这是璩静的简历,4条短视频丢了百度千万年薪的工作

项目中什么地方使用了redis缓存,redis为什么快?
在技术派实战项目中,很多地方都用到了 Redis,比如说用户活跃排行榜、作者白名单、常用热点数据(文章标签、文章分类)、计数统计(文章点赞收藏评论数粉丝数)等等。
技术派专栏
像用户活跃榜,主要是基于 Redis 的 Zset 实现的,可以根据 score(分值)进行排序,实时展示用户的活跃度。

技术派阅读活跃榜
当然了,这块也可以使用 Redis 的 zrevrange,直接倒序展示前 8 名用户。
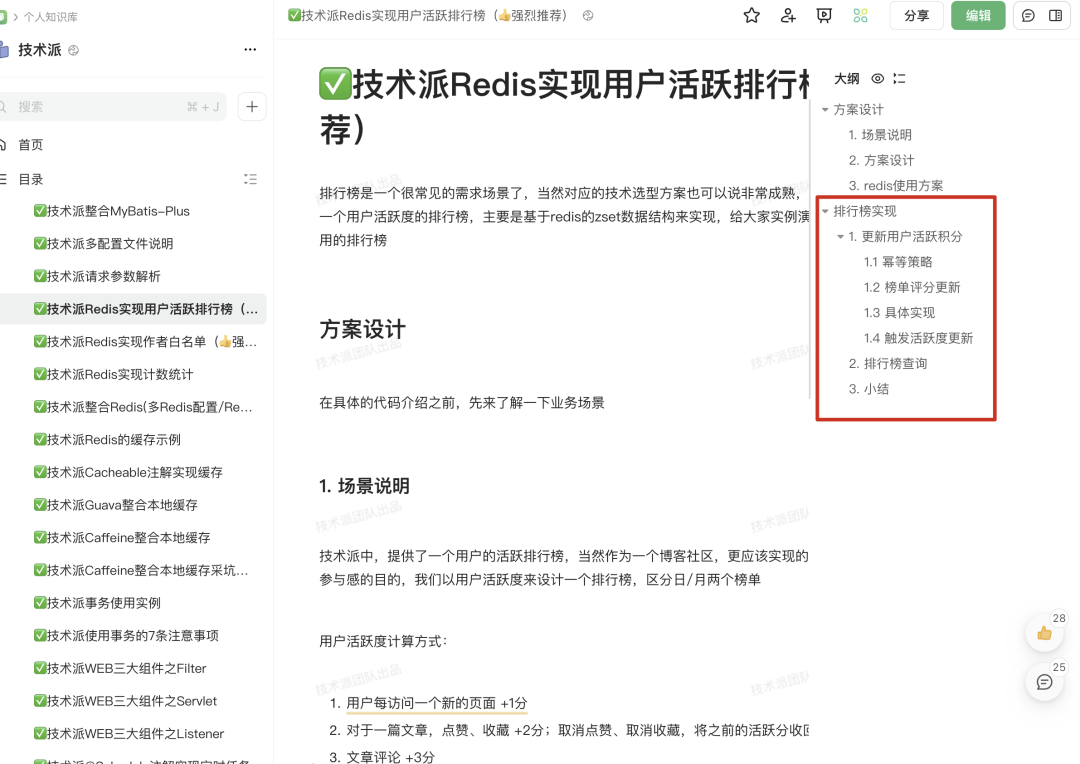
Redis 为什么快呢?
Redis 的速度⾮常快,单机的 Redis 就可以⽀撑每秒十几万的并发,性能是 MySQL 的⼏⼗倍。速度快的原因主要有⼏点:
①、基于内存的数据存储,Redis 将数据存储在内存当中,使得数据的读写操作避开了磁盘 I/O。而内存的访问速度远超硬盘,这是 Redis 读写速度快的根本原因。
②、单线程模型,Redis 使用单线程模型来处理客户端的请求,这意味着在任何时刻只有一个命令在执行。这样就避免了线程切换和锁竞争带来的消耗。
③、IO 多路复⽤,基于 Linux 的 select/epoll 机制。该机制允许内核中同时存在多个监听套接字和已连接套接字,内核会一直监听这些套接字上的连接请求或者数据请求,一旦有请求到达,就会交给 Redis 处理,就实现了所谓的 Redis 单个线程处理多个 IO 读写的请求。
三分恶面渣逆袭:Redis使用IO多路复用和自身事件模型
④、高效的数据结构,Redis 提供了多种高效的数据结构,如字符串(String)、列表(List)、集合(Set)、有序集合(Sorted Set)等,这些数据结构经过了高度优化,能够支持快速的数据操作。
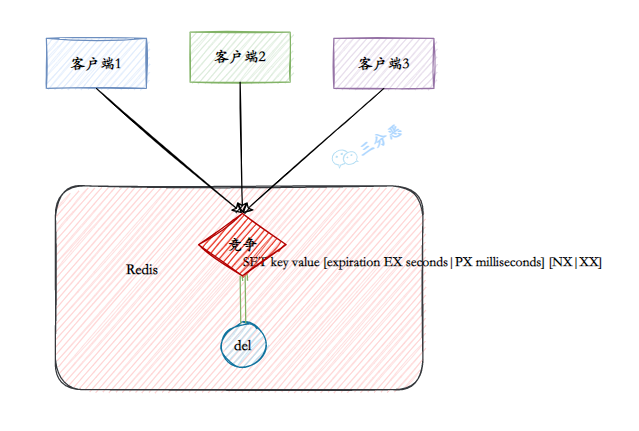
redis分布式锁的实现原理?setnx?
Redis 实现分布式锁的本质,就是在 Redis 里面占一个“茅坑”,当别的进程也来占坑时,发现已经有进程蹲在那里了,就只好放弃或者稍后再试。
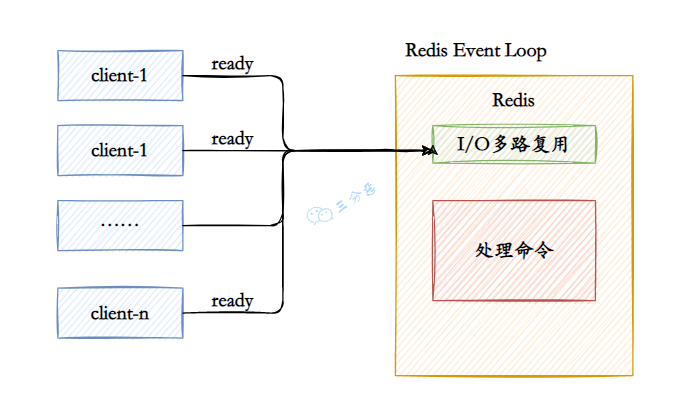
①、V1:setnx 命令
占坑一般使用 setnx(set if not exists) 指令,只允许被一个客户端占坑。先来先占,用完了再调用 del 指令释放茅坑。
三分恶面渣逆袭:setnx(set if not exists)
> setnx lock:fighter true
OK
... do something critical ...
> del lock:fighter
(integer) 1
但是有个问题,如果逻辑执行到中间出现异常了,可能会导致 del 指令没有被执行,这样就会出现死锁,锁永远得不到释放。
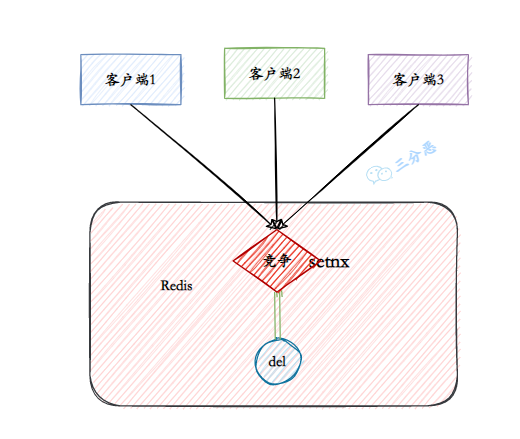
②、V2:锁超时释放
所以在拿到锁之后,可以给锁加上一个过期时间,比如 5s,这样即使中间出现异常也可以保证 5 秒之后锁会自动释放。
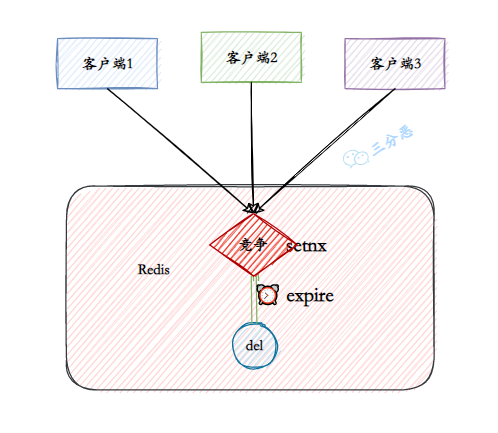
三分恶面渣逆袭:锁超时释放
> setnx lock:fighter true
OK
> expire lock:fighter 5
... do something critical ...
> del lock:fighter
(integer) 1
但是以上逻辑还有问题:如果在 setnx 和 expire 之间进程突然挂掉了,可能是因为机器断电或者被人为杀掉了,就会导致 expire 无法执行,也会造成死锁。
这种问题的根源就在于 setnx 和 expire 是两条指令,不是原子指令。如果这两条指令可以一起执行就不会出现问题了,对吧?
③、V3:set 指令
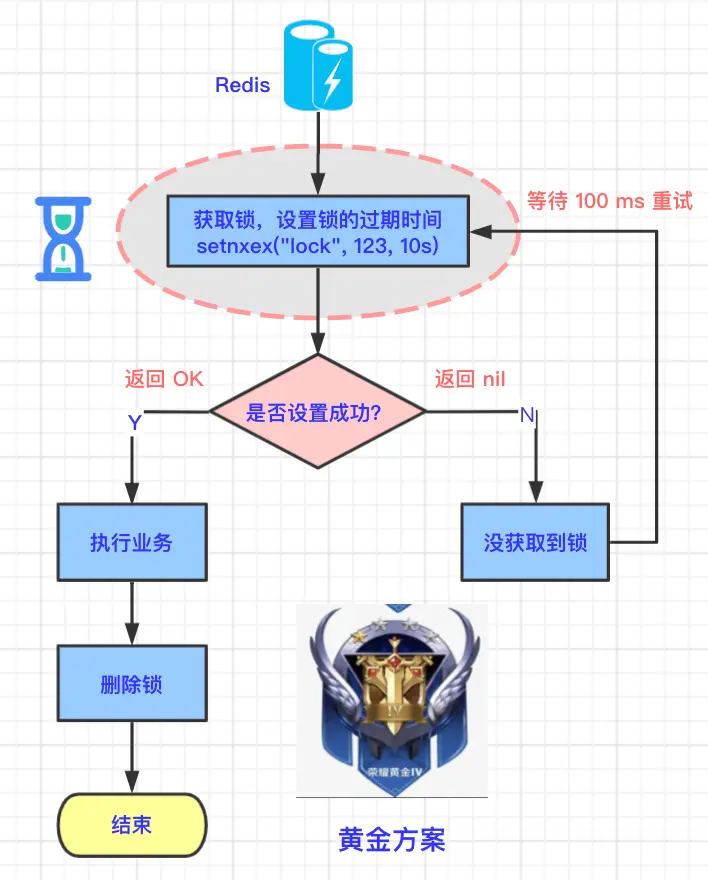
上面的问题在 Redis 2.8 版本中得到了解决,这个版本加入了 set 指令的扩展参数,使得 setnx 和 expire 指令可以一起执行。
三分恶面渣逆袭:set原子指令
> set lock:fighter3 true ex 5 nx
OK ... do something critical ...
> del lock:fighter3
SET命令用于设置键值对。lock:fighter3是锁的键名。true是设置给键lock:fighter3的值。EX 5设置这个键的过期时间为 5 秒。这意味着如果锁的持有者没有在 5 秒内释放锁(比如因为崩溃或其他原因),锁会自动被释放,以防止死锁。NX保证只有当lock:fighter3不存在时,即锁未被其他客户端持有时,当前操作才会成功设置键,从而实现加锁。如果锁已经存在,则命令不会执行任何操作。
悟空聊架构 Redis 分布式锁
上面这段指令就是 setnx 和 expire 组合在一起的原子指令,算是比较完善的一个分布式锁了。
hashmap的底层实现原理、put()方法实现流程、扩容机制?
JDK 8 中 HashMap 的数据结构是数组+链表+红黑树。
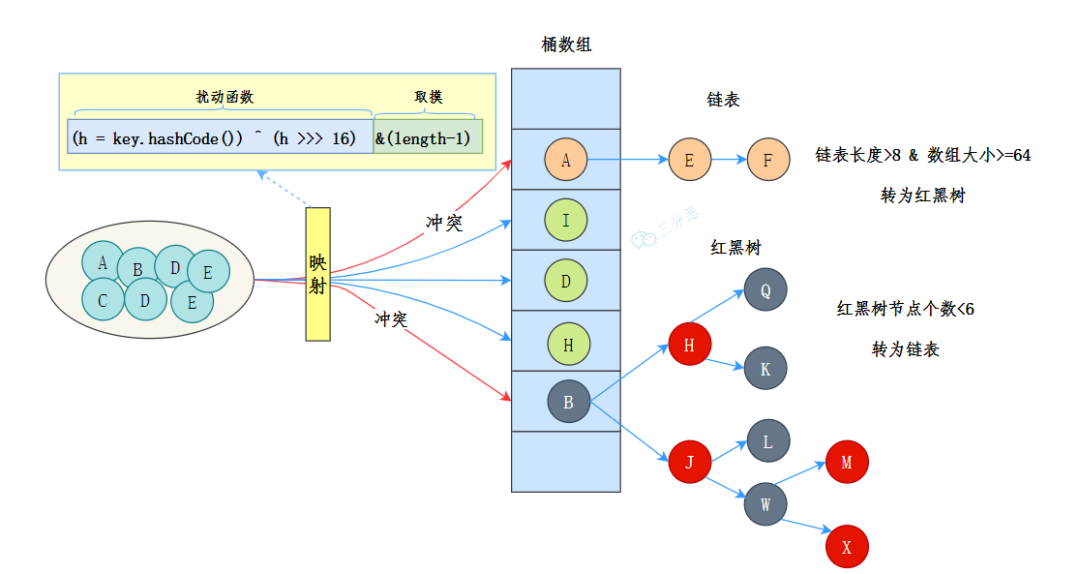
三分恶面渣逆袭:JDK 8 HashMap 数据结构示意图
HashMap 的核心是一个动态数组(Node[] table),用于存储键值对。这个数组的每个元素称为一个“桶”(Bucket),每个桶的索引是通过对键的哈希值进行哈希函数处理得到的。
当多个键经哈希处理后得到相同的索引时,会发生哈希冲突。HashMap 通过链表来解决哈希冲突——即将具有相同索引的键值对通过链表连接起来。
不过,链表过长时,查询效率会比较低,于是当链表的长度超过 8 时(且数组的长度大于 64),链表就会转换为红黑树。红黑树的查询效率是 O(logn),比链表的 O(n) 要快。数组的查询效率是 O(1)。
HashMap 的 put 流程知道吗?
直接看流程图。
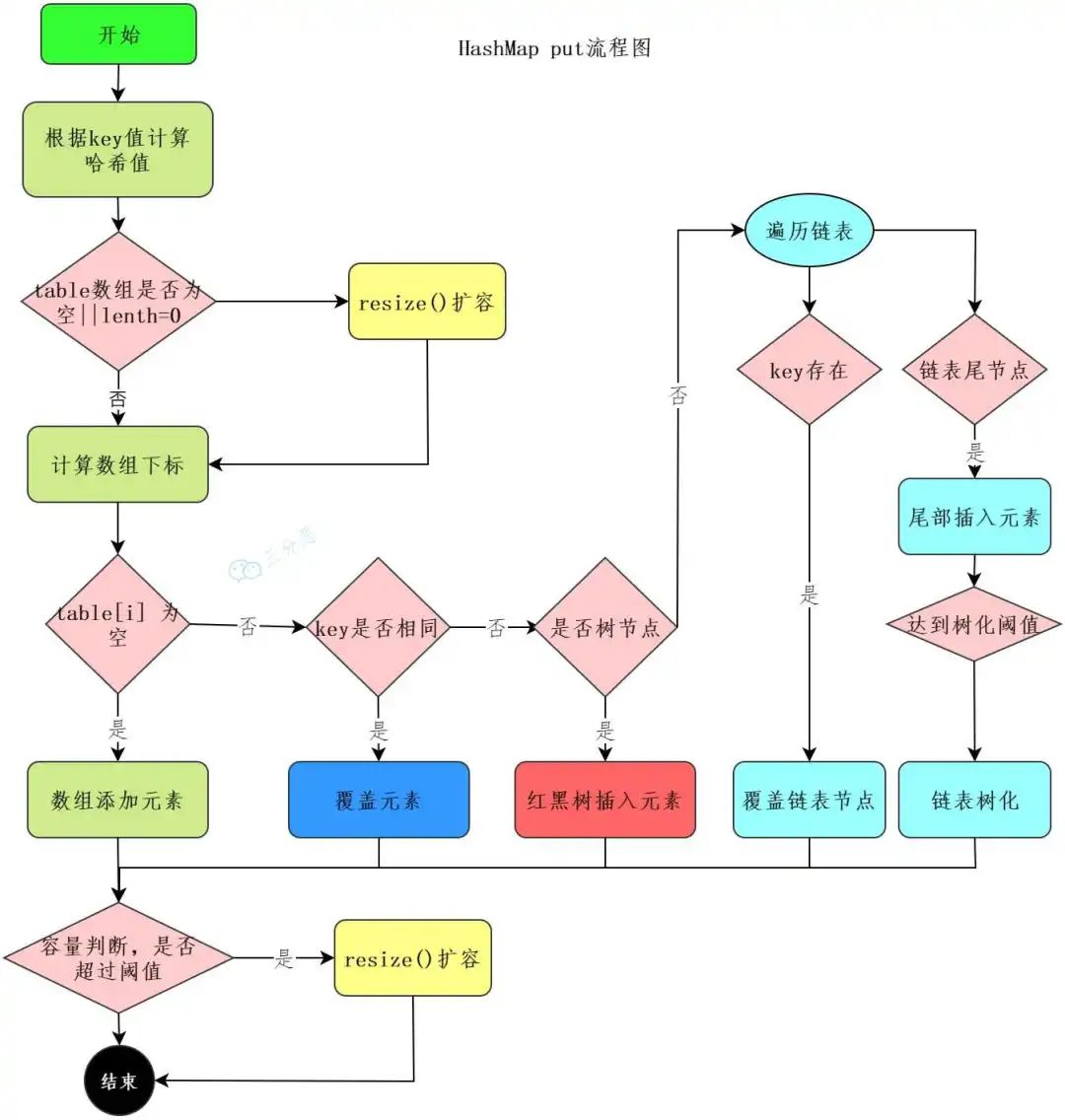
三分恶面渣逆袭:HashMap插入数据流程图
第一步,通过 hash 方法计算 key 的哈希值。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
第二步,数组进行第一次扩容。
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
第三步,根据哈希值计算 key 在数组中的下标,如果对应下标正好没有存放数据,则直接插入。
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
如果对应下标已经有数据了,就需要判断是否为相同的 key,是则覆盖 value,否则需要判断是否为树节点,是则向树中插入节点,否则向链表中插入数据。
注意,在链表中插入节点的时候,如果链表长度大于等于 8,则需要把链表转换为红黑树。
所有元素处理完后,还需要判断是否超过阈值threshold,超过则扩容。
那扩容机制了解吗?
扩容时,HashMap 会创建一个新的数组,其容量是原数组容量的两倍。
然后将键值对放到新计算出的索引位置上。一部分索引不变,另一部分索引为“原索引+旧容量”。
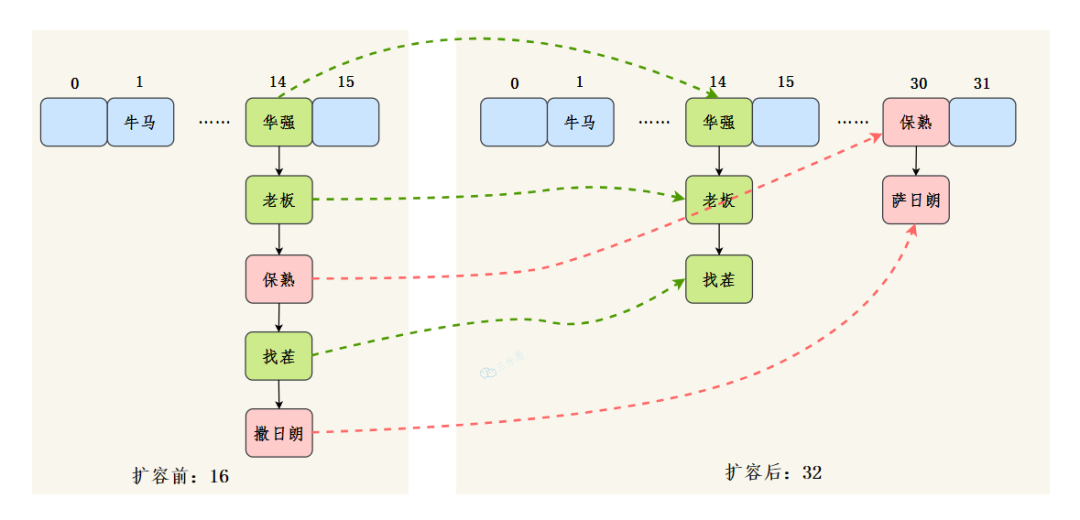
三分恶面渣逆袭:扩容节点迁移示意图
继承和抽象的区别
继承是一种允许子类继承父类属性和方法的机制。通过继承,子类可以重用父类的代码。
抽象是一种隐藏复杂性和只显示必要部分的技术。在面向对象编程中,抽象可以通过抽象类和接口实现。
java如何启动多线程,有哪些方式?
在 Java 中,启动一个新的线程应该调用其start()方法,而不是直接调用run()方法。
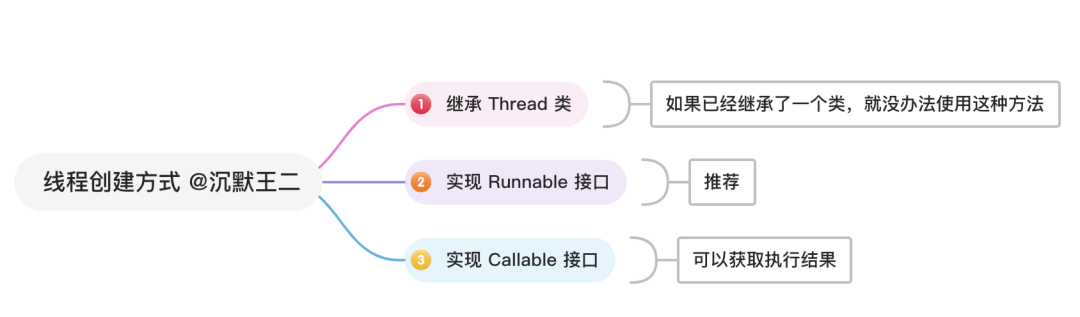
java如何创建线程?每次都要创建新线程来实现异步操作,很繁琐,有了解线程池吗?
Java 中创建线程主要有三种方式,分别为继承 Thread 类、实现 Runnable 接口、实现 Callable 接口。
二哥的 Java 进阶之路
什么是线程池?
线程池,简单来说,就是一个管理线程的池子。
三分恶面渣逆袭:管理线程的池子
①、频繁地创建和销毁线程会消耗系统资源,线程池能够复用已创建的线程。
②、提高响应速度,当任务到达时,任务可以不需要等待线程创建就立即执行。
③、线程池支持定时执行、周期性执行、单线程执行和并发数控制等功能。
你有哪些熟悉的设计模式?
单例模式,在需要控制资源访问,如配置管理、连接池管理时经常使用单例模式。它确保了全局只有一个实例,并提供了一个全局访问点。
在有多种算法或策略可以切换使用的情况下,我会使用策略模式。像技术派实战项目中,我就使用策略模式对接了讯飞星火、OpenAI 等多家 API 服务,实现了一个可以自由切换 AI 服务的对话聊天服务。
技术派派聪明 AI 助手
这样就不用在代码中写 if/else 判断,而是将不同的 AI 服务封装成不同的策略类,通过工厂模式创建不同的 AI 服务实例,从而实现 AI 服务的动态切换。
后面想添加新的 AI 服务,只需要增加一个新的策略类,不需要修改原有代码,这样就提高了代码的可扩展性。
MySQL索引为什么使用B+树而不是用别的数据结构?
普通二叉树存在退化的情况,如果它退化成链表,就相当于全表扫描。
为什么不用平衡二叉树呢?
读取数据的时候,是从磁盘先读到内存。平衡二叉树的每个节点只存储一个键值和数据,而 B+ 树可以存储更多的节点数据,树的高度也会降低,因此读取磁盘的次数就会下降,查询效率就快。
为什么用 B+ 树而不用 B 树呢?
B+ 树相比较 B 树,有这些优势:
①、更高的查询效率
B+树的所有值(数据记录或指向数据记录的指针)都存在于叶子节点,并且叶子节点之间通过指针连接,形成一个有序链表。
极客时间:B+树
这种结构使得 B+树非常适合进行范围查询——一旦到达了范围的开始位置,接下来的元素可以通过遍历叶子节点的链表顺序访问,而不需要回到树的上层。如 SQL 中的 ORDER BY 和 BETWEEN 查询。
极客时间:B 树
而 B 树的数据分布在整个树中,进行范围查询时可能需要遍历树的多个层级。
②、更高的空间利用率
在 B+树中,非叶子节点不存储数据,只存储键值,这意味着非叶子节点可以拥有更多的键,从而有更多的分叉。
这导致树的高度更低,进一步降低了查询时磁盘 I/O 的次数,因为每一次从一个节点到另一个节点的跳转都可能涉及到磁盘 I/O 操作。
③、查询效率更稳定
B+树中所有叶子节点深度相同,所有数据查询路径长度相等,保证了每次搜索的性能稳定性。而在 B 树中,数据可以存储在内部节点,不同的查询可能需要不同深度的搜索。
B+树的页是单向链表还是双向链表?如果从大值向小值检索,如何操作?
B+树的叶子节点是通过双向链表连接的,这样可以方便范围查询和反向遍历。
- 当执行范围查询时,可以从范围的开始点或结束点开始,向前或向后遍历,这使得查询更为灵活。
- 在需要对数据进行逆序处理时,双向链表非常有用。
如果需要在 B+树中从大值向小值进行检索,可以按以下步骤操作:
- 定位到最右侧节点:首先,找到包含最大值的叶子节点。这通常通过从根节点开始向右遍历树的方式实现。
- 反向遍历:一旦定位到了最右侧的叶子节点,可以利用叶节点间的双向链表向左遍历。
SpringBoot基本原理
Spring Boot 是一个开源的、用于简化 Spring 应用初始化和开发过程的框架。提供了一套默认配置,约定优于配置,来帮助我们快速搭建 Spring 项目骨架,极大地提高了我们的生产效率,再也不用为 Spring 的繁琐配置而烦恼了。
以前的 Spring 开发需要配置大量的 xml 文件,并且需要引入大量的第三方 jar 包,还需要手动放到 classpath 下。

SpringBoot图标
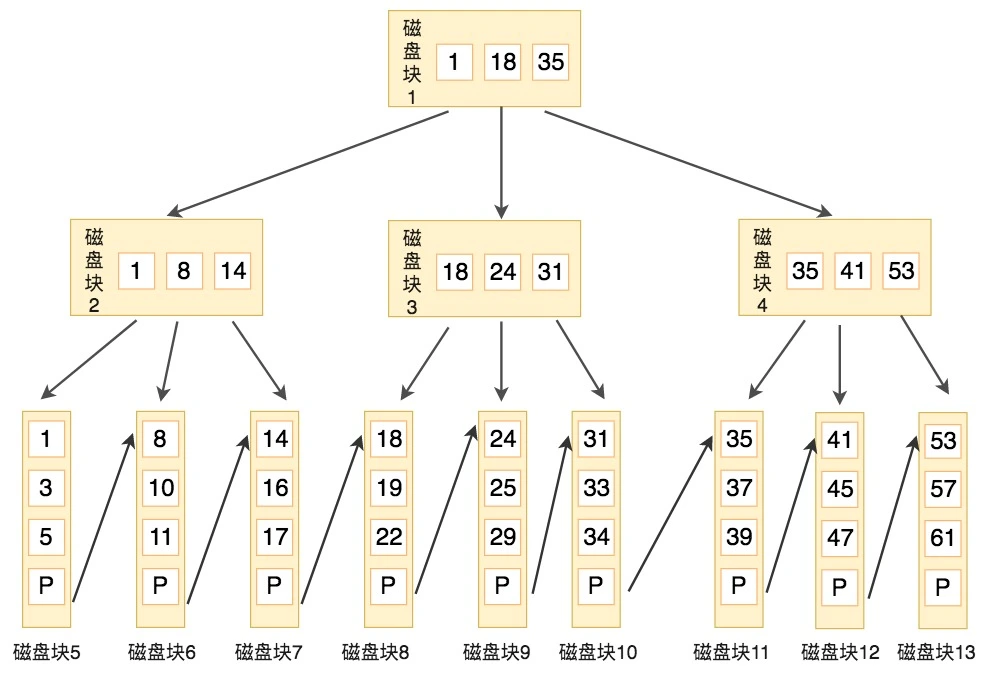
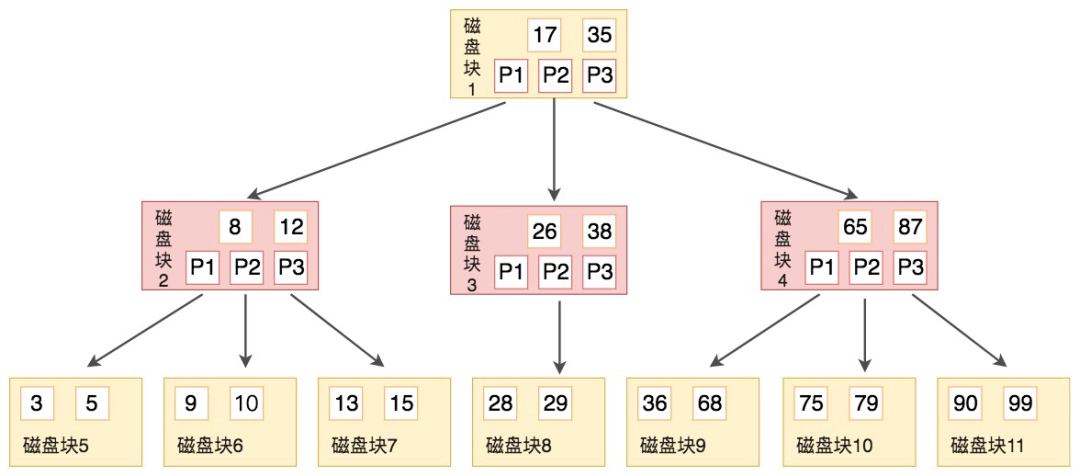
SpringBoot如何实现自动装配
在 Spring 中,自动装配是指容器利用反射技术,根据 Bean 的类型、名称等自动注入所需的依赖。
在 Spring Boot 中,开启自动装配的注解是@EnableAutoConfiguration。
二哥的 Java 进阶之路
Spring Boot 为了进一步简化,直接通过 @SpringBootApplication 注解一步搞定,这个注解包含了 @EnableAutoConfiguration 注解。
二哥的 Java 进阶之路
①、@EnableAutoConfiguration 只是一个简单的注解,但是它的背后却是一个非常复杂的自动装配机制,核心是AutoConfigurationImportSelector 类。
@AutoConfigurationPackage //将main同级的包下的所有组件注册到容器中
@Import({AutoConfigurationImportSelector.class}) //加载自动装配类 xxxAutoconfiguration
public @interface EnableAutoConfiguration {
String ENABLED_OVERRIDE_PROPERTY = "spring.boot.enableautoconfiguration";
Class<?>[] exclude() default {};
String[] excludeName() default {};
}
②、AutoConfigurationImportSelector实现了ImportSelector接口,这个接口的作用就是收集需要导入的配置类,配合@Import()就将相应的类导入到 Spring 容器中。
二哥的 Java 进阶之路
③、获取注入类的方法是 selectImports(),它实际调用的是getAutoConfigurationEntry(),这个方法是获取自动装配类的关键。
protected AutoConfigurationEntry getAutoConfigurationEntry(AnnotationMetadata annotationMetadata) {
// 检查自动配置是否启用。如果@ConditionalOnClass等条件注解使得自动配置不适用于当前环境,则返回一个空的配置条目。
if (!isEnabled(annotationMetadata)) {
return EMPTY_ENTRY;
}
// 获取启动类上的@EnableAutoConfiguration注解的属性,这可能包括对特定自动配置类的排除。
AnnotationAttributes attributes = getAttributes(annotationMetadata);
// 从spring.factories中获取所有候选的自动配置类。这是通过加载META-INF/spring.factories文件中对应的条目来实现的。
List<String> configurations = getCandidateConfigurations(annotationMetadata, attributes);
// 移除配置列表中的重复项,确保每个自动配置类只被考虑一次。
configurations = removeDuplicates(configurations);
// 根据注解属性解析出需要排除的自动配置类。
Set<String> exclusions = getExclusions(annotationMetadata, attributes);
// 检查排除的类是否存在于候选配置中,如果存在,则抛出异常。
checkExcludedClasses(configurations, exclusions);
// 从候选配置中移除排除的类。
configurations.removeAll(exclusions);
// 应用过滤器进一步筛选自动配置类。过滤器可能基于条件注解如@ConditionalOnBean等来排除特定的配置类。
configurations = getConfigurationClassFilter().filter(configurations);
// 触发自动配置导入事件,允许监听器对自动配置过程进行干预。
fireAutoConfigurationImportEvents(configurations, exclusions);
// 创建并返回一个包含最终确定的自动配置类和排除的配置类的AutoConfigurationEntry对象。
return new AutoConfigurationEntry(configurations, exclusions);
}
Spring Boot 的自动装配原理依赖于 Spring 框架的依赖注入和条件注册,通过这种方式,Spring Boot 能够智能地配置 bean,并且只有当这些 bean 实际需要时才会被创建和配置。
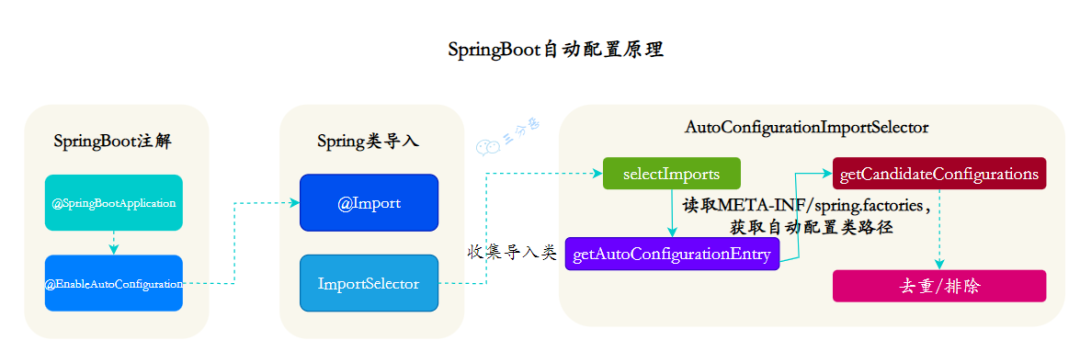
三分恶面渣逆袭:SpringBoot自动配置原理
Spring中bean生命周期
Spring 中 Bean 的生命周期大致分为四个阶段:实例化(Instantiation)、属性赋值(Populate)、初始化(Initialization)、销毁(Destruction)。
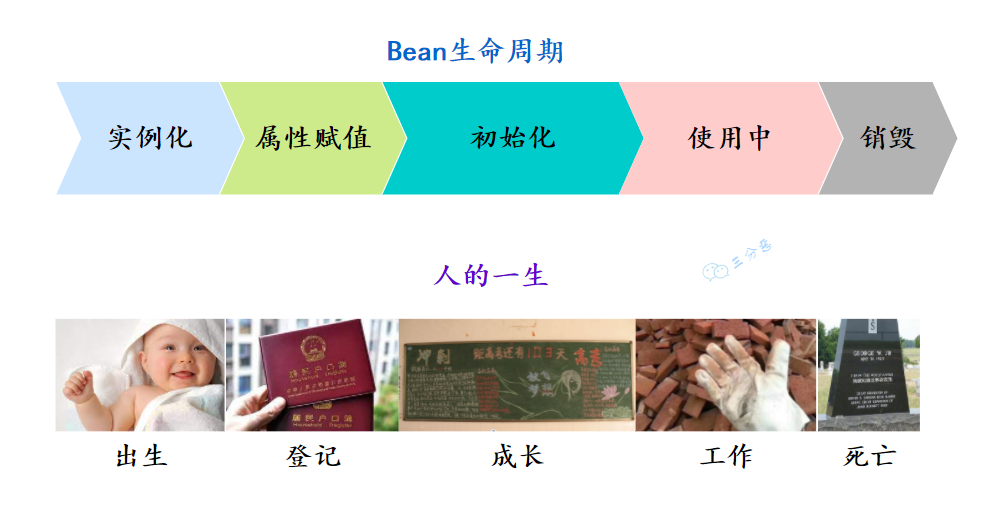
三分恶面渣逆袭:Bean生命周期四个阶段
对应的完整步骤如下图所示:
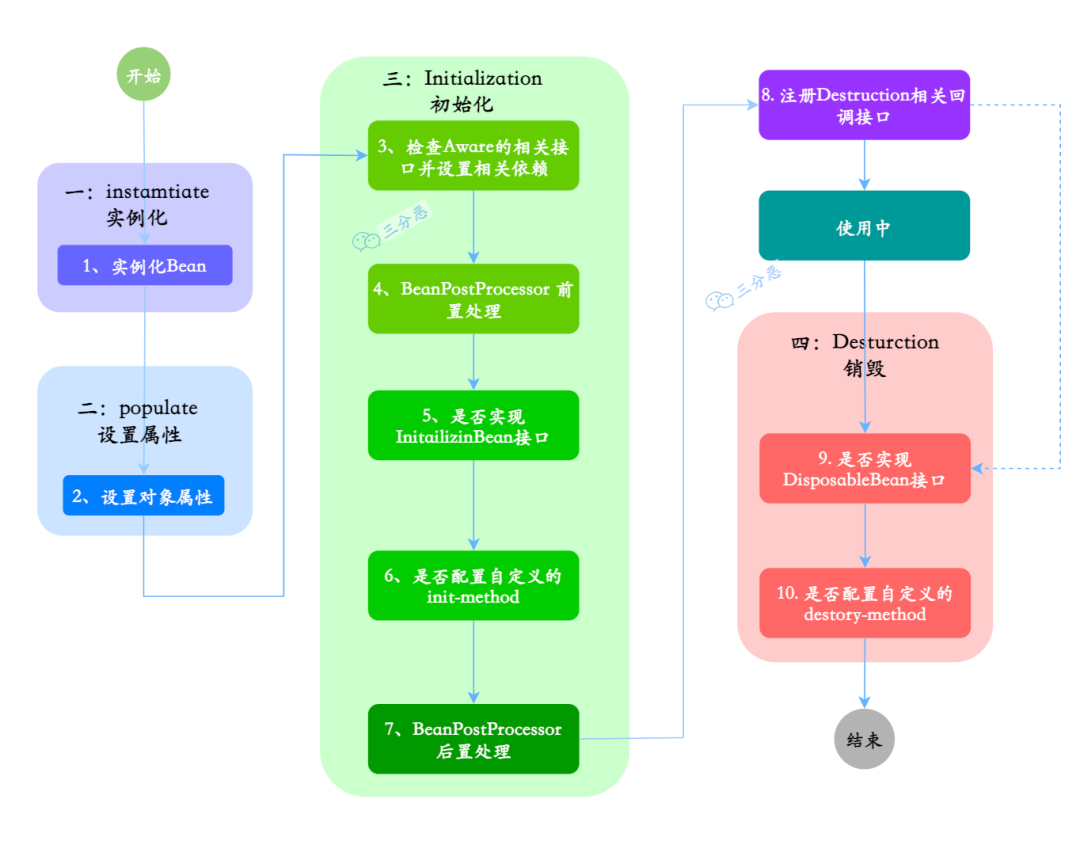
三分恶面渣逆袭:Spring Bean生命周期
- 实例化:Spring 容器根据 Bean 的定义创建 Bean 的实例,相当于执行构造方法,也就是 new 一个对象。
- 属性赋值:相当于执行 setter 方法为字段赋值。
- 初始化:初始化阶段允许执行自定义的逻辑,比如设置某些必要的属性值、开启资源、执行预加载操作等,以确保 Bean 在使用之前是完全配置好的。
- 销毁:相当于执行
= null,释放资源。
Spring如何解决循环依赖?
我们知道,Singleton 的 Bean 要初始化完成,需要经历这三步:
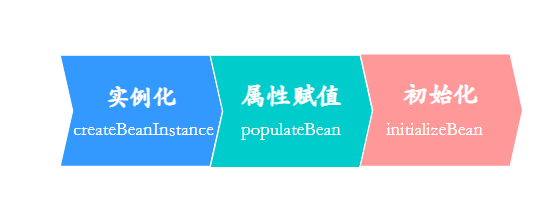
三分恶面渣逆袭:Bean初始化步骤
注入发生在第二步,属性赋值,Spring 可以在这一步通过三级缓存来解决了循环依赖:
- 一级缓存 :
Map<String,Object>singletonObjects,单例池,用于保存实例化、属性赋值(注入)、初始化完成的 bean 实例 - 二级缓存 :
Map<String,Object>earlySingletonObjects,早期曝光对象,用于保存实例化完成的 bean 实例 - 三级缓存 :
Map<String,ObjectFactory<?>>singletonFactories,早期曝光对象工厂,用于保存 bean 创建工厂,以便后面有机会创建代理对象。
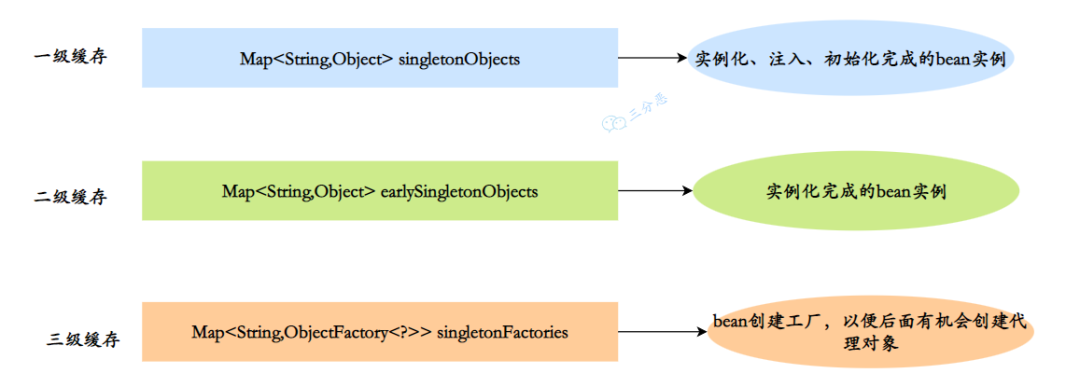
三分恶面渣逆袭:三级缓存
我们来看一下三级缓存解决循环依赖的过程:
当 A、B 两个类发生循环依赖时:
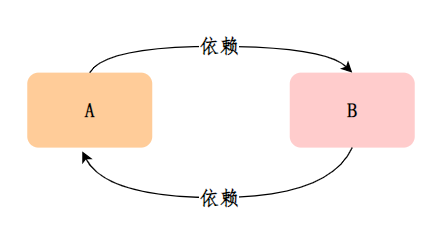
三分恶面渣逆袭:循环依赖
A 实例的初始化过程:
①、创建 A 实例,实例化的时候把 A 的对象⼯⼚放⼊三级缓存,表示 A 开始实例化了,虽然我这个对象还不完整,但是先曝光出来让大家知道。
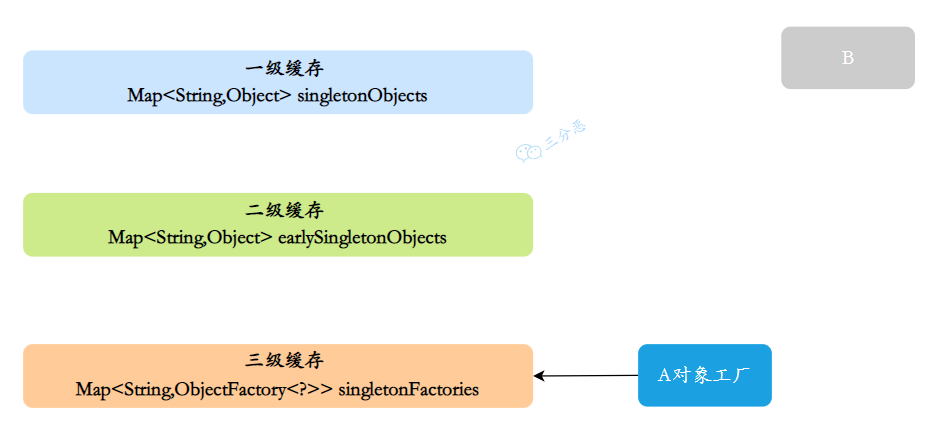
三分恶面渣逆袭:A 对象工厂
②、A 注⼊属性时,发现依赖 B,此时 B 还没有被创建出来,所以去实例化 B
③、同样,B 注⼊属性时发现依赖 A,它就从缓存里找 A 对象。依次从⼀级到三级缓存查询 A。
发现可以从三级缓存中通过对象⼯⼚拿到 A,虽然 A 不太完善,但是存在,就把 A 放⼊⼆级缓存,同时删除三级缓存中的 A,此时,B 已经实例化并且初始化完成了,把 B 放入⼀级缓存。
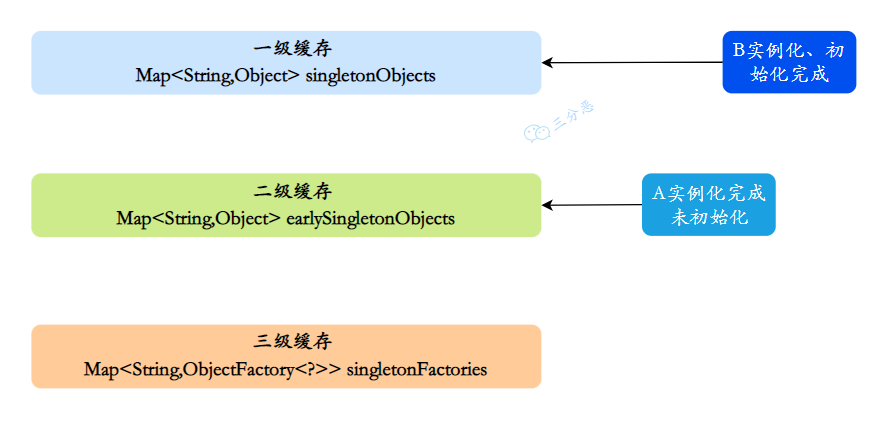
三分恶面渣逆袭:放入一级缓存
④、接着 A 继续属性赋值,顺利从⼀级缓存拿到实例化且初始化完成的 B 对象,A 对象创建也完成,删除⼆级缓存中的 A,同时把 A 放⼊⼀级缓存
⑤、最后,⼀级缓存中保存着实例化、初始化都完成的 A、B 对象
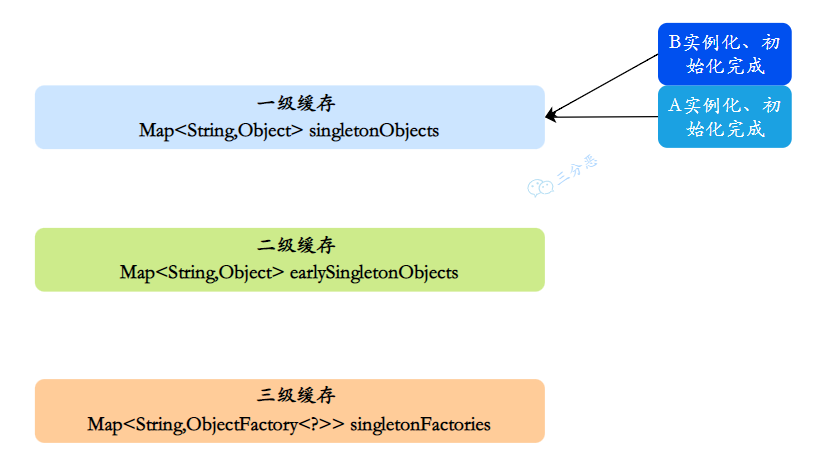
三分恶面渣逆袭:AB 都好了
到此,我们就知道为什么 Spring 能解决 setter 注入的循环依赖了,因为实例化和属性赋值是分开的,里面有操作的空间。
如果都是构造器注入的话,那么都得在实例化这一步完成注入,没有可操作的空间。
参考链接
- 三分恶的面渣逆袭:https://javabetter.cn/sidebar/sanfene/nixi.html
- 二哥的 Java 进阶之路:https://javabetter.cn