YOLOv8优化创新:backbone改进 | 微软新作StarNet:超强轻量级Backbone | CVPR 2024
原创YOLOv8优化创新:backbone改进 | 微软新作StarNet:超强轻量级Backbone | CVPR 2024
原创
💡💡💡创新点:star operation(元素乘法)在无需加宽网络下,将输入映射到高维非线性特征空间的能力,这就是StarNet的核心创新,在紧凑的网络结构和较低的能耗下展示了令人印象深刻的性能和低延迟
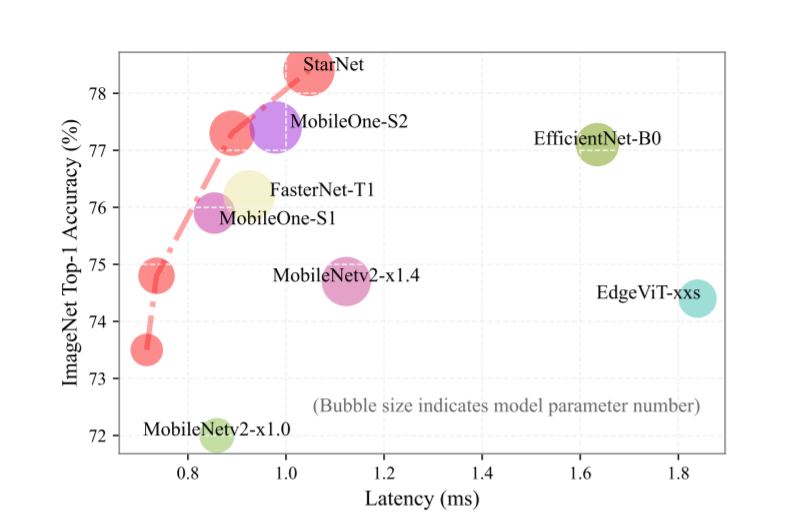
💡💡💡如何跟YOLOv8结合:替代YOLOv8的backbone
1.原理介绍

论文:https://arxiv.org/pdf/2403.19967
摘要:最近的研究引起了人们对网络设计中尚未开发的“星型操作”(元素智能乘法)潜力的关注。虽然有很多直观的解释,但其应用背后的基本原理在很大程度上仍未被探索。我们的研究试图揭示明星手术将输入映射到高维、非线性特征空间的能力——类似于核技巧——无需扩大网络。我们进一步介绍了StarNet,一个简单而强大的原型,在紧凑的网络结构和高效的预算下展示了令人印象深刻的性能和低延迟。就像天上的星星一样,星星的运作看起来不起眼,但却蕴藏着巨大的潜力。
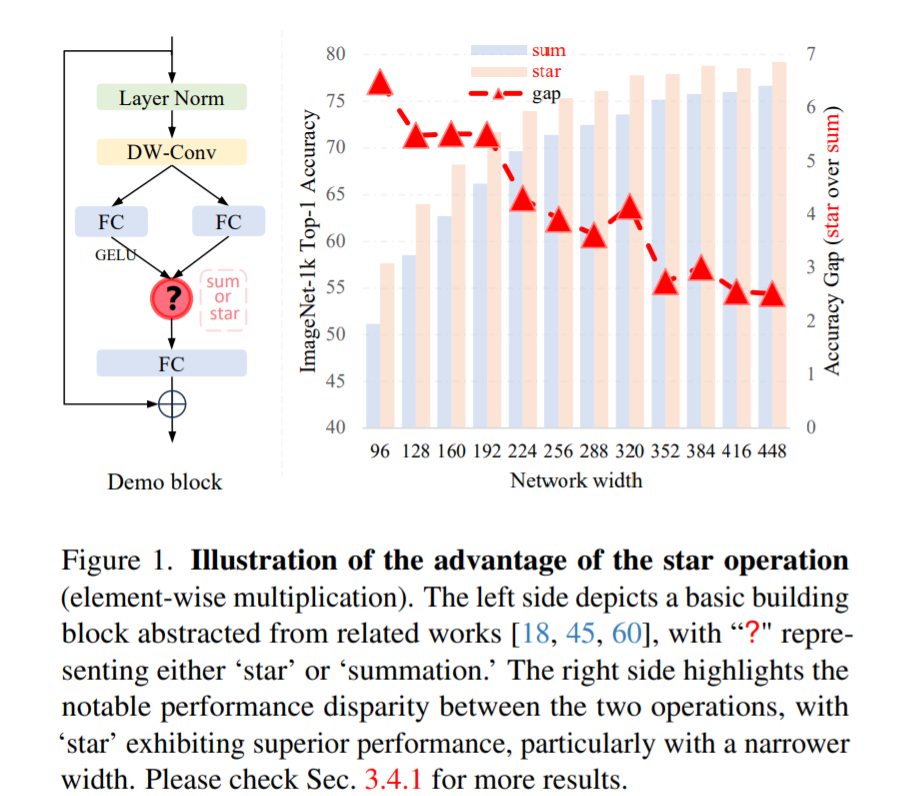
为了便于说明,构建了一个用于图像分类的demo block,如图 1 左侧所示。通过在stem层后堆叠多个demo block,论文构建了一个名为DemoNet的简单模型。保持所有其他因素不变,论文观察到逐元素乘法(star operation)在性能上始终优于求和,如图 1 右侧所示。
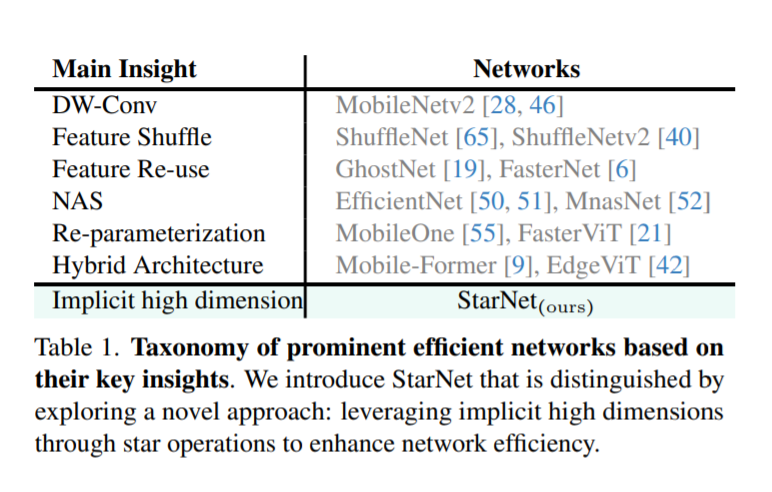
通过元素乘法融合不同的子空间特征的学习范式越来越受到关注,论文将这种范例称为star operation(由于元素乘法符号类似于星形)。
2. starnet加入YOLOv8
2.1 新建ultralytics/nn/backbone/starnet.py
核心代码
"""
Implementation of Prof-of-Concept Network: StarNet.
We make StarNet as simple as possible [to show the key contribution of element-wise multiplication]:
- like NO layer-scale in network design,
- and NO EMA during training,
- which would improve the performance further.
Created by: Xu Ma (Email: ma.xu1@northeastern.edu)
Modified Date: Mar/29/2024
"""
import torch
import torch.nn as nn
from timm.models.layers import DropPath, trunc_normal_
from timm.models.registry import register_model
from ultralytics.nn.modules import (Conv, Bottleneck,C2f)
model_urls = {
"starnet_s1": "https://github.com/ma-xu/Rewrite-the-Stars/releases/download/checkpoints_v1/starnet_s1.pth.tar",
"starnet_s2": "https://github.com/ma-xu/Rewrite-the-Stars/releases/download/checkpoints_v1/starnet_s2.pth.tar",
"starnet_s3": "https://github.com/ma-xu/Rewrite-the-Stars/releases/download/checkpoints_v1/starnet_s3.pth.tar",
"starnet_s4": "https://github.com/ma-xu/Rewrite-the-Stars/releases/download/checkpoints_v1/starnet_s4.pth.tar",
}
class ConvBN(torch.nn.Sequential):
def __init__(self, in_planes, out_planes, kernel_size=1, stride=1, padding=0, dilation=1, groups=1, with_bn=True):
super().__init__()
self.add_module('conv', torch.nn.Conv2d(in_planes, out_planes, kernel_size, stride, padding, dilation, groups))
if with_bn:
self.add_module('bn', torch.nn.BatchNorm2d(out_planes))
torch.nn.init.constant_(self.bn.weight, 1)
torch.nn.init.constant_(self.bn.bias, 0)
class StarNetBlock(nn.Module):
def __init__(self, dim, mlp_ratio=3, drop_path=0.):
super().__init__()
self.dwconv = ConvBN(dim, dim, 7, 1, (7 - 1) // 2, groups=dim, with_bn=True)
self.f1 = ConvBN(dim, mlp_ratio * dim, 1, with_bn=False)
self.f2 = ConvBN(dim, mlp_ratio * dim, 1, with_bn=False)
self.g = ConvBN(mlp_ratio * dim, dim, 1, with_bn=True)
self.dwconv2 = ConvBN(dim, dim, 7, 1, (7 - 1) // 2, groups=dim, with_bn=False)
self.act = nn.ReLU6()
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
input = x
x = self.dwconv(x)
x1, x2 = self.f1(x), self.f2(x)
x = self.act(x1) * x2
x = self.dwconv2(self.g(x))
x = input + self.drop_path(x)
return x
原文详见
https://blog.csdn.net/m0_63774211/category_12511737.html
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。