Phoenix框架 从0到1设计业务并发框架 自动构建有向无循环图设计
Phoenix框架 从0到1设计业务并发框架 自动构建有向无循环图设计

Phoenix 自动构建有向无环图的业务并发框架,核心就在于不需要开发人员关心调用分层和依赖互斥的排序问题,通过算法进行自动构建、收集 Task 任务、检测环或者依赖,最后打印并发组分层信息。
本篇文章就讲解下如何构建有向无环图的设计实现方案及遇到的问题。
实现方案
有向无环图的构建采用的是设计模式中的策略模式,首先定义好 Builder 的实现方式,如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | /** * @author debuginn */ public interface PhoenixBuilder { // 过滤 Phoenix API 使用到的 Task 任务 Map<String, ArrayList<TaskObj>> filterApiUsedTask(ArrayList<TransObj> transObjArrayList); // 根据 api 获取需要执行的 trans Map<String, ArrayList<TransObj>> apiTransMap(ArrayList<TransObj> transObjArrayList); // 是否存在依赖关系 void isHaveLoop(Map<String, ArrayList<TaskObj>> apiUsedTaskMap); // 处理并发组分层划分 Map<String, ArrayList<ArrayList<TaskObj>>> processConcurrentGroup(Map<String, ArrayList<TaskObj>> apiUsedTaskMap); // 打印并发组分层信息 void printConcurrentGroup(Map<String, ArrayList<ArrayList<TaskObj>>> phoenixApiArrayListMap); } |
|---|
PhoenixBuilder 需要实现 6 种方法:
- 首先,将收集上来的 Task,按照 API 进行分组,Task 存在依赖调用的都进行收集;
- 按照 API 进行收集 Trans,后续 Trans 使用请求线程进行串行执行;
- 判定每个 API 收集上来的 Task 是否存在相互依赖或循环依赖;
- 将每个 API 收集上来的 Task 按照先后依赖关系进行分组划分;
- 打印并发分组信息,用来给开发者调试及校验使用;
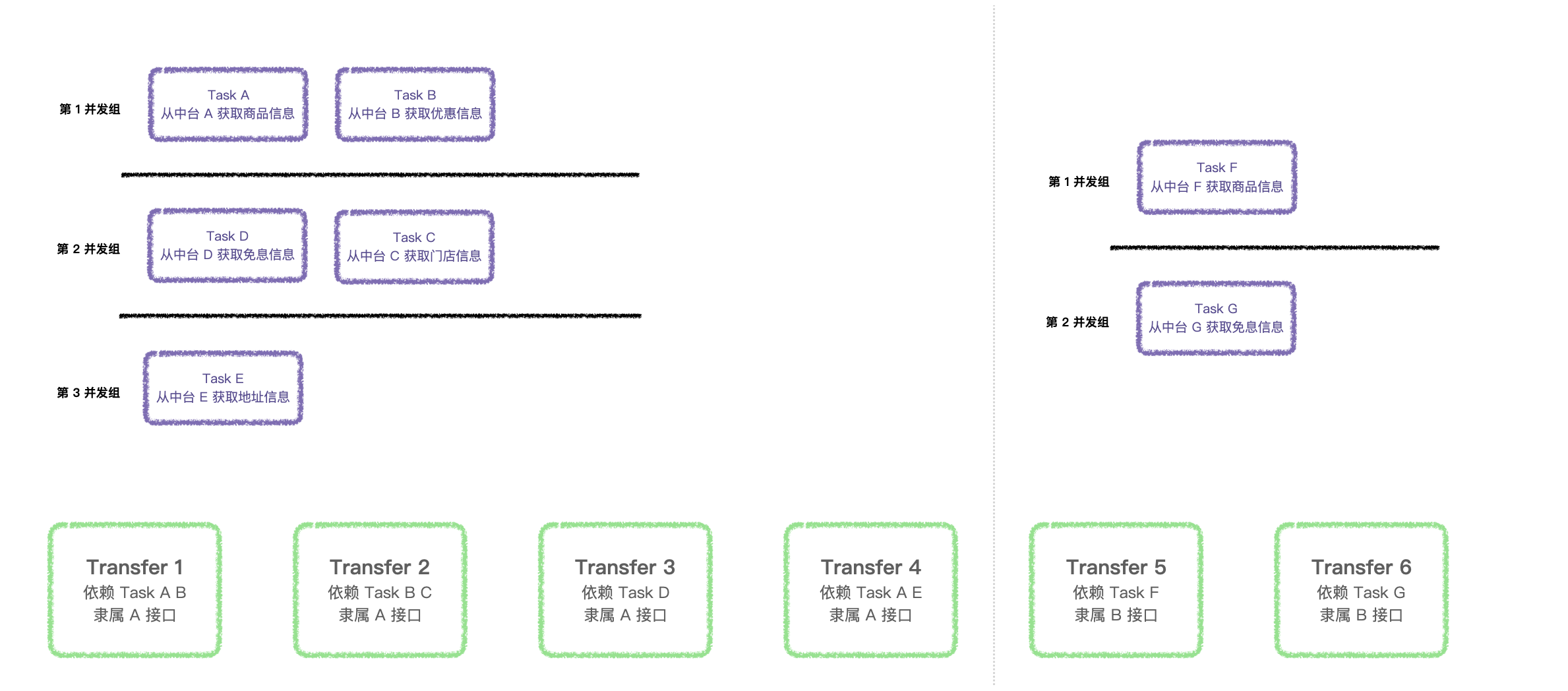
由于存在依赖关系,需要进行分层设计,这里可以结合 Phoenix 框架 怎么组织设计一个框架 来看,然而每一层并不需要关系执行的顺序问题,这里采用了最简单的数据结构存储分层信息,Map<String, ArrayList<ArrayList<TaskObj>>> Key 用来标识属于哪个 API 请求的并发分组,Value 则采用最简单的二维数组进行存储,每一维分别存储需要进行执行的 Task 任务。
遇到的问题
怎么判定存在环
由于我们要进行构建的是有向无环图,那么存在相互依赖的 Task,在框架设计逻辑中是行不通的,若存在相互依赖,那么究竟该先执行哪个 Task 呢?
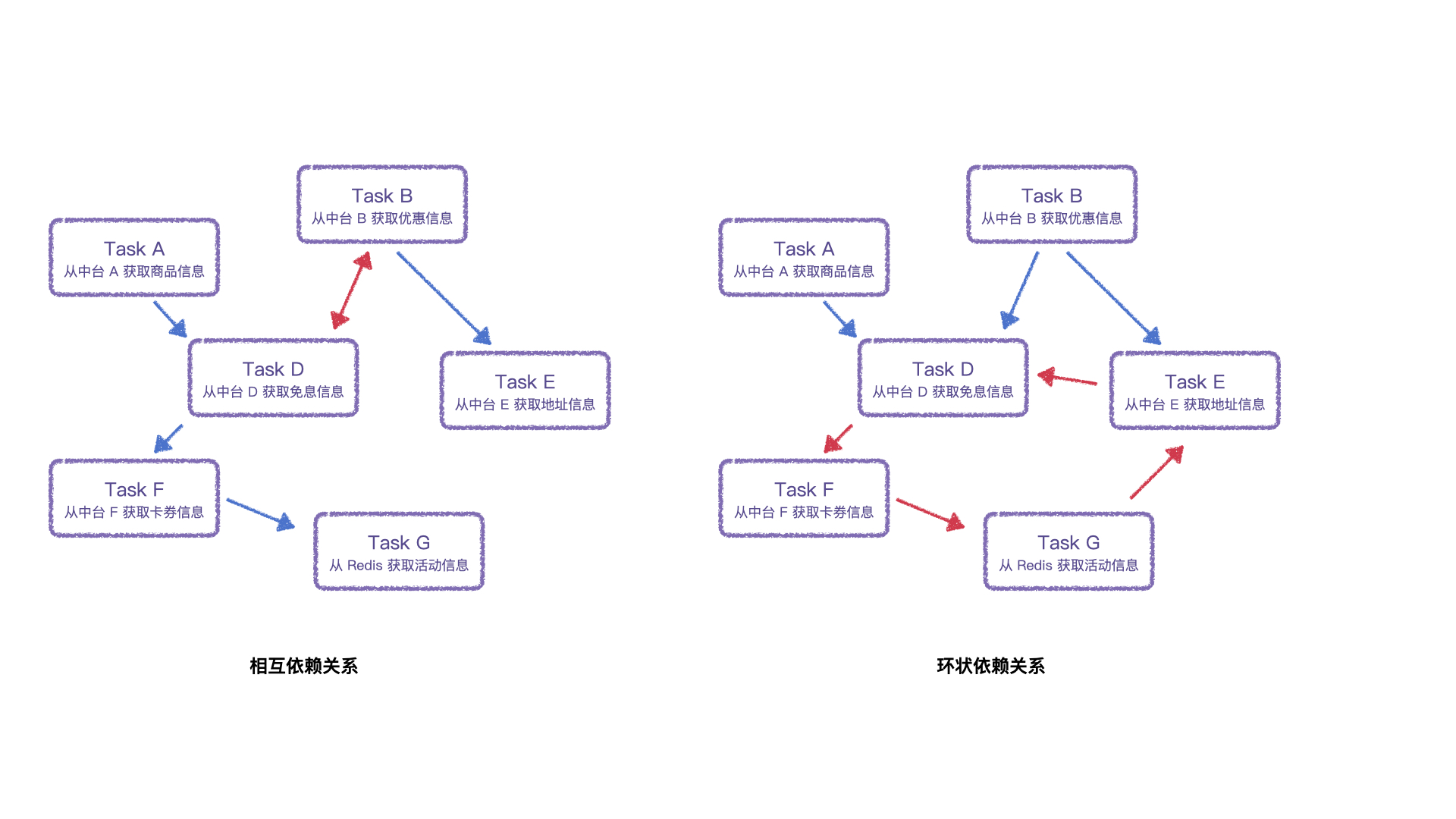
可以看到上图,只要有两个场景:
- 相互依赖关系:TaskB 与 TaskD 存在相互依赖,那么就不能确定执行顺序;
- 环状依赖关系:TaskD、TaskF、TaskG 和 TaskE 存在依赖环,也无法确定执行顺序;
相互依赖关系判定比较简单,就是检索一个 TaskA 依赖的 TaskB 是不是也依赖这个 TaskA, 循环依赖判定相对来说比较复杂,需要遍历图的所有路径,若路径存在闭环,则代表着存在环,反之,就是不存在环路,代表就是单向依赖的分支路径。
怎么划分并发分组
划分并发分组,就是将彼此没有依赖关系的 Task 按照依赖的先后顺序进行分组,其实就是按照图的深度遍历。
这里的遍历,由于有依赖关系,可以采用向上遍历或者向下遍历的方式,我们采用了压栈的方式处理:
向上遍历
- 首先找到没有被依赖的 Task,这是一组,之后存入数组压入栈底;
- 之后栈底的 Task 收集出来需要依赖的 Task,这些收集上来的 Task 需要再判定是不是被其他 Task 依赖,若是依赖的话,则保存在临时的 Task 数组中,最后将剩下 Task 就是只被栈底 Task 数组依赖的 Task,那么将这个分组继续压入栈内;
- 重复第 2 步,把栈底的 Task 换成栈内最上层的数组,之后再把临时 Task 追加到收集出来需要依赖的 Task 上,去重,之后重复执行;
- 最后执行到剩下的 Task 没有依赖的 Task,这就是最后一个并发组,之后压入栈内;
最后程序执行的时候,就是先执行栈顶部的并发组,之后一次出栈执行。
向下遍历
- 首先找到不依赖其他 Task 的 Task,这是一组,之后存入数组压入栈底;
- 之后栈底的 Task 收集出来依赖这个分组的 Task,这些收集上来的 Task 判定是不是被其他 Task 依赖,若是依赖,也是保存在临时的 Task 数组中,最后就只剩下只依赖栈底的 Task 数组的 Task,之后将这个数组压入栈内;
- 重复第 2 步,把栈底的 Task 换成栈内最上层的数组,之后再把临时 Task 追加到收集出来需要依赖的 Task 上,去重,之后重复执行;
- 最后执行到剩下的 Task 没有任何 Task 依赖,这就是最后一个并发组,之后压入栈内;
此时,这个堆栈存储的是最先执行的 Task 并发分组在栈底,最后执行的在栈顶,需要进行反转操作,之后再依次进行执行。
为何要使用"策略模式"
在开发程序的时候,大家都不约而同地讲究程序的横向扩展能力,将核心的关键的任务拆分成具体执行的子任务,这样不仅可以提高程序的可阅读性,而且还可以扩展不同的遍历算法,用来后续框架的持续优化。
不仅这里,Phoenix 框架尽可能的采用策略模式实现,将核心功能点都进行拆分,做到模块化设计,这样的设计正是 Phoenix 框架的设计初衷,生生不息,持续迭代。
写在最后
本篇文章主要讲了如何进行自动构建有向无循环图的思路及遇到的问题,其实在开发中,这种解决依赖关系的场景还有很多,其实抛开上层的业务实现或者框架需求来看,底层就是最基本的数据结构,算法,图的遍历场景在当今比较火的 AI 场景下也是如此。
感谢你的阅读,你要是有好的方案或者好的 idea 可以与我一起交流,最后,如果你感兴趣,推荐关注公众号或订阅本站,欢迎互动与交流,让我们一起变得更强~