使用Celery构建生产级工作流编排器

使用 Celery 为高 RPS 数据处理引擎构建复杂工作流的分步指南,从设计到实现,再到 Kubernetes 中的新生产。
译自 Building a Production Grade Workflow Orchestrator with Celery,作者 Param Rajani。
Celery 是一款出色的编排和数据工程工具,尤其是其画布工作流功能。无论您需要处理异步任务、长时间后台进程、构建复杂工作流、实现容错机制、构建微服务模式,还是其他需求,将其与 K8s 结合使用,您将获得最适合您产品的平台。
本文是我在使用 Celery 一年并部署产品后的总结。
将其视为您的“操作指南”,用于构建跨多个计算处理任务的工作流编排器,了解如何对其进行通信,如何协调和部署产品。
步骤 1:了解业务
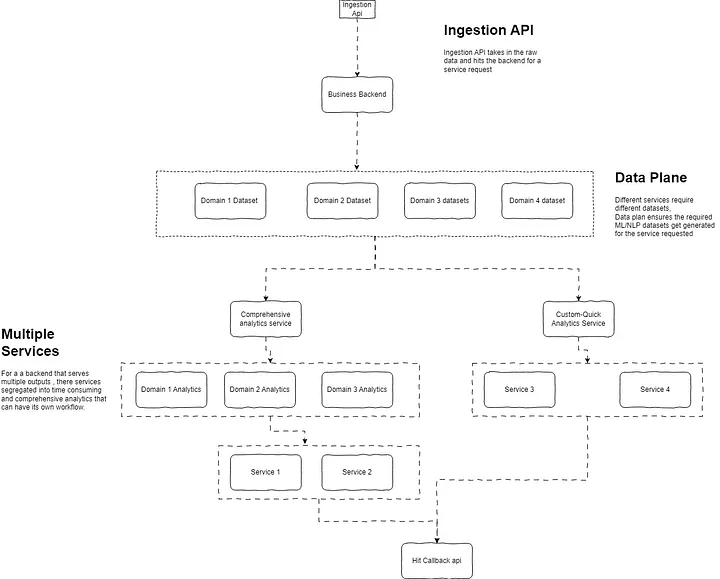
工作流业务视图
在开始编写代码前,了解业务流程是第一步,例如快速处理速度、如何实现这些功能、数据需进行哪类处理以及期间的所有步骤,程序如何在本地和云基础架构上部署以及就此类问题展开大量讨论。
此案例中的业务之旅始于将原始数据输入的数据摄取 API,从而生成不同的 ML/NLP 数据集,获取分析结果,并触发回调 API 进入下一行系统。上方的图表是整个旅程的快速概览
工作流必须满足以下要求:
- 模块化设计,以便轻松集成不同类型的分析服务
- 实时处理
- 扩展以实现高 RPS 摄取
- 必须在低至 10 秒内完成整个流程
- 该系统包括使用文件,并且将频繁与数据库(如 DynamoDB、S3、kms)进行交互,因此还必须满足成本优化架构
步骤 2:将其转换为 Celery 工作流
将其转换为工作流的真正难点在于定义任务、将执行这些任务的 worker 以及如何使用队列进行所有通信。
Celery 的优点在于其功能,例如 Celery 画布工作流和它提供的不同类型的 worker 池,这使其可以灵活地适应不同的设计模式和架构。
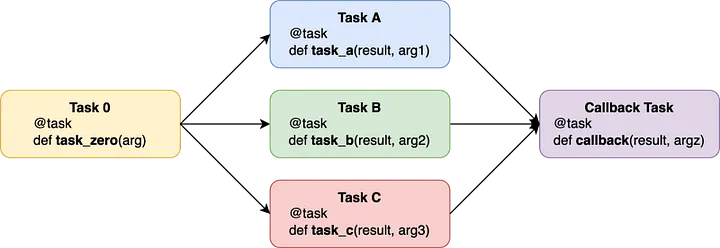
我们首先从定义不同的 Celery 任务开始。
即把每个组件分解为一个单独的任务,该任务必须负责实现其自己的业务目标,它甚至可以失败或重试,但必须实现其目标。
下图中的域数据集生成器和分析师任务负责 ML、NLP 和 Pandas,并针对其特定业务目标进行隔离。每个业务域都可以使用自己的逻辑和模型生成自己的数据集,每个域都可以分解为自己的不同任务。
然后是编排任务
这些任务作为协调器出现,它们本身没有任何业务逻辑,但实际上定义了实际数据处理任务如何执行和协调才能顺序运行。
第一个流程发起程序充当编排器的入口点,并按顺序与数据集生成器以及服务任务进行协调。下一个数据生成器和服务任务确保正确地并行执行子任务。
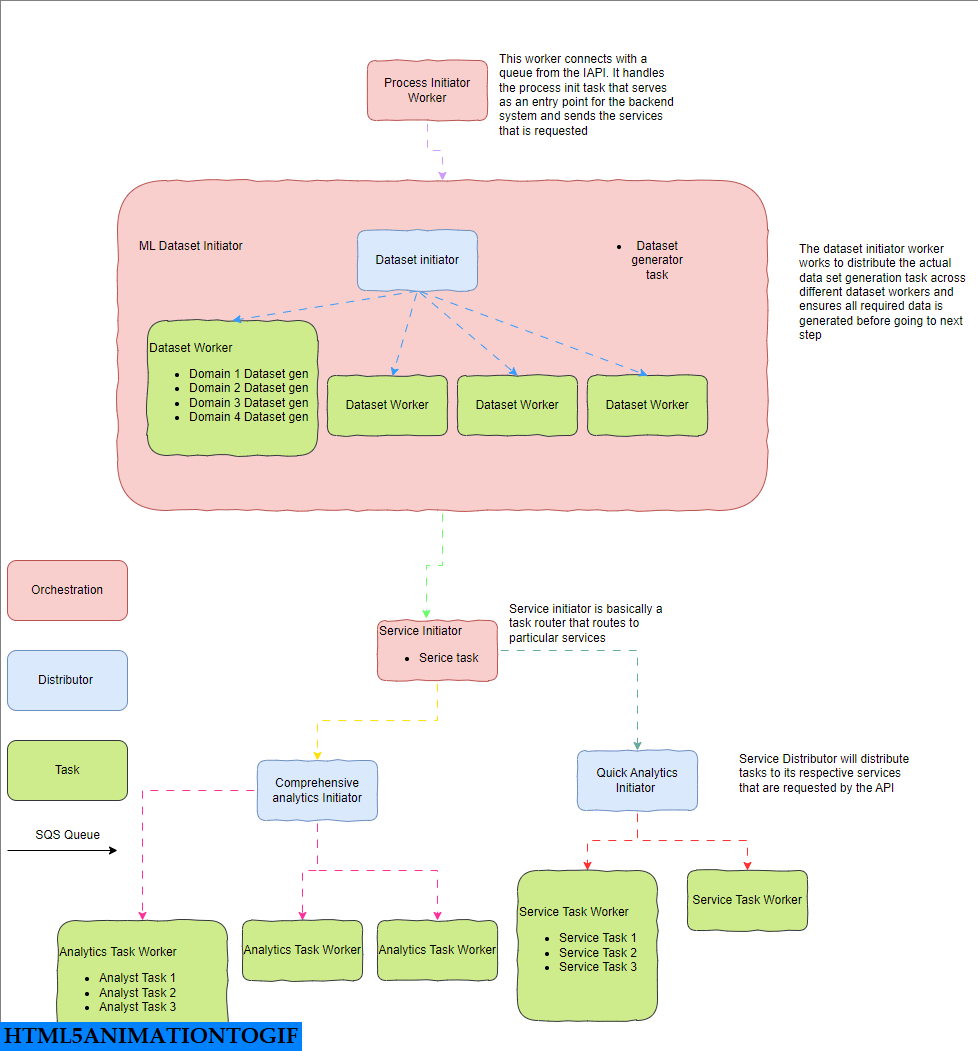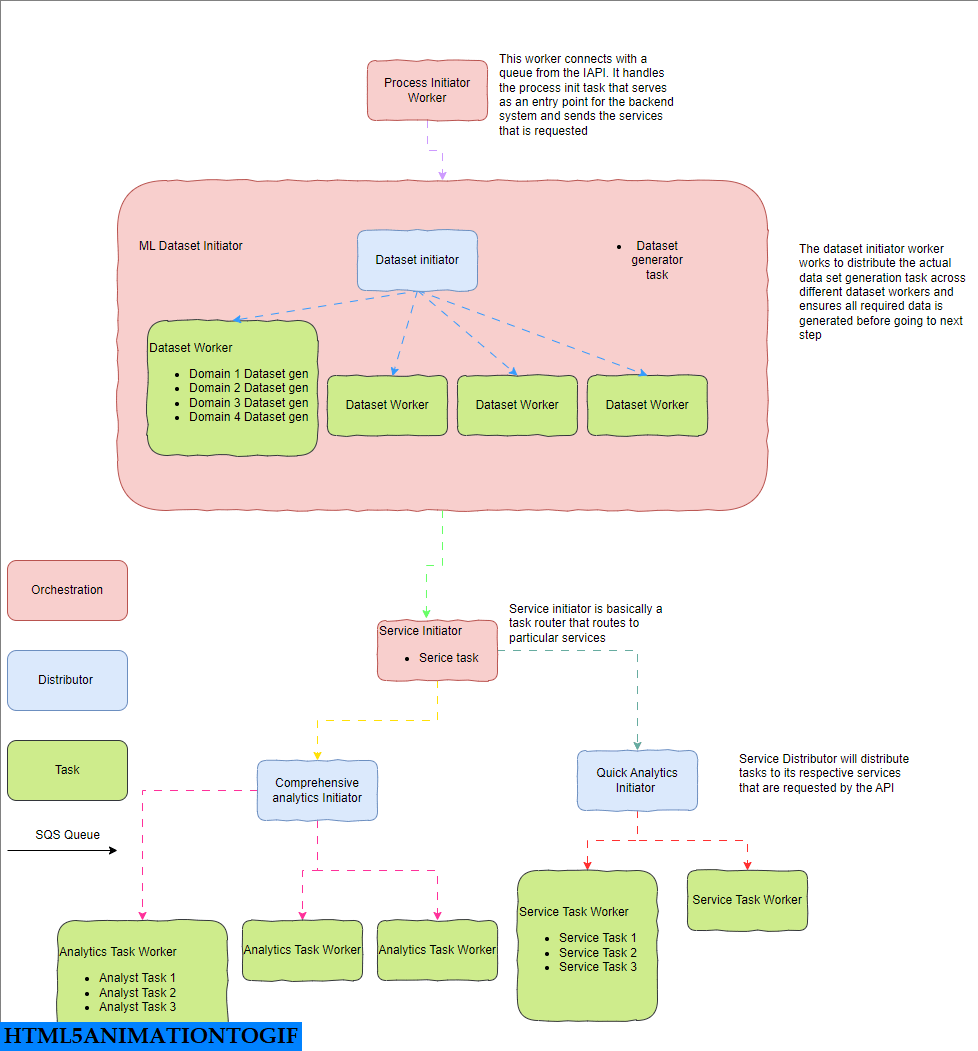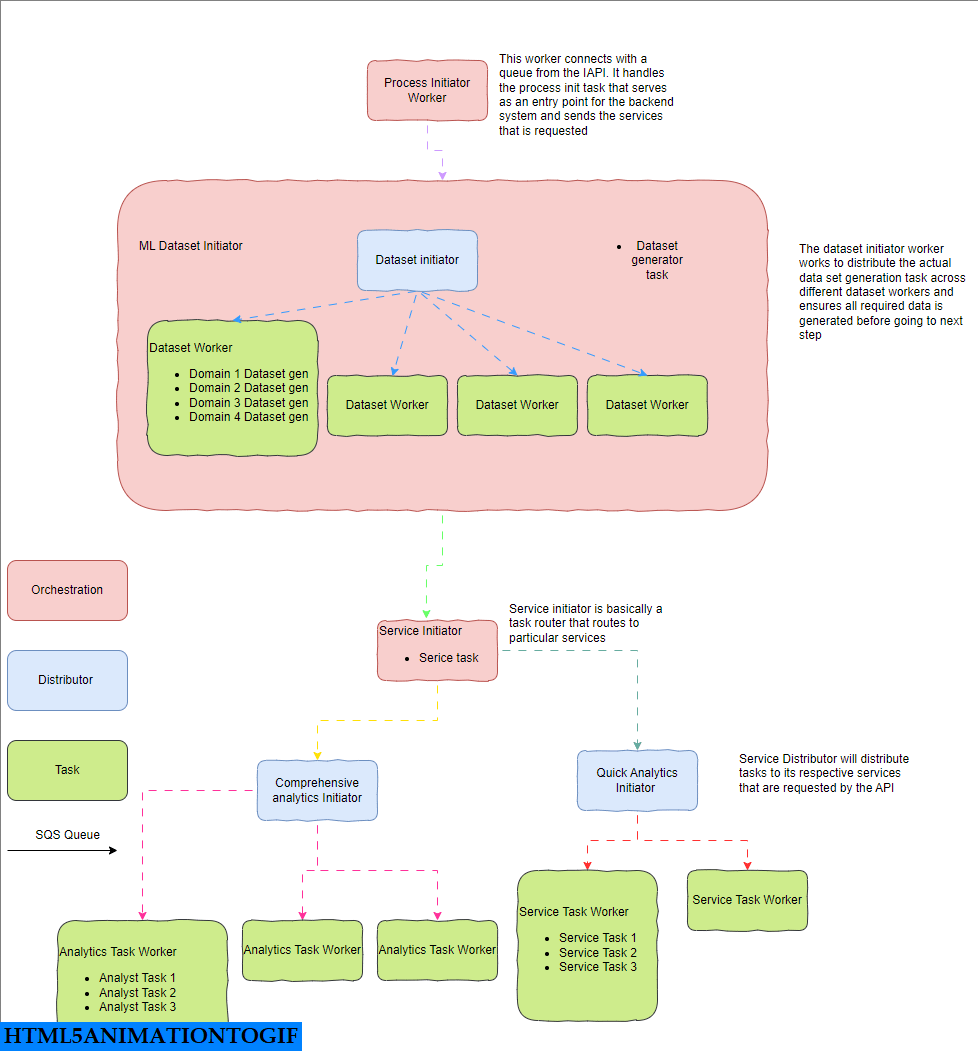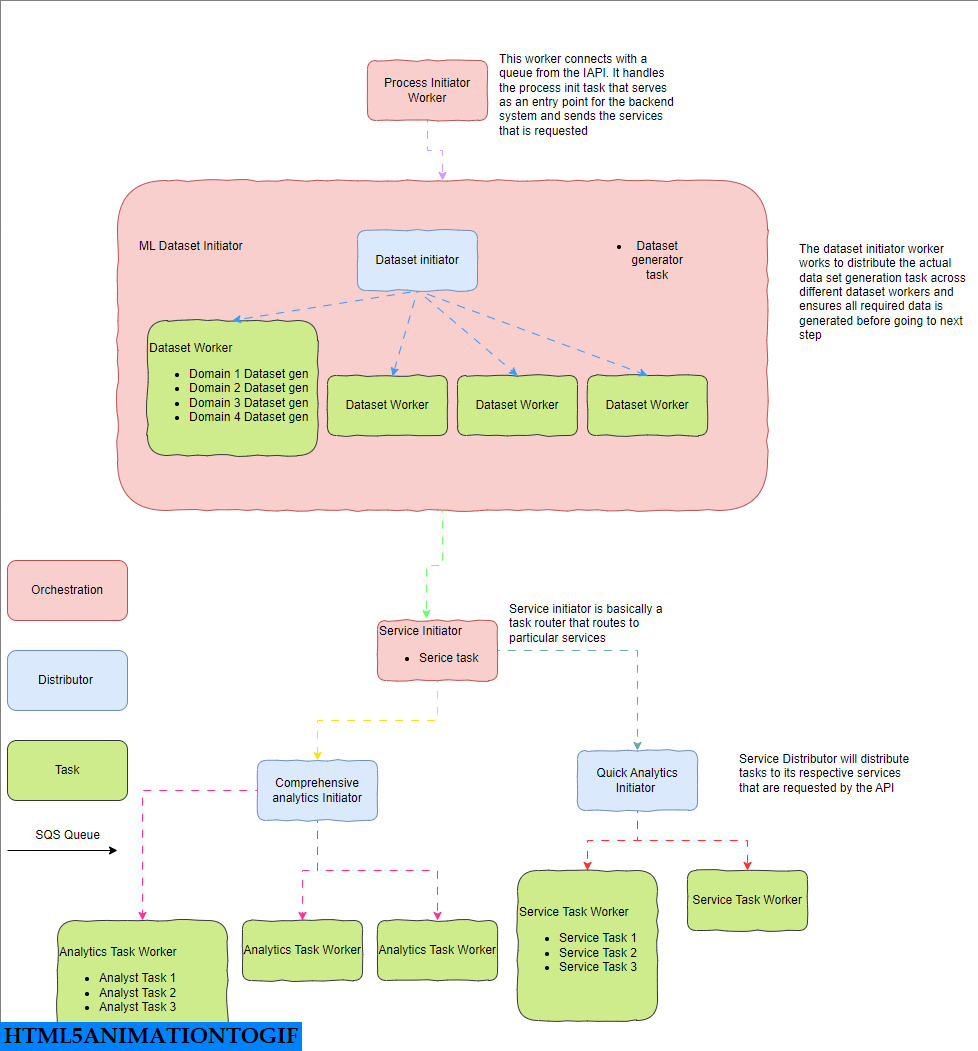
包含工作人员、任务和消息代理的完整芹菜工作流
然后我们决定负责这些任务的 Celery worker 并使用适当的配置。
我们将有许多执行多个任务的 worker ,但我们可以将它们广泛分类为 3 种类型:Orchestration、Distributor 和 Task worker 。
- Orchestration worker:这是整个工作流的中央协调器,它决定如何顺序执行任务、如何控制消息流并建立从摄取到分析再到消费的数据管道。
- Distributor worker:负责并行执行任务并等待它们完成,例如数据生成器和综合分析发起者 worker 。
- Tasks Worker:负责执行涉及 Pandas 和模型预测的实际任务,并且计算量也很大。
此处的每个 worker 都已容器化并作为 pod 部署在 K8s 集群上,并且可以按您希望的那样进行扩展。
定义 worker 配置:
Celery 有一些不同类型的 worker 配置,可用于不同的并发性和任务持续时间要求,例如 gevent、forkpool 和 eventlets。对于短且仅具有 IO 操作或简单 api 调用的内容,您可能需要使用以非阻塞方式执行任务的 gevent 和 eventlet,对于需要计算和内存的内容,请使用 forkpool worker ,它在子进程上工作以实现并发。
前 2 个 worker orchestration 和 distributors 都是针对不需要计算或内存的短期任务并且通常会导向队列中的消息并处理 DynamoDB 操作。这些任务可以具有更高的并发性和使用 gevent worker 池。
另一方面,Task worker 是数据魔力发生的地方,并且具有较低的并发性,它计算繁重,并且必须使用默认的 celery forkpool worker 。
使用正确的池配置正确的 worker 可以实现更快速的数据处理目标,在编排 worker 本身的情况下,从一个任务移动到另一个任务可以满足高 RPS 和并发处理。
当任务已定义好了以及哪个 worker 将执行它们时,下一步需要确定路由。
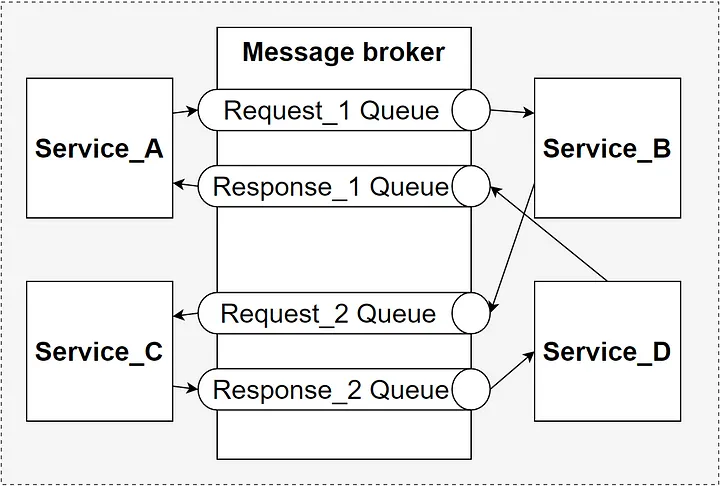
Celery 有一个可以通过配置提及的任务路由这个惊人的特性。
它可以根据名称自动将任务路由到不同的队列中,是的!是名称…所以如果你按照一些命名约定来为任务命名,Celery 将会使用 regex 和 glob 匹配模式将这些任务路由到那个队列。
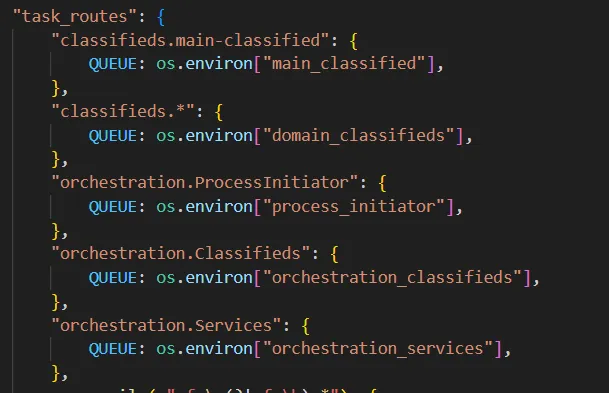
基于任务名称的任务路由示例
步骤 3:引入优化
Celery 有一些非常棒的生产系统功能,社区对此非常了解。
我遇到的某些功能加快了长时间运行的进程,这些功能侧重于 worker 轮询任务的方式、指定并发性上的任务分配机制、重试机制和处理故障。
-O Fair flag:默认情况下,预分叉 Celery 工作人员会在收到任务后立即将任务分配给他们的工作进程,而不管进程当前是否正忙于其他任务。 -Ofair 选项会禁用此行为,等待分发任务,直到每个工作进程可以工作。
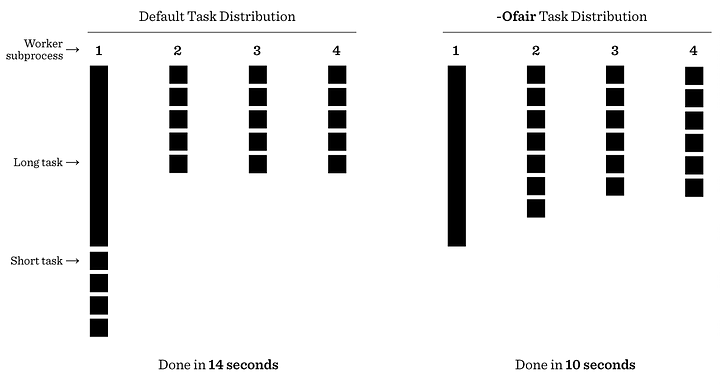
Workerpools:分布式系统中的工作器类型提供多样化的并发模型,以优化性能。Eventlet 和 Gevent 是 Python 中的轻量级库,用于异步 I/O 操作。Eventlet 使用协程和绿色线程,而 Gevent 采用基于绿色线程的协作多任务。Forkpool 工作器(如 Celery 中的工作器)使用基于进程的模型,创建独立的工作器进程,适合 CPU 绑定的任务,从而确保健壮的资源管理和隔离。这些选项提供了灵活性,可以根据应用程序的需要来提高性能。
prefetch multiplier:默认情况下,Workers 轮询从队列中获取其并发处理能力的 4 倍任务。对于一个长时间运行且需要从队列中立即处理的任务,如果将乘数改成 1,它将只轮询能够从队列中获取的并发处理能力数量的任务,从而允许另一个 Workers 轮询队列中的消息。
任务时间限制和处理:Celery 任务可以有自己的单独时间限制,如果运行时间过长则会失败。但它也提供了多种处理选项,如软时间限制和硬时间限制异常处理。这些可以允许恢复由于限制而导致任务被终止而发生的数据库事务。
任务失败和重试:你的代码可能会失败,但如何处理失败可以选择,通过 propagate 标志,chord 和 group 中失败的任务不会影响其他任务的执行,添加重试机制将原子地确保任务被工作进程重试。
缓存中的 Redis:对于中频使用的中间资源,如 json 文件或数据库调用,可以使用所有工作人员共享的公共 Redis 进行缓存。它们可以存储任务结果,并且也可以将缓存放在一边策略与 DynamoDB 和 S3 等数据库一起使用,以满足成本优化架构需求。
预加载机器学习模型文件:当使用 ML 模型构建工作流应用程序时,一种最佳优化技术是将它们加载为全局变量,这样一来,模型加载发生在工作器初始化时,并且可用作共享的静态文件。
步骤 4:添加警报和监控设置
现在我们有了分布式计算架构,下一步最好的事情是添加用于警报、监控和日志记录的机制。
ELK Stack:发送所有 Celery 任务状态日志的一种方法是在工作进程启动时劫持 Celery 记录器,并为其附加 Fluentd 处理程序,这将发送包含任务持续时间、在执行期间传递给任务的参数和关键字参数以及任务状态的日志。
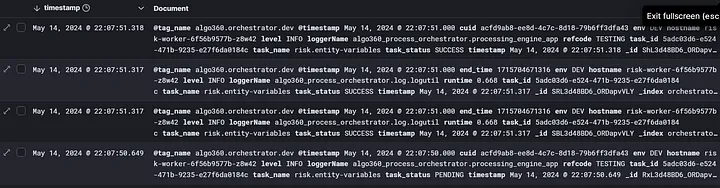
ELK 上的日志监控
Sentry:在处理可能让你感到意外的不同类型数据时,错误可能是不可预料的,尤其是当流量很大时,Sentry 可能是你的好帮手,它会在出现问题时提醒你,在 Celery 工作进程启动时设置 Sentry,并让它通过错误堆栈跟踪向你的 Slack 和电子邮件组发出警报。
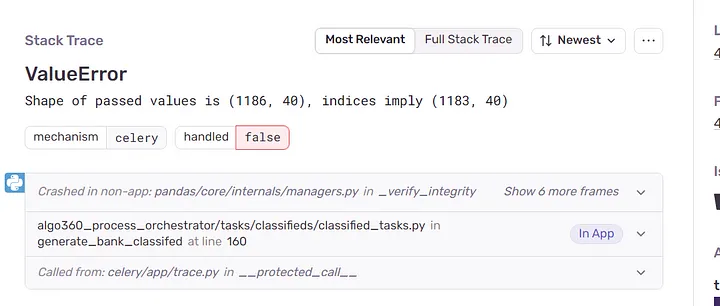
Sentry 允许在生产系统上进行调试的堆栈轨迹
Datadog:需要一个极其强大的工具来进行日志监控、堆栈监控、网络跟踪吗?…Datadog 可能是一款满足所有需求的最先进工具。
步骤 5:部署到生产环境,开始吧!
- 工作流构建?
- 故障和异常处理?
- 优化?
- 处理速度?
- 日志记录和警报?
我们现在已准备好将此设置投入生产环境。我们通过将应用程序容器化并在 K8s 集群的不同 Pod 上启动每个工作进程来实现此目的。
此处的容器编排将使我们能够满足按需流量,我们的工作进程可以根据队列中的消息进行扩展,并更快地处理这些消息。
由于我们使用的是 SQS Queues,因此可以利用 Kubernetes 事件驱动的自动扩缩器 KEDA(简称)进行扩缩。
理想情况下,对于高 RPS 工作流,工作进程必须立即从队列中使用一条消息并对其进行处理。如果流量很大,则更多侦听同一队列的工作进程将解决此问题。为了定义最佳扩展策略,我们查看队列指标,例如 Amazon SQS 上提供的指标。
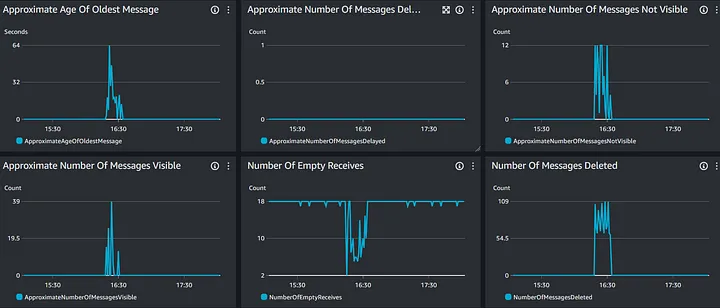
使用 SQS 指标调整策略
扩展和生产设置?
所有系统都已准备就绪,我们已成功制作了一个生产级编排器,该编排器可以满足高 RPS 要求,并按需扩展。
因此,现在使用 Celery 以其最佳本质用于数据工程和构建复杂工作流以及部署你的产品。我希望这能让你大致了解如何使用 Celery 在多个计算中实现任务的复杂协调和执行,但不仅限于构建,还包括构建一个具有扩展、监控和优化的生产级系统。