SQL向量数据库正在塑造新的LLM和大数据范式

将矢量数据库与 SQL 相结合可以提供构建现代生产级 GenAI 应用程序所需的准确性和性能。
译自 SQL Vector Databases Are Shaping the New LLM and Big Data Paradigm,作者 Linpeng Tang。
像 GPT-4、Gemini 1.5 和 Claude 3 这样的强大大型语言模型 (LLM) 的兴起已成为人工智能和技术领域的颠覆者。一些模型能够处理超过 100 万个 Token,它们处理长上下文的强大能力令人印象深刻。然而:
- 许多数据结构过于复杂且不断发展,LLM 无法有效地自行处理。
- 在上下文窗口内管理海量异构企业数据根本不切实际。
检索增强生成 (RAG) 有助于解决这些问题,但检索准确性是端到端性能的主要瓶颈。一种解决方案是通过高级 SQL 向量数据库将 LLM 与大数据集成。LLM 与大数据之间的这种协同作用不仅使 LLM 更有效,而且使人们能够从大数据中获得更好的智能。此外,它在提供数据透明性和可靠性的同时进一步减少了模型幻觉。
向量数据库的现状
作为 RAG 系统的基石,向量数据库在过去一年中发展迅速。它们通常可以分为三类:专用向量数据库、关键字和向量检索系统以及 SQL 向量数据库。每种类型都有其优点和局限性。
专用向量数据库
一些向量数据库(如 Pinecone、Weaviate 和 Milvus) 从一开始就专门设计用于向量搜索。它们在该领域表现出良好的性能,但通用数据管理能力有些受限。
关键字和向量检索系统
以 Elasticsearch 和 OpenSearch 为代表,这些系统因其全面的基于关键字的检索能力而被广泛用于生产中。然而,它们消耗大量的系统资源,并且关键字和向量混合查询的准确性和性能往往令人不满意。
SQL 向量数据库
SQL 向量数据库 是一种专门的数据库类型,它将传统 SQL 数据库的功能与向量数据库的功能相结合。它提供了借助 SQL 高效存储和查询高维向量的能力。
上图展示了两个主要的 SQL 向量数据库:pgvector 和 MyScaleDB。Pgvector 是 PostgreSQL 的向量搜索插件。它易于上手,适用于管理小型数据集。然而,由于 Postgres 的行存储劣势和向量算法限制,pgvector 对于大规模、复杂的向量查询往往具有较低的准确性和性能。
MyScaleDB 是一个开源 SQL 向量数据库,建立在 ClickHouse(一个列式存储 SQL 数据库)之上。它旨在为 GenAI 应用程序提供高性能且经济高效的数据基础。MyScaleDB 也是第一个在整体性能和成本效益方面 优于专用向量数据库 的 SQL 向量数据库。
来源: MyScale GitHub
SQL 和向量联合数据建模的强大功能
尽管 NoSQL 和大数据技术不断涌现,但在 SQL 诞生半个世纪后,SQL 数据库仍继续主导着数据管理市场。即使是 Elasticsearch 和 Spark 等系统也添加了 SQL 接口。借助 SQL 支持,MyScaleDB 能够在向量搜索和分析中实现高性能。
在实际的 AI 应用中,集成 SQL 和向量可以增强数据建模的灵活性并简化开发。例如,一个大型学术产品使用 MyScaleDB 对海量的科学文献数据进行智能问答。主要的 SQL 架构包含 10 多个表,其中几个表具有基于向量和关键字的反向索引结构,并通过主键和外键连接。该系统处理涉及结构化、向量和关键字数据以及跨多个表的联接查询的复杂查询。这对专门的向量数据库来说是一项艰巨的任务,这通常会导致缓慢的迭代、低效的查询和高昂的维护成本。
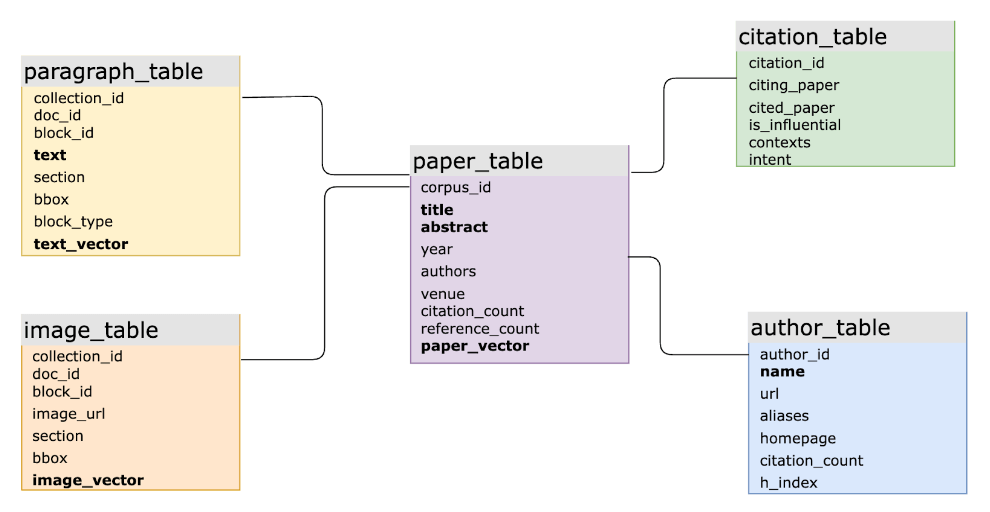
MyScale 支持的大型学术产品的 SQL 向量数据库架构(加粗的列具有关联的向量索引或反向索引)。
提高 RAG 的准确性和成本效益
在实际的 RAG 系统中,克服检索准确性(以及相关的性能瓶颈)需要一种有效的方法来组合对结构化、向量和关键字数据的查询。
例如,在金融应用中,当用户查询文档数据库时,询问“2023 年全球 <company_name> 的收入是多少?”时,语义向量可能无法捕获“<company_name>”和“2023”等结构化元数据,或者这些元数据不存在于连续文本中。整个数据库中的向量检索可能会产生杂乱的结果,从而降低最终准确性。
但是,公司名称和年份等信息通常可以作为文档元数据获得。使用WHERE year=2023 AND company LIKE "%<company_name>%"作为向量查询的过滤条件可以精确定位相关信息,从而显著提高系统可靠性。在金融、制造和研究领域,我们观察到 SQL 向量数据建模和联合查询将精度从 60% 提高到 90%。
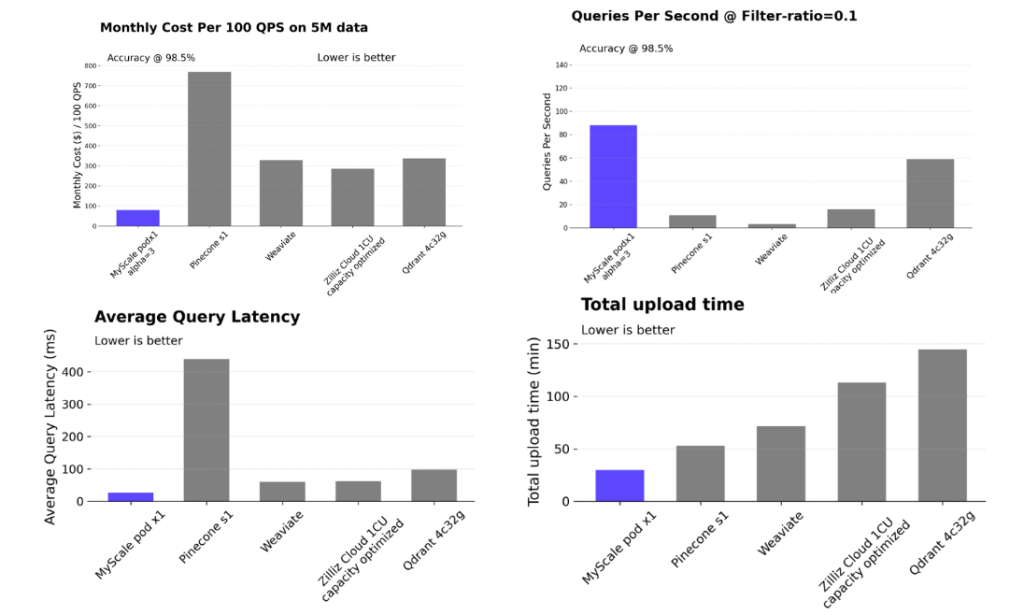
虽然传统的数据库产品已经认识到在 LLM 时代向量查询的重要性并开始添加向量功能,但其组合查询的准确性仍然存在重大问题。例如,在过滤器搜索场景中,当过滤比率为 0.1 时,Elasticsearch 的每秒查询数 (QPS) 速率下降到大约 5,而使用 pgvector 插件的 PostgreSQL 在过滤比率为 0.01 时准确率仅为大约 50%。这表明不稳定的查询准确性和性能极大地限制了它们的使用。相比之下,SQL 向量数据库 MyScale 在各种过滤比率场景中实现了超过 100 QPS 和 98% 的准确性,成本仅为 pgvector 的 36% 和 Elasticsearch 的 12%。

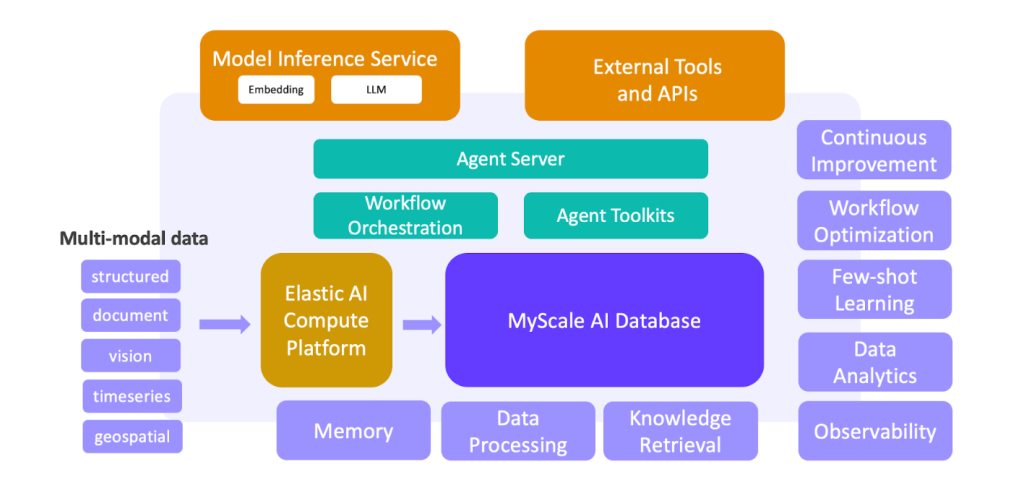
LLM + 大数据:构建下一代代理平台
机器学习和大数据推动了 Web 和移动应用程序的成功。但随着 LLM 的兴起,我们正在转向构建具有大数据解决方案的新一代 LLM。这些解决方案解锁了大规模数据处理、知识检索、可观察性、数据分析、少样本学习等关键功能。它们在数据和 AI 之间创建了一个闭环,为下一代 LLM + 大数据代理平台奠定了基础。这种范式转变已经在科学研究、金融、工业和医疗保健等领域展开。
随着技术的快速发展,预计在未来 5 到 10 年内会出现某种形式的人工通用智能 (AGI)。关于这个问题,我们必须问:我们需要一个静态的虚拟模型,还是需要一个更全面的解决方案?数据无疑是连接 LLM、用户和世界的纽带。我们的愿景是有机地集成 LLM 和大数据,创建一个更专业、更实时、更协作的 AI 系统,它也充满了人性化的温暖和价值。
欢迎您探索 GitHub 上的 MyScaleDB 存储库,并利用 SQL 和向量构建创新的生产级 AI 应用程序。