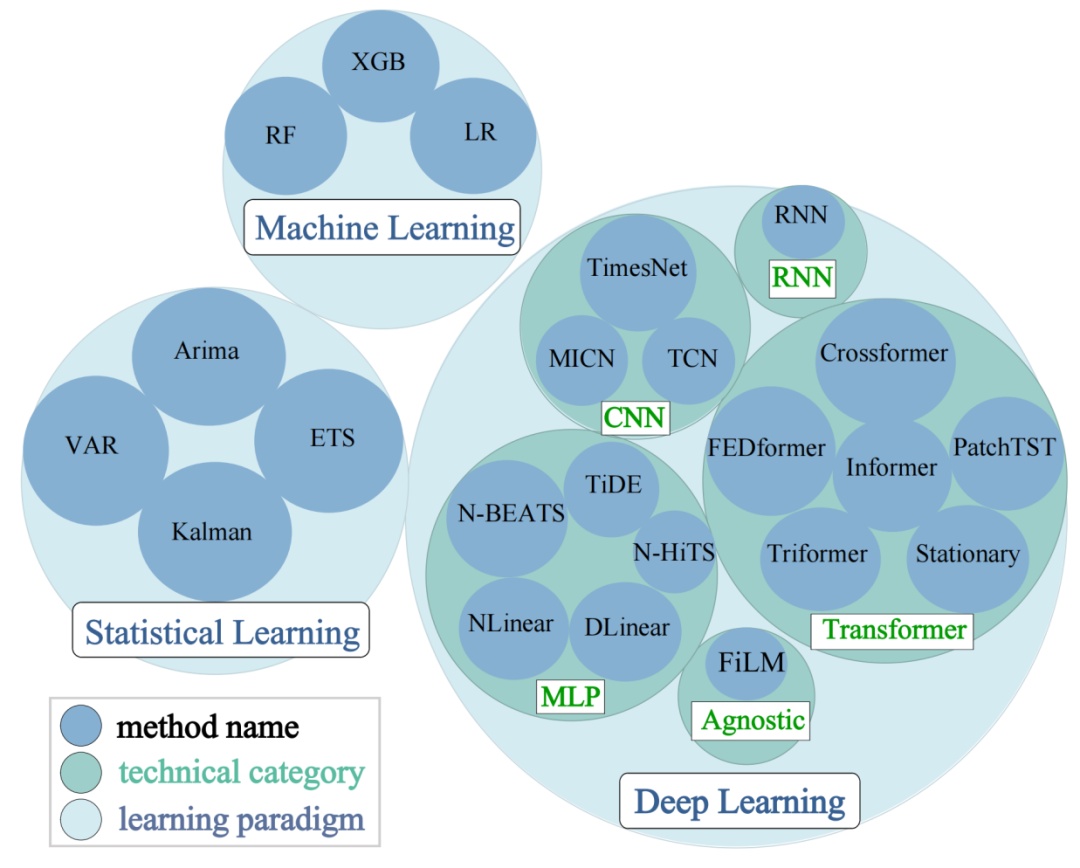
图3:比较方法的分类
02
评估设定
为了评估方法的预测准确性,TFB实现了两种不同的评估策略:1) 固定预测;2) 滚动预测。
固定预测:给定长度为n的时间序列,从n-f个历史时间点预测f个未来时间点,如图4a所示。
滚动预测:如图4b所示,在滚动预测中,蓝色方块表示历史数据,绿色方块表示预测步长,白色方块表示时间序列中的剩余数据。
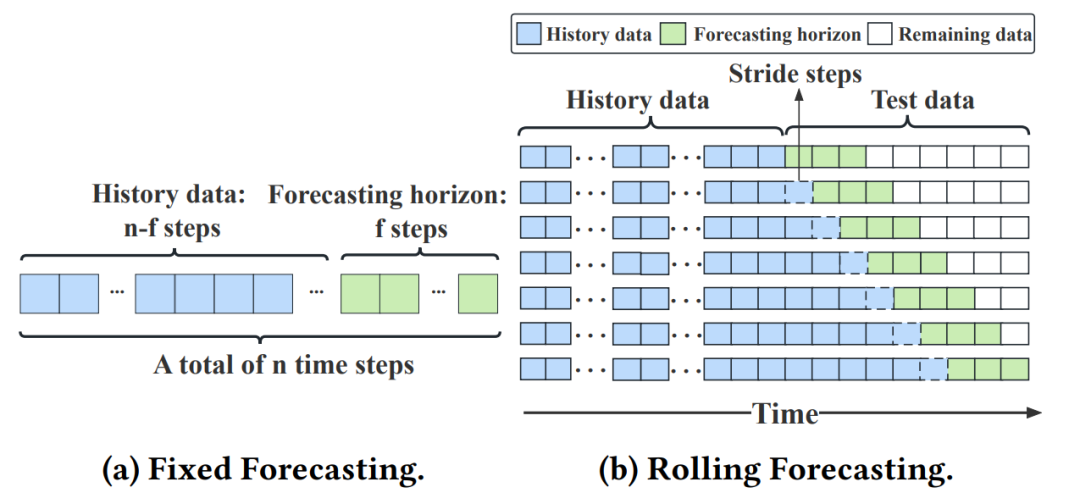
图4:不同时间序列预测评估策略(a)固定时间步预测;(b)滚动划窗预测
03
统一的流程
为了实现方法的公平和全面比较,研究者设计了一个统一的评估流程,分为数据层、方法层、评估层和报告层。
用户只需在方法层部署自己的方法架构,并选择或配置配置文件,然后TFB就可以自动运行图5中的流程。
TFB流程具备可扩展特性。与CPU和GPU硬件兼容性使得在不同的计算环境中进行评估成为可能。TFB还支持顺序和并行程序执行,为用户提供多种选择。
总之,TFB是一个统一、灵活、可扩展且用户友好的时间序列预测方法基准工具。它能够帮助用户更好地了解、比较和选择适用于特定应用场景的时间序列预测方法。
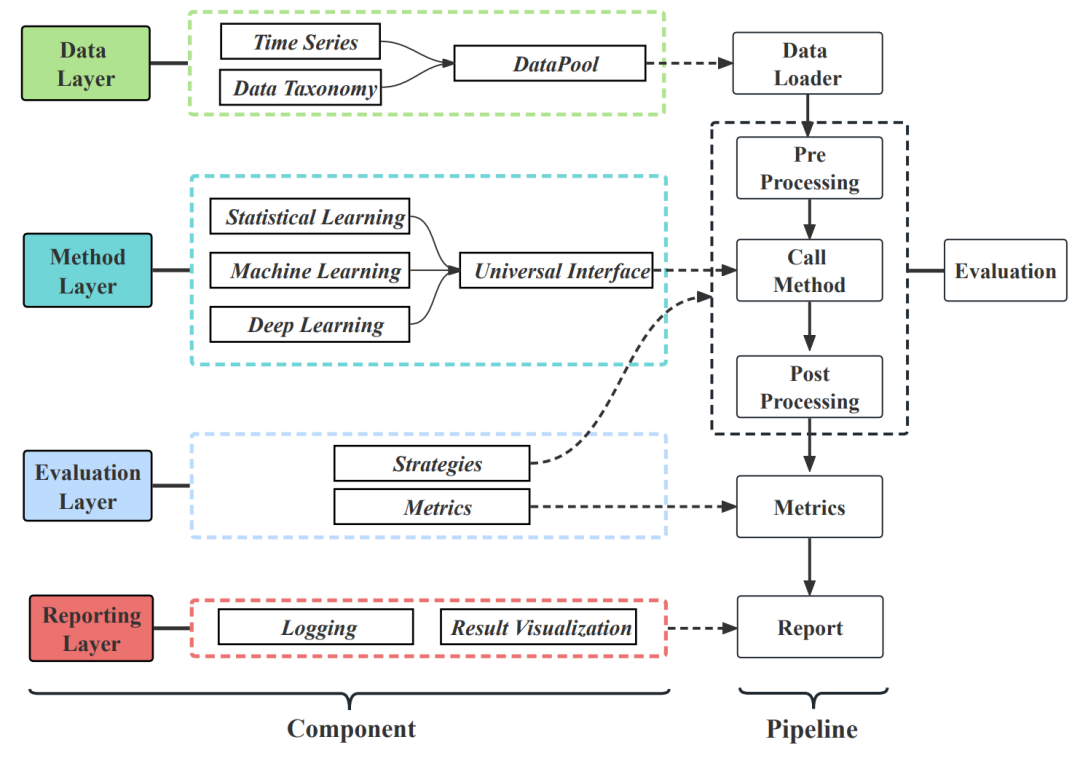
图5:TFB pipeline
实验结果
01
实验设定
在数据集方面,研究者使用了TFB中包含的所有数据集,包括25个多变量数据集和8,068个单变量时间序列。
在对比方法上,为了减少对比方法上的刻板印象,使用了22种不同的时间序列预测方法,涵盖统计学习、机器学习和深度学习三大类,进行全面比较。
单变量时间序列预测:采用固定预测策略,以保持与M4竞赛设置的一致性,预测步长从6到48,回看窗口长度H 设置为预测步长F 的1.25倍。
多变量时间序列预测:采用滚动预测策略。对于FredMd、NASDAQ、NYSE、NN5、ILI、Covid-19和Wike2000等数据集,考虑了四个预测步长:24、36、48和60;对于其他长度更长的数据集,使用另外四个预测步长:96、192、336和720。回看窗口长度H 在FredMd、NASDAQ、NYSE、NN5、ILI、Covid-19和Wike2000等数据集上分别为36和104;对于其他所有数据集,为96、336和512。
02
实验结果
单变量时间序列预测:研究者主要分析了不同方法在具有不同特征(如季节性、趋势、平稳性等)的时间序列上的表现。
从实验结果上来看,包括TimesNet、PatchTST和N-HiTS在内的最近提出的深度学习方法,在MASE和MSMAPE方面在单变量数据集上表现出明显更好的平均性能。LR在具有季节性、趋势性和漂移特征的时间序列上表现更好,而在这些模式不存在时,RF表现更好。此外,结果还显示LR对于没有平稳性的数据更合适。最后,LR和RF对转移特征很敏感:特征越强,表现越好。这些结果为选择特定设置下的正确方法提供了指导。
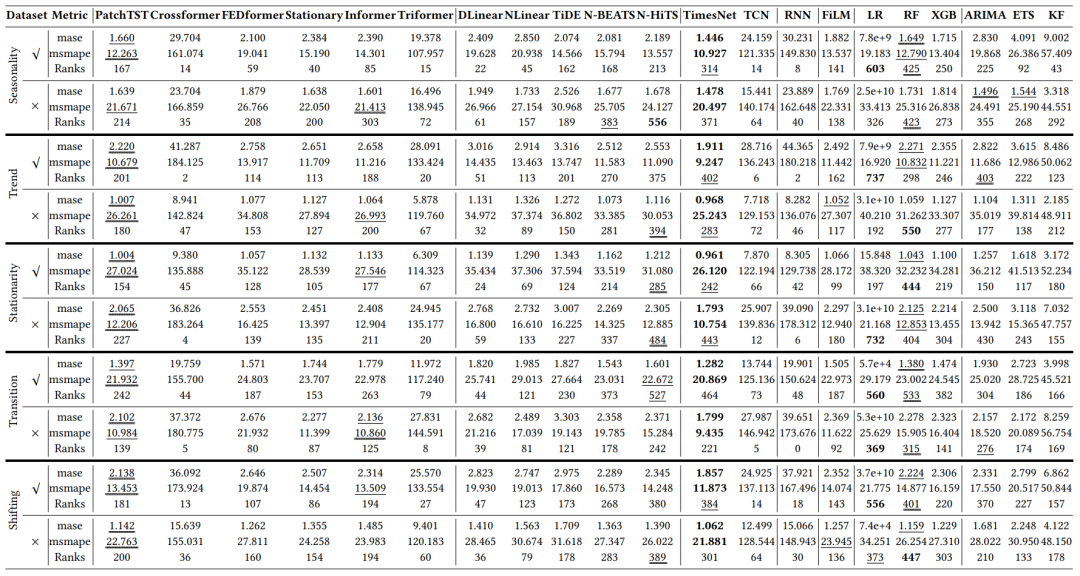
表4:单变量预测结果
多变量时间序列预测:比较了不同方法在数据集上的表现,并探讨了它们在处理多变量时间序列时的优缺点。
从实验结果上来看,没有单一方法在所有数据集上都表现最佳,基于Transformer的方法通常在具有较弱趋势的数据集上表现优于其他方法。接下来,基于线性的方法在具有强趋势的数据集上往往表现略好。此外,研究者还发现最近的方法并不一定在所有数据集上表现优于较早的研究,如Informer、LR和VAR。这一发现突显了在不同数据集上评估方法性能的必要性。在相对较少的数据集上评估方法使得准确评估它们的普遍性和整体性能变得困难。因此,扩展评估中使用的数据集范围至关重要。
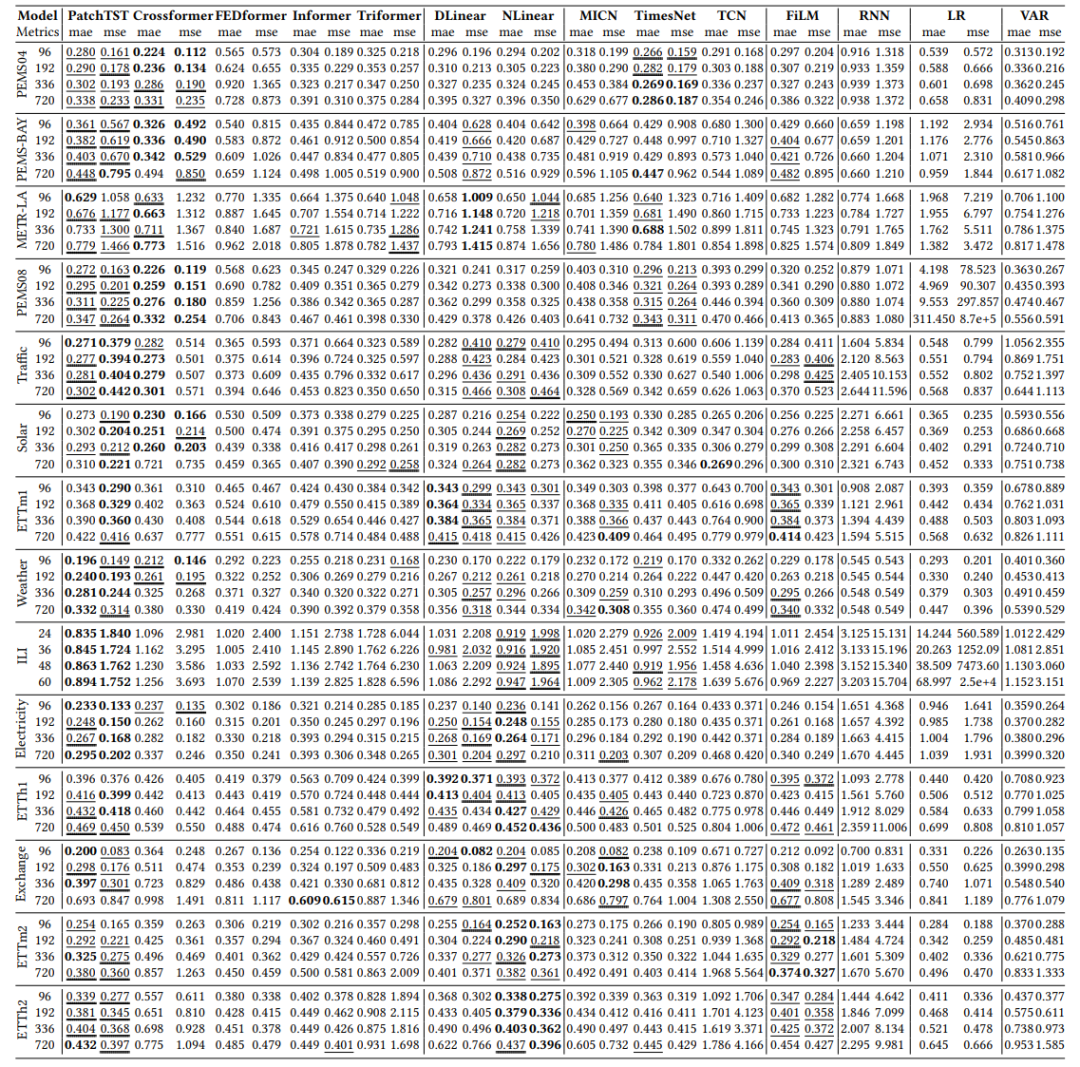
表5:多变量预测结果 I
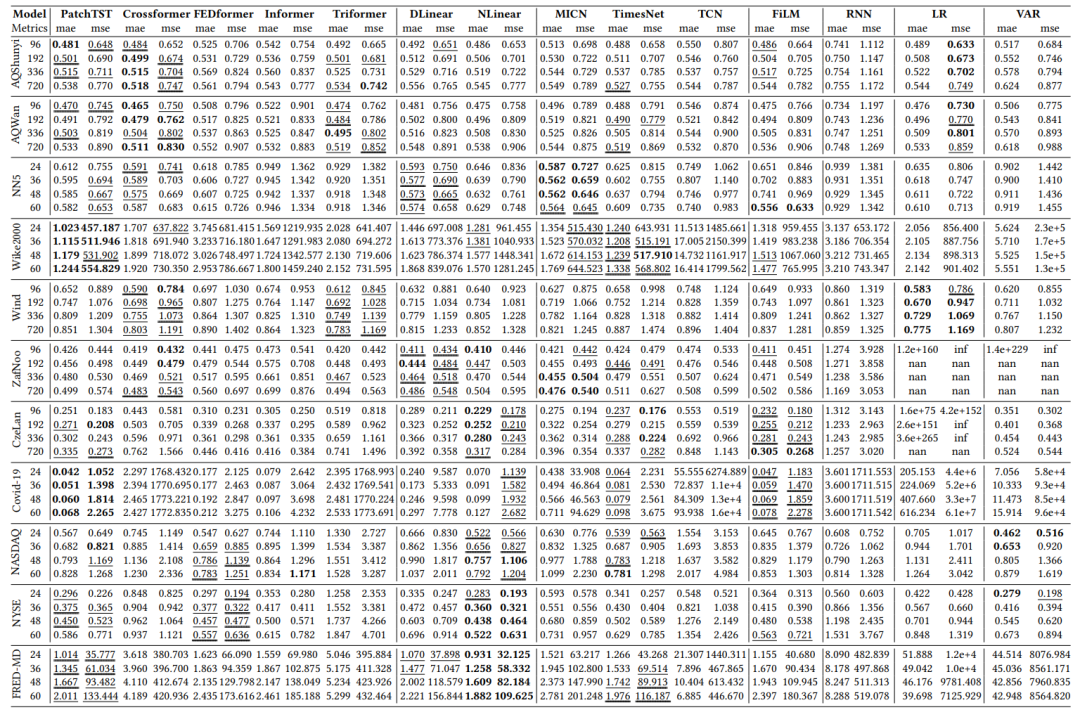
表6:多变量预测结果 II
03
方法性能分析
论文研究了不同深度学习方法在不同特征下的表现,结果表明,不同的深度学习方法在具有不同特征的数据集上具有不同的能力,没有一种方法被认为是最佳方法。因此,指导新方法设计的深入分析非常重要。
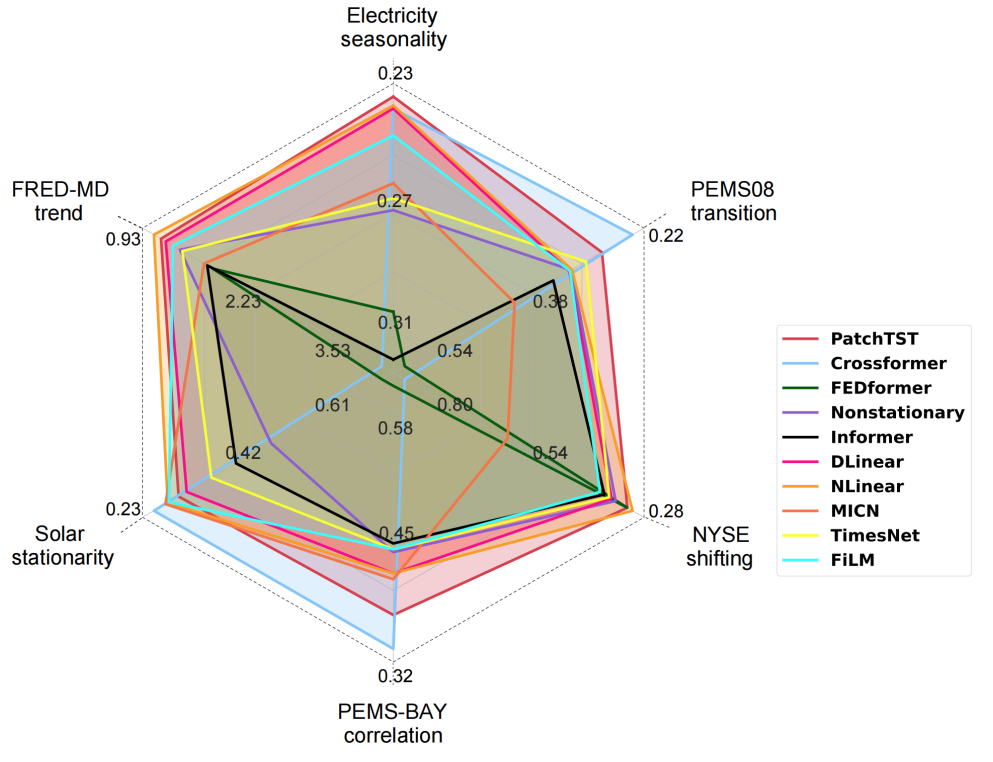
图6:方法在六个特征上的平均绝对误差(MAE)结果
为了研究不同数据特征对这两种类型方法的影响,研究者考虑了CNN、Linear和Transformer的最佳MAE结果。观察到的现象强调了Transformer方法和线性方法在处理时间序列的不同特征时的固有差异。为了实现最佳性能,论文建议根据相关时间序列的特征选择合适的方法,使方法能够充分发挥其优势。
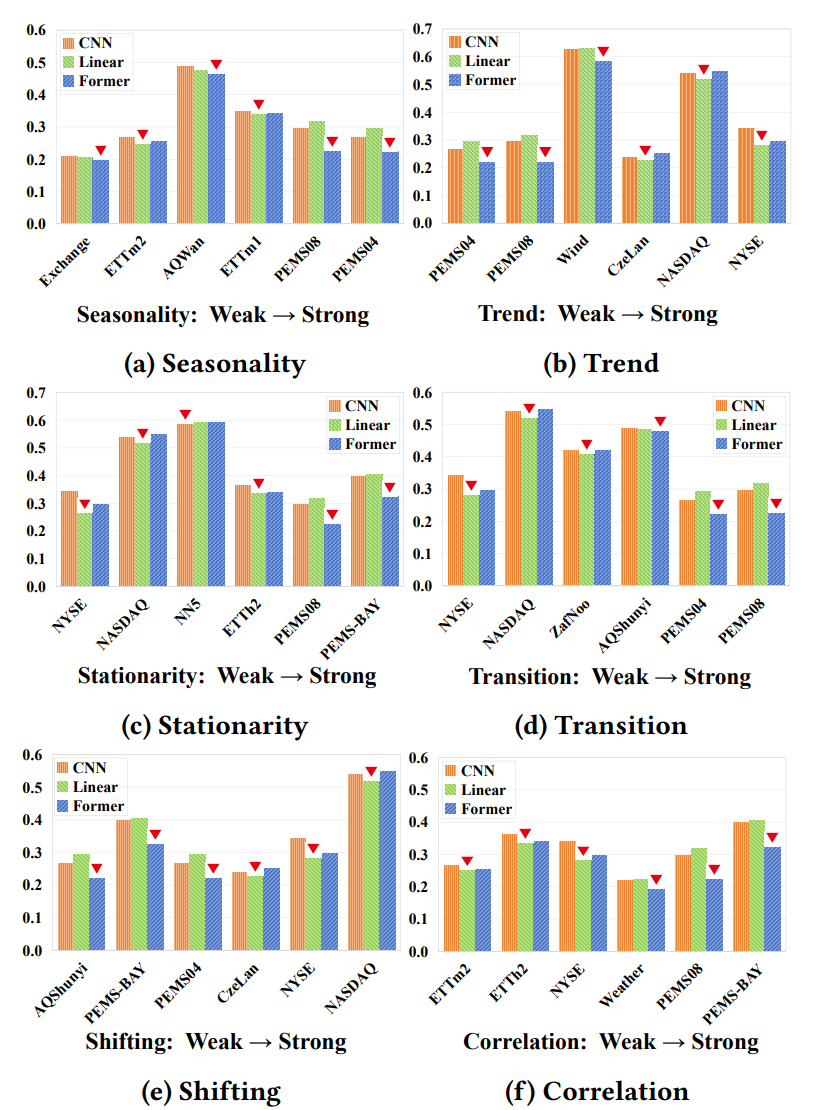
图7:基于Transformer、基于CNN和基于线性的方法之间的比较。红色三角形表示具有最佳准确性(最小MAE)的方法
关键发现
- 在某些数据集中,统计方法VAR和LinearRegression的表现优于最近提出的SOTA方法。
- 当数据集呈现增长趋势或明显漂移时,基于线性的方法表现良好。
- 基于Transformer的方法在具有明显季节性、非线性模式以及更明显模式或强内部相关性的数据集上优于基于线性的方法。
- 考虑通道之间依赖关系的方法,与假设通道独立性的方法相比,有时可以提高多变量时间序列预测的性能,特别是在具有强相关性的数据集上。未来的文章应该关注如何提取、利用变量间关系来进行预测。
- 测试过程中使用Drop-last操作会对实验结果产生很大影响,造成不公平比较现象,论文呼吁testing不使用Drop-last操作,这一影响多个时序Baselines性能的代码bug。
总结
本文研究者提出了TFB时间序列预测基准,它解决了三个问题,以实现对时间序列预测(TSF)方法的全面和可靠比较。为了缓解数据域不足的问题,TFB包含了来自总共10个不同领域的数据集,涵盖了交通、电力、能源、环境、自然、经济、股票、银行、健康和网页等领域。研究者还包括了对时间序列特性的分析,以确保所选数据集在不同特性上分布良好。为了消除对传统方法的偏见,TFB涵盖了一系列多样化的方法,包括统计学习、机器学习和深度学习方法,并辅以多种评估策略和指标。因此,TFB能够全面评估不同方法的性能。为了解决不一致和不灵活的流程问题,TFB提供了一种新的灵活且可扩展的流程,消除了偏见,并为性能比较提供了更好的基础。总体而言,TFB是一个更全面、更公平的基准,旨在促进新TSF方法的发展