文本生成视频Sora技术解读——作为世界模拟器的视频生成模型 Video generation models as world simulators
原创文本生成视频Sora技术解读——作为世界模拟器的视频生成模型 Video generation models as world simulators
原创
OpenAI最近推出了一款全新的文本生成视频模型:Sora。其只要输入一些描述视频画面的提示词,它就能生成一段时长60秒的视频。这些视频的质量和准确性达到了令人惊艳的程度,创造出既真实又充满想象力的场景,号称“作为世界模拟器的视频生成模型”。
什么是Sora?Sora有多牛?背后的技术原理是什么?应用价值如何?本篇文章将根据技术报告边解读边介绍Sora的效果、技术、发展和理解。
Sora预览地址:https://openai.com/sora 技术报告地址:https://openai.com/research/video-generation-models-as-world-simulators
一、摘要
我们探索在视频数据上对生成模型进行大规模训练。具体来说,我们在可变持续时间、分辨率和宽高比的视频和图像上联合训练文本条件扩散模型。我们利用了一种Transformer架构,该架构对视频和图像潜在代码的时空补丁进行操作。Sora能够生成一分钟的高保真视频。我们的研究结果表明,scaling video generation models(Sora)是构建物理世界通用模拟器的一条很有前途的途径。
二、文本生成视频Sora生成技术解读
2.1、生成模型速览
许多先前的工作已经研究了使用各种方法对视频数据进行生成建模,包括循环神经网络(RNN)、生成对抗网络(GAN),自回归Transformer(Autoregressive Model)和扩散模型(Diffusion Model),这些作品通常关注一小类视觉数据、较短的视频或固定大小的视频。
1️⃣、扩散模型(Diffusion Model) 扩散模型是一类生成模型,其通过迭代去噪过程将高斯噪声转换为已知数据分布的样本,生成的图片具有较好的多样性和写实性。
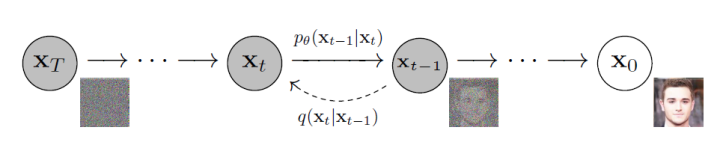
扩散过程逐步向原始图像添加高斯噪声,是一个固定的马尔科夫链过程,最后图像也被渐进变换为一个高斯噪声。而逆向过程则通过去噪一步步恢复原始图像,从而实现图像或视频的生成。
2️⃣、自回归模型(Autoregressive Model) 自回归模型模型利用其强大的注意力机制已成为序列相关建模的范例,受GPT模型在自然语言建模中的成功启发,图像GPT(iGPT)通过将展平图像序列视为离散标记,采用Transformer进行自回归图像生成。生成图像的合理性表明,Transformer模型能够模拟像素和高级属性(纹理、语义和比例)之间的空间关系。Transformer整体主要分为Encoder和Decoder两大部分,利用多头自注意力机制进行编码和解码。
3️⃣、生成对抗网络模型(Generative Adversarial Networks)
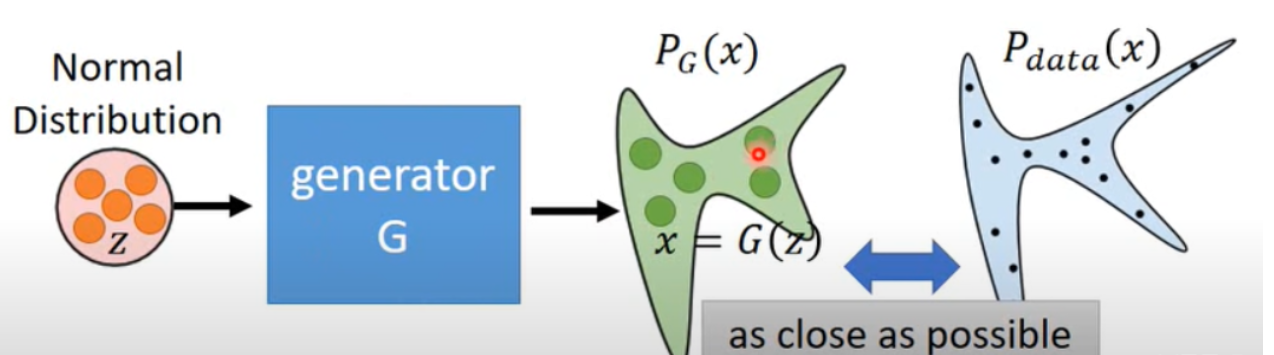
生成对抗网络包含一个生成模型和一个判别模型。其中,生成模型负责捕捉样本数据的分布,而判别模型一般情况下是一个二分类器,判别输入是真实数据还是生成的样本。整个训练过程都是两者不断地进行相互博弈和优化。生成器不断得生成图像的分布不断接近真实图像分布,来达到欺骗判别器的目的,提高判别器的判别能力。判别器对真实图像和生成图像进行判别,来提高生成器的生成能力。
而Sora 是视觉数据的通用模型,它可以生成不同时长、长宽比和分辨率的视频和图像,最多可达一分钟的高清视频。
2.2、视频数据预处理
Sora采取了一种方法来处理视频数据,其首先将视频压缩成较低维度的潜在空间,然后将这个压缩后的表示分解成一系列时空潜在补丁,这些补丁可以被视为是视频中的小块,每个补丁捕捉了一小段时间内的空间结构,从而更好地理解和处理视频数据,使其适用于后续的模型训练和生成。
2.2.1、将视觉数据转为补丁:Turning visual data into patches
大型语言模型通过在互联网规模的数据上进行训练,获得了通用能力,这部分归功于它们使用的令牌能够优雅地统一不同形式的文本,包括代码、数学和各种自然语言。在这项工作中,研究人员思考了如何将这种通用能力应用于生成视觉数据的模型中。
与大型语言模型使用文本令牌不同的是,Sora模型使用了视觉补丁(visual patches)来处理视觉数据。与文本令牌类似,视觉补丁也具有高度可扩展性和有效性,特别适用于训练生成多种类型的视频和图像的模型。

2.2.2、视频压缩网络:Video compression network
Sora训练了一个网络用于降低视觉数据的维度。网络以原始视频作为输入,并输出一个时空上压缩的潜在表示。Sora在这个压缩的潜在空间上进行训练,并在其中生成视频。同时还训练了一个对应的解码器模型,将生成的潜在表示映射回像素空间。
简单来说,Sora将一段视频的内容压缩成一个更加紧凑、高效的形式(即降维)。这样, Sora就能在处理时更高效,同时仍保留足够的信息来重建原始视频。
2.2.3、时空潜在补丁:Spacetime latent patches
给定一个压缩的输入视频,Sora提取一系列时空补丁,这些补丁作为转换器令牌。这个方案也适用于图像,因为图像只是具有单帧的视频。基于补丁的表示使得Sora能够在变化分辨率、持续时间和宽高比的视频和图像上进行训练。在推断时,可以通过将随机初始化的补丁以适当大小的网格排列来控制生成视频的大小。
简单来说,Sora将视频分解成一个个小块, 这些小块含有视频中一小部分的空间和时间信息,就好像是对视频内容的详细“清单”,帮助Sora在之后的步骤中能针对性地处理视频的每一部分。
2.3、视频生成
2.3.1、将Transformer扩展到视频生成:Diffusion Transformers Scaling transformers for video generation
Sora是一种基于扩散模型的生成模型,它的工作原理是接收输入的含有噪声的补丁(例如图像的局部区域)以及一些条件信息(比如文本提示),然后通过训练来预测原始的“干净”补丁,即去除了噪声的补丁。这种模型的目的在于使得生成的图像更加清晰和真实。
值得注意的是,Sora采用了一种特殊的Transformer架构,即Diffusion Transformer(DiT),其模型结构如下:
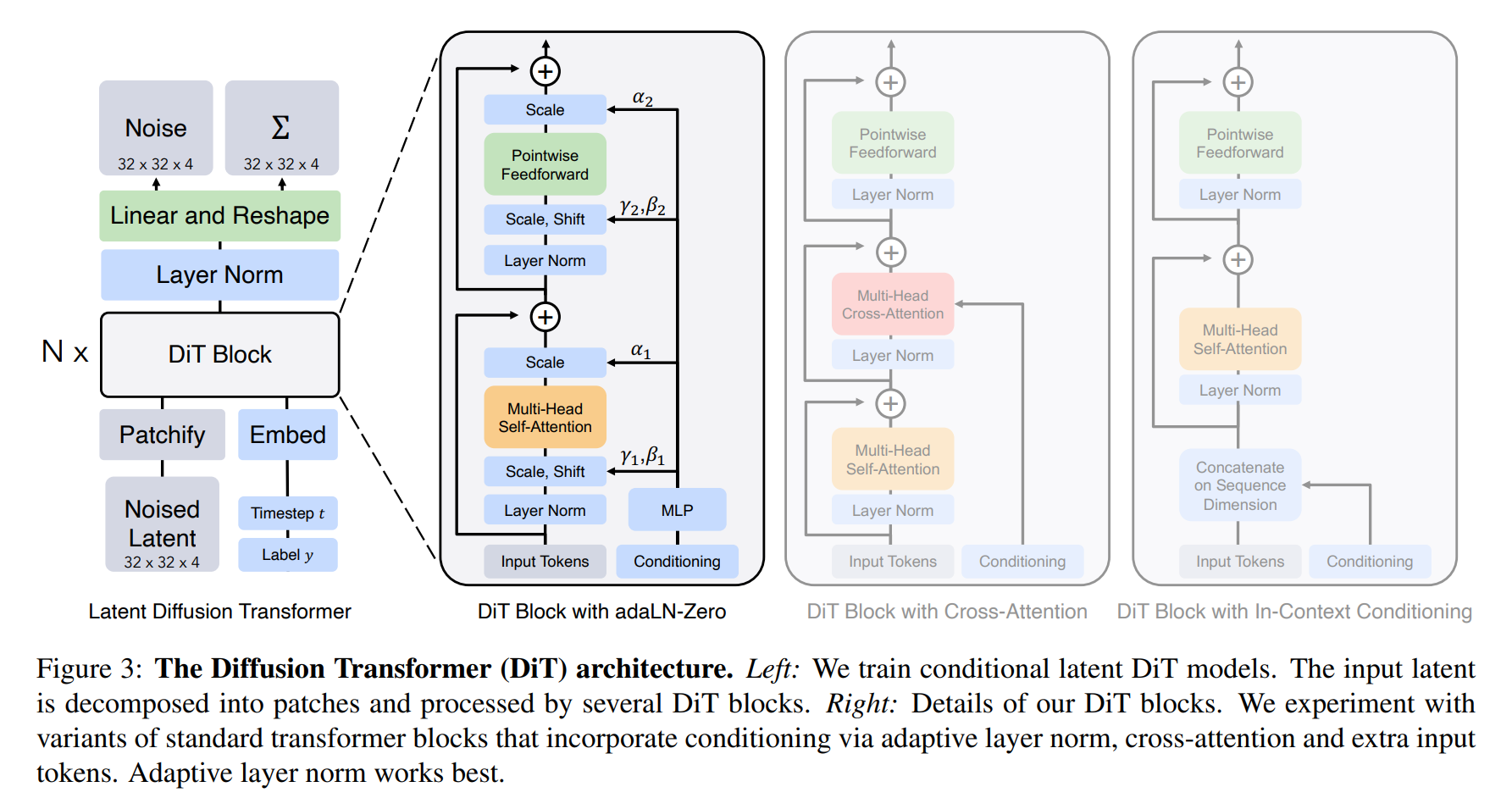
Diffusion Transformers(DiTs)是一种基于 Transformers的扩散模型。它们遵循 Vision Transformers(ViTs)的最佳实践,并被设计用于处理图像的扩散过程。
Diffusion Transformers将Transformer应用于扩散模型中,以实现更高效的图像生成。在传统的扩散模型中,通常需要额外的条件信息来处理噪声图像输入,具体来说,DiTs的设计包括以下几个方面:
- 上下文条件:DiTs将t和c的向量嵌入作为输入序列中的两个额外标记,并将其视为与图像标记相同的方式处理。这样可以在不改变标准Transformer架构的情况下保留其缩放属性。
- 混合基础方法:DiTs使用现成的卷积变分自编码器(VAE)和基于变换器的DDPM来生成非空间数据,如CLIP图像嵌入。
- 变体设计:DiTs引入了四种不同的Transformer变体,它们以不同的方式处理条件输入,对标准的ViT块设计进行了微小但重要的修改。
如果你对Diffusion Transformers的细节感兴趣,可以在评论留言,如果人多,可以后面再出一期Diffusion Transformers的架构详细解读。
话说回来,在Sora的研究工作中,研究人员发现Diffusion Transformers不仅在图像生成方面表现出色,而且在视频模型方面也非常有效。他们通过比较随着训练计算量增加而生成的视频样本,发现随着训练的进行,样本的质量显著提高。这意味着Diffusion Transformers在处理视频数据时能够有效地学习并生成更高质量的视频内容,这对于视频生成领域具有重要的意义。
2.4、效果优化
OpenAI还使用了一些优化技术使模型拥有可变的持续时间、分辨率、宽高比等等特性,包括:灵活的采样方法、改善构图和画面组成等技术,由于相关资料较少,这里暂时不展开,如果感兴趣,也可以在评论留言。

2.5、自然语言理解方面:Language understanding
在自然语言理解方面,OpenAI应用了DALL·E 3中引入的重新标题化技术。重新标题化技术通过训练一个高度描述性的标题生成模型,为训练集中的所有视频生成文本标题。这样做的好处是,使用高度描述性的视频标题进行训练可以提高文本的准确性,可以使模型更好地理解和生成视频内容,从而提升生成视频的质量和准确性。
类似于DALL·E 3,作者还利用了GPT将用户简短的提示转换为更详细的标题,然后将其发送给视频模型。这使得Sora能够生成准确遵循用户提示的高质量视频。
这两种方法让文本到视频的训练的Prompt充实了不少,从而更容易训练。
三、Sora目前的限制
在技术报告中,作者还提到,Sora依然存在许多限制。例如,它不能准确地模拟许多基本交互的物理现象,比如玻璃破碎。其他的交互,比如吃食物,也不总是能够正确地改变物体状态。我们在我们的主页上列举了模型的其他常见失败模式,比如在长时间样本中出现的不连贯性,或者物体的突然出现。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。