华为的职级与薪资体系。。

大家好,我是二哥呀。
站在一个旁观者的角度,我个人对任何厂都是没有抵触情绪的,只要发 offer,只要钱给到位,只要不拖延,只要能就业,就算是好公司(咱要求不高)。
郑重声明:非华为的托(这年头必须得先甩锅)
去年秋招的时候,星球里就有好几位球友拿到了华为的 offer。从球友的反馈来看,华为对技术的要求不像互联网其他大厂那样,非常苛刻,基本上一天就能速通。
球友的报喜
只不过流程确实慢,所以我建议大家最好是先有一个备胎 offer,不要 all in。那对于 25 届打算冲华为的同学,可以看看《Java 面试指南》中收录的一些 QA,比如说:
- 签三方的时候看英语四六级吗?
- 为什么大家对华为评价这么高?
- 定级谈薪和小奖状的顺序?
- 审批用了多久?
- 切 base 地还能收到小奖状吗?
- 华为流程真的很恶心吗?
- 华为的职级和薪资体系
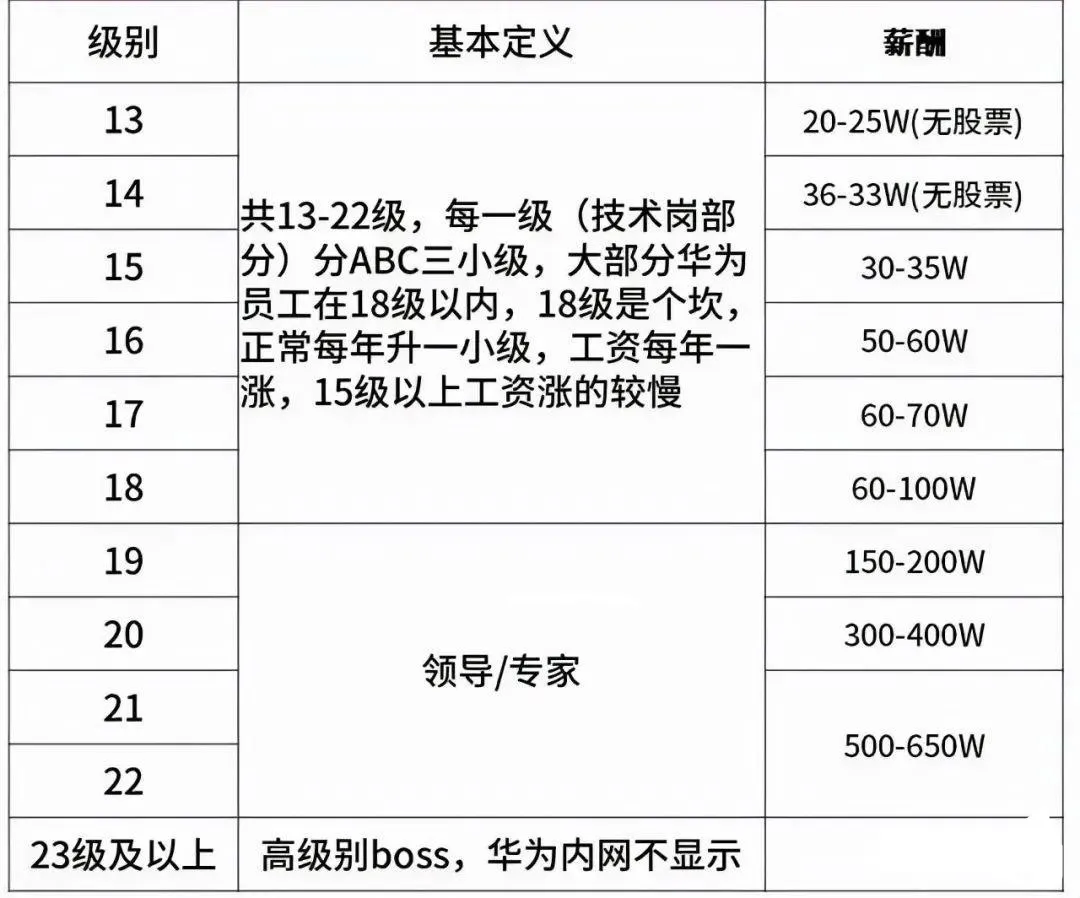
图片来源于牛客:仅供参考
了解清楚后再做打算,毕竟 25 届秋招还有两个月就启动了,7 月份很多提前批就开始了,现在正是准备的好时机。
这次我们就以《二哥的Java 面试指南》中同学 11 的华为面经为例,来看看华为的面试都会问哪些问题,好做到知彼知己百战不殆。

二哥的 Java 面试指南-华为面经
- 1、二哥的 Linux 速查备忘手册.pdf 下载
- 2、三分恶面渣逆袭在线版:https://javabetter.cn/sidebar/sanfene/nixi.html
华为面经(八股吟唱开始)
介绍一下项目,项目中的难点怎么解决?
技术派是一个基于 Spring Boot、MyBatis-Plus、MySQL、Redis、ElasticSearch、MongoDB、Docker、RabbitMQ 等技术栈实现的社区系统。
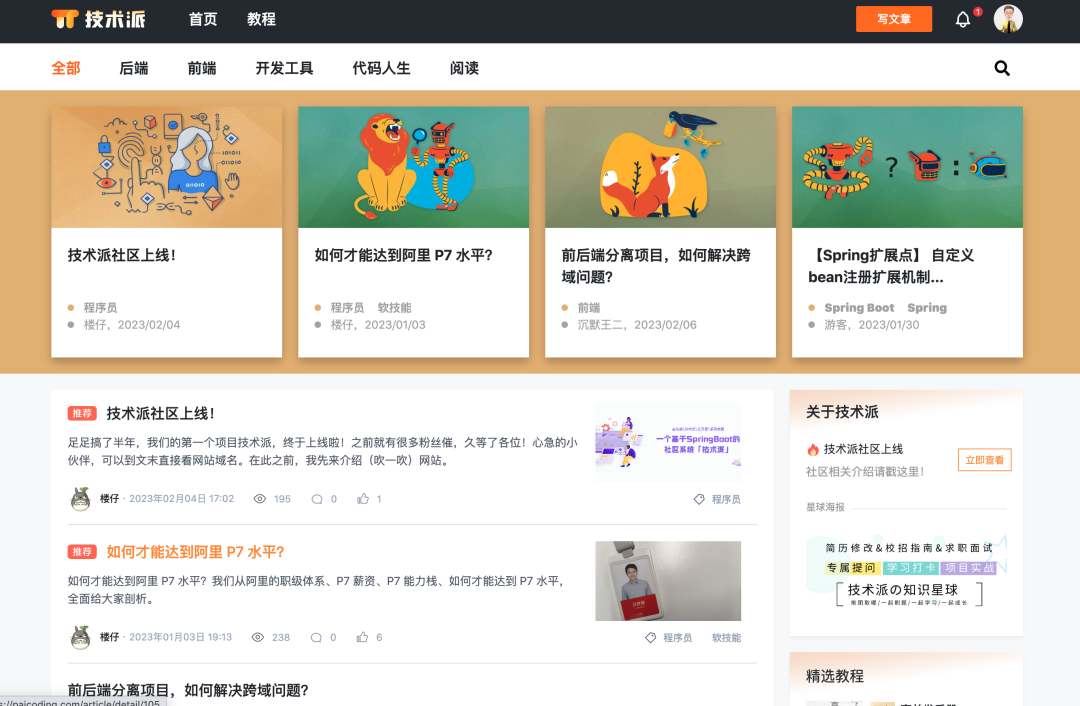
技术派首页
这个系统旨在为创作者提供一个可以发布文章和教程,并赚取佣金的社区平台,同时又兼顾一些社交属性,比如说用户可以通过阅读、点赞、收藏、评论的形式和作者互动。
与此同时,为了紧跟时代潮流,该系统还为用户提供了一套基于 OpenAI、讯飞星火等多家大模型的派聪明 AI 助手,帮助用户在工作和学习中大幅提效。
项目中有哪些难点,如何解决?
在技术派这个项目当中,遇到了蛮多有挑战的任务。
比如说 MySQL 的库表自动初始化,用户在启动项目前不需要手动导入 SQL 文件,只需要在 application.yml 中配置好 MySQL 的用户名和密码,run 以下 main 类,就自动完成了。这个是通过 Liquibase 实现的。
技术派教程
再比如说技术派是一个前后端分离项目,admin 端请求后端 API 接口时会遇到跨域问题,这个可以通过 Node 代理或者 Nginx 设置同源策略解决。
再比如说用户点赞、收藏文章的时候,可以通过 RabbitMQ 的发布/订阅模式来提高异步效率,保证用户的操作能够得到及时反馈。
再比如说为了满足社区在高并发场景下业务 ID 的唯一性和可追溯性,我们实现了一套基于雪花算法(Snowflake)的 ID 生成方案,进一步降低了 ID 生成的延迟。
还有我们通过 Redis 实现了计数统计和用户活跃度排行,并通过先写 MySQL,再删除 Redis 的方案来保证高并发场景下的缓存一致性。
还有在对接讯飞星火、OpenAI 等大模型平台的时候,为了提高代码的复用性和可扩展性,我们采用了策略模式+抽象工厂的模式来实现。
项目中使用了redis,redis有哪些数据类型?分别使用的场景是什么?什么使用hash类型而不使用string类型序列化存储?
Redis 有五种基本数据类型,这五种数据类型分别是:string(字符串)、hash(哈希)、list(列表)、set(集合)、sorted set(有序集合,也叫 zset)。
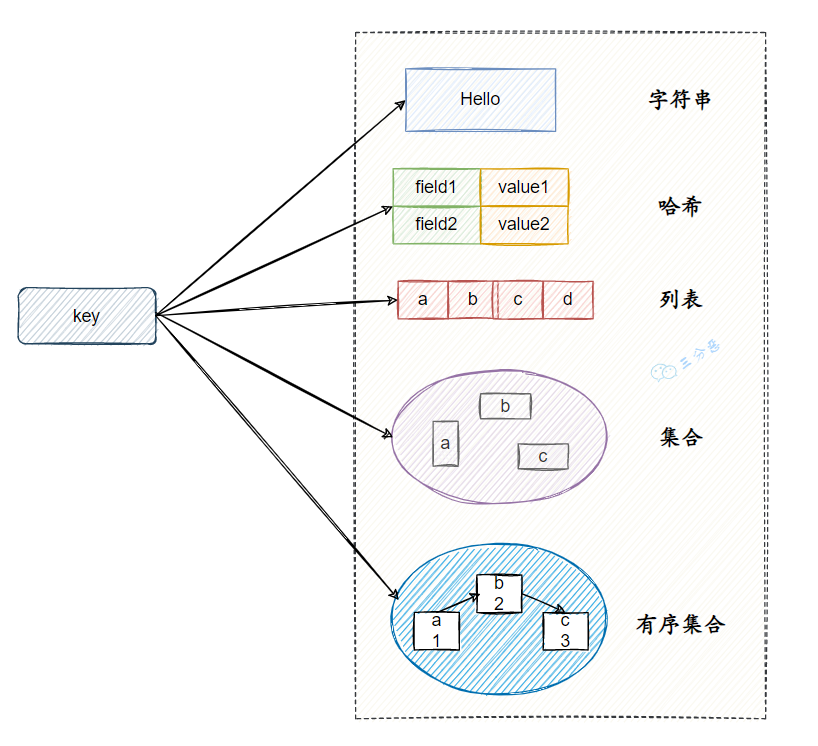
三分恶面渣逆袭:Redis基本数据类型
简单介绍下 string
字符串是最基础的数据类型,key 是一个字符串,不用多说,value 可以是:
- 字符串(简单的字符串、复杂的字符串(例如 JSON、XML))
- 数字 (整数、浮点数)
- 甚至是二进制(图片、音频、视频),但最大不能超过 512MB。
字符串主要有以下几个典型的使用场景:
- 缓存功能
- 计数
- 共享 Session
- 限速
简单介绍下 hash
键值对集合,key 是字符串,value 是一个 Map 集合,比如说 value = {name: '沉默王二', age: 18},name 和 age 属于字段 field,沉默王二 和 18 属于值 value。
哈希主要有以下两个典型应用场景:
- 缓存用户信息
- 缓存对象
什么使用hash类型而不使用string类型序列化存储?
来感受一下,使用字符串类型存储用户信息和使用哈希类型存储用户信息的区别:
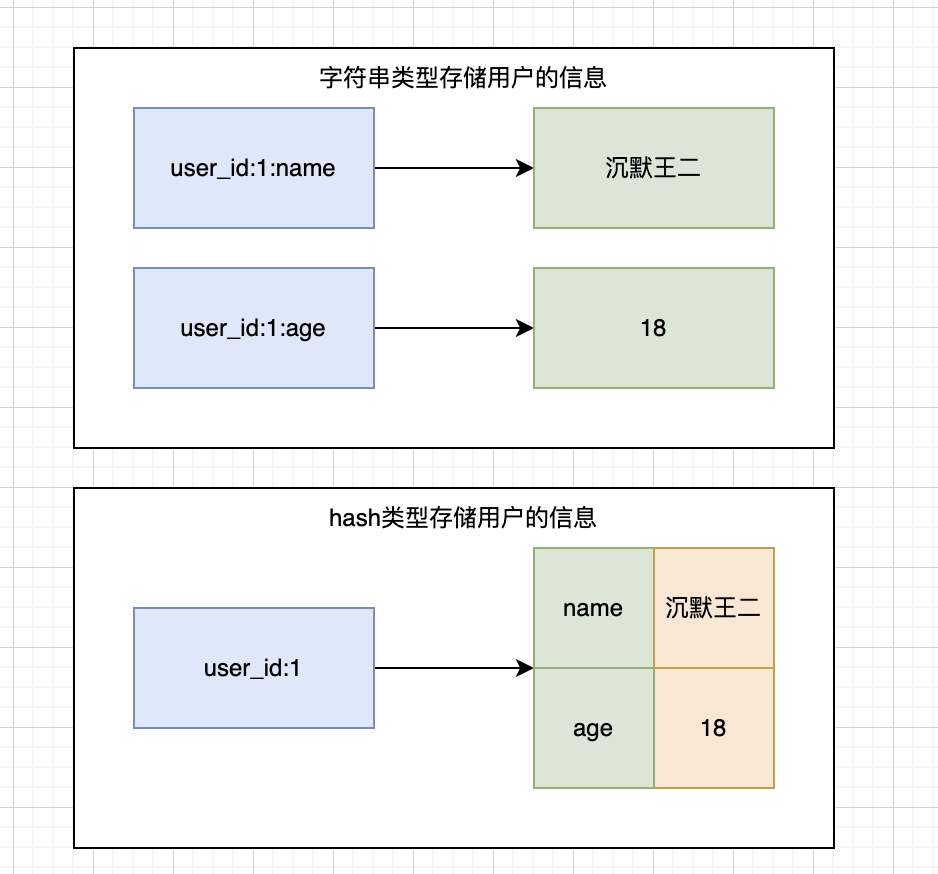
二哥的 Java 进阶之路
可以看得出,使用 hash 比使用 string 更便于进行序列化,我们可以将一整个用户对象序列化,然后作为一个 value 存储在 Redis 中,存取更加便捷。
简单介绍下 list
list 是一个简单的字符串列表,按照插入顺序排序。可以添加一个元素到列表的头部(左边)或者尾部(右边)。
列表主要有以下两个使用场景:
- 消息队列
- 文章列表
简单介绍下 set
集合是字符串的无序集合,集合中的元素是唯一的,不允许重复。和 Java 集合框架中的 Set 有相似之处。
集合主要有以下两个使用场景:
- 标签(tag)
- 共同关注
简单介绍下 sorted set
Zset,有序集合,比 set 多了一个排序属性 score(分值)。
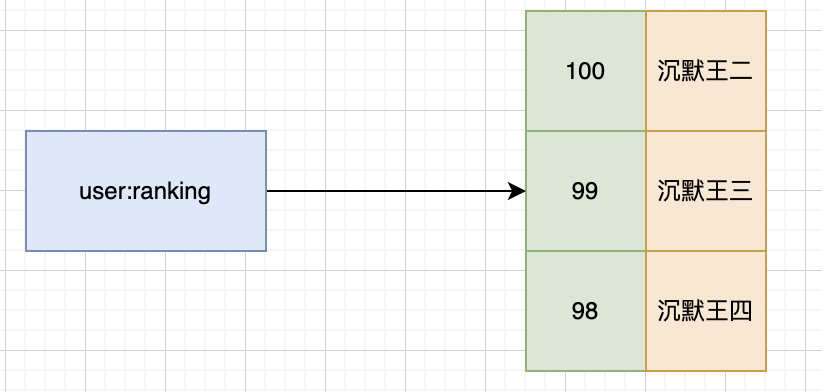
二哥的 Java 进阶之路
主要应用场景有:
- 用户点赞统计
- 用户排序
比如技术派实战项目中,我们就使用 Zset 来实现了用户月度活跃排行榜。
技术派用户活跃榜
使用的guava cache和redis是如何组合使用的?
在技术派实战项目中,就采用了本地缓存 Caffeine(或者 Guava Cache) + Redis 缓存的策略。分布式缓存基本就是采用 Redis。

三分恶面渣逆袭:延时双删
当数据库发生变化时,我们直接删除 Redis 缓存中的 key 就可以了,因为下一次请求会将数据库同步到 Redis 缓存中。
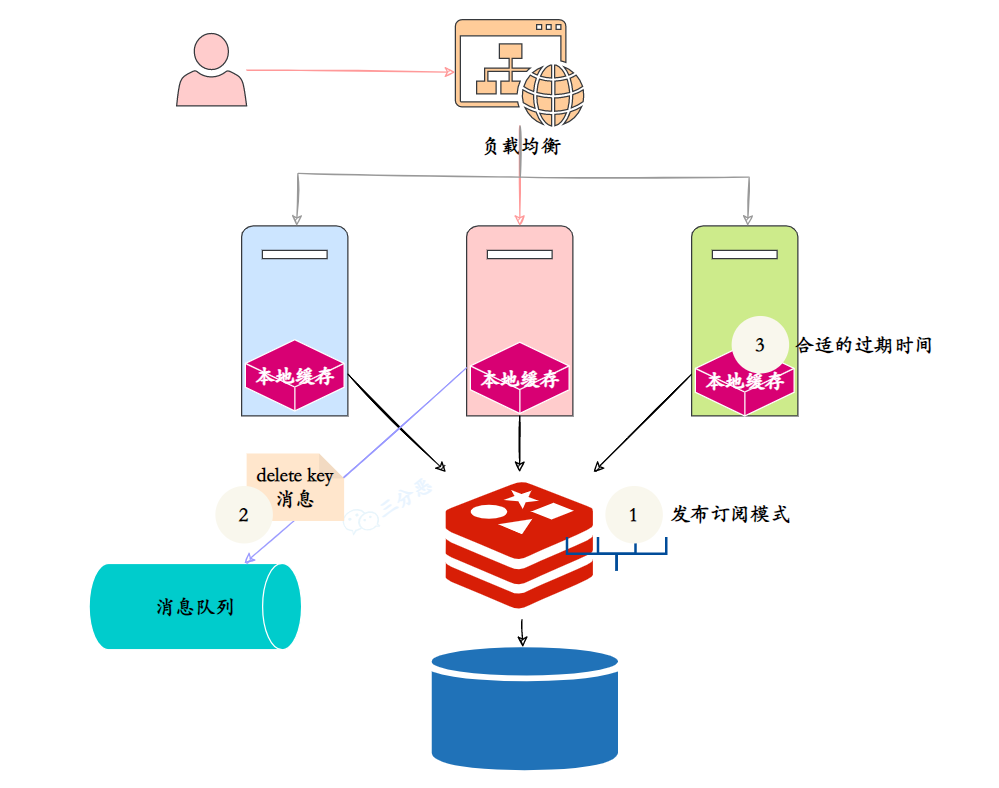
三分恶面渣逆袭:本地缓存/分布式缓存保持一致
那为了保证本地缓存和 Redis 缓存的一致性,我们可以采用的策略有:
①、设置本地缓存的过期时间,这是最简单也是最直接的方法,当本地缓存过期时,就从 Redis 缓存中去同步。
②、使用 Redis 的 Pub/Sub 机制,当 Redis 缓存发生变化时,发布一个消息,本地缓存订阅这个消息,然后删除对应的本地缓存。
③、Redis 缓存发生变化时,引入消息队列,比如 RocketMQ、RabbitMQ 去更新本地缓存。
在技术派实战项目中,我们使用了 CacheBuilder 来完成 Guava Cache 的构建,像一些简单的缓存场景,比如说获取菜单分类、获取登录验证码、获取用户转存图片等,都使用了 Guava Cache。

技术派教程:Guava
像首页侧边栏、专栏侧边栏、文章详情侧边栏等缓存场景,使用了 Caffeine 作为本地缓存,代码是通过 @Cacheable、@CacheEvit、@CachePut 等注解实现的。

技术派教程:Caffeine
像用户 Session 和网站地图 SiteMap 等缓存场景,我们就使用了 Redis 来作为缓存。

技术派教程:Redis
如果在项目中多个地方都要使用到二级缓存的逻辑,如何设计这一块?
在设计时,应该清楚地区分何时使用一级缓存和何时使用二级缓存。通常情况下,对于频繁访问但不经常更改的数据,可以放在本地缓存中以提供最快的访问速度。而对于需要共享或者一致性要求较高的数据,应当放在一级缓存中。
java中的集合类型?哪些是线程安全的?
Java 集合框架可以分为两条大的支线:
①、Collection,主要由 List、Set、Queue 组成:
- List 代表有序、可重复的集合,典型代表就是封装了动态数组的 ArrayList 和封装了链表的 LinkedList;
- Set 代表无序、不可重复的集合,典型代表就是 HashSet 和 TreeSet;
- Queue 代表队列,典型代表就是双端队列 ArrayDeque,以及优先级队列 PriorityQueue。
②、Map,代表键值对的集合,典型代表就是 HashMap。
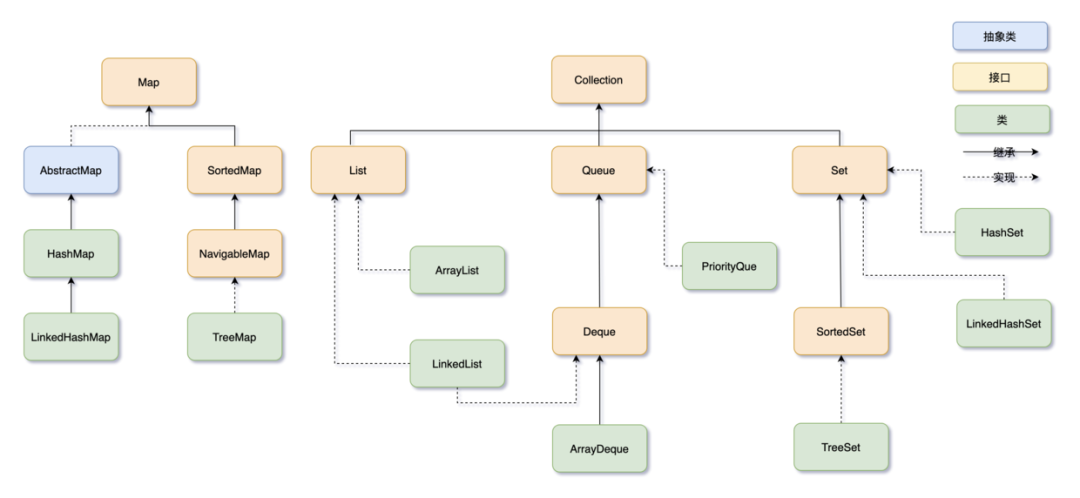
二哥的 Java 进阶之路:Java集合主要关系
像 Vector、Hashtable、ConcurrentHashMap、CopyOnWriteArrayList、ConcurrentLinkedQueue、ArrayBlockingQueue、LinkedBlockingQueue 这些都是线程安全的。
concurrenthashmap如何保证线程安全?
ConcurrentHashMap 在 JDK 7 时采用的是分段锁机制(Segment Locking),整个 Map 被分为若干段,每个段都可以独立地加锁。因此,不同的线程可以同时操作不同的段,从而实现并发访问。

初念初恋:JDK 7 ConcurrentHashMap
在 JDK 8 及以上版本中,ConcurrentHashMap 的实现进行了优化,不再使用分段锁,而是使用了一种更加精细化的锁——桶锁,以及 CAS 无锁算法。每个桶(Node 数组的每个元素)都可以独立地加锁,从而实现更高级别的并发访问。
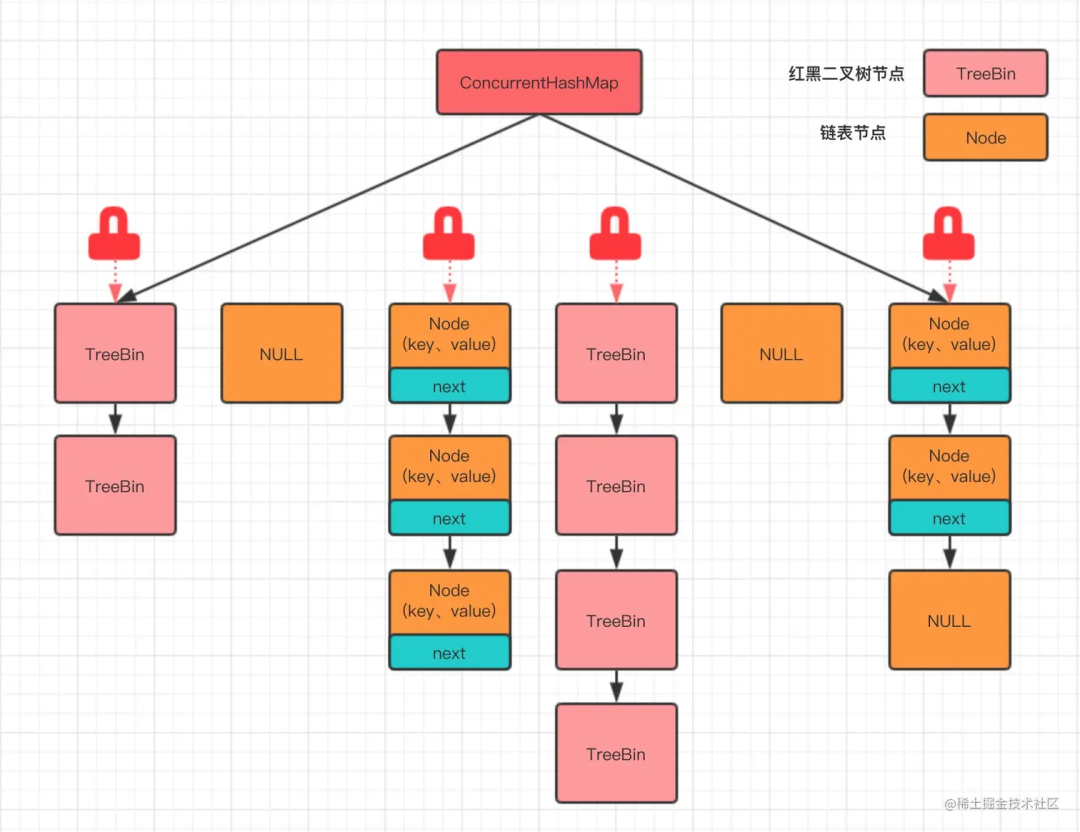
初念初恋:JDK 8 ConcurrentHashMap
同时,对于读操作,通常不需要加锁,可以直接读取,因为 ConcurrentHashMap 内部使用了 volatile 变量来保证内存可见性。
对于写操作,ConcurrentHashMap 使用 CAS 操作来实现无锁的更新,这是一种乐观锁的实现,因为它假设没有冲突发生,在实际更新数据时才检查是否有其他线程在尝试修改数据,如果有,采用悲观的锁策略,如 synchronized 代码块来保证数据的一致性。