金融市场中的人工智能:新算法和解决方案(全)
金融市场中的人工智能:新算法和解决方案(全)

原文:
zh.annas-archive.org/md5/98949b54b6218a075bcbfbd4379f7727译者:飞龙 协议:CC BY-NC-SA 4.0
前言
金融市场可能是少数真正可以被描述为复杂系统的人类成就之一。复杂系统是物理学中的结构,它们:(a) 从组件之间的相互作用中获得其动态的很大一部分,(b) 相互作用高度非线性,并且往往根据其自身的动态(反馈)而变化,© 系统的行为不能直接归因于个体相互作用的纯和:整体远大于个体部分的总和,(d) 并由此产生两个非常重要的后果:对初始条件的非常强烈的依赖(从相似的情况开始,我们观察到完全不同的最终状态)(一个典型的例子是天气预报)。
金融市场具备所有这些特征,因此,它们为试图理解趋势、平衡、危机时刻和高变异性的那些人提出了巨大的挑战。
然后是人工智能(AI),这种技术被称为“未来的石油”,驱动着我们社会经济系统的大部分。AI 存在于互联网上,存在于我们每天使用的应用程序中,存在于经济预测系统、广告管理系统、搜索引擎中。在我们的汽车、游戏以及当然,在金融市场中。
本书探讨了当人工智能技术在资本市场中变得更加普遍时会发生什么(以及在不久的将来可能发生的情况)。这与几年前在市场中(尤其是金融衍生品)肆无忌惮地横行的高频交易算法相比,是一个重大进步。这些算法正逐渐被能够执行与市场运作生态系统深度整合的任务的极其复杂的人工智能技术所取代(涉及新闻世界、社会政治动态、疫情、地缘政治紧张局势)。
本书分为两部分:理论部分,即 AI 目前的状况、当前的金融市场,以及可能是历史上尝试过的最大的社会经济政策行动,即所谓的“大重置”。然后是应用部分,这些应用源于混合大数据/AI 技术在检测和消除假新闻、经济评估和预测系统、基于能够独立做出决策的人工代理的模型以及动态意见模型中的使用。
所有这些旨在回答一个问题:人工智能能否使金融市场更安全、更可靠、更有利可图?以及存在哪些风险?
感谢
本书得以问世,得益于 QBT Sagl qbt.ch/提供的资源,这是一家在人工智能领域深耕多年的瑞士公司,尤其在金融科技和房地产科技领域。QBT 提供了模型开发和模拟数据收集所需的硬件和软件资源。
Federico Cecconi 罗马,意大利目录 1 人工智能与金融市场 1Federico Cecconi2 AI,总体概况 13Luca Marconi3 金融市场:价值、动态、问题 39Juliana Bernhofer 和 Anna Alexander Vincenzo4 AI 在“大重置”中的作用 57Federico Cecconi5 金融科技 AI:揭露真相 65Federico Cecconi 和 Alessandro Barazzetti6 ABM 在金融市场中的应用 73Riccardo Vasellini7 机器学习在金融市场的应用 85Riccardo Vasellini8 用于定价不良资产 UTP 和 NPL 贷款组合的 AI 工具 95Alessandro Barazzetti 和 Rosanna Pilla9 不仅仅是数据科学:FuturICT 2.0 109Federico Cecconi10 意见动态 117Luca Marconi 关于编辑 Federico Cecconi
担任 QBT Sagl 的研发经理(www.qbt.ch/it/),负责 LABSS(CNR)的计算机网络管理和模拟计算资源,并为 Arcipelago Software Srl 提供咨询服务。他开发了针对 LABSS 问题的计算和数学模型(社会动力学、声誉、规范动力学)。为 LABSS 进行传播和培训工作。他目前的研究兴趣有两个方面:一方面是研究社会经济现象,通常使用计算模型和数据库。另一方面是开发金融科技和房地产科技的 AI 模型。
第一章:人工智能与金融市场
Federico Cecconi^(1 )(1)LABSS-ISTC-CNR, Via Palestro 32, 00185 罗马, 意大利 Federico Cecconi 电子邮件:federico.cecconi@istc.cnr.it
摘要
人工智能是计算机科学的一个分支,专注于开发能够像人类一样工作和行为的智能机器。AI 基于这样的理念:机器可以模拟人脑,并且,在足够的数据下,机器可以学会像人类一样思考和行动。因此,我们可以将人工智能应用于金融市场并预测未来的趋势,例如。机器还可以被训练来识别买家动态中的模式,然后利用这些知识来预测未来的价格。我可以继续说下去,但主要观点是:为什么 AI 在信贷市场背景下有用?将人工智能应用于金融的优势是什么?简而言之,本书致力于解释这一点:提高准确性:AI 可以帮助预测收盘价、开盘价和其他金融数据。这可以导致更好的决策和更有利可图的交易。提高服务:人工智能可以用于改善金融机构的客户服务。例如,它可以用于帮助客户进行账户查询或提供市场技术分析。降低成本:AI 可以帮助降低金融机构的运营成本。例如,它可以用于自动化流程或提高运营效率。
关键词人工智能金融市场 PropTechFinTechFederico Cecconi
F. Cecconi 是 QBT Sagl 的研发经理(www.qbt.ch/it/),负责 LABSS (CNR)的计算机网络管理和模拟计算资源,同时也是 Arcipelago Software Srl 的顾问。他为 Labss 开发了计算和数学模型(社会动态、声誉、规范动态)。在 Labss,他既负责传播也负责培训。他目前的研究兴趣有两个方面:一方面是研究社会经济现象,通常使用计算模型和数据库。另一方面是开发金融科技和房地产科技的 AI 模型。
1.1 人工智能对金融市场有何用处?
人工智能在模型和应用中变得越来越普遍。它在辅助(或自主)驾驶解决方案、计算机视觉、自动文本分析、聊天机器人创建、经济规划应用和营销支持平台中不断扩展。但是,这种增长,有多少被再投资于金融市场?我们目前在资本市场中能看到多少人工智能,更重要的是,我们预计在不久的将来能看到多少?有哪些挑战?您正在使用哪些技术?
要开始回答这些问题,让我们先定义当今的人工智能。人工智能距离创造一个智能的头脑还有很长的路要走。确实,有许多迹象表明这已不再是热门话题。相反,我们在所谓的受限人工智能领域已经遥遥领先,当应用于非常特定的情境时,它能确保优于人类技能和能力的卓越成果。我们不应认为商业聊天机器人(如 SIRI)是为了模仿人类智能,甚至更好地理解人类的认知过程而创建的。实际上,这种雄心壮志,即在理解心灵、人工智能实现和心灵新理解之间创造一个正反馈循环,似乎并未出现在基础研究或应用的议程上。SIRI 是访问分布式数据库的一个例子,它使用自然语言作为接口,与传统的 IT 技术有更多的共同点,而不是与寻找信息的认知系统理论,如人类心灵中的短期记忆结构有共同之处。
确实,世界上有一些研究中心以综合的方式处理心灵和人工智能,经常将心灵的运作与心灵与自然中的大脑和身体的联系联系起来。在过去的几十年里,人类的多感官整合认知模型已经被开发出来并应用于模拟人类身体体验。最近的研究表明,贝叶斯和连接主义模型可能会推动机器人学各个分支的发展:辅助机器人设备可能会适应其人类用户,例如在假肢中,而类人机器人可能会被赋予与周围空间相关的人类般的能力,例如保持安全或社交上适当的距离。然而,我们预计会在本书设定的时间范围(十年)之外看到实验室之外的人工智能。
总之,尽管人工智能模型的抽象能力有限,且学习方式与人类不同,我们现在能够开发出能够高效有效地执行行动和任务的系统(想想它们与孩子相比学习识别猫的方式有何不同)。然而,不可否认的是,在某些领域和特定任务中,使用人工智能技术的系统能够产生比人类更优越的结果。
回到金融市场,我们逐渐清晰地认识到目前期望找到哪些技术,相信哪些技术很快会被发现,以及哪些技术与使市场更安全、更有利可图、更与社会和宏观经济动态相连接的愿望相一致。我为每一种技术都写了一章。
1.1.1 自动评估与 PropTech
人类一直试图为物品赋予货币价值,特别是在我们这个物种能够产生可保存和可能交换的“剩余”资源之后。实际上,在狩猎采集社会中,比如北美的原住民群体,试图为物品赋予价值是没有意义的,因为无论是什么物品,都是立即使用并被新的物品所取代。
资本市场是这一过程的最高级形式,因为它试图为有时与产生它们的‘实体’商品相去甚远的金融资产赋予价值。让我们从抵押贷款开始。即使我们忽略任何复杂的金融抵押交易(例如,将多个抵押贷款合并为一个可以借款的单一对象),抵押贷款是一种我使用实体资产(如房产)的价值作为抵押的贷款,其价值动态与贷款金融对象的动态非常不同。房产的价值可能会根据其租赁环境中的结构性变化而增加或减少(例如,我的社区开通了新的地铁站),而抵押贷款则受到与利率相关的宏观经济动态的影响(例如,银行因为利率趋于低而减少提供抵押贷款的兴趣)。
毕竟,金融价值与抵押贷款作为严格意义上的金融对象,以及房产作为严格意义上的实体资产之间存在着数十种循环联系:例如,如果宏观经济动态推动利率下降,银行支付减少,房屋的价值可能会下降,因为需求下降(许多人没有足够的钱购买,并且由于获得抵押贷款的困难,他们放弃了)。
在房地产领域,为了拥有能够计算物品价值的工具,人工智能已经做出了令人印象深刻的贡献,创造了许多属于 proptech 宏观类别的模型。
房地产科技(proptech)一词源于“property”(财产)和“technology”(技术)的混合,于 2014 年在英国创造,指的是用于创新流程、产品、服务和房地产市场的解决方案、技术和工具。房地产科技涉及正在改变房地产各个方面的数字解决方案,如房地产销售、风险分析、财务预测模型、资产管理以及开发项目的融资动态。实际上,房地产科技是房地产行业更大规模数字化转型的一个较小组成部分。它与房地产行业及其用户在数据收集、交易以及建筑和城市设计方面的技术创新思维转变有关。但这不仅仅是销售。根据一些研究,对租赁住房单元的需求正在迅速增加,以至于我们称之为“租赁一代”。
从房产所有权向房产租赁的转变是推动房地产科技趋势的主要因素。今天的租户不断寻找更好、更新的空间,配备尖端技术。消费者希望获得他们能够控制——灯光、温度、访问等——的体验,无论是通过手机还是其他渠道,无论是他们的工作环境、最喜欢的商店,还是他们日常生活的空间。人工智能系统可以帮助计算成本、评估解决方案,并偶尔为居住者提供数字体验,但通过使用增强/虚拟现实等技术,它可以显著提升客户体验。公司因此可以提供灵活的租赁,同时提供高质量的家具空间体验。此外,金融科技-房地产科技公司可以提供简化的租户入职流程。
房地产科技解决方案几乎总是包含人工智能元素,这些元素几乎总是基于能够定期使用数据库进行学习的模型。这些模型有时包含计算机视觉和自然语言理解元素,尤其是在涉及到对非经济性质的新闻(典型的例子是与气候动态相关的新闻)做出反应的可能性时。
1.1.2 基于新闻的决策模型
我们已经有了能够实时阅读新闻并能够提出建议或自行采取行动的系统。最容易实现自动化的记者领域是那些能够访问大型、结构良好的数据集的领域。例如,体育新闻、天气预报、地震预警、交通和犯罪新闻,当然还有金融新闻。以下是一些例子。
体育
至于体育领域,2016 年瑞典地方媒体公司Östgöta Media 推出了“Klackspark”网站,旨在覆盖每一场地方足球比赛。在瑞典,足球非常受欢迎,每个地区都有自己的球队,因此对于报纸来说,报道所有国内和国际足球分区的比赛(男女)是复杂的。
为了能够拥有更广泛的覆盖范围,Klackspark 决定使用自动编写软件算法,这些算法收集每场比赛的结构化数据,并自动发布关于挑战的百字报告。这不是一个困难的任务,也不需要特别的想象力,因为所讲述的内容基于谁进了球、之前的比赛结果和排名。生成的简短文章随后由记者进行审查,并添加有趣的特色。
此外,机器在可能出现有趣的故事时会提醒记者,例如一名球员在同一场比赛中多次进球。这允许你采访直接受访者,为文章添加信息,实际上使其更加生动。
气象学
自动化能否提高我们的生活质量?在天气新闻行业,这可能是事实,该行业为每个城市生产自动化的天气预报。这些报告的速度和准确性对这个行业至关重要。一个相关案例是报告和发布地震警报的机器人,对人们的生活有重大影响。一个特殊案例是洛杉矶时报的“Quake Bot”项目,它可以自动生成并发布地震报告,帮助读者了解可能对其生存或亲人构成的风险。
该系统通过从美国地质调查局(USGS)数据库中提取信息来工作。然而,在 2017 年 6 月,Quake Bot 发布了一个虚假报告,由于一个错误发出了错误的警报。后来发现,错误是由一个错误的设计决策造成的。算法不是中立和客观的决策者,而是不透明的,既为了保护创建和使用它们的公司,也为了满足安全系统管理的技术需求。
在编程阶段,创作者必须考虑到用户将如何使用接收到的信息,以提供一个复杂的产品。速度、大规模数据分析和准确性是选择自动化新闻的原因。对于新闻编辑室来说,最重要的好处是有机会自动化那些对记者来说不刺激的重复性日常任务。这样他们就可以把时间用于更需要创造性和批判性思维的工作上。只有某些行业从自动化中获益更多,因此并不是所有东西都值得自动化。
金融
我选择报道的是由国际新闻机构彭博创建的金融工具。十多年来,该机构一直在为其终端自动生成书面新闻稿。2018 年,彭博通过自动化实现了内容生产的四分之一(Mandeep et al. 2022)。同年,该机构的创新实验室(称为 BHIVE)推出了“公告”,这是一个能够提供新闻自动摘要的工具。
研究团队专注于用户偏好,特别是他们的主页,以及如何为他们提供最新信息,以便提供一个清晰且易于阅读的概览。公告包括来自彭博全球网络的三个最重要和最新的新闻摘要。其目标是为那些时间有限、只在手机上短暂浏览但希望全面了解世界动态的用户提供信息。人工智能通过筛选该机构 2700 名记者和分析师的网络,提取最重要的细节来介入。它基于自然语言处理(NLP),扫描文章中的关键词和语义,并将它们综合成一个简单的句子,供用户使用(Ashkan 2022)。
1.1.3 趋势跟随者
简而言之,AI 交易软件旨在实时分析股票和交易模式。通过其市场分析,软件可以提出股票推荐以及实时数据。这类软件生成的信息极具价值,因为您可以使用它们来优化进入和退出股票头寸的时机,以最大化利润(Yan 2022; Yao et al. 2022; Gu et al. 2021)。
由于交易主要依赖于基于市场未来价格变动的及时决策,因此分析和预测价格变动的能力是交易中的一项宝贵技能。通过代表您分析市场并预测价格变动,AI 交易软件提供了超越其他类型交易软件的空前优势。AI 交易软件的核心是机器学习,这是人工智能的一个子领域。机器学习软件试图模仿人类的思维和行为。我们使用“模仿”这个词,是因为它们被设计为具有通过接触数据集来学习和改进的能力。换句话说,机器学习模型能够在没有人类干预的情况下从错误中学习并随着时间的推移而改进。
大多数 AI 交易软件能够同时监控数千只股票的价格行为,并且全天候运作。根据预设的参数,软件可以监控市场中的特定价格变动标志。然后,它会通知您这些即将发生的变化,使您能够相应地采取行动。
除了监控股票价格变动外,一些人工智能交易软件还能跟踪你的长期表现。在回测过程中,软件分析历史数据,让你了解在特定时期内你的策略效果如何。一些软件还允许你在模拟交易平台上测试不同的策略。软件每天同时筛选数千只股票,分析技术和基本面。它还分析数百个社交媒体和新闻网站,以获取可能影响股价的公司动态报告。
该软件提供了广泛的功能选择,包括提供入场和退出的信号以最大化你的利润。它还具备实时交易模拟、价格警报、风险评估、构建和回测各种交易策略,以及自动交易。它还提供了一个虚拟交易助手,可以帮助你实时分析图表模式以及理想的入场和退出点。
该软件的一个优势是其过滤不良股票的能力。它通过分析股票的历史表现与当前市场状况的对比来实现这一点。该软件也非常易于使用,适合初学者和专业交易者。
然后,软件将数据通过一系列复杂的金融和工程模型运行。这些模型包括分类、回归等。软件随后将结果编译成股票和其他资产的预测排名。
除了能够使用指标对股票进行排名外,该软件还具备其他非常实用的功能,其中一些功能还得到了人工智能的支持。其中一个功能包括一个模拟交易组合,允许你在不使用真实资金的情况下测试投资策略。
该软件还提供市场新闻服务。这项服务汇总了相关的财经新闻,并具备一个观察列表功能,用于跟踪特定的股票和市场。此外,还有一个市场分析工具,可筛选出最适合投资的股票,以及一个日历,用于跟踪股票每周的表现。
最后,鉴于可用信息的缺乏,寻找支持加密货币交易的人工智能交易软件可能很困难。
自动交易将实际交易交给加密货币机器人,你无需手动输入订单。你所需要做的就是提前设置交易参数。系统将运行一系列模拟,并为你提供具有最佳可能结果的股票列表。
该软件还具备回测功能,通过查看你过去的交易决策和市场状况来评估你的表现。它还提供了一个演示组合,你可以在不使用真实资金或加密货币的情况下运行交易场景。此外,它还提供了一种方式,通过单一应用程序跟踪你的加密货币交易表现,无论是单独的还是汇总多个交易所的数据。
软件的另一个关键优势是其操作安全性水平。该软件仅在通过严格的身份验证流程后才与加密交易所连接,以保障您的安全。它还允许您控制交易机器人在您的交易平台上拥有的权限,作为风险缓解过程的一部分。
1.2 模式发现
在高度数字化的市场,例如股票和外汇产品市场,AI 解决方案承诺提供竞争定价、管理流动性、优化和简化执行。重要的是,用于交易的 AI 算法可以通过动态方式优化大小、持续时间和订单大小,根据市场条件增强流动性管理和大订单执行,以最小化市场影响(Joshi 等人 2021;刘 2021;泽义和王 2021;Sanz 等人 2021)。
使用 AI 和大数据进行情感分析来识别主题、趋势和交易信号,这是一种并不新鲜的做法。交易员们已经几十年来一直在挖掘新闻报道和管理公告/评论,试图了解非金融信息对股票价格的影响。如今,通过 NPL 算法对社交媒体帖子、推文或卫星数据进行文本挖掘和分析,是创新技术的应用示例,这些技术可以为交易决策提供信息,因为它们具有自动收集和分析数据的能力,并且能够在人类无法处理的规模上识别持久的模式或行为。
AI 管理的交易与系统性交易的不同之处在于,AI 模型根据变化的市场条件进行强化学习和调整,而传统的系统性策略由于涉及大量人为干预,调整参数需要更长的时间。基于历史数据的传统后测策略可能无法在实时交易中提供良好的回报,因为先前确定的趋势会崩溃。ML 模型的使用将分析转向实时趋势的预测和分析,例如使用“前进步进”测试而不是后测。这些测试预测并实时适应趋势,以减少基于历史数据的后测中的过拟合(或曲线拟合)和(Yin 等人 2021)。
我们现在开始谈论算法轮。算法轮是一个广义术语,涵盖了完全自动化的解决方案,到大部分由交易员指导的流量。
基于 AI 的算法轮是一种自动路由过程,嵌入了 AI 技术,用于从预配置的算法解决方案列表中为订单分配经纪算法(Bharne 等人 2019)。换句话说,基于 AI 的算法轮是选择最佳策略和经纪人的模型,通过这些模型,可以根据市场条件和交易目标/要求路由订单。
投资公司通常使用算法轮盘的原因有两个:第一,通过改进执行质量来实现性能提升;第二,通过自动化小订单流或将经纪人算法规范化为标准命名约定来获得工作流效率。市场参与者认为算法轮盘减少了围绕经纪人选择和在市场中部署的经纪人算法的交易员偏见。
从历史角度来看,AI 在模式发现中的应用经历了不同阶段的发展和相应的复杂性,在每个过程的每个步骤都为传统的算法交易增加了一层。第一代算法由具有简单参数的买入或卖出订单组成,随后是允许动态定价的算法。
第二代算法采用策略来分解大订单,减少潜在的市场影响,帮助获得更好的价格(所谓的‘执行算法’)。基于深度神经网络的当前策略旨在提供最佳的订单放置和执行方式,以最小化市场影响(Sirirattanajakarin 和 Suntisrivaraporn 2019)。深度神经网络通过一组设计用于识别模式的算法来模仿人脑,并且不太依赖人为干预来运作和学习。使用这种技术对市场做市商有利,可以增强他们的库存管理并减少资产负债表的成本。随着人工智能的发展,人工智能算法演变为自动化的、计算机程序化的算法,可以从使用的数据输入中学习,并且不太依赖人为干预。
在实践中,当今更先进的人工智能形式主要用于识别‘低信息价值’事件中的信号,这些事件由流量交易组成,包括不太明显的事件,难以识别和提取价值。人工智能实际上不是用来帮助执行速度,而是用来从数据中提取信号并将此信息转化为交易决策。较不先进的算法主要用于‘高信息价值事件’,这些事件包括金融事件的新闻,对所有参与者都更为明显,执行速度至关重要。
在目前的发展阶段,基于机器学习(ML)的模型并不旨在进行前瞻性交易并从行动速度中获利,例如高频交易(HFT)策略。相反,它们主要限于离线使用,例如用于校准算法参数和改进算法的决策逻辑,而不是用于执行目的。然而,随着人工智能技术的进步,并在更多用例中部署,它可能会增强传统算法交易的能力,对金融市场产生影响。当人工智能技术开始在交易执行阶段得到更广泛部署时,这种情况预计会发生,提供增强的自动化交易执行能力,并为从信号采集到策略制定,再到执行的整个行动链提供服务。基于机器学习的执行算法将允许在交易过程中自主和动态地调整其决策逻辑。在这种情况下,已经适用于算法交易的要求。
1.3 虚拟助手
商业智能
有许多软件解决方案致力于所谓的商业智能,即在商业环境中做出经济决策的能力。有许多软件解决方案致力于所谓的商业智能,即在商业环境中做出经济决策的能力。例如 Gravity 的产品(www.gogravity.com/)。一个例子是www.gogravity.com/。我猜想在银行环境中有一个应用。
银行需要适应客户发展前景的变化,降低成本,避免因快速启动的竞争对手而损失业务,并寻找创新方式来增加收入。银行的需求在实践中因快速增长,以及广泛的产品线而面临挑战(Mendoza Armenta 等人 2018)。银行经常面临处理与客户呼叫中心和客户电子邮件相关的查询量增加的问题,而且众所周知,传统的银行客户服务模式在财务审慎平衡和调整方面存在不足。因此,银行正在实施聊天机器人或“高科技人格”。这些可以提供自动化的帮助,例如处理常见问题;完成金融服务;并协助财务申请(Kurshan 等人 2020)。
诈骗
随着电子商务欺诈或在线诈骗的增加,避免它们变得不那么可能。最近,美国报告的欺诈检测率是实际欺诈率的 15 倍。人工智能如今变得触手可及。通过调查统计数据的支持,应用程序实践的过程现在可以识别虚假合同,而无需向人类专家提供一些信息,提高了实时授权的准确性,并减少了错误失败。跨国公司目前正在探索人工智能,以识别和交叉检查金融部门的不确定性预防。我们可以观察到的人工智能应用的最佳用途之一是与万事达卡合作。如果诈骗者试图通过窃取信息和数据使用他人的万事达卡,人工智能决策智能技术将分析实际数据,并向真实持有者的电子邮件或智能手机发送即时通知,以及与个性化钱包相关的所有通信媒介。
保护安全
许多管理机构正试图将人工智能纳入其中,以提高运营交易和相关服务的安全性。如果有处理器访问权限,可以准确预测非法数据库,这是可能的。
支出配置预测
人工智能对于消费者支出识别非常有用,被许多公司和金融服务部门采用。当汽车被盗或账户被黑客攻击时,它将有助于避免欺诈或盗窃。
股票交易系统
计算机系统已被训练用于预测何时买卖股票,以便在不确定性和市场崩溃期间最大化利润并最小化损失。客户端用户验证:这可以再次验证或识别用户,并允许交易发生。
第二章:AI,整体视角
Luca Marconi^(1 )(1)意大利国家研究委员会认知科学与技术研究所,人工智能、大脑、心灵和社会高级学校,罗马,圣马丁诺德拉巴塔利亚 44 号 Luca MarconiEmail: luca.marc@hotmail.it
摘要
如今,人工智能(AI)算法正在被设计、开发和集成到各种不同和异构的应用领域的软件或系统中。AI 明显而逐渐地成为横向和强大的技术范式,这是因为它不仅能够处理大数据和信息,而且尤其是因为它产生、管理和利用知识。研究人员和科学家开始从多个角度探索 AI 将如何以不同而协同的方式转变异构商业模式和所有行业的每个领域。
关键词知识表示推理人工智能机器学习认知科学 Luca Marconi
目前在米兰比科卡大学攻读计算机科学博士学位,研究领域包括人工智能和决策系统,同时也是米兰一家人工智能公司的商业战略师和 AI 研究员。他还在米兰一家知名媒体情报和金融传播私人顾问公司担任研究顾问和顾问。他拥有米兰理工大学的管理工程硕士和学士学位,以及巴利阿里群岛大学交叉学科物理与复杂系统研究所(IFISC UIB-CSIC)的复杂系统物理学硕士学位。他还拥有意大利国家研究委员会认知科学与技术研究所(ISTC-CNR)组织的人工智能、大脑、心灵和社会高级学校的研究生研究证书,在那里他与 ISTC-CNR 的基于代理的社会仿真实验室合作开展了计算社会科学领域的研究项目。他的研究兴趣包括人工智能、认知科学、社会系统动力学、复杂系统和管理科学。
总的来说,AI 有潜力提供比人类专家更高质量、更高效率和更好的结果。这种 AI 的显著和强大潜力正在潜在的每一个应用领域、组织背景或业务领域中显现出来。因此,AI 对我们的日常生活和工作生活的影响不断增加:智能系统正在通过物联网这一强大的技术范式进行建模和互连,自主驾驶汽车正在在异质驾驶条件下进行生产和测试,智能机器人正在为各种挑战和领域进行设计。
实际上,根据世界经济论坛的创始人兼执行主席克劳斯·施瓦布(Klaus Schwab)的说法,人工智能(AI)确实正在为所谓的第四次工业革命做出贡献。他明确表示,AI 是技术场景中的一次重大突破,能够推动我们生活和互动方式的深刻转变。值得一提的是,安德鲁·吴(Andrew Ng)是百度前首席科学家,也是 Coursera 的联合创始人,他在 2017 年的 AI 前沿大会上表示,AI 实际上就是新的电力:一种具有颠覆性和普遍性的横向技术,能够支持甚至赋能潜在的任何领域或领域的技术和流程。因此,AI 能够刺激和重塑人类社会的当前和未来演变,当谈到描绘这一决定性技术范式的不断演变的情景时,对 AI 方法和技术的理解显然至关重要。
在本章中,我们将通过呈现整体情景和主要宏观挑战、方法和对未来 AI 和社会可能发生的步骤进行探讨,探索当前的技术和方法情景。具体而言,我们旨在为读者提供一般的概念工具,以同时处理主要的符号和子符号 AI 方法。最后,我们将专注于人机交互视角,通过回顾人类和 AI 在异质环境中实际上以何种程度互动甚至合作,以描绘朝向混合和集体的社会-AI 系统智能的当前阶段。
2.1 AI 简介
如今,人工智能(AI)正在整个社会中变得至关重要:它绝对是 21 世纪的主要方法论、技术和算法主角之一。人工智能方法和工具的泛滥显然已经为每个人所见:新的算法不断地被设计、利用并集成到各种不同和异构的应用领域的软件或系统中。从业者们意识到人工智能不仅仅是一个技术领域或方法论。事实上,人工智能正逐渐成为一个横跨的、强大的技术范式:它的力量来自于它促进了社会的广泛转型能力,这是因为它不仅能够处理大数据和信息,而且因为它能够产生、管理和利用知识。研究人员正在从多个角度开始探索,人工智能已经从不同的深度和协同的方式刺激了异构商业模式和行业领域的演变(Haefner et al. 2021;Brynjolfsson and Mcafee 2017;Krogh 2018)。
根据 DARPA(Launchbury 2017),对人工智能的一般视角应考虑一组最小的宏观能力,以表示其收集、处理和管理信息的方式:感知、学习、抽象和推理。这些认知能力在整个人工智能方法的领域中并不均匀分布。事实上,目前仍然没有任何单一正式和广泛接受的人工智能定义。尽管目前正在努力寻找统一的定义,但人工智能方法、模型和算法的潜力,以及它们的多重功能、特征和潜在影响,已经影响着人类社会。总的来说,人工智能有潜力在广泛的任务和条件下,与人类专家相比,提供更高质量、更高效率甚至更好的结果(Agrawal et al. 2018)。人工智能的这种重大而强大的影响正在潜在的每一个应用领域、组织背景或业务领域中显现出来。因此,学术研究和经验表明,人工智能对我们的日常生活和工作生活的影响不断增加:智能系统正在通过物联网的方式进行建模和互联,将智能设备连接到强大的生态系统中,自动驾驶车辆正在在各种异构的驾驶条件下进行生产和测试,智能机器人正在被设计用于各种挑战和领域。
从更广泛的视角来看,根据世界经济论坛的创始人兼执行主席克劳斯·施瓦布(2017)的说法,人工智能是所谓的第四次工业革命的主要推动者之一。他明确表示,人工智能是技术场景中的一项基本突破,能够促进我们生活和互动方式的深刻转变。其分析表明,人工智能是这场革命的驱动力之一,物理、数字和生物领域之间存在着多重、协同和复杂的相互作用。足以提及的是,安德鲁·吴,百度前首席科学家兼 Coursera 联合创始人,在 2017 年的 AI Frontiers 大会上发表的主题演讲中表示,人工智能真的是新的电力:一种具有颠覆性和普遍性的横跨技术,能够在潜在的任何领域或领域支持甚至赋予技术和流程。因此,人工智能不仅仅是一种有限但强大影响的简单工具:相反,它在人类和非人类生态系统中的行动和相互作用直接导致了它们的新状态、条件和新兴行为,在一个复杂的社会技术总体视角下。因此,当涉及描绘这一决定性技术范式的演变场景时,理解人工智能方法和技术绝对至关重要。
在本章中,我们将通过呈现整体图景和主要的宏观挑战、方法和未来人工智能与社会可能发生的步骤来探索人工智能的当前技术和方法论情景。在文献中,有各种各样的分类和分类方法来对人工智能方法进行分类。本章并不打算涵盖所有问题和方法,也不打算提供全球、整合和全面的审查,包括整个最新技术状态的整个情景。然而,它旨在提供关于人工智能的两个广泛维度——认知和交互的主要宏观方法和范式的一般概述。具体来说,我们旨在为读者提供通用的概念工具,以接近主要的符号和次符号人工智能方法。最后,我们将关注于人工智能与人类互动的视角,通过审查人类和人工智能在异质环境中实际互动甚至合作的程度,以描绘当前朝着混合和集体的社会-人工智能系统智能的阶段。
2.2 历史视角
尽管人工智能在当前技术场景中扮演着基本的角色,但人工智能系统的设计、开发和评估的初期阶段实际上在历史上并不是新鲜事物。该学科的正式诞生可以追溯到 1956 年,当时 Marvin Minsky 和 John McCarthy 在新罕布什尔州达特茅斯学院举办了达特茅斯人工智能暑期研究项目(DSRPAI)。达特茅斯会议涉及了一些主要的和最重要的历史上的人工智能“奠基人”,包括 Allen Newell、Herbert Simon、Nathaniel Rochester 和 Claude Shannon。达特茅斯活动的主要目的是创建一个完全新的研究领域,重点研究设计和构建智能机器的挑战。随后的提案(McCarthy 等人 2006)为在计算机中对智能进行分析研究奠定了基础,并确定了应用相关方法学的第一个基本概念,例如信息理论,用于研究人工智能。
尽管学科发展的后续阶段并不像创始人们所想象的那样容易。尽管进一步创造了第一批算法和计算机程序,但明斯基乐观地声称人工智能很快就能够模拟和仿效人类智能的说法并未得到证实,尽管那段充满狂热活动的时期进行了不懈的努力。那些年的一些成果包括 ELIZA(Weizenbaum 1966),这是一种自然语言处理工具,某种程度上预示了现代聊天机器人的出现,以及通用问题解决器(Newell 等人 1959),这是一个基于逻辑的程序,旨在创建一个通用问题解决器,但实际上只能解决特定类别的有限问题。在那个时期采用的基本方法主要依赖于逻辑和显式知识表示,完全采用符号视角,旨在通过演绎和线性的if–then逻辑路径处理经验和心理数据。总体而言,人工智能的最初阶段的野心是迅速而有力地催生所谓的强人工智能,或人工通用智能,即完全能够模仿甚至取代人类自然智能的人工智能系统。然而,选择纯逻辑方法的应用导致了固有的有限方法,利用 DARPA 特别称为手工制作的知识(Launchbury 2017)仅为狭义选择和预定义的一组有限问题提供了推理能力。这些系统没有任何学习或抽象能力,因此未能满足学科的创始人们的雄心勃勃的期望。
结果,学者和政府开始质疑初期对人工智能的乐观浪潮和概念上的蓬勃发展。在 70 年代,美国国会和英国议会严厉批评了之前用于研究和设计人工智能系统的经费。在同一时期,英国数学家詹姆斯·莱特希尔(James Lighthill)发表了所谓的Lighthill 报告(James 等人 1973),由英国科学研究理事会委托,在大学和学者之间经过长时间的讨论后:这份报告最终开始了人工智能的艰难时期,之前人工智能研究人员给出的乐观前景被抛弃了。 Lighthill 报告收集了失望的主要原因,包括人工智能系统在解决泛化设置中的真实世界问题方面的能力有限,尽管在模拟有限心理过程时取得了令人鼓舞的结果。结果,人工智能领域的研究部分被放弃,多个支持基金被终止。
然而,1986 年连接主义(McLeod 等人 1998)的出现标志着人工智能重新兴起的一个时期,从一个不同的,有些相反的角度。除了取代人类智能的任何野心外,连接主义方法和哲学的目标是研究作为来自相互连接的神经单元的工作行为和相互作用的新兴过程的心理模型及其相关认知和行为现象。这种向大脑机制的概念转变在某种程度上预示了进一步的神经科学介入人工智能,以及人工智能与复杂系统理论(San Miguel 等人 2012)之间的协同作用和关系,其中大脑和神经系统实际上是突出的示例和案例研究。连接主义的兴起开始了人工神经网络的研究和设计的基础时期,试图模拟大脑上的认知机制,同时基本上假设知识主要来源于神经系统与外部环境的相互作用。尽管机器学习的基础可以追溯到上世纪 40 年代唐纳德·赫布(Donald Hebb)的工作,以及所谓的赫布学习理论(Wang 和 Raj 2017),但其创立和初期发展的最重要支柱是由马文·明斯基(Marvin Minksy)、詹姆斯·麦克莱兰(James McClelland)、大卫·鲁梅尔哈特(David Rumelhart)和弗兰克·罗森布拉特(Frank Rosenblatt)等研究人员刺激的,他们构想了感知机(Rosenblatt 1958),即第一个神经网络模型,从而提出了进一步研究反向传播训练和前馈神经网络的基本方法。
同时,历史的进程导致了人工智能演化的其他重要步骤:首先是广泛范围的人工生命方法的奠基,它通过模型如群集、细胞自动机(Langton 1986)和自组织,扩大了使算法类似生物和行为学现象的野心。将模拟和计算机模型应用于自组织相互作用的代理和系统的研究是向当前意识到需要利用人工智能和复杂系统之间众多潜力的步骤之一,在当前和未来广泛的社会系统和人工智能视角中。此外,神经科学方法的涉入,以及发育和表观遗传机器人学的兴起(Lastname 等人 2001)增加了对通过神经科学、发育心理学和工程科学的整合来理解生物系统的重要贡献。
尽管如此,直到 21 世纪初,人工智能才开始发挥其全部潜力,这要归功于计算资源和计算机性能的同步指数增长,以及在各个领域提供大量和异构数据的可用性。不断增长的智能系统算法的巨大潜力目前正在经历辉煌时期,人工智能方法和技术的发展正在促成整个社会不可避免的影响和即将出现的现象。
2.3 人工智能对社会的影响
总的来说,人工智能对社会的影响深远而本质上多面。尽管与整体人类智慧相比,其“智力”仍然有限,但人工智能的主要力量源于其能够应用于潜在的每一个应用领域。人工智能代表了与其他技术相比的真正飞跃,由于其普遍、颠覆性和技术赋能结构:它被描述为一种使能技术(Lee 等人 2019;Lyu 2020),通过其生产、管理和丰富知识的能力来赋能其他技术。这些结构支柱使人工智能成为不仅仅是一个局限的和单纯的技术工件的“大”和“更多”的东西。人工智能被认为是技术和方法论的范式,用于技术自身和组织的演变。因此,考虑到其广泛的应用范围,影响我们世界的许多情况和背景,以及人工智能与人类之间不断增长的互动,值得强调的是,人工智能对社会的影响并不边缘,而是有可能在社会技术和社会-人工智能系统视角下彻底改变社会的潜力。
这一过程仍在进行中,引发了重大且不可避免的伦理问题。尽管人工智能具有强大的性质,但人类无法摆脱这样一个明确的决定,即他们是否打算将其视为一种工具——或者说,一种令人印象深刻的方法论和技术范式——即作为达到目的的手段,或者在某种程度上将其视为终极目标。从另一个相关的视角来看,伦理挑战始终根植于人类关于他们如何设计人工智能以及他们打算如何利用人工智能的潜力、能力和结构应用的选择。这一选择明确反映了人类的自由意志:因此,这无疑是一个只有人类智慧和本性才能通过的基本十字路口。然而,对人工智能在社会中的许多和重要的伦理含义进行审查并不是本章的重点。
毫无疑问,人工智能对我们社会的影响不断增长和发展:只需考虑到,根据国际数据公司(IDC)的数据,全球对人工智能的投资和市场预计将在 2023 年突破 5000 亿美元(IDC 2022)。此外,统计门户网站 Statista 预测,全球人工智能市场规模将在 2024 年达到 5000 亿美元以上(Statista 2022)。因此,就业市场的演变需要工人和利益相关者将他们的技能和元素能力适应一个迅速转变的场景。根据世界经济论坛的数据,超过 60%的今天开始上学的孩子将在尚不存在的工作中工作(世界经济论坛 2017)。此外,牛津马丁经济学院报告称,在未来 20 年内,美国所有工作职能中最多可自动化 47%,这将导致一个与我们所知和所处的世界非常不同的世界(Frey 和 Osborne 2017)。值得特别注意的是,Gartner 将人工智能视为 2022 年度 Gartner 十大战略技术趋势中两个互补基础趋势之一(Gartner 2021):人工智能工程 和 决策智能。人工智能工程专注于通过 AI、机器人流程自动化(RPA)、业务流程管理(BPM)等协同技术和方法论方法的完整识别和运作,来检测和自动化业务和 IT 流程。相反,决策智能是一种系统化的方法,通过强大和广泛的人工智能和人工智能的使用,来对高度复杂的情况和业务条件进行建模和有效管理,通过 连接、上下文 和 连续 的决策过程来提高组织决策的效率。
因此,人工智能对潜在的任何业务领域的影响对于组织的发展和数字转型越来越关键。人工智能正在影响技术和组织的视角和流程,从而重塑组织并重新定义技术、管理和业务之间的互动。此外,人工智能方法和算法的持续增长几乎每天都会提供比人类领域专家在异质领域和条件下更高质量、更高效率和更好结果的潜力。在组织和业务框架中,这意味着人工智能倾向于在决策者和技术人员的范围之外提供帮助,因此不仅仅是一种工具,而是一种决策辅助,也可用于管理任务。例如,基于人工智能的解决方案在联合利华的人才招聘流程(Marr 2019)中发挥着重要作用,在 Netflix 关于电影情节、导演和演员的决策过程(Westcott Grant 2018)中发挥着重要作用,以及在辉瑞公司的药物发现和科学发展活动(Fleming 2018)中发挥着重要作用。
如今,计算能力和资源的最新进展、数据可用性的指数增长以及新的机器学习技术正促成这种影响。尽管人工智能有着相对悠久的历史,但正是今天,我们才有了这些技术因素的同时存在,使得人工智能在社会中的应用快速发展成为可能。我们在 21 世纪初期面临的指数增长现象——即计算能力和数据可用性的指数增长以及信息学在方法、算法和基础设施方面的进步——构建了一个科学和技术发现、市场机遇和社会影响的协同系统。这种良性循环已被国家和国际机构认真识别,导致对涉及公司、初创企业、研究中心和大学的技术转让项目的支持日益增加。对于促进国家创新的有价值的技术转让项目的关注已被许多机构任务组、工作组以及特别是最近的人工智能国家战略文件的出版所确认,比如意大利的情况。
然而,让我们退一步,有效地理解为什么以及如何人工智能对当前社会产生如此巨大的影响。要深入理解人工智能在产生、管理和利用知识方面的作用,有必要开始思考智能和认知能力是什么。我们不能回避从不同互补视角考察的概念进展:从数据到知识,从能力到智能,进而从社会到社会人工智能系统。
2.4 认知科学框架
为了提供对当前人工智能场景的概念化组织概述,基于更广泛的认知科学视角和学科是至关重要的。实际上,设计、实现和评估能够强大地封装和利用认知能力的有效人工智能系统,使我们开始质疑智能的确切本质。认知科学试图通过其概念框架和对心理特征和活动的分类来回答这样的问题。本节的目的绝对不是提供对这一学科大景观的全面和完整的审查。相反,我们报告了一组有限的基本概念,这些概念后来被证明对理解和欣赏主要报告的人工智能系统和方法的宏观类别的进一步描述是有用的。
首先,我们必须考虑一个三重概念框架,这已经在上一节的末尾预见到:从数据到知识,从能力到智能,进一步则是从社会到社会人工智能系统。尽管这个概念架构的第一个支柱与知识表示机制的对象相关,但第二个支柱则允许考察非常不同的认知能力和智能的结构。最后,第三个支柱将考虑的视角扩大到人类和人工认知系统之间的相互作用,预见到了认知科学视角下的人机交互的基本主题。
在认知主义方法中,大脑及其内部工作机制可以被认为是一个认知系统,通过事先定义的内部组织和结构来收集、管理和加工信息(Garnham 2019)。这种结构在某种程度上类似于计算机,利用一组内部认知特征和能力,以及其传输通道上固有的有限信息处理能力。因此,在这一视角下,心理机制在理论上类似于软件的机制,或者更好地说是一种完整但有限的电子大脑,从外部输入源收集和加工数据和信息,并通过某种知识表示方法输出信息和知识。此外,通过一系列迭代反馈, elicited 知识的逐步改进和演化可以受益于更好地利用收集到的数据及其被大脑机制加工。相反,认知科学和心理学的进一步发展导致了两种互补的视角:一方面,通过模块化(Fodor 1985)和连接主义(Butler 1993)的范式,深化了心智与计算机之间的类比;另一方面,在更建构主义的视角下(Amineh 和 Asl 2015),经验和社会互动的作用变得更加重要。
此外,智力本身的性质也没有被广泛或正式地接受的固定定义方式。类似于 AI 的情况,在科学界缺乏一个独特的官方定义,智力的整体结构也没有被一个局限和全面的概念完全捕捉到,涵盖了所有可能的认知特征和特性。在学者们研究的可能的二分法中,有所谓的流体和结晶智力(Ziegler et al. 2012),分别研究认知代理人如何对新情况进行推理并利用先前引发的知识,逻辑和创造智力的区别,直到情感智力(Salovey 和 Mayer 1990)的概念,影响甚至更广泛的心理和社会情况和条件。即使在临床实践中,目前广泛接受的是,用于诊断过程的当前心理测量智商测试,本质上是有限的:事实上,它们通常受到一系列限制的限制,与设计和利用完全无文化测试的困难有关(Gunderson 和 Siegel 2001),以及它们固有的能力仅检验有限的认知能力集合。值得注意的是,多重智能理论(Fasko 2001)试图考虑一个更广泛的框架,涉及几种宏观能力,从语言-语言到逻辑-数学和视觉-空间,甚至到身体动作和音乐-和谐智力。
对于我们的范围,值得强调两个主要方面:
-
目前,将注意力集中在便于研究以增强人工智能系统的特定认知能力上也是功能上有用的。 DARPA 分类(Launchbury 2017)证明了通过将它们归纳到四种宏观能力中来有效地涵盖可能的广泛认知特征的广泛范围,以表示认知系统收集、处理和管理信息的方式:感知、学习、抽象化和推理。
-
在呈现人工智能系统及其与人类认知能力和社会的关系时,考虑到两个主要维度也是功能上方便的:认知,如前所述,以及交互,旨在扩展社会 -AI 视角,面向人工和人类代理。
因此,在接下来的章节中,我们将按照之前提供的指南,提供人工智能方法的主要宏观类别。我们报告的概述并不旨在涵盖不断发展的人工智能场景中所有可能的方法和算法:相反,我们的目标是展示从认知和社会交互角度看人工智能方法的宏观类别的概述。总的来说,我们将为读者提供一般的概念工具来了解人工智能领域,以及欣赏人类和人工智能在异质性背景和情境中实际上相互交互甚至合作的程度,从而勾勒出通向混合和集体社会 - 人工智能系统智能的当前阶段。
现在让我们放大一个我们必须考虑以有效分类当前人工智能方法及其不同潜力的重要二分:符号和子符号人工智能。通过关注这两个宏观类别,我们将承认此分类的相关性,以某种方式概括所展示的认知特征,以及帮助读者欣赏所报告方法的互补认知潜力。
2.5 符号和子符号人工智能
符号和子符号人工智能之间的二分已经源自于认知主义(Garnham 2019)和连接主义(Butler 1993)之间的二分:这样的范式实际上涉及两种相反的智能观念。一方面,认知主义将思维视为计算机,遵循逻辑和正式预定义的规则和机制,以及操纵符号,封装来自外部环境的异质数据和信息,并通过反馈和输出结果的迭代过程进行。另一方面,连接主义考虑了智能的生物性质,描绘了一个基于单个单元—神经元—的并行参与的认知系统,通过神经元之间的相互作用处理所感知的信息。虽然认知主义通过人类思维和纯粹逻辑和正式化方式工作的人工信息处理系统之间的完全类比获得了其观点,但连接主义基于这样一个思想:认知潜力直接来自于相互连接的神经元之间的大规模互动,智能是从收集到的信息和数据的分布式加工中产生的。
作为前进的一步,符号和子符号 AI 的区别变得清晰起来。前者处理符号和知识表示和管理的逻辑手段,而后者使用数字,非逻辑和非形式化的现实表示。符号 AI 允许通过谓词组成的逻辑规则来操作符号,这些谓词通过逻辑运算符连接起来。通过这种方式,系统中允许的所有知识都可以通过所利用的形式边界和操作进行精确形式化和约束。相反,子符号 AI 允许通过数学运算符来处理它所处理的信息元素和因素,这些运算符能够管理来自环境的数字和数据,并通过连接的神经元促进进一步的学习过程。总的来说,符号 AI 在高级别视角下运作,例如所涉及的元素可以是对象和它们之间的关系。相反,子符号 AI 在低级别运作,例如所涉及的元素可以是图像像素、位置距离、机器人关节扭矩、声波等。
在符号 AI 范式中,我们可以将不同的问题表示为知识图谱(张等人 2021; 季等人 2021),其中节点通过逻辑符号表示特定对象,而边则编码了操作这些对象的逻辑操作。一切都以状态空间表示,即允许配置特定问题或情况的一组有限可能状态。结构本质上是分层和序列的:从根节点开始,表示初始情况,不同的节点通过几个层连接起来,根据所考虑的允许情况和条件。当状态中的所有同意行动都已执行时,最终节点是一个叶节点,编码了导致它的所有行动和过程的结果。显然,可以有不同的过程得到特定的结果并达到所期望的状态。因此,可以沿着图中的各种路径进行导航,涉及异构节点和边缘,从给定的根到所需的叶子。因此,符号 AI 可以与 DARPA(Launchbury 2017)所说的第一波 AI联系起来,处理手工制作的知识,利用推理能力解决狭窄范围的问题,没有任何学习或抽象能力,且在处理信息不确定性和复杂性方面能力较弱。
在亚符号范式下的人工智能中,相反地,所收集的信息是通过人工神经网络(Shanmuganathan 2016)管理的,由相互连接的神经元组成,能够通过“嵌入式”函数管理数据和信息。神经元根据特定的阈值激活,涉及一些参数,然后操作管理的信息元素,生成的输出信息可以作为系统学习过程和进一步分析的基础。因此,整个亚符号人工智能系统通过并行分布处理机制工作,在这种机制中,信息由参与的不同神经元并行处理。因此,在完全连接主义和新兴主义视角下,亚符号人工智能范式允许将心理或行为现象建模为直接从局部单元的互连中产生的新兴过程,这些过程在特定网络中链接。这些工作机制涉及统计学习,其中模型是在大型和异构数据集上进行训练的,就像与特定领域相关的大数据案例一样。这样的人工智能的第二波—正如 DARPA 所称的那样(Launchbury 2017)—具有感知和学习能力,但它的推理能力很差,完全缺乏抽象能力。
在后续章节中,我们将通过考虑认知和交互的两个主要维度,呈现不同的方法。关于认知,集中在符号和亚符号人工智能方法之间的这种二分法是有用的(但肯定不是全面的),以便对人工智能的整体情况有一个大致的了解。在这个选择的框架中,所呈现的人工智能方法和范式的一般概念图在以下图中得到了视觉呈现。认知大致分为符号和亚符号方法,涵盖了不同的认知特征和能力。相反,交互在人类-人工智能和人工智能-人工智能交互之间进行功能分类。在我们的方法中,我们并不打算声称自己的方法是详尽的或是独家的,我们只是想为读者提供一个视觉草图,以更好地理解后续章节和随后呈现的方法(图 2.1)。
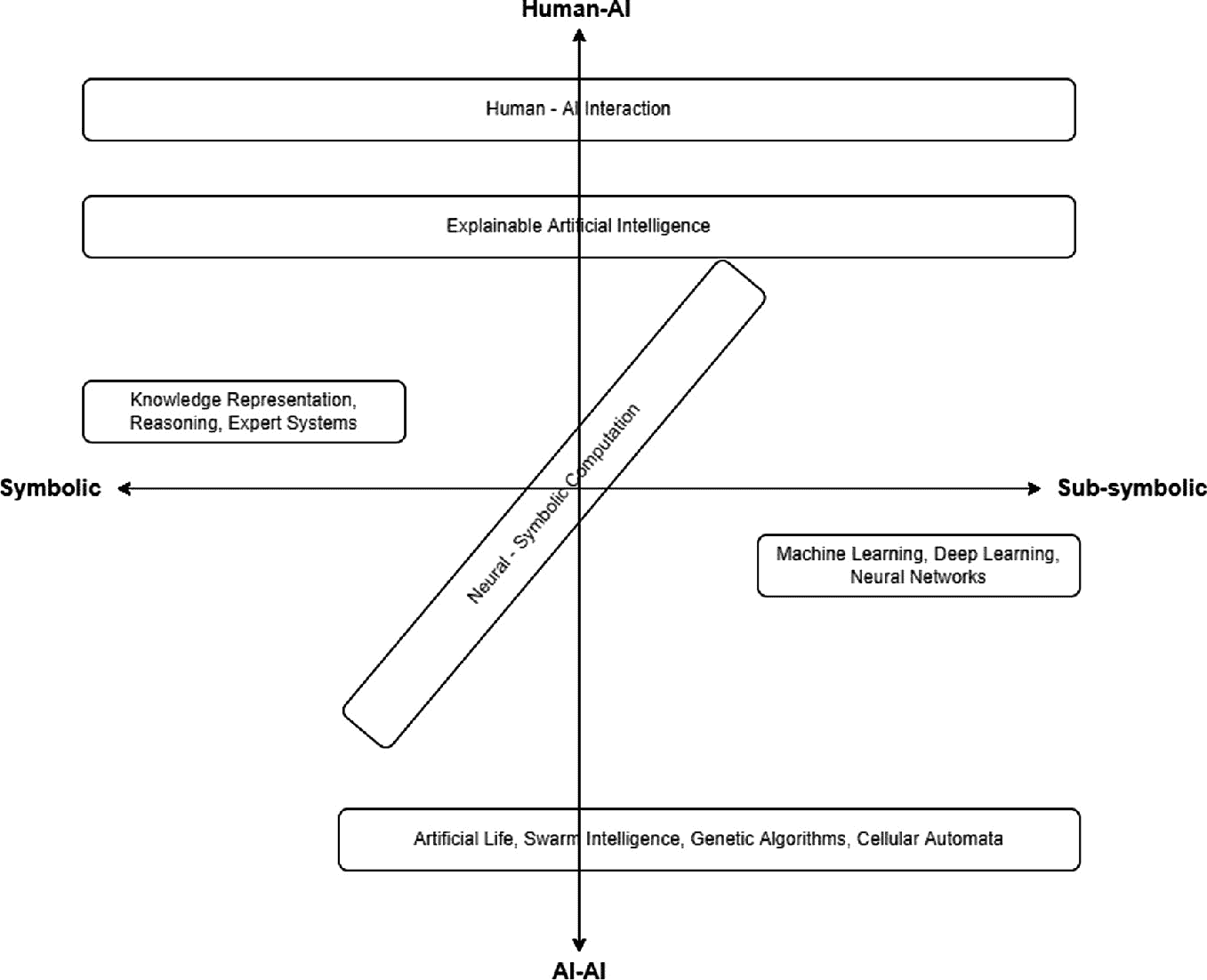
人工智能方法的四个象限绘制了人工智能方法与人类人工智能、人工智能与符号到亚符号的对比。人类人工智能具有人类人工智能交互和可解释的人工智能。亚符号具有机器学习、深度学习和神经网络。人工智能连字符人工智能包括人工生命、群体智能、遗传算法和细胞自动机。符号具有知识表示、推理和专家系统。
图 2.1
人工智能方法和范式的概念图
尽管我们将在本章后续部分详细考察所有这些宏观方法和方法,但已经有用的是将这些方法如何定位于认知和交互的两个主要维度的概念框架中进行上下文化。关于认知,我们在符号和亚符号之间功能性地对所呈现的 AI 方法进行分类:因此,可以相对直接地相应地定位方法。相反,交互的维度功能性地考虑了人工智能与人类的交互以及人工智能与人工智能之间的交互,假设了一个扩展的社会人工智能视角。考虑到这些参考,因此可以得出这样的结论,即轴的原点代表完全没有与人类或人工智能代理的交互存在的情况。因此,根据在概念地图中的交互的分类和“程度”,定位方法。我们提醒这只是报告的 AI 方法的粗略视觉表示,以帮助读者更好地欣赏和理解 AI 景观的概述,根据提供的分类方法。
2.6 知识表示与推理
让我们继续我们对当前人工智能场景的概述,通过介绍与知识表示领域相关的主要和关键的符号方法和方法。虽然这些方法在人工智能历史的最初阶段曾经备受炒作,但毫无疑问,它们今天仍然是相关的,并且在多个应用领域可以找到许多应用。表示知识基本上意味着通过预定义的语言、模型或方法形式化它。因此,知识表示(《知识表示手册》2008)的目的是研究、分析和应用所有广泛的框架、语言、工具来表示知识,以及对其进行不同形式的推理。符号视角绝对是基础的,因为在不同系统中使用符号来表示异构知识库是至关重要的。从这个角度来看,智能体被赋予了一组圈定的符号来表示外部世界(知识表示),并且能够根据规则和原则对其进行具体的推断。因此,基于知识的系统(KBS)(Akerkar 和 Sajja 2009; Abdullah 等 2006)的主要能力是通过一种符号化的建模语言逻辑地和符号地表示世界的固有有限部分,以及再次通过一种逻辑和形式化的方法推理,以发现所表示的世界的进一步特征、特性或属性。在 DARPA 对人工智能方法的有用分类中,这恰好对应于第一波人工智能:利用手工制作的知识的系统,甚至能够推断出特定表示世界中外部环境或代理的重要隐藏方面、特征或行为,尽管它们缺乏像学习或抽象这样的基本认知能力。
为了有效地表示知识,许多方法论和工具已被研究人员、学者和实践者广泛利用。特别值得一提的是逻辑的运用,尤其是一阶逻辑(FOL),作为一种强大的方法论和形式化方法,被广泛应用于许多应用领域和领域中。FOL 基本上能够利用广泛的命题、运算符和量词,以有效地形式化预定义和指定领域的知识库。此外,如今模糊逻辑的作用至关重要,以使 AI 系统能够在信息复杂性和不确定性极高的条件下表示知识并进行推理。除了逻辑之外,还重要提及本体论和知识图谱的作用,以在限定领域内捕捉明确且自然界定的知识。事实上,显性知识和隐性知识之间的差异对于理解知识表示和 KBS 的主要挑战和原因至关重要。前者已经在符号框架中表达,因此易于通过某种语言或系统进行交流,而后者是隐含的,通过个体在经验、教育、传统、社会互动、直觉和其他复杂的动态知识生成过程中经验性地获取。因此,本体论和知识图谱作为表达概念要素、对象及其关系的手段,传统上有效地局限于表示显性知识,而最近提出的几种方法和算法则应对在组织和工业领域中形式化隐性知识的挑战。
无论如何,第一个也许是最主要的挑战出现在符号形式化阶段之前:事实上,引发知识 的过程至关重要且极其微妙,特别是在高度复杂的领域或组织环境中。虽然知识基本系统明显缺乏将其推理能力抽象化或延伸到未形式化的变量、规则或行为的能力,但知识工程 的角色主要是致力于改进知识管理系统 和工具的质量和数量。在复杂的组织中,这意味着增强甚至彻底改革整个组织的信息系统 或其当前的功能。此外,这还意味着让所有相关的利益相关者或决策者意识到他们在知识共享、知识管理和知识丰富化 过程中的潜在角色。这种基于知识的对运营流程和人类决策的改进可以通过 AI 工具得到有效的帮助,这些工具已经在各种领域进行了研究和应用,包括异构操作系统、制药和临床领域以及教育。
在知识表示和推理领域,最可能被熟知和利用的人工智能方法与专家系统 领域相关。从最早的人工智能浪潮开始,一直到现在,这些系统已被广泛设计、开发和应用于各种应用环境中。专家系统的能力明确是专注于一个狭窄但精确表示的领域,并推断与该领域相关的问题的解决方案。许多应用包括临床和医学应用、工业环境以及销售和营销的产品配置器。基本上,专家系统适用于替代特定过程、选择或行动的人类领域专家。通过这种方式,它们帮助决策者和经理提高他们在异构业务、组织或工业过程中的决策和行动的效力和有效性:在解释来自传感器的数据和信息、向临床医生建议潜在的诊断、识别潜在的风险和检测行为以及通过改进规划和编程过程帮助经理实现业务目标的问题解决方面,它们的帮助是显著的。因此,专家系统通常是决策支持系统 的基础或组成部分:这些系统通过包括几个模块和组件来捕获、组织和管理数据和信息,从而增强公司中的经典信息系统,以支持商业背景下的战略决策过程。
KBS 通常根据两种互补的分类而分类:一方面,考虑潜在应用,另一方面考虑问题解决方法:换句话说,知识表示和推理方法。就应用而言,KBS 可以分为知识捕获和存储系统、知识部署和共享系统和知识处理系统。这种分类允许专门关注所考虑系统的具体能力,贯穿整个收集、管理和阐述数据和信息以获取有用知识的整个过程。根据问题解决方法,KBS 可以分为基于规则的、基于案例的和基于模型的系统。这样的分类直接源自推理方法的分类。实际上,KBS 所利用的内部推理机制可以基于逻辑规则,或者利用类比和案例进行推理,或者利用特定的基于模型的描述。下图旨在帮助读者欣赏与知识表示和推理方法及系统相关的不同阶段和概念(图 2.2)。
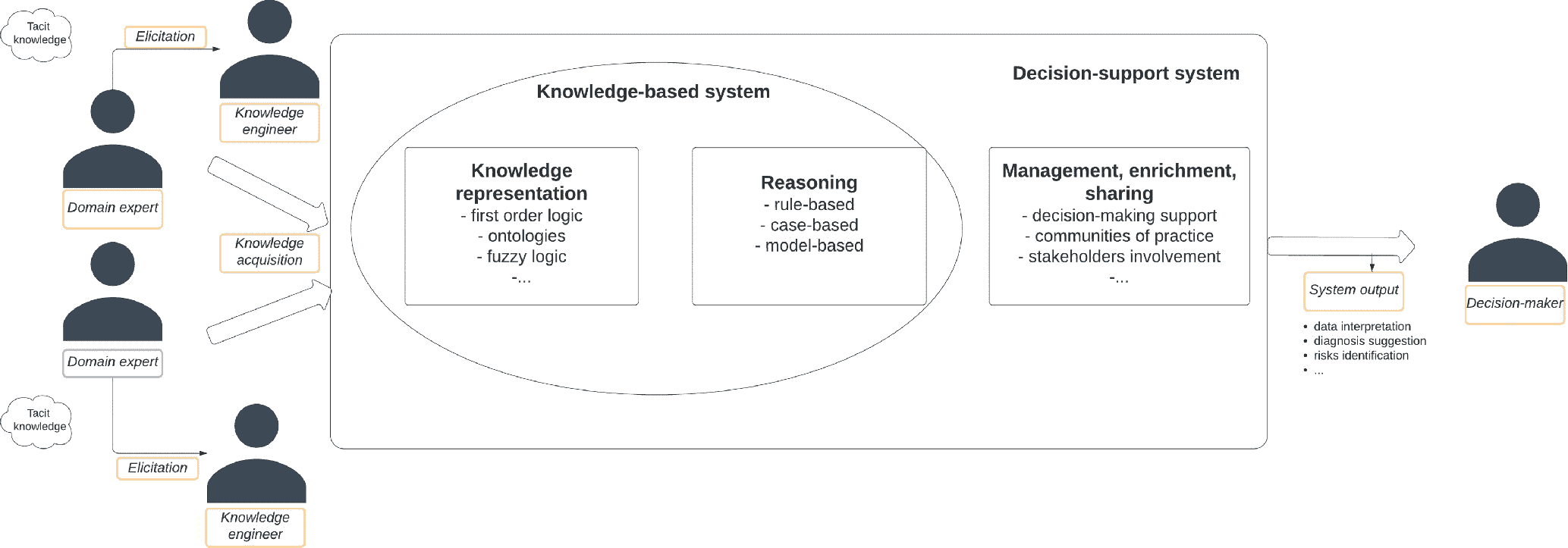
流程图说明了领域专家通过引发成为知识工程师。知识获取导致基于知识的系统和决策支持系统。基于知识的系统包括知识表示和推理。决策支持系统包括管理、丰富和共享。它导致系统输出和进一步的决策标记。
图 2.2
知识表示和推理过程的概念表示
这种符号和知识管理方法的使用在明确定义的领域或环境中代表和阐述知识时确实是有用的。当涉及到从广泛和复杂的数据集中学习时,问题就出现了,这些数据集通常在结构上是异构的或来自不同的来源。从过去的数据中学习并预测未来的行为、情况或状态的能力是 AI 的另一个主导范式的典型特征:连接主义,具体而言,是机器学习方法。
2.7 机器学习与深度学习
在当前 AI 方法、方法论和算法的情景中,主导范式的主要部分归功于机器学习。这仍然是真实的,但绝不能被视为理所当然,因为 AI 不断经历着快速、动态且有些不可预测的演进,这得益于技术、数据来源和可用性的进步,以及组织和整个社会的发展。尽管如此,机器学习模型在 AI 方法和算法的全球范围内尤其重要,因为它们能够分析大量数据、从中学习并预测新的、未知的行为,或者在不同的环境条件下对新实例进行分类。
从总体上看,机器学习(ML)是一门致力于设计、构建和评估基于 AI 的模型的学科,这些模型能够通过识别相关的模式和行为,从样本、训练、预定义的特定数据中学习,从而从中进行推断,并向人类决策者提供重要的自动分类、建议或预测。数据挖掘是一整套方法、算法和评估技术,用于从数据中提取价值和见解。ML 起源于统计学习、计算学习和模式识别的学科领域:在这个意义上,它本质上是基于使用统计方法来分析样本数据、执行相关的测试和实验,并得出与问题相关的推断。然后,这些 AI 方法的整个设计和编程过程旨在获得数据驱动的输出或预测,因此可以根据可用数据集的演变进行动态修改。数据中的实例通常围绕着特定的特征来表示,这些特征可以是分类或数值、二进制或连续的。ML 方法的应用广泛,从语音识别到计算机视觉,从战略和操作业务智能到欺诈检测,从天体物理学对星系的分析到金融应用。
总体而言,ML 方法可以分为三种学习范式,在文献和日常实践中被广泛利用:
-
监督学习方法:这种方法提供了预定义的和已提供的输入和输出变量,如已分类或分析的实例样本,算法能够通过检测从输入到输出的映射函数来进行泛化。
-
无监督学习方法:在这种情况下,提供的数据尚未标记,因此模型在训练过程中未提供样本的预先分析数据和结果。
-
强化学习方法:这种方法通过提供具体的反馈来训练它们,智能系统或代理努力最大化某些累积奖励函数,以逐步优化其输出。
因此,虽然 ML 方法的工作机制在可能的算法范围内可能会有很大差异,但很明确的是,这些 AI 方法能够从数据中生成知识,这与基于知识的系统和知识表示方法完全不同:这是知识发现的过程,它帮助从业者、决策者和组织利益相关者从数据中获得重要、准确和有用的知识,目的是理解领域相关和环境现象或行为,以及提高决策过程的质量和效果。从一般的角度来看,ML 旨在通过从过去的经验中学习,为指定的学习问题产生更好的结果,以帮助人类处理需要在异质条件下进行有效和高效自动化分析的大量数据,如不确定性和复杂性的情况。
监督学习在文献和实践中被广泛传播和利用。基本上,它包括提供已经标记和分类的数据及相关实例,理解它们的输入和期望输出。因此,数据集被直接而自然地分成两部分,用于学习:训练集和测试集。前者用于通过标记的训练样本来训练模型,而后者随后需要允许模型对未见数据进行新的推断。在理想的一般过程中,模型的训练应该通过检查已标记的数据提供将输入数据和期望输出相连接的映射函数,而测试过程应该将其应用于新实例以获得预测或见解。SL 模型允许处理两种宏观类别的问题:分类和回归。
分类是将数据集分类为特定预定义类别的问题:如果只有两个类别,则问题简化为二元分类,可以进一步扩展为多类问题。在分类方法和算法中,有非概率方法,如支持向量机,但也有基本上是概率方法的方法,如朴素贝叶斯分类器,以及神经网络,基于规则和基于逻辑的方法,或者决策树。相反,回归是预测实值目标响应对预测变量的问题,因此是输入特征的加权和。主要目的是检测和建模回归目标对一些预定义考虑特征的依赖关系。虽然线性回归由于其线性特性和不同特征的线性效应的透明性而具有显著优势,但同时需要手工修改以处理非线性,并且所利用的权重的解释不一定直观。因此,类似广义线性模型和广义加性模型的扩展方法经常在文献和日常实践中被研究和利用。
无监督学习是机器学习模型的学习范式,不需要已经预先标记的数据或实例。在这种情况下,训练集和测试集同样存在,并且学习过程仍然基于算法在过去的经验和示例上的训练。模型被训练以自行发现与数据提取的信息相关的相关模式和以前未检测到的见解。这种学习范式主要用于处理聚类问题,创建共享相似特征的数据组,降维,找到数据变化的主要因素,以及异常检测,以识别一组实例中的不同示例。这里最流行和最知名的问题是聚类:通过某些特定特征对数据进行分组以将它们分离的问题在实践和应用中广泛传播。在 K-means 聚类方法中,目标是创建 K 个不同的组,每个组都有一个特定的质心,每个群集一个,并通过最小化平方误差函数对数据进行分组。相反,降维的问题通常通过主成分分析等方法解决,帮助将二维数据降维为一维数据,或者像自动编码器这样的神经网络,这对处理异常检测以及无监督学习范式的许多应用也很有用。
最后,深度学习 是 ML 方法的一部分,包括基于 表示学习 的所有模型,并处理多个 表示层 来学习复杂情况下的数据,在这种情况下,涉及多个抽象级别和复杂性。在这种情况下,传统的、浅层的机器学习模型在能力和容量上本质上是有限的。因此,深度学习方法对于隐式提取特征是有用的,通过网络或算法结构中的一组 隐藏 层传递数据,对数据进行传递、处理和转换。深度神经网络 确实是具有许多输入和输出层的扩展型神经网络,数据在学习过程中在 前馈 网络中传输和管理,而无需循环。在最广泛和最经常被利用的方法中,有 卷积神经网络 、 循环神经网络 和 深度置信网络。尽管深度学习方法在分析大数据和在复杂和不确定条件下进行推理方面具有强大的能力,但 ML 和深度学习方法仍然受到多种不同问题的限制,例如 透明度 、 鲁棒性 、 可信度 和 可靠性 问题。因此,在对符号和次符号 AI 方法进行了一般性概述之后,现在是时候进一步探讨神经符号方法的承诺和挑战了。
2.8 神经符号计算
神经符号计算 的目标是有效地整合和利用符号、逻辑和形式化计算方法以及连接主义、次符号和神经方法来增强系统能力、认知能力和输出准确性。这些方法努力解决第一和第二波人工智能出现的问题,回顾 DARPA 的分类。总的来说,它们试图满足将 知识表示 和 推理 机制与基于深度学习的方法相结合的需要。目标是为研究人员和实践者提供更准确和 可解释 的系统,以提高系统的 预测能力 、 可解释性 、 可追溯性 ,从而促进人类对 AI 决策助手的 信任。虽然我们将在接下来的章节中重点讨论 可解释性 问题,但在这里我们只是简要概述了这些方法的主要支柱。
神经符号计算的目标是将我们已经考察过的两种互补认知能力融合在一起,分别是符号和次符号方法:学习,从外部环境或过去的经验中学习,以及从学习过程的结果中进行推理。神经符号计算试图充分利用现代先进神经网络中学习的优势和符号表示中的推理,从而产生可解释的模型。因此,神经符号计算背后的主要思想是在一个综合的通用框架下协调 AI 的符号和连接主义范式。从这个角度来看,知识通过符号形式机制来表示,例如一阶逻辑或命题逻辑,而学习和推理则通过适应的神经网络来计算。因此,神经符号计算框架允许有效地将神经网络中的强大和动态学习与推理相结合。这不仅提高了 AI 系统的计算能力和效率,增强了算法的鲁棒性和输出结果的准确性,而且还通过符号知识提取和通过形式理论和逻辑系统进行推理提供了可解释性。
从一般的角度来看,神经符号人工智能系统能够处理比之前介绍的方法更广泛的认知能力范围,通过利用连接主义和符号主义方法之间的能力的协同作用。更进一步,这些系统的主要特征与知识提取和表示、推理、学习以及它们在不同领域中的应用和效果相关。在神经符号计算不断发展的情景中,基于知识的人工神经网络(KBANN)和连接主义归纳学习和逻辑编程(CIL²P)系统是一些最常见的模型。KBANN 是一个从神经网络中插入、细化和提取规则的系统。KBANN 的设计和开发结果表明,神经符号方法可以通过整合背景知识和从示例中学习来有效地改善学习系统的输出。KBANN 系统是第一个确定这一研究路径的系统,在生物信息学中有着重要的应用。KBANN 还作为设计和构建 CIL²P 的灵感之一。该方法将从示例中的归纳学习和背景知识与来自逻辑编程的演绎学习相结合。基本上,逻辑编程允许通过形式逻辑来表示程序。因此,CIL²P 允许通过一个命题一般逻辑程序来表示背景知识,通过例子进行训练来完善背景知识,随后的知识提取步骤通过网络进行,在一个逻辑程序中完成。
在神经符号计算中的主要挑战之一是解决所谓的符号接地问题(SGP)。本质上,这是赋予人工智能系统能力,自主和自动地创建内部表示,将其操作的符号与外部世界中的相应元素或对象相连接的问题。将符号接地到环境对象的方法是设计和开发神经符号人工智能系统的一个微妙而基础的步骤,通常通过将符号接地到真实函数或者一般来说,接地到某种泛函上,以编码现实世界元素的特性和特征来解决。解决 SGP 问题使得通过符号接地有效传播信息,最终使得神经符号网络的整个工作机制能够在系统内捕获和加工知识。神经符号方法解决和解决 SGP 的方式是Deep Problog和逻辑张量网络等方法之间的差异之一。
神经符号系统的应用涉及广泛的领域,例如数据科学、本体论中的学习、模拟器中的培训和评估,以及不同应用的认知学习和推理方法。这类系统最显著的优势之一与可解释性有关。与深度学习和黑匣子模型不同,这类系统是可解释的,因此允许人类决策者理解其提供的输出背后的原因。事实上,日益复杂的人工智能系统需要能够向用户解释其工作机制和决策的方法。因此,在当前情景和人工智能系统的演进中,了解可解释人工智能的基本作用和作用是必要且不可避免的。
2.9 可解释人工智能
可解释人工智能(XAI)的兴起和传播是当前和未来人工智能系统演进的关键一步。除了神经符号方法,这种方法还可以显着地归类为 DARPA 所定义的所谓的第三波人工智能。因此,XAI 努力实现情境适应的重大挑战,即逐渐解释方法的构建,以适应现实世界现象的类别。虽然 XAI 领域在文献和人工智能研究中并不新鲜,但如今其重要性不断增长,因为它能够满足对可解释、透明和可问责系统的需求。解释模型背后的主要原因是机器学习和深度学习模型的一般不透明性和缺乏可解释性:尽管人工智能以及机器学习和深度学习系统取得了强大的计算能力和高性能,但当试图理解某些结果的来源时,很难从它们的内部机制中获取洞见。
为了解决这个问题,XAI 旨在创建一套人工智能技术,能够使其自己的决策更加透明和可解释,从而打开黑匣子,与用户分享输出结果的方式。最终目标是创建完全可解释的模型和算法,同时保持高性能水平。这样一来,XAI 允许用户增强与人工智能系统的交互,通过理解某些输出或决策是如何产生的具体原因,从而增加对系统机制的信任。在各种应用领域,可解释性都是非常必要的,而且相关的规定开始出现,要求其成为人工智能系统的基本且不可避免的特征。
尽管对解释没有一个统一的、预定义的、广泛接受的正式定义,但文献中出现了一些关键概念。努力定义什么是解释的确切角色是用户或观察者的作用是至关重要的:从这个角度来看,解释的目标是让对象的相关细节清晰或易于被某个观察者理解。因此,解释能够向用户提供重要和必要的信息,使他们能够理解模型的工作方式或为什么做出特定决定或提供特定输出或建议。更进一步,值得强调的是,解释是人类决策者和智能助手之间的接口,使人类代理能够理解一些关键的相关代理,以获取系统输出的原因,以及系统内部的工作机制。这为解释的概念增添了新的维度,展示了解释应具有的新特征。它应该是一个准确的代理,即解释必须基于模型的机制和所使用的输入。从这个角度来看,生成解释的挑战需要确保它们具有准确的代理,这在最先进的模型中并不保证。这些代理与模型管理的特征密切相关:解释通常将实例的特征值与其模型预测相关联,以一种人类决策者、从业者或组织利益相关者能够轻松理解的方式。
文献中有几次尝试提供对 XAI 系统进行分类、归类和描述。可解释的建议可以是模型内在或模型无关:在前一种情况下,输出模型是内在可解释的,意味着决策机制完全透明,提供解释;而在后一种情况下,输出模型提供所谓的事后解释,而不对模型本身进行任何修改。这两种方法在概念上可以与认知心理学根源相关联:在这种观点下,模型内在模型在某种程度上类似于人类思维的理性决策,而模型无关模型则在某种程度上类似于直觉决策方式,随后进行一些解释的搜索。这种分类也反映在可解释的 AI 模型的分类中,可解释的机器学习技术通常可以分为两类:内在解释性和事后解释性,其中区别在于解释性何时获得并包含到模型中。内在解释性通过设计自我解释的模型直接包含解释性来获得。在这些方法中有线性模型、决策树、基于规则的系统等。相反,事后方法是通过定义另一个模型来为现有系统提供解释。
另一个重要的分类,来自可解释推荐系统的具体子领域,用于概念上对 XAI 世界中的两个主要相关维度进行分类:解释的信息来源或显示样式以及可解释模型的角度。前者是解释如何提供给用户的方式,例如文本解释、视觉解释等,而后者是为设计和开发考虑的可解释系统所利用的特定模型。因此,虽然显示样式代表着人机交互的角度,而模型本身则与 XAI 研究的机器学习维度相关。总的来说,当涉及解释时,用户与模型之间的交互作用的角色至关重要:XAI 的不断普及及其在各种应用领域的应用要求高质量的交互和智能助理与人类决策者之间信息和知识共享过程的有效性。因此,人―AI 交互这一有前景的学科的崛起和演变对 AI 历史的下一阶段至关重要。
2.10 人―AI 交互
当前 AI 的情景和发展,如本章节中简要而一般性地介绍的那样,如今已经引起了研究人员和从业者对 AI 系统与人类代理之间的作用和交互质量的关注。虽然 AI 可以被视为一种形式的自动化,但它绝对不是单纯的技术手段:相反,它更多地是一种使能力,使整个社会拥有连续、非线性和某种程度上不可预测的动态。从更广泛的视角来看,AI 正变成一个真正的代理,不仅仅是支持人类,而且是与人类互动并交换信息和知识。因此,有必要采用更广泛的视角,在这个视角下,人类和 AI 共同工作,以增强和加强决策过程以及这些行为者生活和行动的整个环境。这引发了一些相关且不可避免的伦理问题,因为可能会由于某种方式上“使人类与 AI 等同”而产生的潜在风险。尽管伦理问题是基本的,应该通过预先定义的和广泛接受的框架来明确面对和解决,但这并不是本章的目的。对我们的目标来说,理解人类和 AI 在先进和广泛分布的社会技术系统中共同工作、推理和行动是足够的:更好地说,是在 社会 - AI 系统 中,我们不能忽视或低估。此外,这些系统还将越来越多地激发各种 新兴集体行为,从复杂系统的角度来看。
在这种背景下,人工智能与人类的交互(HAII)是一门新兴且具有挑战性的学科,旨在研究、设计和评估基于人工智能的交互式系统,以及交互过程中人类与人工智能系统之间的潜在关系、问题和挑战。HAII 将从人机交互(HCI)中衍生的经典范式和框架应用于技术交互系统基于人工智能的情况。因此,与用户 - 中心设计、可用性和用户体验相关的概念被广泛保留和调整。用户的角色至关重要:在设计和改进人工智能系统建模时,人类应该参与其中。在 HAII 领域,有几种评估应用、交互和 AI 系统利用的后果的框架,涵盖了各种应用领域:其中一个最重要的框架是人工智能影响评估,它有助于在实际情况中映射 AI 应用的潜在益处和威胁,识别和评估 AI 系统的可靠性、安全性和透明度,并限制其部署中的潜在风险。其他框架和建模工具旨在确定人工智能系统和功能的当前演化和自动化水平,以及与人类交互的角色:为此,可以应用 Parasuraman 的类型和级别人与自动化交互的模型来评估基于人工智能系统的自动化程度。
在这个角度来看,人工智能越来越成为一个队友和决策者,而不仅仅是一个简单的工具、助手或者代理人。为了能够设计和开发可靠且值得信赖的人工智能系统,以及增强与人类的互动类型,已经设计并应用了HAII 指南。这些指南旨在提高人类和基于人工智能系统之间的流畅度、有效性以及整体协调性。它们考虑并努力改善操作的所有阶段,在互动过程和整个知识提取和决策过程的开始、进行和结束时。主要的重点再次是将用户置于循环中,即在整个过程中清晰地表明行动、决策和相关信息。此外,它们努力确保所有必要的信息和知识收集阶段都能够被很好地执行,并且知识能够准确地被引出、收集和传递:因此,它们强调了从过去的反馈和用户行为中学习的重要性,以及记住过去的互动。其思想是使人工智能系统能够根据积累的先前知识和经验以及涉及的人类代理人的行为来调整和发展其行为。遵循这种方法,有几种方法和框架可以设计人类行为者和基于人工智能系统之间的互动,例如智能和会话界面、拟人化以及应用人格化,即将人类的态度或意图归因于机器,在“计算机作为社会行为者”理论的概念范式中。
在这段旅程的尽头,接下来会是什么呢?嗯,我们在地平线上还有更多等待着我们!人工智能目前正在转变其在整个社会中的角色和特征:从仅仅是有限的自动化决策支持系统和技术基础设施,到互动助手、队友甚至经理和决策者。因此,人类和机器智能将以不可预测和协同的方式结合,达到所谓的混合智能,在这种统一和增强的环境中,人类和机器的认知能力一起被利用,以实现复杂的目标和取得优越的结果,同时通过人与机器之间流动和相互的知识和经验共享实现持续学习。接下来呢?集体混合智能的崛起可能会彻底改变人类社会的方方面面,导致新兴、全面的社会-人工智能系统智能的出现。由于人工智能广泛应用于人类社会所引发的数字、社会和文化转型,我们需要现在和每一天都回答的问题。让我们每天努力工作,提高对人工智能潜力和挑战的理解和意识,以确保其力量和优势能够服务于我们的子孙和所有新的和未来的一代。作为研究人员、学者和实践者,这应该始终是我们的最终目标。作为人类。
第三章:金融市场:价值、动态、问题
Juliana Bernhofer^(1, 2 ) 和 Anna Alexander Vincenzo^(3 )(1)意大利摩德纳和雷焦埃米利亚大学经济系,“马尔科·比亚吉”,雅各波·贝伦加里奥大街 51 号,41121 摩德纳(2)意大利威尼斯卡·福斯卡里大学经济系,坎纳雷吉奥 873 号,30121 威尼斯(3)意大利帕多瓦大学,圣德罗 33 号,35123 帕多瓦 Juliana Bernhofer (通讯作者)Email: juliana.bernhofer@unive.itAnna Alexander VincenzoEmail: anna.alexandervincenzo@unipd.it
摘要
由 2020 年冠状病毒爆发引发的全球股市崩盘导致了一系列交织在一起且仍在发展的社会、经济和金融后果。我们将审查最近的疫情危机的几个方面,并对其与现有发现的金融中断、恐惧和动荡(全球金融危机、恐怖主义和先前的大流行病)对金融市场的影响进行批判性比较。随着不确定性和波动性的增加,新冠疫情也影响了投资者的风险态度、信任和信心。我们将提供对这些行为方面的洞察,并讨论它们如何最终影响金融决策。此外,政府限制的一个独特副作用是数字化的前所未有的增长:全球各年龄段的公民被迫使用在线服务和数字工具。我们将讨论这一新现象对金融市场的影响、其对社会不平等的影响以及它所蕴含的机遇场景。
关键词金融市场风险信任韧性数字素养 Juliana Bernhofer
是摩德纳和雷焦埃米利亚大学“马尔科·比亚吉”经济系学术研究员,威尼斯卡·福斯卡里大学荣誉研究员和 CF 应用经济学的联合创始人,这是一个应用经济分析和研究中心。她是一位应用行为经济学家,研究兴趣涵盖了从计算决策支持工具的开发到语言经济学、教育与劳动经济学、税收和卫生经济学领域的实证数据分析和人类实验。
Anna Alexander Vincenzo
是帕多瓦大学经济与管理系助理教授。她目前的研究兴趣涉及金融会计领域,特别关注公司避税、公司治理和第三部门。
3.1 引言
2019 年末,Covid-19 开始蔓延。由于严重的肺炎,病毒导致老年人和社会中最脆弱的人之间的死亡率异常高,引发了全球超过 20 亿人的国际社交距离和居家隔离,带来了巨大的社会、政治和经济后果(Goodell 2020;Sharif et al. 2020)。此外,这种病毒的商业影响之一是对商品和服务流动、商品价格和金融状况的意外干扰,由于对中国、美国、欧洲、日本和世界其他重要经济体的生产和供应链造成了影响,引发了许多国家的经济灾难(IMF 2020)。
Covid-19 的爆发对市场参与者造成了震惊(Ramelli 和 Wagner 2020),卫生危机预期的实际影响通过金融渠道被放大。与 2007 年的全球金融危机不同,Covid-19 主要是对实体经济的冲击,最初与外部金融手段的可用性无关,尽管市场的反应预示着通过金融限制可能会放大实际冲击。
分析这场意外罕见灾难对金融市场的影响,我们可以概括出疫情进展的三个阶段。[¹] 2019 年 12 月 31 日,中国武汉发现的肺炎病例首次向世界卫生组织报告,2020 年 1 月 1 日,中国卫生部门关闭了华南海鲜批发市场,因为发现那里销售的野生动物可能是病毒的来源(世界卫生组织 2020a)。第一个交易日是 1 月 2 日,因此第一个时期的起点。
第二,2020 年 1 月 20 日,中国卫生部门确认了冠状病毒的人传人传播,次日世界卫生组织发布了关于该疫情的首份情况报告(中国国家卫生委员会 2020;世界卫生组织 2020b)。1 月 20 日星期一是美国的国定假日;因此,次日标志着第二阶段的开始。
第三,在 2 月 23 日星期日,意大利将近 5 万人置于严格的封锁之下,试图在 2 月 22 日星期六首次报告新冠病毒死亡后控制疫情的爆发(意大利内阁大臣会议 2020)。2 月 24 日是这一阶段的第一个交易日,接下来的几周情况急剧下滑。3 月 9 日星期一,道琼斯工业平均指数(DJIA)下跌了 2014 点,跌幅为 7.79%。两天后,即 3 月 11 日,世界卫生组织将 Covid-19 列为大流行。2020 年 3 月 12 日,道琼斯工业平均指数下跌了 2352 点,收于 21,200 点。这是历史上第六次最严重的百分比下跌,跌幅为 9.99%。最后,在 3 月 16 日,道琼斯工业平均指数暴跌近 3000 点,收于 20,188 点,跌幅为 12.9%。股价的下跌迫使纽约证券交易所在这些日子内多次暂停交易。
在 2020 年 3 月,世界目睹了迄今为止最引人注目的股市崩盘之一。在仅仅四个交易日内,道琼斯指数暴跌 6400 点,相当于大约 26%。股市价格的急剧下跌是由于当局决定对人口实施严格的隔离措施,并下令对大多数商业活动实施封锁,以限制新冠病毒的传播。对商业活动实施的封锁暂停了大部分的业务运作,公司对此做出反应,通过调整劳动力成本来弥补收入冲击。裁员导致消费和经济产出急剧减少,降低了公司未来预期现金流的流动性。
**道琼斯工业平均指数(DJIA)**在交易周末的 3 月 20 日达到最低点。随后的星期一,3 月 23 日,美联储宣布对企业债券市场进行重大干预,指数开始再次上涨。2020 年第一季度指数的演变如图 3.1 所示。
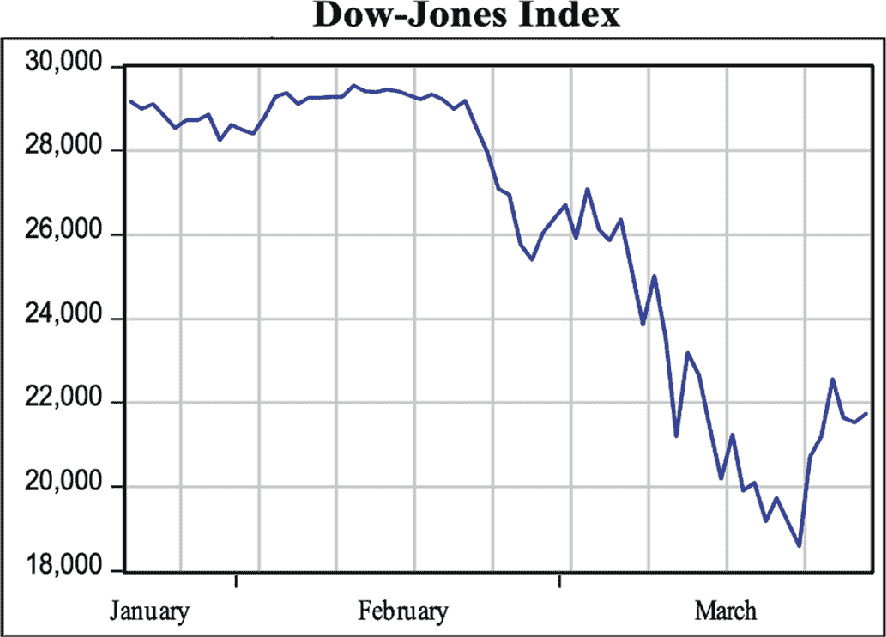
一张道琼斯指数市场的图表,涵盖了一月、二月和三月。图表呈下降趋势。
图 3.1
2020 年第一季度的道琼斯工业平均指数(DJIA)
然而,Covid-19 大流行并没有平等地影响所有行业²,封锁也没有导致所有行业的股价变动为负。事实上,一些行业受益于大流行和随之而来的封锁。Mazur 等人 2021 关注了 S&P 1500,发现从事原油石油行业的公司受到了最严重的打击,在一天内失去了超过 60% 的市值。相比之下,天然气和化学行业的公司提高了其市值,并平均获得了超过 10% 的正回报。此外,他们研究了行业水平的模式,并显示在 2020 年 3 月股市崩盘期间,表现最佳的行业包括医疗保健、食品、软件和技术,以及天然气,其月回报率超过 20%。另一方面,包括原油石油、房地产、酒店业和娱乐业在内的行业暴跌超过了 70%。
如果说 Covid-19 吸引了金融市场的注意并不奇怪,那么有趣的是注意到市场参与者何时更加关注局势的发展。Da 等人 2015 开发了一种用于衡量零售投资者对某一主题兴趣的研究方法,该方法利用了 Google 上的搜索强度。Ramelli 和 Wagner 2020 利用 Google 趋势搜索来捕捉投资者情绪,并显示全球 Google 对冠状病毒的搜索关注度急剧上升,特别是在 3 月 9 日之后,而国际公司的电话会议数量和涉及冠状病毒主题的电话会议数量也增加了,但在二月底就已经急剧增加。在他们的研究中,他们发现最初,随着中国的有效关闭,投资者避开了与中国有关联的美国股票和国际化公司;随着中国的病毒情况相对于欧洲和美国的情况改善,投资者再次更有利地看待了这些公司。随着病毒在欧洲和美国的传播,导致这些经济体封锁,市场动荡不安。
3.2 金融市场如何应对以往的流行病?
很少有研究分析流行病或大流行对金融市场的影响。最近的研究将冠状病毒大流行置于透视,并分析了与 20 世纪以前的大流行相比,其后果。
传染病爆发的影响特点是高度不确定性,尤其是当爆发涉及一种具有未量化传播、感染性和致死性模式的新疾病时(Smith 2006)。根据 (Baker 等人 2020),Covid-19 大流行爆发对股票市场的影响是前所未有的。
在图 3.2 中,我们展示了标准普尔 500 指数实际实际价格随时间的演变。1918 年的股票市场回报率很难获取,并且受到了第一次世界大战的影响,该战争发生在 1914 年至 1918 年之间。标准普尔 500 指数可以追溯到 1871 年;1918 年下跌了 24.7%,1919 年上涨了 8.9%。
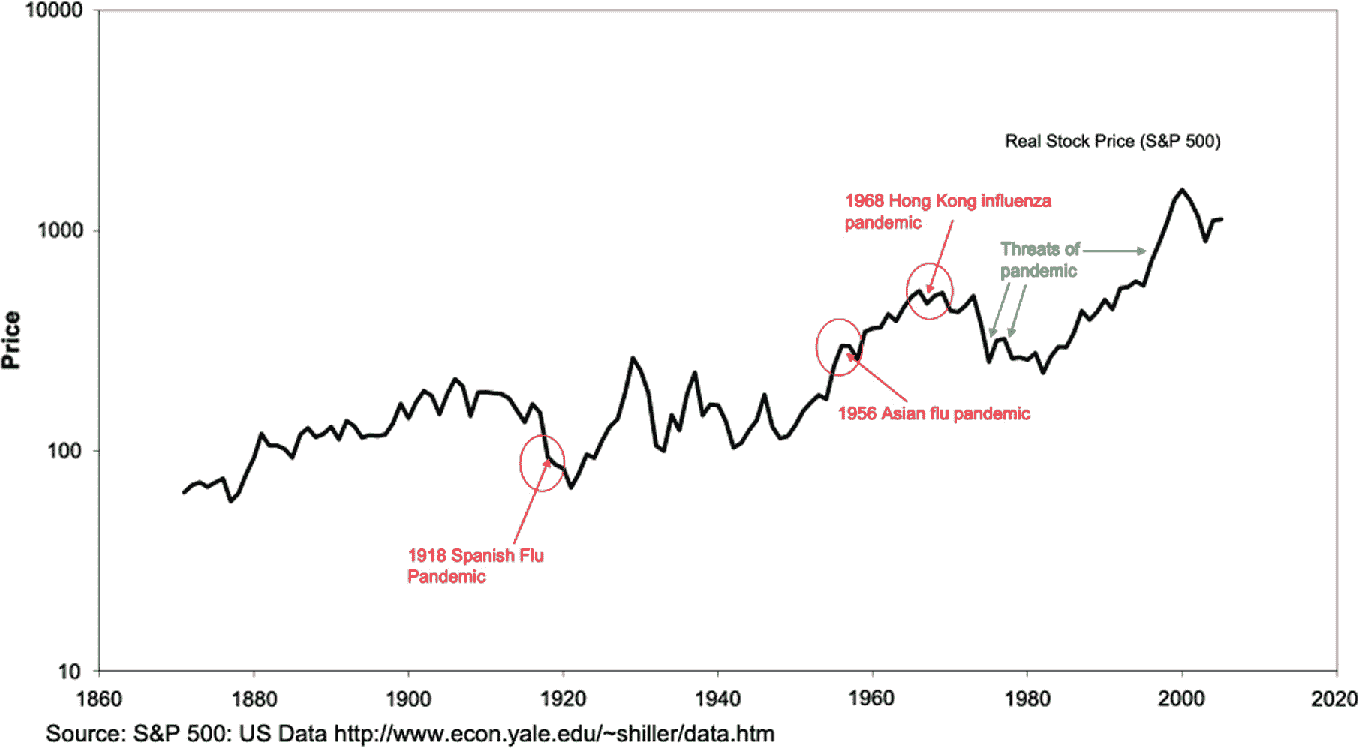
从 1860 年到 2020 年的 S&P 历史的折线图描述了价格和事件。1918 年是西班牙流感大流行,1956 年是亚洲流感大流行,1968 年是香港流感大流行。大流行的威胁也得到了表述。
图 3.2
标准普尔 500 指数历史 1860–2020
1957 年的亚洲流感大流行是近年来第二大重要爆发事件,全球大约有 1-2 百万人受害。这一大流行首次在 1957 年 2 月在远东被确认。经过最初的熊市阶段,标准普尔 500 指数在 1958 年第四季度完全恢复。
1968 年初,香港流感疫情首次在香港被发现。该病毒的死亡人数在 1968 年 12 月和 1969 年 1 月达到峰值。标准普尔 500 指数在 1968 年上涨了 12.5%,在 1969 年上涨了 7.4%。2003 年,即首次报告非典型肺炎流行的那一年,太平洋日本指数从 1 月 14 日至 3 月 13 日下跌了 12.8%。然而,随后市场大幅反弹,整个年份该指数回报了 42.5%。
Correia 等人的另一项研究 2022 着眼于政府干预措施(如社交距离)对流行病蔓延的经济严重性的影响,旨在减少死亡率。他们的研究重点是造成美国 675,000 人死亡,约占人口的 0.66%的 1918 年流感大流行。大多数死亡发生在 1918 年秋季的第二波中。作为回应,美国主要城市实施了一系列旨在遏制病毒传播的行动,速度和严格程度各不相同。其中包括关闭学校,剧院和教堂,禁止公众集会,对疑似病例进行隔离以及限制营业时间。他们的研究结果显示,实施了更严格的遏制措施的城市在大流行之后表现得更差的证据。事实上,他们的研究结果表明,这些遏制措施减少了病毒的传播,而不加剧大流行引起的经济衰退。
在 SARS 爆发之后,诸如(Beutels 等人,2009;Sadique 等人,2007;Smith,2006)的研究强调了大流行的经济影响。像 SARS 这样的爆发预计会产生直接经济效应,这是由疾病本身的影响(治疗感染者的健康部门成本)、遏制疾病的政策(与隔离、封锁和学校关闭相关的公共部门和私人成本)以及由爆发所引发的恐惧(影响个人行为)所导致的。健康威胁的存在可以影响消费者和投资者的一般预期和行为,因此,其影响远不止于来自患病患者的直接生产力减少(Sadique 等人,2007)。例如,对于 SARS,已经观察到最大的经济影响主要来自减少的本地和国际旅行以及减少了非必要消费活动,例如餐厅和酒吧,尤其是在 2003 年 5 月,以及推迟了主要是耐用品的消费(Richard 等人,2008)。Beutels 等人,2009 强调了承认消费者和投资者对公共卫生紧急情况的适应性的重要性,以提供有用的大流行背景下的经济分析。
在新冠疫情爆发前十年,(Keogh-Brown 等人,2010)研究了潜在的当代大流行对英国经济的可能影响。他们使用了来自过去大流行的流行病学数据,例如 1957 年³和 1968 年⁴的流感大流行,并应用了英国经济的季度宏观经济模型进行了估计。他们以 20 世纪后两次大流行作为基础情景,通过增加疾病参数的严重性来构建进一步的疾病场景,从而探究更严重的流感大流行可能造成的经济影响。
他们在研究中选择使用 1957 年和 1968 年的流感大流行,而不是 1918 年的大流行,这是因为观察到,考虑到社会行为和公共卫生政策的现代变化,西班牙流感的再次爆发对当前经济的影响将会截然不同。然而,通过以更近期的大流行作为疾病场景的基础,并对更严重的大流行(如 1918 年的大流行)的严重程度进行推断,他们能够提出一些有用的假设,并激发对传染病爆发可能产生的经济影响的思考(Keogh-Brown 等人,2010)。
Keogh-Brown 等人的模型根据临床发病率和病死率的严重程度提供了不同的输出。对工作人口的冲击表现为死亡、直接缺勤(由感染引起)和间接缺勤(由学校关闭和对工作的“预防性”避免引起)。当然,模型的结果根据对爆发严重性的不同赋值而变化,但在 GDP 损失、消费下降和通货膨胀方面提供了有趣的结论。最重要的是,这些结果清楚地表明了疾病参数上的行为变化的重要性。
3.3 关于自然灾害和恐怖袭击
尽管有关流行病、更不用说大流行病,对金融市场的影响的先前文献有限,但可以从其他形式的自然灾害(Goodell 2020)中得出不完美的类比。市场对自然灾害(如地震和火山喷发)、空难以及近期的恐怖袭击做出反应。
Niederhoffer 1971 是第一个分析各种危机对价格影响的人,研究范围从肯尼迪的暗杀到朝鲜战争的开始。Niederhoffer 发现,这些世界事件对股市平均值的波动有着明显的影响。Barrett 等人 1987 分析了在 1962 年至 1985 年期间发生的 78 起致命商业航空事故,并发现航空事故的即时负面价格反应仅在事件发生后的一个完整交易日内显著。他们还分析了初始反应期后的市场反应,并未发现初始反应期内的低估或高估的证据,这与市场中的即时价格调整的想法一致。Shelor 等人 1992 研究了 1989 年 10 月 17 日加州发生的地震对房地产相关股票价格的影响。他们的研究结果表明,地震传递了与金融市场相关的新信息,这表现为旧金山地区运营的公司的股票收益显著下降。在加州其他地区运营的与房地产相关的公司通常不受地震影响,也没有经历任何显著的价格反应。Worthington 和 Valadkhani 2004 测量了各种自然灾害(包括严重风暴、洪水、气旋、地震和森林火灾)对澳大利亚资本市场的影响。他们的结果表明,森林火灾、气旋和地震对市场收益产生了重大影响,而严重风暴和洪水则没有。
过去几年来,恐怖主义对全球金融市场的间接经济后果在学术文献中受到了广泛关注。几项研究已经研究了恐怖主义对股票市场的影响。有关恐怖事件对金融市场影响的研究可能提供了一些并行,因为恐怖事件,尽管在其初始表现中是局部化的,但其性质是旨在引起公众情绪的广泛变化。负面影响可以在主要宏观经济变量上观察到,消费者和投资者信心受到负面冲击,从而也对经济前景和金融市场产生负面影响(Frey et al. 2007; Johnston and Nedelescu 2006)。
许多实证研究已经分析了恐怖袭击对股票市场的影响。Eldor 和 Melnick 2007 使用每日数据分析了特拉维夫证券交易所对恐怖事件的反应。他们关注了 1990 年至 2003 年间的 639 次袭击,并发现自杀袭击对股票市场产生了永久影响。Karolyi 和 Martell 2006 研究了 1995 年至 2002 年间 75 起恐怖袭击的股票价格影响,重点关注上市公司。他们对公司异常股价回报的横截面分析表明,恐怖袭击的影响取决于目标公司的所在国家和事件发生国家。在较富裕和更民主的国家发生的袭击与更大的负面股价反应相关。此外,他们的研究结果表明,人力资本损失,如公司高管被绑架,与股价的负面反应相关性更大,而物理损失,如设施或建筑物的爆破,影响较小。
Chen 和 Siems 2007 使用事件研究方法评估了恐怖主义对全球资本市场的影响。 他们研究了自 1915 年以来 14 次恐怖袭击对美国股票市场的影响,并另外分析了全球资本市场对两起较新事件的反应——1990 年伊拉克入侵科威特和 2001 年 9 月 11 日的恐怖袭击。该研究的结果表明,与过去相比,美国资本市场更具韧性,倾向于比其他全球资本市场更快地从恐怖袭击中恢复过来。这一后者的发现部分是由于稳定的银行/金融部门提供了充足的流动性,以鼓励市场稳定并最大程度地减少恐慌。
此外,Drakos 2004 和 Carter 和 Simkins 2004 研究了 9/11 袭击对航空公司股票的具体影响。 后者侧重于袭击对投资者心理的显著情感影响,通过测试攻击后第一个交易日的 9 月 17 日股价反应是否对每家航空公司都相同,或者市场是否根据公司特征对航空公司进行区分。 他们的横截面结果表明,市场担心袭击后破产的可能性,并根据航空公司偿还短期债务的能力对航空公司进行区分。 Drakos 则侧重于航空公司股票的风险特征,并报告了 9/11 恐怖袭击后金融风险发生结构性转变的情况。 Drakos 报告称,自 2001 年 9/11 事件以来,航空公司股票的系统性和特有风险都大幅增加。 有条件的系统性风险增加了一倍多,这可能对公司和投资者都产生影响。 投资组合经理需要重新考虑将资金分配给航空公司股票的情况,上市航空公司在筹集资本时将面临更高的成本。
Burch 等人 2003 和 Glaser 和 Weber 2005 也考察了恐怖主义对金融市场情绪的影响。 Burch 等人 2003 发现,9/11 袭击事件后,封闭式共同基金折价显著增加,因此得出这些袭击导致投资者情绪出现负面转变的结论。 Glaser 和 Weber 2005 使用问卷数据分析了 9/11 袭击事件前后个人投资者的预期。 令人惊讶的是,他们发现,恐怖袭击后,个人投资者的股票回报预测更高,意见差异更小。 然而,Glaser 和 Weber 2005 也报告了投资者波动性预期显著增加的情况。
Karolyi 2006 讨论了恐怖袭击的“溢出效应”,以及对这一主题的研究是否表明潜在恐怖主义对整体风险的广泛或“系统性”贡献。 他的结论是证据相当有限,但是有很少的测试检验了资产定价模型中的波动率或贝塔风险。 Choudhry 2005 调查了 9/11 之后在各行各业的一小部分美国公司,以查看这一恐怖主义事件是否影响了市场贝塔的转变,结果参差不齐。 Hon 等人 2004 发现,9/11 恐怖袭击导致全球市场之间的相关性增加,不同地区的变化不同。 一些其他论文提出了恐怖行为溢出到金融市场性质变化的程度的混合图片(Chesney 等 2011; Choudhry 2005; Corbet 等 2018; Nikkinen 和 Vähämaa 2010)。
一些论文表明,与恐怖事件相关的市场下行相对较轻。 根据(Brounen 和 Derwall 2010),金融市场在未经预料的事件后的头几周内反弹,例如地震和恐怖袭击。 在他们的研究中,他们比较了恐怖袭击的价格反应与自然灾害的价格反应,并发现恐怖袭击后的价格下跌更为显著。 然而,在两种情况下,价格很快就会恢复。 他们还比较了国际间和各行业的价格反应,并发现当地市场和直接受到袭击影响的行业的反应最强烈。 9/11 袭击是唯一对金融市场产生长期影响的事件,尤其是在行业系统性风险方面。
3.4 风险、信任和信心在危机时期
风险偏好、对政府的信任和信心态度如何影响金融决策?反过来说,近期的新冠肺炎大流行会在短期和长期内对这些决定性参数产生何种影响?
接触到地震、洪水、恐怖袭击和流行病等灾难不仅对受害者及其家庭产生直接影响,而且对整个社会和集体偏好产生影响。
风险偏好、信任和动物精神
Ahsan 2014 表明,焦虑作为极端事件(如气旋)的结果,增加了人们的风险规避倾向。然而,焦虑不仅通过风险偏好的渠道影响股市表现;创伤后应激反应和恐惧也影响理性,并在解释现实时引入了显著偏差。Engelhardt 等人 2020 分析了覆盖全球 95% GDP 的 64 个国家的数据,以评估 2020 年股市崩盘是由理性预期⁵ 还是对新闻关注增加所驱动的。与 Ramelli 和 Wagner 2020 类似,后者通过评估在评估时间范围内的异常谷歌搜索量来衡量。作者发现,新闻关注度每增加一个标准偏差,市场回报就会减少 0.279 个标准偏差,而作者的理性预期度量每增加一个标准偏差,市场回报就会减少 0.131 个标准偏差。与此同时,截至 2020 年 4 月,负面新闻炒作对美国股市的成本估计为 3.5 万亿美元。同样,(Al-Awadhi 等人 2020) 发现,对中国股市的股市回报对确诊病例总数和每日新冠肺炎死亡人数的反应产生了负面影响,(Albulescu 2021) 发现美国金融市场也出现了类似的结果。Shear 等人 2020 比较了不同文化及其不确定性规避水平。试图减轻不确定情况的倾向越高,对额外信息的搜索量就越高。结果与先前的报告一致:国家文化与不确定性规避指数结合在一起,在危机时期是股市回报的重要预测因子,因为更倾向于风险和不确定性规避的文化往往寻求更多信息,最终增加了他们的焦虑水平,进而对股市结果产生负面影响。同样,(Bernhofer 等人 2021) 也表明,使用非陈述(非真实)心情的语言的讲话者更具风险规避倾向,更少投资于风险资产。这是因为语义上,未知更加精确定义,因此增加了他们不确定性区域的显著性。
人们在做出财务决策时受情绪影响的想法最早由约翰·梅纳德·凯恩斯在他 1936 年的重要著作《就业、利息和货币一般理论》中首次描述。在这本书中,他阐述了“动物精神”如何影响消费者信心,这很可能代表了行为金融的起源。希波克拉底(公元前 400 年)和帕加马(公元 200 年)的克劳狄斯·加伦观察到了这一点,将之称为pneuma psychikon(或“动物精神”),这是一种位于脑室内的不可见实体,通过肌肉和神经传导(Herbowski 2013; Smith et al. 2012)。然而,这一近似似乎确实是对生物学解释背后心理反应的原始想法,表现为“自发的行动冲动”。对震荡的反应之一似乎是产生“压力激素”皮质醇,作为例如市场波动的反应而增加,并已被证明降低风险倾向(Kandasamy et al. 2014)。同时,由于压力水平增加,对小概率事件的过度关注可能部分解释了焦虑及其对金融决策的后果。后一现象在男性中比在女性中更常见。
此外,人类倾向于关注新闻而不是遵循数据驱动模型,这是克里斯托弗·A·辛姆斯在 21 世纪初描述的他著名的理性注意力理论,此后已被许多研究者讨论和应用。根据辛姆斯的论点,投资者在数据、时间和认知能力方面没有信息处理能力来运行高度复杂的模型,因此他们采取一种捷径,依赖媒体报道。虽然这在某种程度上是一种节省金钱的技巧,但这种方法的主要缺点之一是暴露于负面偏差,因为对悲观新闻的增加关注导致了悲观预期的形成和对金融市场的扭曲影响。
政府的信任与信心
Engelhardt 等人 2021 从略有不同的角度探讨了金融决策中的行为因素问题,通过调查一个社会的预先存在的固有信任水平以及其对疫情影响的韧性。作者分析了涵盖 47 个国家的世界价值观调查数据以及从 2020 年 1 月底到 7 月底的确诊 Covid-19 病例数量。信任通过两个不同的指标来衡量,社会信任——或者对其他人的信任——和对政府的信心。市场波动性计算为 5 天移动平均波动率,而 Covid-19 病例则根据人口规模进行了调整。在那些社会信任和对政府的信心较高的国家,股票市场受新的 Covid-19 病例报告影响显著较少。作者假设传播机制通过不确定性水平,这个水平通过对政府规则的信心以及对新规则和处方的遵守程度降低了。Akerlof 和 Shiller 2010 强调了积极政府在建立信任和调节对危机的情感反应或“动物精神”的作用。因此,它应该像对经济负责任的父母一样,减轻其对关键事件的反应。
3.5 数字素养和 Covid-19
大暴发
对于 Covid-19 疫情的研究往往伴随着一种苦涩的余味:死亡人数、对各个年龄段心理健康的影响、失业和企业关闭。依赖面对面交流的行业的收入显著下降,而相对能够适应远程市场的现实情况,如 Zoom Video Communications、Netflix 和亚马逊等,则未受影响。Miescu 和 Rossi 2021 进行了一些冲击响应函数分析,并显示由 Covid-19 引起的冲击将贫困家庭的就业机会减少了近两倍。另一方面,与贫困家庭相比,富裕家庭的私人支出下降了近 50%,这可能是由于消费组合的差异,娱乐和餐饮行业暂时不可用。
由于社交距离、学校关闭和其他限制,首次封锁的一个著名且广泛讨论的外部性是,各种规模的企业和各个年龄段的私人公民被迫在在线世界中导航以克服物理限制。对数字环境的适应几乎是一夜之间发生的,并且已经充当了对以前未知或被忽视的各种数字工具的使用的催化剂(Amankwah-Amoah et al. 2021)。政府和企业不得不迅速从纸质程序转移到在线服务以达到他们的目标,各年龄段、社会背景和教育类别的私人公民不得不提高现有的数字技能或获得新知识以从公共援助中获益,并保持对医疗保健的访问并参与市场。随着疫情袭击整个社会系统,几乎没有抵抗的空间和时间。
在图 3.3 中,我们比较了通过欧洲健康、衰老和退休调查(Axel Börsch-Supan 2022)进行的访谈。SHARE 是一个关于 50 岁及以上个人的社会经济地位、家庭网络、个人偏好和健康状况的两年一次的跨国面板数据库,因此代表了较脆弱的年龄群体之一。第一轮问卷调查(即第 1 波)于 2004 年进行,涉及 11 个欧洲国家和以色列。第 8 波的实地调查原计划于 2020 年春季结束,但在 2020 年 3 月的疫情中断了。同年 6 月,对已经接受过访谈的一些受访者和尚未回答问题的一些受访者进行了 CATI⁶问卷调查。在这两个图表中,我们比较了疫情前欧洲 50 岁以上人口的计算机技能水平和 2020 年首次封锁后的自我改善计算机技能。通过比较数字技能预存在低水平的国家与数字技能预存在高水平的国家,我们观察到前者国家的平均技能增长更强烈,表明数字鸿沟有所缩小!
欧洲的 2 张地图。左边是 Covid 19 之前 50 岁以上人群的平均计算机技能。右边是 2021 年 50 岁以上人群中数字技能改善的百分比。
图 3.3
疫情前后的数字技能
表 3.1 中呈现的第二次计量评估为我们揭示了社会方面的一些情况。我们分析了 Covid-19 大流行之后数字素养提升的决定因素,如性别、识字能力、家庭收入水平以及国家层面的收入不平等情况。一方面,女性受益几乎是男性的两倍,也是那些原先数字素养较低的人,但另一方面,那些阅读能力更好的人从大流行带来的数字化转型中稍微更多受益。有趣的是,似乎没有任何差异性效应,对于收入高于本国中位数的受访者,但更重要的是,在大流行期间,收入不平等水平较高的国家平均有 7.5 倍更有可能出现数字素养的提升。
改善数字素养的一些决定因素
(1) | (2) | (3) | |
|---|---|---|---|
女性 | 1.858*** | 1.781*** | 1.809*** |
0.168 | 0.160 | 0.160 | |
识字能力 | − | 1.118** | 1.105** |
− | 0.049 | 0.049 | |
高收入 | − | − | 1.257 |
− | − | 0.186 | |
高基尼 | − | − | 7.548*** |
− | − | 0.054 | |
常数 | 0.407*** | 0.207*** | 0.189*** |
0.042 | 0.028 | 0.026 | |
观察数量 | 1992 | 1992 | 1992 |
国家数量 | 24 | 24 | 24 |
伪 R2 | 0.016 | 0.055 | 0.057 |
估计方法 | 对数几率 | 对数几率 | 对数几率 |
注释:因变量为“Covid-19 后的 PC 技能是否提高”。估计方法为对数几率,系数报告为几率比。在所有模型中,都聚类了鲁棒标准错误。在所有模型中都包含了国家固定效应。识字能力的衡量标准为从 0(一般)到 4(优秀)的等级。女性的参考类别是男性。高收入 = 1,如果受访者的收入高于本国中位数。高基尼 = 1,如果收入不平等高于样本中其他国家的中位数。
显著性水平:* p < 0.1,** p < 0.05,*** p < 0.01
3.6 大重启
社会可持续性是世界经济论坛(WEF)推动的“大重启”倡议的主要目标之一。其目标是通过创建一个更具韧性、更公平、更可持续的利益相关者经济来从 Covid-19 的挫折中崛起。增长应该更环保、更智能、更公平,符合联合国 2030 年可持续发展目标。
数字化过程在 2020 年首次封锁期间提供了积极的外部性:正如我们之前所见,更频繁地在封锁期间提升数字技能的人是女性和那些居住在收入不平等程度较高的国家的人。此外,受教育程度更高的人稍微更多地受益于数字化进程,这意味着技能是自我强化的。知识使得获取更多知识变得更容易。
政府的角色不仅在于创建信任,如前一节所述,而且同样重要的是平等分配和促进数字技能的获取、数字包容和连接。
财富不平等的驱动因素之一是对传统信贷形式的不平等获取。小型企业和私人公民通常无法提供足够的信用证明,没有财务资源,因此人口中有相当大的一部分被排除在市场之外,从而阻碍了创新和生产力。受影响最严重的人口部分包括低收入公民、妇女和少数民族。人工智能有可能克服这些限制,因为潜在的受益者可以在不同的领域进行评估:个人的信用 worthiness 不仅仅限于他们的财务历史,还可能包括他们的社交网络活动和行为、地理位置和在线购买等。在确保平等获得数字技术的条件下,最近的发展允许全球范围内将处于劣势和地理上偏远的人口纳入到金融、教育和商业现实中。例如,在孟加拉国,iFarmer 是一个众筹平台,汇集了以牛为目标的女性农民,面向潜在投资者。随着疫情的爆发,数字贷款经历了显著增长,特别是 Fintech 的特殊形式——P2P(点对点)借贷应用变得越来越成为银行或其他金融中介机构的替代品(Arninda 和 Prasetyani 2022)。在这些平台上,贷款从个人到个人转移,大幅削减了繁文缛节和成本。众筹和 P2P 借贷在疫情爆发前已经存在(Agur 等 2020;Lin 等 2017),但所获得的数字素养水平为针对性的政策干预提供了前所未有的机会,目的是将慈善家与在过去两年中被遗落的人以及有潜力但传统信用 worthiness 很小的小型创业项目与没有地理约束的小风险资本家联系起来。与约会应用程序类似,借款人和贷款人在匹配平台上相遇(例如 Estateguru、PeerBerry、Mintos 和 Lendermarket),这些平台通常受人工智能支持以优化市场。
人工智能是一种强大的技术。到目前为止,随着越来越多的人工智能解决方案的开发,我们只是触及到了可能实现的可能性的一部分。学习算法能够理解和重新解释复杂的人类需求,以克服可能阻碍无传统中介的金融交易成功的行为态度,缓解经济震荡对社会平等的负面影响,并在放贷方和借款方之间建立互信。人工智能已经广泛应用于关键基础设施领域,例如公共卫生、交通、供水、发电和电信,增强了它们在极端事件发生时的韧性。相同的韧性概念应该应用于中小企业和私人公民的金融资产:在大流行病或其他灾难等极端事件发生时,金融资产必须受到保护,并且能够迅速从这些冲击中恢复。除其他解决方案外,可以通过引导小投资者选择具有较高 ES(环境和社会)评级的股票来实现这一点,因为据显示它们对市场波动的反应较小(Albuquerque 等人 2020),通过增加人口的数字和金融素养,并提供公平的技术获取,无论其社会经济地位、种族、性别和年龄如何。
3.7 结论
战争、大流行病、恐怖袭击和自然灾害都以对金融市场产生重大影响而闻名。我们概述了上个世纪的主要经济和社会冲击,以及投资者在金融决策方面的反应。我们讨论了这些反应在社会平等方面所涉及的内容,以及这些危机如何影响个人偏好,如对冒险行为的倾向、对信任和对政府的信心的态度。
最近新冠疫情的一个特殊副作用是数字化。我们还将本章的一部分专门致力于数字素养现象,这在第一次封锁后经历了前所未有但又强有力的激增。虽然这一过程的成本和随后的市场不稳定性仍然不均匀分布,数字化为发展中国家和具有较低社会经济地位的阶层打开了一扇窗户:它具有教育、网络、经济增长和财富再分配的巨大潜力。然而,全球政府的任务是积极创造积极的变革和协同效应,防止其最终加剧人口和国家之间的社会经济差距。这可以通过建立信任、投资数字基础设施和人力资本、为私人公民和小企业提供培训和支持来实现。
社会联系是向上社会流动的已知预测因素,并且可能促成新的全球互联,这也可以被那些以前局限于常常有限的本地机会的人所利用。Chetty 等人 2022a,2022b 研究了基于社交媒体友谊和邮政编码的三种连接方式。第一种是低社会经济地位和高社会经济地位之间的连接,第二种类型是社会凝聚力,第三种是定义的公民参与水平。他们发现第一种(经济)连接是向上收入流动的最强因素。我们声称,这在某种程度上也适用于全球互联,无论物理距离如何。
当前世纪是复杂性的世纪,正如一位著名物理学家已经预言的那样,而我们已经看到,金融市场也不例外。弹性概念的发展是这一预言的结果,因为复杂性无法用一颗药丸解决。然而,通过增加金融和数字素养,投资于教育,提供技术接入,并通过建立对同行和政府的信心,可以实现从未预料到的情况中恢复——无论是在金融还是社会上。一个更加公平的世界可以通过增强同行和政府的信心、投资于教育以及提供技术接入来创建。最后,利益相关者资本主义的理念,即公司以共同利益为考量而不是眼前利润行事,以及创建一个具有韧性、平等和环境可持续性的系统是大重启的主要支柱,这是世界经济论坛推动的一个倡议,将在下一章中更深入地介绍。
第四章:大重置中的人工智能角色
费德里科·切科尼^(1 )(1)LABSS-ISTC-CNR,Via Palestro 32,00185 罗马,意大利费德里科·切科尼电子邮件:federico.cecconi@istc.cnr.it
摘要
“大重置”一词现已进入公共领域,并出现在许多分析和讨论中。然而,我们在这方面经常保持模糊。阅读世界经济论坛的所谓白皮书《在后疫情世界中重置未来工作议程》可能会有所帮助,以了解这一时代性举措的理论家们的目标。这份 31 页的文件描述了如何运行(或者,如今他们所说的,实施)包含在 CoViD-19 书籍中的软件。世界经济论坛创始人克劳斯·施瓦布和蒂埃里·马勒雷共同撰写了《大重置》(Schwab and Malleret 在《COVID-19:大重置》中,2020;Umbrello 在《价值探讨期刊》中:1-8,2021;Roth 在《欧洲管理期刊》39.5:538-544,2021)。为什么在一本关于人工智能及其在金融中的应用的书中要专门致力于这个话题一个完整的章节?答案很简单:为了更新金融世界,使其更安全、更可理解和更可控制,需要广泛使用人工智能技术。这些技术在某种程度上可能是有害的。
关键词大重置 COVID-19 微趋势信用 ESGF 费德里科·切科尼
是 QBT Sagl 的研发经理(www.qbt.ch),负责计算机网络管理的 LABSS(CNR)和仿真的计算资源,并为 Arcipelago Software Srl 担任顾问。他为 Labss 开发计算和数学模型(社会动态、声誉、规范动态)。对于 Labss 进行了传播和培训。他目前的研究兴趣有两个方面:一是使用计算模型和数据库研究社会经济现象。第二个是为金融科技和房地产科技开发人工智能模型。
4.1 总结大重置
大重置可能是以信息技术(人工智能作为主要支柱)为核心的第一次大革命:重置未来涵盖了从 2021 年到 2030 年的十年(见图 4.1)。

世界经济论坛的显示页面上有标题“大重置”。下面,一个文本写着六月十日的亮点。
图 4.1
描述了大重置,是世界经济论坛的一个倡议。
首先,数字化工作流程将加速进行,要求所有工作流程的 84%都必须数字化或通过视频制作。为了实现完全的社会分离,大约 83%的人将被要求远程工作,不与任何人进行互动。预计至少一半的活动将被自动化,这意味着直接的人类参与,甚至在相同的远程活动中,都将大大减少,并且升级和再培训活动也需要电脑化。升级是获取新技能,使个人在其领域更加有效和合格。为了让一个人执行不同的功能而获得明显不同的能力,这被称为再培训。换句话说,在这种情况下的要务是避免人与人之间的接触,并通过计算机、人工智能和算法实现一切。
加快重新培训计划的实施,以使至少 35%的技能得到“再培训”,这意味着必须放弃已经获得的技能。
加快组织结构改革的步伐。建议对当前 34%的组织结构进行“重组”,宣布其过时。目标是为新的组织框架腾出空间,以便对所有活动,包括数字化,保持完全控制。
暂时重新分配人员到不同的岗位:这可能会影响到大约 30%的劳动力。这包括对工资水平的审查。
暂时减少劳动力:这一命运预计将影响 28%的人口。这是一个失业问题,因为“暂时”一词的含义不明确。
此外,大重置还包括一个信用计划,其中个人债务可能会被“宽恕”,以换取所有个人资产的转让给一个行政机构或机构。
先前的 COVID-19 传播是追求大重置的最迫切理由。这场大流行是近年来最致命的公共卫生危机之一,已经造成数十万人死亡。战争远未结束,在世界许多地方仍然报告有伤亡。
结果,长期的经济增长、公共债务、就业和人类福祉都将受到影响。《金融时报》报道称,全球政府债务已经达到历史最高水平。此外,许多国家的失业率正在飙升;例如,在美国,自 3 月中旬以来,每四名工人中就有一人申请了失业救济金,每周的新申请数量远远超过历史最高水平。据国际货币基金组织称,全球经济今年将收缩 3%,在短短四个月内下降了 6.3 个百分点。
所有这些将加剧现有的气候和社会危机。一些国家已经利用 COVID-19 危机削弱了环境保护和执法力度。而对于像日益加剧的不平等这样的社会弊病的不满—美国亿万富翁的总财富在危机期间增加了—正在增长。
实际上,已经有一个可以用一个词概括的要求:稳定。我们目前正在目睹我们社会和全球出现大量怀疑的情况。然而,主要要求是稳定。虽然本章的大部分内容将继续集中讨论 COVID 及其后果,但重要的是要记住需求要大得多。
如果不加以解决,这些危机连同 COVID-19 将会恶化,使世界变得不可持续、不平等和脆弱。渐进措施和临时修复措施将不足以避免这种情况。我们的经济和社会体系必须彻底重建。
这需要前所未有的合作和雄心壮志。然而,这并非是不可能实现的梦想。大流行的一个好处是,它展示了我们有多快速地进行根本性的生活方式变革。几乎立即,危机迫使企业和个人放弃长期坚持的重要做法,如频繁的空中旅行和办公。
同样,人口已经表现出为医疗保健等基本工作者以及脆弱人群如老年人做出牺牲的强烈意愿。而且,许多公司已经开始支持员工、客户和当地社区,向以前只是口头上支持的利益相关者资本主义方向转变。
显然,人们希望创造一个更好的社会。我们必须利用它来确保急需的大重置。这将需要更强大和有效的政府,但这并不意味着要推动更大的意识形态。这还需要私营部门在各个阶段的参与。
4.2 元素
大重置议程将包括三个主要组成部分。第一个是引导市场走向更加公平的结果。政府应该提高协调能力(例如,在税收、监管和财政政策方面),升级贸易协定,并创造实现这一目标的“利益相关者经济”的条件。在税基萎缩和公共债务飙升的时代,政府有强烈的动机采取这样的行动。
此外,政府应该进行长期拖延的改革,促进更公平的结果。这些可能包括改变财富税、消除化石燃料补贴以及根据国家情况制定新的知识产权、贸易和竞争规则。
大重置议程的第二个组成部分将是确保投资推动诸如平等和可持续性之类的共同目标。许多政府正在实施的大规模支出计划为在这一领域取得进展提供了重要机会。例如,欧洲委员会提出了一个 7500 亿欧元(8260 亿美元)的复苏基金。美国、中国和日本都有积极的经济刺激计划。
我们应该利用这些资金以及来自私人实体和养老基金的投资,来修补旧系统,而应该利用它们来建立一个更具弹性、更公平和长期可持续的新系统。例如,这包括建设“绿色”城市基础设施,并制定激励措施,鼓励行业在环境、社会和治理(ESG)指标上改善业绩。
大重置议程的第三个也是最后一个优先事项是利用第四次工业革命的创新来造福公共利益,特别是解决健康和社会挑战。在 COVID-19 危机期间,公司、大学等团结一致,开发诊断、治疗方法和可能的疫苗;建立测试中心;开发追踪感染的机制;提供远程医疗服务。想象一下,如果每个领域都采取类似协调的努力,可以取得什么样的成就。
4.3 微趋势
大重置将涉及一系列长期而复杂的微观层面、行业和企业的变革和调整。面对这一挑战,一些行业领导者和高级执行官可能会试图将恢复与重启等同起来,希望回到过去的常态,并恢复过去的成功之道:传统、经过验证的程序和熟悉的做事方式——简而言之,恢复到常规业务。这是不可能发生的,因为它不可能发生。在大多数情况下,“常规业务”已经死亡(或被感染)了 COVID-19。封锁和社交隔离措施导致的经济休眠摧毁了一些部门。在全球经济衰退的影响下,其他部门将在艰难地恢复失去的收入之前,开始走上一条越来越狭窄的盈利之路。然而,对于进入后冠状病毒时代的大多数企业来说,关键问题将是在过去的成功之间找到平衡和如何在新常态中蓬勃发展。对于这些企业来说,大流行代表了重新思考其业务并实施积极长期变革的一次千载难逢的机会。
什么将定义后冠状病毒时代的新常态?
企业将如何在过去的成功和现在在后疫情时代成功所需的基本要素之间取得最佳平衡?
答案显然取决于每个行业,以及疫情的严重程度。除了少数几个行业会因强劲的有利因素(尤其是技术、健康和健康)而从中受益外,其他行业在后疫情时代的旅程将会艰难,有时甚至会充满危险。对于一些行业,比如娱乐、旅游和酒店业,近期内恢复到疫情前的状况是难以想象的(在某些情况下甚至永远不会……)。另一些行业,尤其是制造业和食品业,更关注于适应冲击并利用新趋势(比如数字化)在后疫情时代蓬勃发展。规模也是一个重要因素。小型企业面临更多挑战,因为它们的现金储备和利润率比大型企业低。
大多数公司将不得不应对将来使它们在成本收入比方面处于劣势的问题,与它们更大的竞争对手相比。然而,在当今世界,灵活性和速度可能决定企业的适应能力,而这对于小型结构来说比对于大型工业结构更容易实现。在今天的世界里,灵活性和速度可以决定企业的生死存亡。
话虽如此,无论行业或特定情况如何,全球几乎所有的商业决策者都将面临类似的问题,并需要回答一些共同的问题和挑战。以下是最明显的几点:
我应该鼓励那些能够(大约占美国劳动力总数的 30%)在家工作的人吗?
我是否会减少公司对航空旅行的依赖,并能用虚拟互动大幅替代多少面对面会议?
我如何使企业和我们的决策过程更加灵活,让我们能够更快速、更果断地行动?
我如何加速数字化和数字解决方案的采用?
我们仍处于后疫情时代的早期阶段,但已经有一些新的或正在加速的趋势在起作用。对于一些行业来说,这将是一个福音;对于其他行业来说,这将是一个重大挑战。然而,每家公司都将根据所有行业的快速而果断的适应能力来利用这些新趋势。表现出最大灵活性和适应能力的公司将会更加强大。
数字化正在加速发展
“数字转型”这个流行词在大流行之前是大多数执行委员会和委员会的口头禅。数字是“至关重要的”,必须“果断”实施,并被视为“成功的前提”!从那时起,这个口头禅已经成为一种必须,甚至在一些企业的情况下,成为生死攸关的问题。这很容易解释和理解。在我们被监禁期间,我们完全依赖互联网进行一切,从工作和教育到社交。正是在线服务让我们保持了一种正常的状态,自然,“在线”是从大流行中受益最多的,为我们提供了一个巨大的推动力,这些技术和流程使我们能够远程完成各种事务,如通用互联网到宽带、移动和远程支付以及可行的电子政务服务等。因此,已经在线运营的企业将拥有长期的竞争优势。像电子商务、无接触运营、数字内容、机器人和无人机交付等行业的企业将随着越来越多的事物和服务通过我们的手机和电脑送到我们手中而蓬勃发展。阿里巴巴、亚马逊、Netflix 和 Zoom 等公司之所以成为封锁的“赢家”,并非偶然。
一般来说,消费者部门是第一个也是发展最快的部门。从封锁期间对许多食品和零售企业强制实施的无接触体验到允许客户浏览和选择他们喜欢的产品的制造业虚拟展厅,大多数企业对消费者的数字旅程“从头到尾”有了快速的认识。
随着一些封锁的结束和一些经济体的复苏,在企业对企业应用中出现了类似的机会,尤其是在制造业中,需要快速实施社交距离规则,通常是在困难的环境中。(例如,装配线。)
因此,物联网取得了显著进展。在封锁之前对物联网采取缓慢步伐的一些公司现在纷纷拥抱它,其特定目标是尽可能多地远程进行各种活动。所有这些不同的活动,如设备维护、库存管理、供应商关系和安全策略,现在都可以(在很大程度上)由计算机执行。物联网为企业提供了不仅能够执行和遵守社交距离规则,还能够降低成本并实施更敏捷运营的能力。
由于全球供应链固有的脆弱性,关于缩短的讨论已经进行了多年。它们通常是错综复杂且难以管理的。它们在环境和劳工法合规方面的监督也很困难,这可能会使公司面临声誉风险和品牌损害。鉴于这段动荡的历史,大流行已经为公司应该根据单个组件的成本以及关键材料的单一供应来源来优化供应链的原则敲定了最后一击。在后大流行时代,“端到端价值优化”——包括弹性、效率和成本的概念将占主导地位。该公式指出,“万一”最终将取代“及时”。
宏观部分讨论的对全球供应链的冲击将影响大大小小的企业。但在实践中,“万一”意味着什么呢?上世纪末由全球制造公司构想并建立的全球化模式,以寻找低成本劳动力、产品和零部件为目的,已经达到了极限。它将国际生产分解为越来越复杂的碎片,导致了一个在亲密规模上运作的系统,这个系统被证明是极其精益和高效的,但也极其复杂,因此也极其脆弱(复杂性带来脆弱性,通常会引发不稳定性)。因此,简化是解毒剂,这应该会增加弹性。结果,占全球贸易约四分之三的“全球价值链”将不可避免地下降。这种下降将被新现实加剧,即依赖复杂的及时供应链的公司不能再假设世界贸易组织的关税承诺会保护它们免受来自某个地方的突然保护主义浪潮的影响。
因此,它们将被迫通过减少或本地化他们的供应链,并制定替代性的生产或供应计划来准备长期停产。任何盈利依赖于及时全球供应链原则的企业都将不得不重新考虑其运营方式,并几乎可以肯定地牺牲最大化效率和利润的想法,以换取“供应安全”和弹性。弹性随后将成为任何认真保护自身免受干扰的企业的主要考虑因素,无论这种干扰是由特定供应商、贸易政策的潜在变化,还是特定国家或地区引起的。在实践中,这将迫使企业扩大其供应商基础,即使这意味着囤积和创建冗余也要付出代价。这也将迫使这些公司确保同样的情况在他们自己的供应链中也成立:他们将评估整个供应链的弹性,一直到最终供应商,甚至可能是供应商的供应商。生产成本将不可避免地上升,但这将是建立弹性的成本。乍一看,汽车、电子和工业机械行业将受到最大影响,因为它们将是首批改变生产模式的企业。
4.5 ESG 和利益相关者资本主义
过去十年左右在 Chap. 1 中审查的五个宏观类别中发生的根本性变化,已经深刻地改变了企业运营环境。它们提高了利益相关者资本主义和环境、社会和治理(ESG)考虑因素在创造长期价值方面的重要性(ESG 可以被认为是利益相关者资本主义的基准)(Puaschunder 2021)。
当许多问题,从行动主义到气候变化,再到不断加剧的不平等现象、性别多样性和#MeToo 丑闻,已经开始引起人们的关注并增加了在当今相互依存的世界中利益相关者资本主义和 ESG 考虑因素的重要性时,这场流行病就爆发了。无论他们是否公开结婚,没有人可以否认,企业的根本目的不再能是对金融利润的放任追求;他们现在必须为所有利益相关者服务,而不仅仅是持有股份的人。这得到了早期轶事证据的支持,表明在后疫情时代,ESG 的未来将更加光明。这可以通过以下三种方式解释:
-
大多数 ESG 问题,尤其是气候变化,危机将会在很大程度上加强或强化对责任和紧迫感的认识。然而,其他问题,如消费者行为、未来工作和流动性以及供应链责任,将成为投资议程的重点,并成为尽职调查的重要组成部分。
-
这场大流行表明,缺乏 ESG 考虑可能摧毁大量价值,甚至威胁到公司的盈利能力。之后,ESG 将更加全面地融入和内化到公司的核心战略和治理中。这也将改变投资者对企业治理的看法。为了避免出现或公之于众的问题带来声誉成本,税收回报、股息支付和工资将受到更严密的审查。
-
提升员工和社区的友好关系对于提升品牌声誉至关重要。
4.6 现在是时候揭晓了……
因此,如果世界选择走这条路,捍卫并追求这些目标,甚至部分接受这些论点,我们几乎肯定会陷入一种情况,即人工智能算法将管理我们无法简单应对的事务。这是一次真正历史性的革命。在讨论数字化时,许多人关注的是更直接的后果,比如失业。相反,这里首次支持的论点是:智能信息技术将能够帮助我们管理复杂性。这是一个真正引人入胜的挑战:以人工智能换取稳定(Da Silva Vieira 2020;Murmann 2003)。
第五章:人工智能金融科技:揭示真相
费德里科·切科尼^(1 ) 和 阿莱山德罗·巴拉泽蒂^(2 ) (1)LABSS-ISTC-CNR, 意大利罗马, Via Palestro 32, 00185(2)QBT Sagl, 瑞士基亚索, Via E.Bossi, 4 CH6830 阿莱山德罗·巴拉泽蒂(通讯作者)Email: federico.cecconi@istc.cnr.it 阿莱山德罗·巴拉泽蒂 Email: alessandro.barazzetti@qbt.ch
摘要
我们提出了一个应用示例,可能对我们的经济产生重大影响:利用人工智能代理复制动态,研究假新闻的传播。众所周知,大量应用程序(其中一些在此处描述)致力于通过观察主要趋势来投资于金融市场,通常以非常高的速度进行操作。这些应用程序经常通过不理性地加速下行趋势而引起问题。市场正在采取措施应对这种类型的问题。但是,正在出现能够评估不是趋势而是直接是趋势本身原因的新闻的自动交易员。这引发了以下问题:如果文化传播(在这种情况下是新闻,但也可能是社交网络上的帖子,稍有改变)因“假新闻”的出现而变得困难,我们如何对我们的自动交易员的运作感到放心?在这里,我们提出了对这个问题的全新方法,该方法利用了一种广泛应用的人工智能技术,即人工代理。这些代理重现了假新闻的传播现象,并提供了如何对抗它的指导(Chen and Freire in Discovering and measuring malicious URL redirection campaigns from fake news domains, pp. 1–6, 2021; Garg et al. in Replaying archived twitter: when your bird is broken, will it bring you down? pp. 160–169, 2021; Mahesh et al. in Identification of Fake News Using Deep Learning Architecture, pp. 1246–1253, 2021).
关键词假新闻自动交易基于代理的仿真费德里科·切科尼
是 QBT Sagl 的研发经理 (www.qbt.ch),负责计算机网络管理和模拟的 LABSS(CNR),并为 Arcipelago Software Srl 担任顾问。他为 Labss 的问题(社会动态、声誉、规范动态)开发计算和数学模型。Labss 既进行传播又进行培训。他目前的研究兴趣有两个方面:一方面,使用计算模型和数据库研究社会经济现象。第二个是为金融科技和地产科技开发人工智能模型。
阿莱山德罗·巴拉泽蒂
米兰理工大学航空工程师,卢德斯(Ludes)校外赛梅尔威斯大学(Semmelweis University)教授和飞行员是 QBT Sagl 的所有者,该公司在金融科技和房地产科技领域开发算法和软件,并且是 Science Adventure Sagl 的所有者,该公司专注于开发应用于卫生保健的人工智能解决方案以及航空航天领域的高级项目。亚历山德罗还是 SST srl 的创始人,一家致力于可持续性研究和认证的公司,以及 Reacorp Sagl,一家致力于金融科技和房地产科技服务的公司。
5.1 文化的扩散
与文化扩散和巩固动态相关的社会学文献非常广泛。在这里,我们选择从 Axelrod 定义的文化概念出发,他认为文化的传播是社会行为者之间相互影响过程的产物,这些行为者分享特定的价值观和独特的特征。实际上,相似的代理人倾向于彼此之间的互动,因此在他们之间形成了一种同化增长的圈子。在这种情况下,代理人之间的互动过程起着关键作用。
特别是,在社会行为者的日常行为中可以找到社会结构的无处不在,以至于在确定自身身份的过程中同时发生。在集体维度上,社交媒体的作用在于确定可以是“弱”的、瞬时的亲和网络,但也可以自我构建到成为真正的社会群体的程度。
因此,在社交媒体的维度内,关系潜力变得如此重要,以至于消费者不仅是信息和内容的使用者,还成为它们的生产者和编辑,形成了一个连续的知识循环。
在这种解释框架中,产消者的形象诞生了,即媒体产品的生产者(生产者)和用户(消费者)。产消者这一术语是由美国社会学家托夫勒在 1980 年创造的,而让·克鲁提尔(Jean Cloutier)在 1975 年已经制定了一个类似的理想类型,将其定义为自我媒体,这两种情况下我们都指的是主体在当代文化和媒体产品中既是生产者又是用户的能力。
然而,数字生产者不能被视为一个特定的一次性人物,而是定义了网络的任何用户。由于每个数字行为者也是内容生产者,特别是数据生产者。在网络空间内生成数字内容的行为实际上不一定局限于创建特定的在线多媒体内容(帖子、视频、图像),它还涉及到更简单和表面上低沟通活动,比如分享或转发内容,插入喜欢或在特定地点地理定位自己。
选择打开一个网站而不是另一个,也意味着你在无意中为其管理做出了贡献。
5.2 研究设计
这个人工智能解决方案的目标是重建 Facebook 页面分享阴谋主题文章的过程,形成了一种从非官方来源获取新闻的泡沫。具体来说,基于人工智能代理的模拟模型被编码了。这些代理是文章、社交页面、网站和用户;它们相互作用形成了页面到文章网络(‘pages to articles’ network, pta network),这是我们调查的焦点(Gupta 和 Potika 2021;An 等 2021;Yu 等 2021;Singh 和 Sampath 2020)。
该模拟项目是基于一个通过两个研究问题构建的探索性调查。
问题 1——一些存在于数字空间中的误导性信息内容具有一些特性,使它们对特定的 Facebook 页面和群体具有吸引力,并且基于特定特征,这些内容在社交网络中传播。这些属性分别涉及:基于阴谋的内容、阴谋内容的强度、政治取向、煽动仇恨和煽动恐惧。
问题 2——涉及通过模拟模型分析文章内容对生态舱拓扑结构的影响。
5.3 数据挖掘
在第一阶段,通过对 Facebook 上一组公开群体中的互动和共享内容进行定性观察,对意大利反信息源的数字足迹进行了分析。在这方面,根据其与阴谋运动典型主题内容的一致性,已选择了 197 篇文章(Choudhary 和 Arora 2021;Garg 和 Jeevaraj 2021)。
随后,通过社交网络分析工具检测了每篇文章在 Facebook 内的互动。这个阶段对于界定阴谋主义公共页面和群体的生态系统以及识别互动最多的帖子都很重要。一些经验性证据从初步分析中浮现出来:(1)有一些 Facebook 来源只分享基于阴谋的内容;(2)这些文章对于具有特定内容的页面具有兴趣;(3)发现的内容反过来又来自专门传播阴谋信息的来源。
收集的数据集和进行的处理使得能够确定构建回音室过程的主要单元(代理):
网站或站点(博客、信息门户、在线报纸等),它们产生并包含所识别的文章。
文章,研究的第一阶段收集的具有呈现信息内容特征的文章。
页面,这个类别包括分享文章的页面和公共 Facebook 群组。
用户,与文章在 Facebook 上进行互动的用户。
5.4 ABM 模拟
模拟的目的是重建页面与文章的关系。在模拟中,我们必须创建页面和文章之间的链接。这必须使用从调查中获取的文章、网站、页面和用户的属性来完成。在起始阶段,页面和文章之间的链接没有加载,因为这种类型的网络代表了模拟的输出。
根据在数据挖掘阶段收集的数据,模拟模型被设计并编码为两个操作任务:定义代理和定义算法。收集的数据用于构建人工代理,分为四个代理集:文章、网站、页面和用户(图 5.1)。
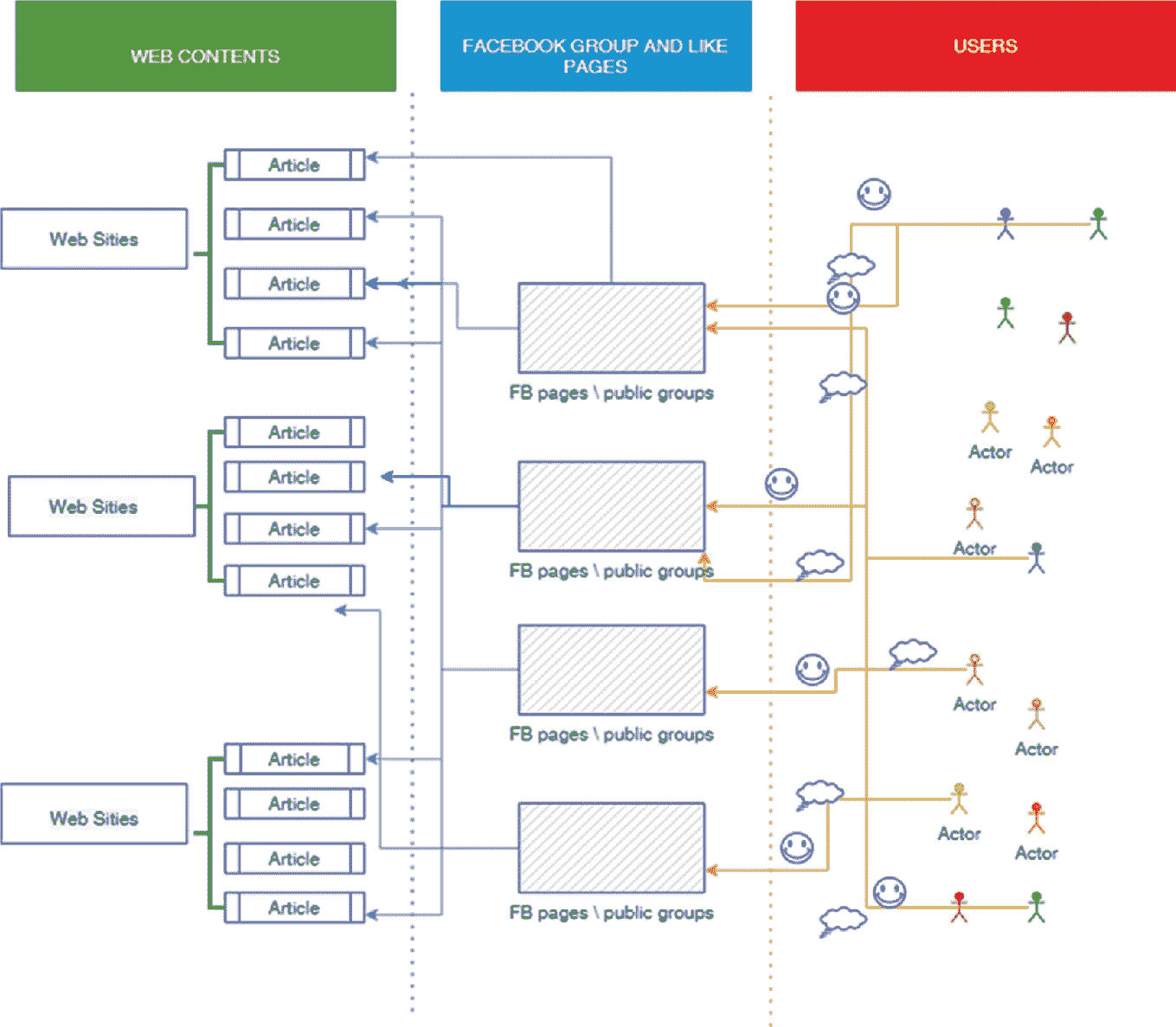
一个框架说明了网页内容与 Facebook 群组和喜欢的页面如何与用户联系在一起。用户在 Facebook 页面和公共群组上发布内容,这些内容被用作网站上的文章。
图 5.1
agentsets
具体来说,四种类型的结构如下:只有网站与文章相连,文章与网站和页面相连,页面与文章和用户相连,最后用户只与页面相连。
具体来说,文章数据集是通过将在研究的第一阶段中识别的所有文章按照以下解释性类别的内容进行分类而构建的:(1)内容,阴谋内容的存在/不存在;(2)强度,内容在 1 到 5 的等级上的强度;(3)议题,或文章中存在的阴谋叙事;(4)政治,文章是否与政治相关联;(5)政治取向,它呈现了什么政治取向;(6)煽动仇恨,是否具有煽动仇恨的特征;(7)煽动恐惧,是否煽动恐惧。
Websities 数据集是通过为每个识别的网站插入以下信息而组成的:交互总和、文章计数、名望指数和独家性。交互总和表示该网站内容在 Facebook 内获得的所有互动总和,而文章计数则是指从该网站收集到的文章数量。这两个值加在一起形成了名望指数,这是一个综合指数,表示一个网站在检测到的闭环中有多受欢迎。
页面数据库由以下内容组成:来源或 Facebook 页面或公共群组的名称,追随者,页面的追随者数量,交互或每篇文章收集到的互动。
最后,用户由用户标识或标签以及每个页面的产品评论内容组成。
5.5 结果:AI 反“假新闻”机器
在图 5.2 中,我们展示了模拟器的界面!
模拟器界面左侧有按钮,并有连接的点和线的照片。左侧的按钮包括运行下划线模拟,运行下划线模拟,设置下划线模拟,选择随机设置的模态,从界面选择的场景以及导入下划线世界。
图 5.2
NFN 系统的界面
如前所述,模拟器加载了一组文章、可以发布这些文章的网页、生成这些内容的用户以及可以找到这些文章的网站。上传完成后,模拟器假设文章将如何连接到页面,重要或不重要的是什么,以创建同质群体(此处使用的示例涉及健康阴谋论者的同质群体)。
在我们使用的图像中,黄色的图形是代理,房屋是网站,顶部两个框包含了被引用的文章和网页。显然,整个界面都是可选择的,可以进行交叉查询,例如找出在创建所有用户都处于联系状态的群体时哪些因素是决定性的(图 5.3)。模拟器接收一定数量的参数作为输入,例如需要给予文章中暴力煽动的存在或不存在多少权重等!
描绘了模拟器界面中的一些按钮。
图 5.3
模拟器的一些输入参数
整个模拟的主要结果是一份报告,总结了导致(或未导致)形成同质阴谋论者群体的因素(示例见表 5.1)。模拟结束后,可以利用该报告选择要馈送给自动资产评估系统的内容,以便能够说出例如… 避免存在关于 RNA 疫苗效果的明显正确评估的内容;因为这些评估是阴谋泡沫形成的基础…,这可能会误导自动评估系统。
NFN 系统评估报告摘录
因素 | |
|---|---|
假新闻泡沫 | RNA 疫苗分配 RNA 生产疫苗(次要) |
群体 | 主要问题中使用‘仇恨’使用‘科学引用’次要问题中使用‘欧盟’ |
换句话说,NFN 系统¹(或其他基于相同类型人工智能代理的模拟器)可以作为风险“选择器”发挥作用,指示哪些语义方面,本例中是从社交网络中提取的,但类似地也可以从新闻中提取,从那些将内容用于基于语义的自动系统的人的角度来看,可以构成风险(Marium 和 Mamatha 2021; Nath 等人 2021; Uppal 2020)。
第六章:ABM 应用于金融市场
Riccardo Vasellini^(1 )(1)意大利锡耶纳大学,锡耶纳 Riccardo VaselliniEmail:r.vasellini@student.unisi.it
摘要
传统经济理论难以解释金融市场波动和宏观经济。交易者很少像标准经济模型中描述的那样假设自己是理性的优化者,他们不会在金融市场中如此行事。繁荣与萧条周期普遍存在,像是公司价值仅基于 CEO 的花哨个性、鲁莽投机者以及普遍的不理性感觉。显然,仅凭这一点就不足以将旧经济理论谴责为“无用”。事实上,了解人类行为导致的自我调节、稳定的市场,在这种市场中价格从不偏离平衡太远,可以提供令人兴奋和实用的结果。与其将整个金融系统作为一个整体进行评估并从上到下对其进行建模,不如检查其代理人,看看是否可以从它们的互动中产生系统特征。这被广泛用于研究所谓的复杂系统,这些系统表现出显著的非线性和不稳定的平衡状态,很容易被小冲击打乱。传统经济理论在说明相对狭窄的系统状态方面是有效的,即市场处于平衡状态的情况。然而,借助复杂系统理论支持的替代技术,可以描绘出一个更通用的模型,在这个模型中,平衡状态是更大模型的一个子领域。ABM 是模拟复杂系统的一种有价值的方法。自下而上的建模不需要科学家将整个系统近似为微分方程。他们可以模仿系统单个代理人的互动。如果代理人的行为假设正确,共享行为应该会在系统中“出现”。
关键词:基于代理的建模、金融市场、认知、Riccardo Vasellini
具有土木、环境和管理工程背景的博士候选人。我目前在锡耶纳大学信息科学系学习,专攻复杂系统。在科学界,我的目标是利用基于代理的建模和人工智能来深入了解复杂系统。我认为研究 emergent phenomena 和系统动力学对做出明智决策至关重要。在攻读博士学位期间,我在多个行业担任项目经理,包括房地产开发、房地产投资组合管理、可再生能源和旅游业。
6.1 引言
传统经济理论在解释金融市场波动及其与宏观经济的关系方面特别困难(LeBaron 2000)。在金融市场中,交易者很少扮演传统经济模型中经常描绘的理性优化者的角色,事实上,观察到经济的繁荣和衰退周期、公司估值仅取决于首席执行官的吸引力、鲁莽的投机者以及整体上的许多非理性行为并不罕见。
显然,这并不足以将传统经济模型视为“无用”,事实上,认为人类行为导致自我调节、稳定的市场,价格永远不会偏离均衡,可能会产生有趣且现实的结果(Iori 和 Porter 2012)。
然而,也存在一种替代方法:不是将金融系统作为一个整体进行评估,并使用自上而下的方法对其进行建模,而是可能考虑通过理解构成系统的代理并观察系统的共同特性是否从它们的相互作用中出现。这通常是研究所谓的复杂系统的方法,即表现出高度非线性的系统,在其中平衡状态是不稳定的,小的扰动很容易打破它们。
有人可能会认为,传统经济理论成功地阐明了一个非常具体的系统状态,即市场处于均衡状态,而由复杂系统理论支持的替代方法可以实现更一般的模型的阐明,其中特定的均衡状态是更广泛模型的一个子领域。
建模复杂系统的一种非常好的方法是使用基于代理的建模。在这种建模类型中,自下而上的方法至关重要,科学家们无需将整个系统近似为微分方程。相反,他们可以集中精力模拟系统中存在的单个代理之间的相互作用。如果创建代理的行为假设是合理的,那么人们期望看到整个系统共享的行为的“出现”。
对于那些不太熟悉这种建模类型的人,想象一下以下情景:
你想描述一个充满气体的气球的行为,而不是写下盖·吕萨克定律,PV = nRT,因此使用自上而下的方法,你描述一个气体的单个原子或分子在交换热量、改变其运动量或被另一个气体原子击中时的行为。然后你使用计算机模拟所有这些原子之间的相互作用以及原子与环境的相互作用。如果你做得很好,出现的结果将与盖·吕萨克定律一致,即使你可能对整个气球一无所知。
显然,在这个比喻的具体案例中,使用这种方法似乎相当违反直觉且不必要复杂。然而,在许多情况下,使用传统的数学模型可能会很困难,甚至是不可能的。当处理大量方程式和多个具有许多指标的异质变量时,数学模型通常不是特别有效的。
这些合规性可以通过算法和迭代过程来更好地管理。特别是当系统的部分经常相互作用,导致重要特征的出现时,要理解系统通常很难实现传统的数学模型。我刚刚写的并不完全准确,更准确的说法是当科学家试图描述系统的整体时,很难实现传统模型。当无法进行鸟瞰式的观察时,比如在社会或经济领域,即使研究该系统的人也是其中的一部分,那么尝试使用代理基模型(ABM)是有用的,从底层开始,从我们能够理解和简化描述的部分进行模拟。这就是 ABM 的真正威力。用另一个比喻来说,描述一只蚂蚁,一个非常简单的生物,要比描述整个蚁巢容易得多,后者的行为不能通过简单描述单个蚂蚁的行为来理解。然而,利用模拟的力量是可能的,通过为单个蚂蚁设置简单的行为规则,描述整个蚁巢。
现在我们已经了解了 ABM 的全部内容,我们可以提供一些建模概述,接着我们将介绍本书作者开发的一种新模型。
6.2 代理基模型(ABM)
代理基模型(ABMs)对新古典主义理念提出了挑战,该理念认为代理根据他们对经济的充分理解和无限的计算能力形成理性预期(Iori 和 Porter 2012)。全知的理性代理被具有有限理性的代理所替代(Simon 1997),后者能够通过行为规则和启发式方法推断市场。实际上,我们可以使用代理的建模类型来分类不同的建模方法:
零智能代理:代理人几乎无法学习,或者根本不具备学习能力,他们的行为规则极其简单。这类模型的重点在于观察是否能从系统结构中产生实际存在于真实金融市场中的特征。这方面的一个很好的例子是由 Farmer 等人开发的模型(2005)。作者将非理性代理人的概念推到了极致,创建了完全没有理性的代理人。在这个模型中,代理人只是随机下订单(订单确切地以泊松随机过程到达),并参与连续的双边竞价,即他们可以随时下买单或卖单。因此,该模型放弃了描述市场策略或人类行为的任何野心,而是主要专注于表征连续双边竞价对系统施加的限制。代理人之间唯一的区别在于他们下订单的频率:不耐烦的代理人将被迫在单位时间内下达固定数量的订单,而耐心的代理人将随机下订单,不仅仅是为了定价,还有时间上的考虑。然后,作者将他们的发现与来自伦敦证券交易所的真实数据进行了比较和评估,仅使用一个自由参数就能解释约 96%的价差和 75%的价格扩散率的变化。
令人惊讶的是,仅仅通过对代理人行为进行非常简单的假设,例如这种最简单的情况,就可以通过将建模注意力集中在代理人实际交互的方式上(连续双边竞价)来重现市场和价格的特征。
在传统模型中,交易者普遍缺乏的一个特征是可能成为图表分析者的可能性。在理性的假设下,股票交易者唯一的可能性就是一直试图发现股票的真实估值并据此交易的基本主义者。
然而,当实现比零智能代理更复杂的代理时,可以包含任意数量的行为规则。在这个框架内,交易者可以追求不同的策略,并对来自市场或其他代理的信号做出不同的反应。Iori 和 Porter(2012)区分了通过市场进行中介交互的异质代理和那些可以直接相互交互的代理。后者类型已被证明对于解释金融中的群体行为很有用(Hirshleifer 和 Slew,2003),而前者则有助于理解学习的作用(LeBaron,2000)。
6.3 我们的模型
我们开始开发这个模型的起点是一个基本的想法:市场是多样化的生态系统,象征性地由无数不同种类的物种组成,每个物种都有自己的利益和抱负。了解这些人群是如何行动和相互作用的可能有助于我们理解市场行为。
这正是安德鲁·罗在他的自适应市场理论中所主张的,这是将有效市场理论纳入更广泛框架的尝试,使其成为特殊情况。以这种方式考虑金融市场意味着将它们视为复杂系统;因此,要理解它们,我们必须采用我们用于研究复杂性的方法。我们决定最好的方法是使用 AB 建模。
此外,我们开始思考这些生活在金融生态系统中的“群体”是否可以从市场中多个交易代理之间的相互作用中自发产生。通过“群体”,我们指的是表现出动态相似行为的代理的聚类。在真实市场中,这可能包括机构和零售投资者或算法和手动交易者等等。群体仅仅受到人们想象力的限制。我们决定只专注于两种类型的投资者:基本主义者和图表派(不幸的是,我们将他们称为“趋势主义者”)。
我们的主要目标是证明如果没有任何对基本主义者或图表派的先验配置或偏见,也没有任何来自系统的明确外部触发器推动向一个方向或另一个方向,那么代理人如何能够聚集成一群投资者,其行为随着时间的推移而呈现出特定的模式。这些行为仅通过代理人可用的两种适应机制,即学习和模仿,自发地产生。现在我们将继续更详细地描述模型。
6.3.1 概述
每天,交易员会使用两种不同的方法分析三种股票。他们对股票进行基本分析,模拟调查发行股票的基础公司的价值,并据此定价股票。他们还会进行趋势分析,仅关注股票的先前表现,而忽略基础资产。执行这两种定价方法的顺序并不重要。然后,他们将根据他们当前的市场展望,或者是否认为成为“基本主义者”或“图表派”更为可取,权衡两个获得的价格。此外,市场参与者当前有多贪婪或恐惧也会影响价格。最后,在进行这些分析之后,他们将确定要出售或购买的股票以及数量。
此时订单被插入账簿。
市场将匹配订单。它将寻找与期望价格和数量相匹配的购买(如果订单是卖出)或卖出(如果订单是买入)订单,从最早发布的订单开始。价格和数量不需要相同;代理可能以比最初期望的更低的价格购买较少的股票,然后从另一个代理那里购买剩余部分。当所有可能被满足的订单都完成时,这一天结束。然后代理将学习,这意味着根据他们是否比以前更好以及如果他们做出其他判断可能会怎样来升级他们的决策启发式。然后他们将模仿与他们关联的财富比他们更富有的代理,适当调整他们的启发式。每两周,股票的基本价值将以适度比例变化。这是为了模拟基础公司资产的实际变化。平均股价和其他代理的基本属性将被保留。在此时,循环可能会恢复!
一个流程图显示了过程;真实视野映射、趋势视野映射、总价格映射、买卖价值、订单创建、学习和模仿。
6.3.2 代理与股票特征
代理根据三个主要决策参数行事;贪婪度、真实视野和趋势视野。此外,它们拥有一定数量的资源和总净值。关于这 5 个特征的更多细节在表 6.1 中。表 6.1
代理属性
资源 | 代理的流动性,其处置的资金。最初以帕累托分布,α = 1.16,分布在人群中。 |
|---|---|
净值 | 总财富,资源和当前拥有的股票价值乘以其价值的总和 |
贪婪度 | 进入市场的意愿。值介于 0 和 1 之间,0 表示对市场极度恐惧,而 1 表示对市场极度恐慌。在人群中以正态分布N ~ (50, 20)分布 |
真实视野 | 对股票基本面分析的能力。值介于 0 和 1 之间,0 表示完全无法根据其基本面定价股票,而 1 表示完美地执行此操作。最初以正态分布N ~ (50, 20)分布在人群中 |
趋势洞察 | 代理对股票趋势分析的重视程度。值介于 0 和 1 之间,0 表示对趋势完全不关心,而 1 则相反。最初以正态分布N ~ (50, 20)分布在人群中 |
在模拟开始时,每个代理都会初始化,根据特征的不同分布为其分配随机值。
这 5 个特征,尤其是 3 个决策性特征,被每个代理用来决定买卖哪些股票以及价格。
市场上存在的股票有 3 种,它们因其初始价格和其 2 种基本属性(“真实价值”)在时间上变化的程度而异。
这 2 种基本属性在表 6.2 中更好地解释。表 6.2
股票属性
真实价值 | 从完美的价格分析中获得的价格值,可以看作是股票的真实价值,由任何人都不完全了解。它每 25 个 ticks 变化一次,增长或减少值在 0.5% 到 6% 之间 |
|---|---|
趋势价值 | 它简单地由过去 5 个价格的加权平均值给出其中 n 是 tick 值 |
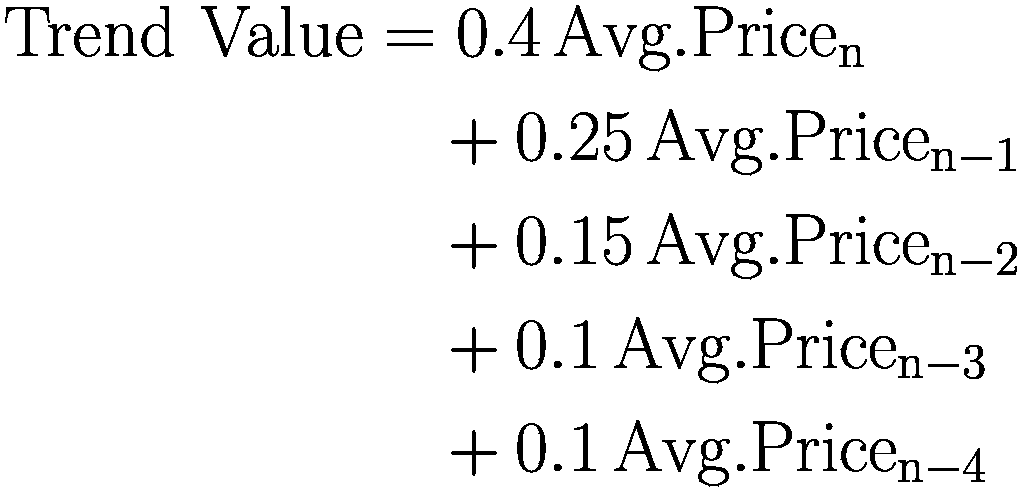
6.3.3 映射过程
在每次模拟迭代中,每个代理订单的特征由代理的三个决策参数和股票的两个特性确定。在实践中,一个代理将建立一个价格,就好像它只是作为一个基本分析者行为,因此仅使用其“真视力”,一个价格,就好像它只是作为一个图表分析者行为,因此仅使用其“趋势视力”,然后一个总价基于它们的趋势视力和真视力值加权的价格。然后,代理将根据自己的“贪婪度”确定是否买入或卖出,当贪婪度较低时卖出(市场恐惧),当贪婪度较高时买入(FOMO)。
经过这个过程,代理将创建一个订单,希望订单能够匹配,如果不能,它将保留在账本上另外的 4 个迭代中,之后将被删除。
6.3.4 学习
每个代理在每个时间间隔结束时将调整其三个决策参数(Truesight、Trendsight 和 Greediness)。它这样做是通过确定其先前的活动是否导致净值增加来完成的,如果是这样,代理将很可能保持参数不变,以较低的概率重复上次做出的选择(因此如果他看到其净值激增,并且在上一次迭代中他决定增加(减少)其 Greediness,它将再次增加(减少)它,并且以非常小的概率它会做与上一次迭代相反的事情。
用数学术语表示:
让
P:代理的收益,即自上次学习以来其净值增加了多少。
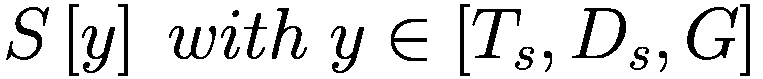
:代理在此时选择的参数 y 的策略。
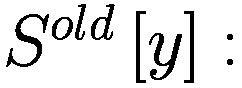
:上一轮代理程序学习的策略。如果
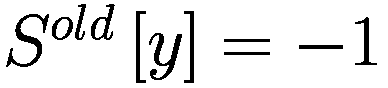
,表示代理程序减少了其 y-决策参数,如果
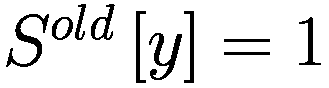
,表示增加了其 y-决策参数,如果
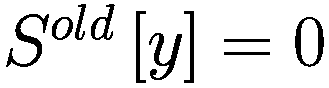
,则不做任何操作。
:在给定先前策略
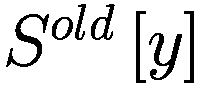
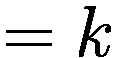
和 P > 0 的情况下,在
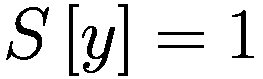
、
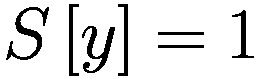
或
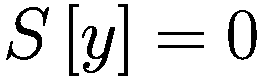
之间选择新策略的概率。
:在给定先前策略
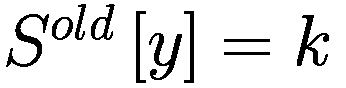
和 P
0 的情况下,在
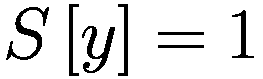
、
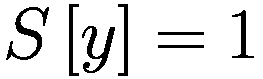
或
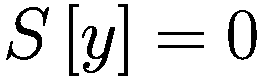
之间选择新策略的概率。

:基于概率
输出
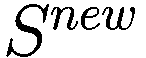
的函数。
如果

那么
对于 y 在
循环执行
如果
那么

否则如果
那么
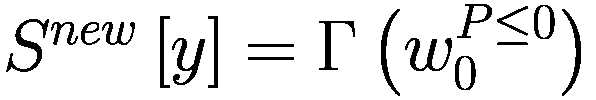
else if
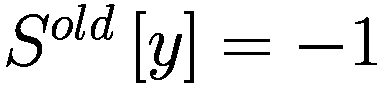
then
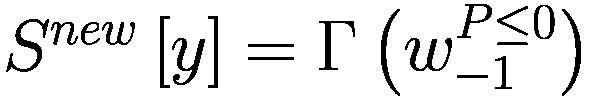
end if
else if
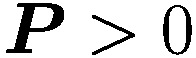
then
for y in
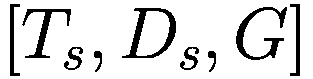
do.
if
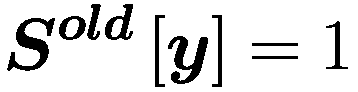
then
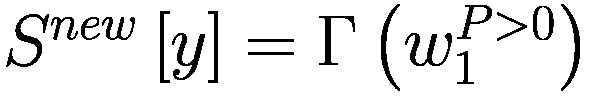
else if
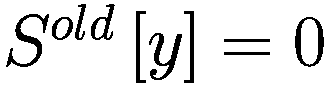
then
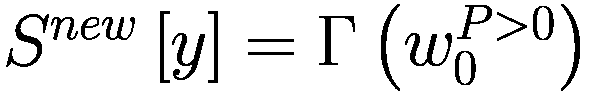
else if
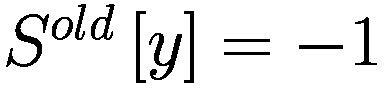
then
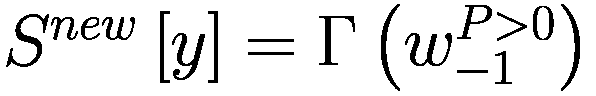
end if
end if
6.3.5 模仿
模仿过程相对简单:代理以巴拉巴西-艾伯特图连接,其中财富较大的节点也是度较高的节点。每个时刻,代理将检查其一度邻居并调整其参数以类似于其较富裕的邻居。
Let:
: i-代理

: i-代理的邻居集合

: j-邻居代理的 i-代理
: 元素的净值 × (一个代理或一个邻居)
G(x): 元素的贪婪程度 × (一个代理或一个邻居)
T(x): 元素的真实视野 × (一个代理或一个邻居)
D(x): 元素的趋势视野 × (一个代理或一个邻居)
deg(x): 节点关联的元素的度 × (一个代理或一个邻居)在网络中
V: 模型中的代理数量
for
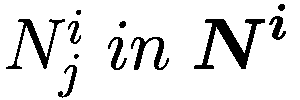
do
if
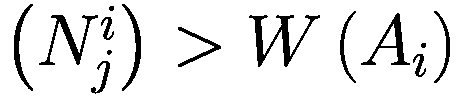
then
if
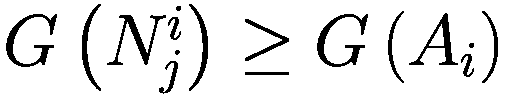
then
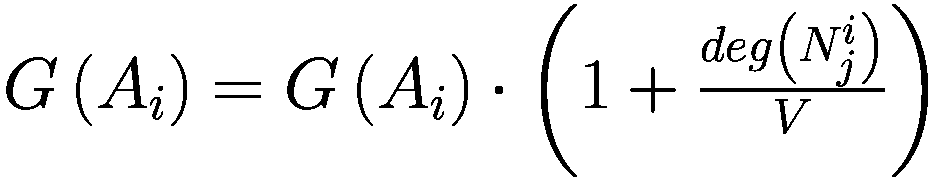
else

end if
if

then
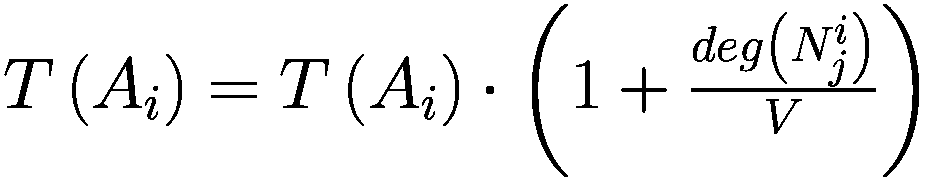
else
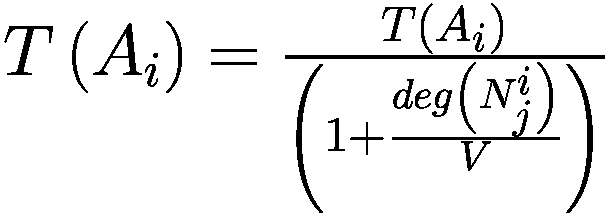
end if
if
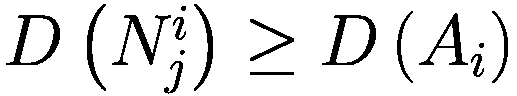
then
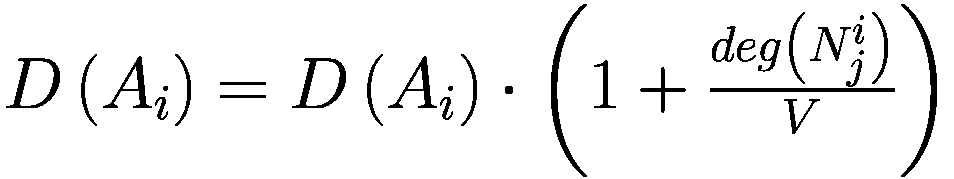
else
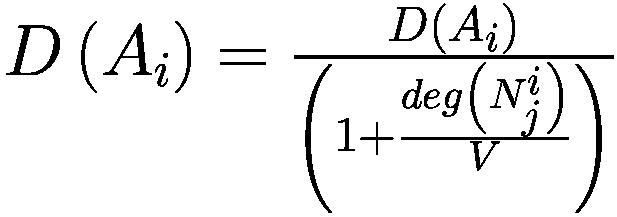
end if
end if
6.3.6 结果和评论
当观察决策参数的平均值(真视力和趋势视力)时,我们注意到在某些时刻,人口更倾向于遵循一种定价策略,其中股票的基本价值(真实价值)在决策过程中的权重大于趋势(趋势价值),反之亦然。这相当于说,在采用的策略方面不存在收敛。然而,当我们抑制模仿或学习机制中的任何一个时,这种现象完全消失。这使我们认为,要获得非平凡的模型,我们需要同时使用这两种机制,以观察投资者类型的出现。
从对行为参数时间序列进行 K 均值聚类分析中得到的其他有趣结果。我们发现随着时间的推移,存在 3 个主要不同的行为集群,这是整个模拟的目标,找到动态投资者类型。转化为现实世界,这就像是确定在其中参与交互(模仿机制)并根据以前的表现改变其策略的市场变化中类似反应的投资者群体。
6.4 结论
ABM 是一种强大而创新的工具,其理想用途是解决难以通过自上而下方法解决的问题。将金融市场视为复杂系统使其成为 ABM 显而易见的应用领域。然而,与 ML 不同,后者已经展示了令人期待的实际应用,目前 ABM 似乎主要在学术界提供其大部分成果,尤其是用于描述市场中发生的社会现象。这使我们认为我们对这种建模技术仍处于早期阶段,因此还有很大的改进和创新空间。我们的模型也是如此。一个对投资者动态聚类和模拟与学习在金融市场建模中作用的早期研究。
总之,我们可以说,虽然 ABM 仍在等待摆脱学术界,但其用处不可否认,金融世界只会从中受益。
第七章:ML 应用于金融市场
Riccardo Vasellini^(1 )(1)Universitá di Siena, Siena, ItalyRiccardo VaselliniEmail: r.vasellini@student.unisi.it
摘要
全球正在被数据淹没,并且新数据收集的速度呈指数级增长。这在仅仅二十年前还不是这样的情况,即使存在于机器学习使用的技术限制,缺乏用于喂养算法的数据也构成了额外的障碍。此外,如果获取精确和有意义的数据导致成本过高,那么获取与我们需要分析的金融现象不直接相关的数据可能更具成本效益,即所谓的替代数据集。替代数据的最终目的是为交易员提供信息优势,以寻找产生阿尔法或与其他任何事情无关的良好投资回报的交易信号。一种策略可能仅基于搜索引擎中免费提供的数据,然后 ML 系统可以将其与某些金融事件相关联。
关键词 AI 机器学习 Riccardo Vasellini
拥有土木、环境和管理工程背景的博士研究生。我目前在意大利锡耶纳大学信息科学系就读,专攻复杂系统。在科学界,我的目标是利用基于代理的建模和人工智能来获得对复杂系统的重要见解。我认为研究新兴现象和系统动态对做出明智的决策至关重要。在攻读博士学位期间,我在多个行业担任项目经理,包括房地产开发、房地产投资组合管理、可再生能源和旅游业。
7.1 引言
过去的十年见证了数据存储和收集在许多行业中的显着增加,包括金融领域。这使得金融机构、投资者、保险公司以及任何对股票、衍生品和利率变动感兴趣的人都能够利用以前缺乏计算能力和数据的机器学习技术。
AI 和 ML 可以应用于各种金融领域,包括投资组合战略制定、欺诈和非法活动检测、风险评估和管理、法律合规、算法交易等。
在本章中,我们将介绍文献中找到的应用示例,金融中的建模技术和 ML 范例。我们将总结使用这些技术的限制和危险,以及未来的展望。
7.2 基础知识
机器学习可以分为三个主要领域:监督学习、无监督学习和强化学习。
监督学习可能是机器学习中最简单的形式,线性回归是其中的一个算法示例,早在“人工智能”或“机器学习”这些术语出现之前就已经被使用了几十年。除了线性回归,监督学习还包括其他算法,例如逻辑回归、决策树、K-最近邻算法、支持向量机、神经网络等。其主要特点是使用包含数据点特征的标签数据集。整个目的是找到一个能够在对算法进行训练后将数据点特征映射到它们相应标签的函数。这种范式假设我们对正在寻找的答案有所了解。一旦训练并测试了算法找到的映射,就可以将其应用于未标记的数据。这可以用于分类或回归问题。
无监督学习涉及在数据中识别模式。通常需要搜索簇或相似发现的分组。在实践中,机器学习算法将相似的事物聚集在一起,其中相似性通常以与簇中心的距离表达。一个好的算法对数据的规模是不可知的,因此通常会采用特征缩放技术,如 z-分数归一化或最小-最大方法。最常用的聚类技术是 k 均值聚类,但也使用其他技术,如基于分布、基于密度或层次聚类。
强化学习围绕着多步决策制定展开。一个代理根据其对所处环境中收益和成本的估计而采取行动,该环境由一系列状态描述,通常为马尔可夫决策过程。奖励(减去成本)是使用 Q 函数计算的,如果某个行动导致具有最高 Q 值的状态,则该行动是最佳的。一个重要的概念是探索,一个“智能代理”总是有可能执行随机动作,这样做是为了不陷入仅利用提供奖励而不探索可能导致更好结果的不同状态。代理不需要标记数据。
推动机器学习应用的不仅仅是对这些新技术的获取。世界正被数据淹没,新数据的获取速度呈指数增长。这在仅仅二十年前还不是这样,即使机器学习的应用存在技术限制,缺乏用于训练算法的数据也构成了一道额外的障碍。此外,当收集准确和有价值的数据成本过高时,获得与我们需要分析的金融现象没有直接联系的数据可能更具成本效益,即所谓的替代性数据集。替代性数据的最终目标是为交易者提供信息优势,以寻找产生阿尔法或与其他任何因素无关的正收益的交易信号(Jensen 2018)。一个策略可能完全基于来自搜索引擎的免费可用数据,这些数据可能通过机器学习算法与某些金融现象相关联。例如,想象一下对冲基金 Cumulus,它只使用天气数据来交易农业公司。
最后,通过结合机器学习算法、当代计算能力和大量数据,我们可以构建出金融领域的强大应用程序,现在我们将进行探讨。
7.3 应用领域
7.3.1 投资组合管理
自从 Markowitz 在 1952 年提出以来,均值-方差优化(MVO)一直是构建投资组合的主要范式。MVO 的成功与二次规划(QP)的成功紧密相连,这使得解决 MVO 变得简单(Jensen 2018)。提出的一种替代方法是风险预算方法,简单来说,投资组合为每种资产类型分配风险预算,我们试图根据这些预算分配资产风险。这种方法在 PO 的各个领域中占主导地位。不幸的是,它通常涉及处理非线性,使得难以解决。然而,就像机器学习在最近几年发展一样,PO 也在发展,虽然 QP 被选择为其简单的计算方法,但如今使用了一整套更消耗计算资源的新算法。其中包括为大规模机器学习问题开发的算法:坐标下降、交替方向乘子法、近端梯度和 Dykstra 算法。使用这些算法可以超越 QP 范式,并深入研究一整套不受线性限制的模型。PO 的未来是利用这些机器学习算法开发新的 PO 模型,或者简单地使用已经开发的模型,这些模型现在在计算上比过去更容易接近。
作为这种方法的一个示例,Ban,El Karoui 和 Lim(Perrin 2019)在 2018 年提出了一种基于绩效的正则化(PBR)和基于绩效的交叉验证模型,以解决投资组合优化问题,以超越应用经典方法到真实数据时产生的估计问题。正则化是几十年来解决围绕线性问题的问题的一种技术,但实际上,问题的常数的微小变化会导致解的巨大偏差。在实践中,它是一种约束或减少估计系数为零的回归。因此,它通过阻止学习更复杂的模型来防止过拟合的风险。在实践中,它减少了模型的方差,而不会增加太多其偏差。
作者们对投资组合优化问题进行正则化,目的是改善解的样本外表现。为了实现这一点,他们限制了投资组合风险和平均值的样本方差。目标是创建一个模型,能够找到一个解决投资组合问题的解(无论是传统问题还是 CVaR 问题),其偏差非常低,而且在样本外表现良好。
在另一篇论文中(Jensen 2018),Perrin 和 Roncalli 确定了可以被视为投资组合优化中最重要的四种算法:坐标下降法,交替方向乘子法,近端梯度法和迪杰斯特拉算法。作者们评估了 MVO 范式的成功在于缺乏竞争的可实施模型。确定的原因包括难以估计参数和复杂的目标函数,使用提到的四种算法的组合可以构建一个能够考虑 QP 形式之外的分配模型的框架。
最后,Ban 等人(Ban et al. 2018)提出了一种创新的方法。作者们试图解决投资组合管理中的数据异质性和环境不确定性问题。他们使用强化学习来做到这一点。具体来说,为了包含异构数据并提高对环境不确定性的韧性,他们的模型(增强状态强化学习,SARL)使用价格变动预测来增强资产信息,这些预测可能仅基于金融数据或来自新闻等非传统来源。通过对比特币价格和高科技股票市场的历史数据进行测试,他们验证了这种方法,展示了总体和风险调整利润的模拟结果。
一般来说,机器学习与计算能力的进步使得科学家和专业人员能够测试不受数量限制的模型,一度不切实际的解决方案正变得可以实现。
7.3.2 风险管理
风险管理(RM)由于机器学习算法的使用,对处理大量变量和数据的新旧模型的采用增加了,并且现在这些算法能够在可接受的时间内找到答案。
风险贯穿金融世界及其他领域。我们将探讨机器学习如何用于其最常见的一些形式。
在处理信用风险时,了解债务人偿还债务的概率对金融机构(或一般的出借人)来说是至关重要的知识。这在处理中小企业或零售投资者时尤其困难,因为可用数据稀缺且有时不准确。文献中可以找到的各种模型的一般思想是,使用机器学习可以在不传统地与预测信用风险相关联的数据中找到这些小额借款人行为的模式(Ban 等人,2018)。
另一个机器学习蓬勃发展的领域是评估复杂衍生品的信用风险,例如信用违约互换(CDS)。对于这些对象,深度学习方法显示出比传统方法更好的结果,在研究中,Son、Byun 和 Lee 模型(Ye 等人,2020)显示他们所使用的参数模型在预测性能方面一直比基准模型更好,并且在所有使用的模型中,人工神经网络(ANN)显示出最佳结果。
目前,机器学习在市场交易风险管理中的主要用途是通过在大量数据上进行回溯测试来验证提出的模型。另一个关键应用是了解交易将如何影响不流动的市场,从而改变所交易资产的价格。通过使用机器学习算法来识别类似资产,可以避免单一资产的高交易量带来的困难。
在此框架内的一个有趣的应用来自 Chandrinos、Sakkas 和 Lagaros(Lynn 等人,2019)。这些研究开发了一个工具,将机器学习作为投资风险管理工具。具体而言,该调查集中于通过使用人工神经网络(ANN)和决策树(DT)将交易策略生成的信号分类为成功和不赚钱的信号。为此,他们使用了两个先前提出的货币组合,并利用他们的人工智能风险管理系统(AIRMS)通过减少损失而不是增加收益来提高其性能。在他们的回测中,不仅所采用的两种方法(DT 和 ANN)提高了投资组合的盈利能力,而且还通过减少标准偏差显着改善了它们的夏普比率。
另一个应用是由 Sirignano、Sadhwani 和 Giesecke 提出的(Son 和 Lee 2016)。他们使用深度学习模型分析了美国在 1995 年至 2014 年间发放的超过 1.2 亿笔抵押贷款数据。试图理解某些借款人行为的概率以及产生不良贷款风险,他们查看了各种变量,包括金融和宏观经济因素。他们得出的结论是,预测抵押贷款成功的最重要因素之一是抵押贷款发放地区的失业率,突显了住房金融市场与宏观经济之间的联系。
7.3.3 房地产科技
房地产科技是房地产行业内新兴技术的广泛应用。这些技术包括房屋匹配工具、无人机、虚拟现实、建筑信息模型(BIM)、数据分析工具、人工智能(AI)、物联网(IoT)和区块链、智能合同、房地产行业的众筹、与房地产相关的金融技术(fintech)、智能城市和地区、智能家居以及共享经济(Spyros 等人 2018) 。房地产行业与金融市场密切相关,特别是在涉及到上市的房地产投资信托基金(REIT)方面,在美国,这些基金的市值已经超过 1 万亿美元(Sirignano 等人 2018)。
在这种情况下,准确预测房价具有明显的相关性。不幸的是,要做到这一点准确性需要对当地市场和周围环境有深入的了解,这种类型的知识对于运营大量房产或每天定价数百份抵押品的大型房地产投资信托基金或信贷机构是难以获取的。
Siniak 等人提出了一个解决方案(2020)。作者认为,通常使用的指数很少准确地描绘了房地产市场的细粒度情况。事实上,他们试图利用超过 16 年的房屋销售数据,得出对单一房屋的定价预测准确性。
所提出的方法称为梯度增强房价指数,它使用了梯度增强回归树算法的机器学习技术,该算法构建了多个决策树并递归拟合模型。实际上,他们颠倒了多个决策树构建过程,这将导致过度拟合的分类树(每个房屋一个叶子节点),构建一个低复杂度的决策树(弱学习器),然后在发生糟糕预测时构建其他低复杂度的树。最终获得的树被称为强学习器,并且可以被看作是弱学习器的加权平均值。作者认为,这种方法能够以比现有的经典指数更好的方式预测房价,对金融机构和房地产基金将会非常有用。
7.3.4 资产回报预测
预测资产的确切正确价格是金融界的圣杯。能够做到这一点将会带来财富和财富,因此问如何用尽可能小的误差来做到这一点肯定是一个非平凡的问题。事实上,金融科学最重要的结果之一,布莱克-斯科尔斯模型,就是用于这个原因:定价一种资产,具体地说,是一个期权(卡波林等人 2021)。
资产价格遵循高度非线性的行为,受到反馈回路的影响,有时会出现繁荣和萧条周期(巴尔等人 2016),应对这些特征的强大工具当然是深度学习。预测资产价格的问题等同于预测时间序列的行为,在经济学和金融学中,这通常是使用动态因子模型(DFM)完成的。DFM 可以被视为多个时间序列的联动模型。
深度学习可用于整合这些模型。例如,我们可以看一下冯、何和波尔森(布莱克和斯科尔斯 1973)。为了预测资产回报,作者开发了使用深度学习训练的动态因子模型。使用随机梯度下降,同时计算隐藏成分和回归系数,从而提高了与传统模型相比的样本外性能。
7.3.5 算法交易
算法交易通过计算机的自动化,执行执行某种交易策略所需的全部或部分步骤。它可以被视为量化交易的基本部分,并且根据华尔街的数据,算法交易占美国股票交易总量的约 60-73%。(冯等人 1804)。
量化交易的发展可以总结为三个主要阶段:
在第一个时代(80 年代至 90 年代),量化公司会使用从学术研究中得出的信号,通常使用来自市场或基本数据的单个或极少量的输入。策略通常相当简单,困难在于迅速获取正确的数据。
在第二阶段(2000 年代),为了探索套利机会,基金采用算法来识别受到价值或动量等风险变量影响的资产。在这个阶段,主要采用基于因子的投资,这是导致 2007 年 8 月量化领域动荡的因子行业。
最后一个阶段就是我们正在经历的阶段,基金正在利用机器学习和替代数据进行投资,以开发有效的交易信号用于循环交易方法。在这个极其竞争的环境中,一旦发现有价值的异常情况,它就会迅速消失,因为竞争激烈。(情报 2022)。
使用机器学习进行交易的主要目标是预测资产基本面、价格走势或市场情况。 一种策略可能使用多种机器学习(ML)算法来实现这一点。 通过结合有关个别资产前景、资本市场预期以及证券之间关系的预测,下游模型可以提供组合级别的信号。
许多交易算法使用市场上的技术指标来调整投资组合构成,增加其预期收益或减少其风险。
作为应用示例,我们可以看一下雷、彭和沈利用深度学习改进了技术分析中常用的指标——移动平均收敛/发散(MACD)(雷等人 2020)。 作者首先指出,传统的 MACD 技术无法理解趋势变化的幅度,这可能会导致算法在实际上没有大的趋势变化但只是波动时发出交易信号。 这将导致由于交易成本而造成不必要的损失。 因此,通过残差网络,可以估计代表所交易股票的时间序列的某些特征,特别是作者关注的 MACD 指标将发出交易信号的时间序列的局部峰度。 如果残差网络估计的峰度高于 0(意味着曲线的陡度高于正态分布),则算法将相信所指示的交易点并执行交易,否则将忽略它并保持持仓。
在 CSI300 股票指数上进行测试,所提出的算法优于仅使用 MACD 的经典算法,显示了通过 ML 可以改进现有的算法交易策略。
7.4 风险与挑战
尽管提供了许多优势,但在金融领域使用 ML 也无法免受其常见缺陷的影响。
在所有领域中,包括金融领域,机器学习模型的复杂性是导致其风险性的主要因素。 机器学习的算法基本上相当困难,因为它们操作的是大规模且有时结构不清的数据,例如文本、照片和声音。 因此,对这些算法的训练需要复杂的计算基础设施,以及模型构建者方面的高度专业知识和理解(Sen 等人 2021)。 此外,复杂性可能会使算法难以被最终用户实施,这可能是因为计算基础设施不适合在任务规定的时间限制内提供答案。
大多数机器学习模型都是黑盒子,这意味着用户可能知道问题的答案是什么,但不知道它是如何找到的。这可能导致几个问题和法律纠纷。例如,考虑一个依赖机器学习来评估合同保费的保险公司。如果无法解释保险公司是如何估算价值的,客户可能会犹豫是否与承保人签订合同。同样,如果银行拒绝客户访问信用而不提供原因,银行可能会面临后果。虽然许多应用程序(比如向客户推荐产品)不需要模型可解释性,但许多其他应用程序需要,而无法做到这一点可能会阻碍机器学习在金融界的应用进展。
另一个挑战是偏见。数据收集的方式可能会影响所使用的机器学习算法提供的答案。现成的数据本质上偏向于复制现有做法。想象一下来自信用机构的数据,客户根据他们接受(或未接受)的贷款类型进行分类。使用机器学习,我们可能只是不断地复制过去使用的相同决策过程,而没有创新任何东西,实际上是在重新发明轮子。偏见可能出现在性别或种族方面,造成道德问题,并使用户面临歧视诉讼。为了避免这种偏见,进行准确的数据清洗、特征选择和提取至关重要。
来自对抗性机器学习的进一步风险,是向机器学习算法提供错误数据以欺骗其朝向某些结果的做法。著名的案例是纳文德·萨拉奥(Wang 2015),一个年轻的英国人通过创建大量订单然后取消它们(一种称为操纵的做法)而触发了 2010 年闪电市场崩盘,从而诱使算法交易机器人修改其策略并人为修改市场。对抗性机器学习的最佳解决方案是人工监控,然而,当算法是黑盒子时,这变得具有挑战性,并且需要更多的可解释性才能成功。
最后,另一个主要关注点无疑是如何不违反数据隐私,特别是涉及敏感的财务信息时。许多政府正在采取措施解决处理个人数据带来的问题,最值得注意的行动无疑是于 2018 年 5 月生效的欧盟 GDPR。
7.5 结论
如今,机器学习以某种方式渗透到每个行业。金融作为一个行业和一个研究领域,一直倾向于计算方法,使用机器学习只能被视为这种态度的自然发展。
我们探讨了各种应用,特别是大部分似乎都围绕着投资组合管理和优化展开。实际上,即使我们在谈论风险管理,我们也可能正在谈论投资组合优化的一个子领域,而算法交易可以被视为投资组合管理规则和模型的自动实施。
其他重要领域包括资产定价和客户分类。关键似乎不仅是所使用模型的类型,而且还包括所获取数据的清洁度。使用正确的数据对于避免偏见并获得创新性见解至关重要。然而,这是一个微妙的过程,因为在处理金融数据时很容易侵犯个人隐私。
主要关注点来自于复杂模型的脆弱性,这些模型通常对于不了解所使用模型的用户来说是黑匣子,这些用户可能容易受到剥削,其中一个例子就是“欺骗”的实践。
总之,机器学习正在为金融世界带来一场巨大的创新浪潮,而且正如所有重大产业变革一样,监管和规范是避免投机和剥削的关键。
第八章:用于定价困境资产 UTP 和 NPL 贷款组合的人工智能工具
Alessandro Barazzetti^(1 ) 和 Rosanna Pilla^(2 )(1)QBT Sagl,Via E. Bossi 4,6830 Chiasso,瑞士(2)Reacorp Sagl,Via E. Bossi 4,6830 Chiasso,瑞士 Alessandro Barazzetti(通讯作者)Email: alessandro.barazzetti@qbt.chRosanna PillaEmail: rosanna.pilla@reacorp.ch
摘要
非 performing 曝光是一种资产金融类别,通过转让操作在自由市场上交易大量来自银行的贷款。因此,信用增强问题在信贷购买过程中变得至关重要。在这项研究中,我们描述了一种基于人工智能算法和计算方法而非传统计量经济学的非 performing 曝光价值评估方法。以下方法已针对意大利非 performing 曝光市场进行了研究,因为在规模、法律和技术房地产方面具有独特特征。
关键词非 performing 曝光贷款评估人工智能金融科技商业计划群集树分析专家系统现金流 Alessandro Barazzetti
米兰理工大学航空工程师,卢德斯离校医科大学教授和飞行员,是 QBT Sagl 公司的所有者,该公司在金融科技和房地产科技领域开发算法和软件,并且是 Science Adventure Sagl 公司的所有者,该公司专门从事应用于健康与护理和航空航天领域的人工智能解决方案和先进项目。 Alessandro 还是 SST srl 公司的创始人,该公司致力于可持续性研究和认证,以及 Reacorp Sagl 公司,该公司致力于金融科技和房地产科技服务。
Rosanna Pilla
是一位律师;她选择巩固自己在银行和金融法律、信贷重组、执行和回收程序方面的技能。精通动态管理和增强房地产担保品、尽职调查和证券化、信用转让、担保和非担保信用组合的业务计划的准备和实施、非 performing 贷款和 UTP 信用。一个年轻专业人士组成的团队的团队领导,该团队已经进行了各种尽职调查活动,包括销售 NPLS 信用组合和 FIA 基金的设立。她有兴趣关注新技术用于数据分析和增强的发展和应用。Rosanna 是意大利执行协会(TSEI Association)—意大利执行研究组的成员,也是 Reacorp Sagl 公司的创始人,这是一家致力于金融科技和房地产科技服务的瑞士公司。
8.1 非 performing 贷款
不良贷款(欧盟法规 2013)是指银行业信贷头寸,债务人已无法履行支付。债务人陷入破产状态,信贷被归类为不良,成为不良信贷风险或 NPE。根据债务人上次向授信机构支付的月数,确定了三种不同类型的 NPE。
每种类型都对应着明确的会计履约和利息及费用计算,直至通过法院拍卖机制进行强制回收信贷的司法程序。
不良信贷风险的类型按照上次支付时间的顺序确定如下:
-
透支和/或逾期信贷风险
-
不良信贷风险(UTP)
-
不良贷款(坏账)。
NPE 头寸的分类是由欧盟通过欧洲银行业监管局(EBA)发布的一项法规(《欧洲中央银行》2017)根据欧洲法规(EBA/GL2016)进行的。
不良信贷风险的位置也根据与信贷相关的担保类型进行区分:因此,我们有具有抵押担保的贷款的不良贷款(担保贷款)和没有抵押担保的贷款(无担保)。
担保头寸,抵押担保由债务人的房地产资产组成:因此,这些是通过法院通过财产拍卖程序便于回收的不良贷款。
另一方面,无担保贷款是根据发放的信贷类型来区分的:我们有金融、商业和银行性质的信贷。
另一个重要区别在于债务人类型。信贷可以发放给个人或法人实体。债务人类型在回收法律行动中尤其具有影响:对于法人实体,欠款的司法回收通过破产执行程序(即破产)进行,而对于自然人则是个人执行(即查封)。
此外,法人实体的信贷金额通常高于自然人。
本研究将重点关注意大利 NPE 信贷市场,因为这是一个庞大的市场,同时也与法律信贷回收活动的复杂性以及用作信贷抵押品的房产的特殊性相关。
8.2 不良贷款市场规模
作为不良信贷风险分类的银行信贷头寸市场在整体量和信贷头寸数量方面都具有相当规模。
截至 2021 年底,意大利的不良贷款存量为 3300 亿欧元,其中不良贷款头寸 2500 亿欧元,被归类为 UTP 的头寸 800 亿欧元(《市场观察》2021)。
预计考虑到当前经济危机,在 2023 年至 2026 年的三年期间将出现强烈的影响,这主要由于高通胀率影响了该国的实体经济。
先前指出的数字中,75%是公司贷款,70%是有房地产担保(有担保)的贷款。
2021 年的 NPE 交易额约为 360 亿欧元,NPLS 为 340 亿欧元,UTP 为 20 亿欧元,分别占 80%的公司贷款和 50%的房地产抵押贷款(图 8.1)。
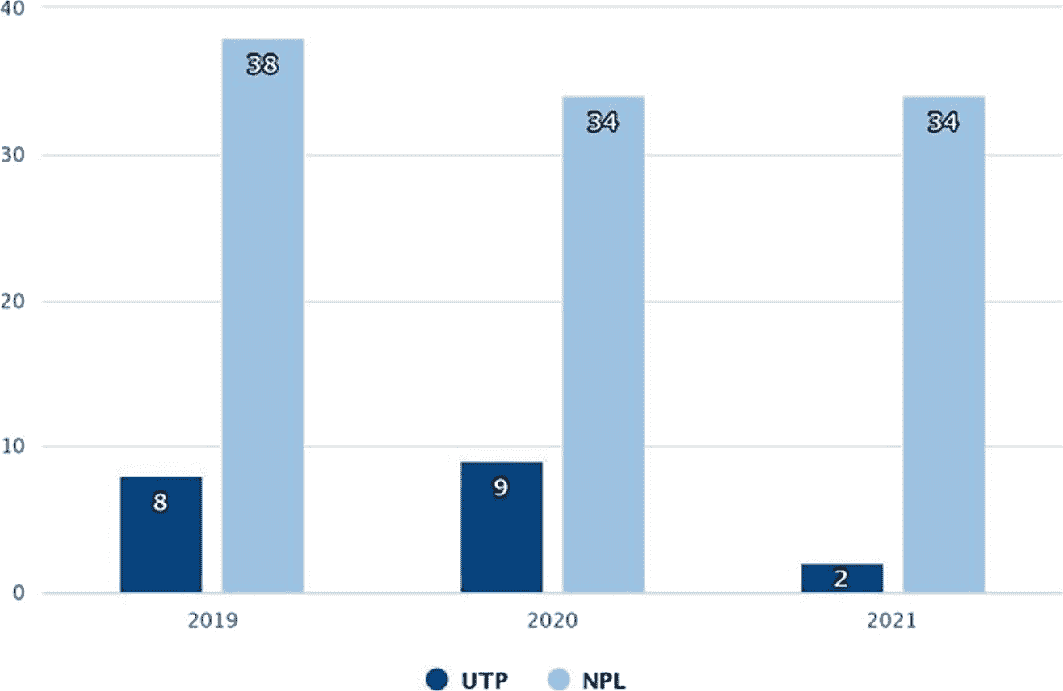
2019 年至 2021 年间以十亿欧元计的 UTP 和 NPL 销售的分组条形图。所有 3 年的 UTP 数据分别为 8、9 和 2。所有 3 年的 NPL 数据分别为 38、34 和 34。
图 8.1
过去三年间的 NPE 组合销售额,以十亿欧元计
8.3 信贷和信贷组合的估值
不良贷款或 NPE 通过信贷证券化过程(意大利银行 2017)由投资基金通过专用目的车辆(SPV)购买。
信贷的购买通过出让行按照当时双方协商的价格进行,采用无追索权的转让方式进行。
无追索转让的替代方案由贡献基金或 FIA 代表,允许转让信贷的银行机构将 NPE 职位转移到封闭基金中。作为交换,出让方按转移的不良贷款金额比例获得基金单位。AIFs 的性质不是投机的。
在这两种情况下,银行可以将单个职位或单个名称分配或贡献给 AIFs,也可以将整个贷款组合分配给 AIFs,这些贷款组合也汇集了大量的债务人。
信贷或投机性贡献值的购买价格由估计信贷回收预测确定,这被称为转让交易的商业计划。
让买方确定回收预测并因此起草商业计划的活动称为信贷尽职调查,包括分析单个 NPE 职位。
买方收集的信息集合由卖方提供,并由计量经济模型用于制定回收预测或商业计划。
通常,买方依赖于专门从事技术法律咨询的公司进行尽职信贷尽职调查:这些公司拥有法律、财务和房地产分析方面的专家人员。
另一方面,在 AIFs 的情况下,贡献机构依靠独立信贷专家的形象。
应收账款的购买价格或贡献价值,无论是单一名称还是整个应收账款组合,都是通过贴现包含在业务计划中的现金流量来确定的,该业务计划代表了信贷回收的预测,根据预期收益率或 IRR。
收益率代表投资者对销售交易的期望。
预期收益率或市场 IRR 根据信贷类型而异,但我们可以指出,对于担保信贷组合,高度投机的投资者方法的基准范围为 11%至 15%。
特别重要的是对 FIA(金融投资者协会)投资运营的收益率定义,我们提醒您,这不具有投机目的。
对于这种类型的交易,预期收益率设定为~3%:该率是根据与 Euribor 的十年平均值和主要银行操作者储蓄存款利率的平均值相关的一系列客观市场参数确定的。
确定信贷或信贷组合购买价格的计量方法基本上是统计方法,基于对债务人描述性属性和信贷性质与收集历史趋势之间相关性的分析。
或者,我们实施了一种基于 AI 方法确定 UTP 信贷回收预测的方法。
8.4 不良授信 UTP 信用的 AI 估值方法描述
在本章中,我们描述了一种基于 AI 方法的信贷价值化方法,该方法基于专家系统的构建(Bazzocchi 1988)。
专家系统是指能够复制一个或多个专家行为的程序(Iacono 1991)。
专家系统的创始原则是编写“规则”,这构成了程序知识的基础:这些规则是通过与该领域专家的访谈建立的,借助数据的统计分析来推断通过决策树(1)或使用机器学习解决方案(Woolery 和 Grzymala-Busse 1994)所识别的规律性。
我们的研究重点放在了向个人和法人发放的 UTP 担保和非担保信贷上。
UTP(不良授信未转逾期贷款)信用是指尚未变为不良的贷款:对于这种类型的贷款,债务人已停止偿还债务,但银行尚未将其归类为实际破产。UTP 状况在法律上具有有限的持续时间,并具有两个潜在的退出条件:该职位变为真正的不良贷款或 NPL,或者通过特定的回收策略,它恢复为正常状态。
这两种退出条件确定了信贷回收预测和相关的回收时间框架。
我们用于确定 UTP 信贷估值的程序或算法包括以下流程图,我们将对其进行详细分析:
UTP 职位最初区分为自然人和法人。
如果位置是自然人,则使用的信息是商业性质的。
如果位置是法人,除了法律信息外,还涉及公司的资产负债表数据和行业分析。
这是模型中使用的信息,代表程序的输入(见表 8.1 和 8.2)。表 8.1
用于个人算法的变量列表
输入参数 | 输入类型 | 描述 |
|---|---|---|
GBV | 金额 | A 应付信用 |
他支付了多少 | 金额 | B 已支付的信贷 |
已发放多少 | 金额 | C 已发放信用 |
上次付款时间 | 在您处 | |
物业位置 | 字符串 | |
房地产价值 | 金额 | |
其他担保 | 是 否 | |
担保人 | 是 否 | |
平均安装金额 | 金额 | |
从 UTP 收集 | 是 否 | 转换为 UTP 后的收集 |
工作 | 是 否 | |
薪水 | 金额 | F 薪水金额 |
工作类型 | 下拉菜单 | |
职业 | 下拉菜单 | |
婚姻状况 | 下拉菜单 | |
新娘是否工作 | 是 否 | |
儿子 | 是 否 | |
可用的 | 是 否 | |
特殊 | 是 否 |
表 8.2
用于法人算法的变量列表
输入参数 | 输入类型 | 描述 |
|---|---|---|
GBV | 金额 | A 应付信用 |
他支付了多少 | 金额 | B 已支付的信贷 |
已发放多少 | 金额 | C 已发放信用 |
上次付款时间 | 在您处 | |
物业位置 | 字符串 | |
房地产价值 | 金额 | d |
其他担保 | 是 否 | |
担保人 | 是 否 | |
平均安装金额 | 金额 | AND |
从 UTP 收集 | 是 否 | |
行业 | 下拉菜单 | 公司的商品行业 |
活跃度 | 金额 | 预算项目 |
被动 | 金额 | 预算项目 |
成员 | 是 否 | |
激活 | 是 否 | |
可退还金额 | 是 否 | |
特殊 | 是 否 | |
重新融资分析 | 下拉菜单 | 从 1 到 10 的指数 |
按图 8.2 中的方案,第一次分析包括确定位置是否仍为 UTP 或将变为 NPL。
6 步骤的流程图。1、UTP 借款人分为公司和个人。2、公司分为法人、资产负债表和市场分析。个人流程个人分析。3、所有分析汇总成恢复策略。4、恢复策略分为 NPL 司法和 UTP 表现。5、UTP 分为 7 类别。6、NPL 和 UTP 类别合并为业务计划。
图 8.2
流程图
使用输入参数,通过集群树分析对两个 UTP 信贷组合进行了如下分析(见表 8.3)。表 8.3
用于分析 NPL 与 UTP 职位的投资组合
投资组合 ID | GBV €(〜) | 借款人数量(〜) |
|---|---|---|
投资组合 A | 12,000,000.00 | 30 |
投资组合 B | 55,000,000.00 | 25 |
分析结果使得能够确定每个参数在确定从 UTP 到 NPL 转换概率时的正确权重。
如果职位变为 NPL,则估值变为司法估值,并涉及对应收账款价值的折扣,折扣率为价值的 80%,恢复时间平均为 5.3 年(法院审理时间研究 2022)。
如果职位仍然是 UTP,则需要定义从 UTP 状态向执行或无论如何都要进行庭外和解的最有可能的退出策略。
在这种情况下,为了确定恢复预测,需要计算非司法 UTP 解决方案的最有可能策略,其可分类如下(表 8.4)。表 8.4
个体法人退出 UTP 条件的策略
退出策略 | 描述 |
|---|---|
资产出售 | 协商的资产出售 |
DPO | 即使有后期或渐进式归还计划,也可以自愿处置 |
根据第 67 条的 DPO | 带有 DPO 的恢复计划 |
第 67 条 lf-恢复计划 | 恢复计划 |
第 182 bis 条. 重组 | 法律重组计划 |
第 160 条 lf-法律协议 | 法律协议 |
为了确定表 8.5 中的恢复策略,对于保持 UTP 状态的职位,我们使用了插入信贷恢复预测计算程序中的一组规则。表 8.5
个人退出 UTP 状态的策略
退出策略 | 描述 |
|---|---|
资产出售 | 协商的资产出售 |
DPO | 即使有 DPO 或渐进式归还计划,也可以自愿处置 |
专家系统由具有不同背景的信贷专家组成:我们组建了一个由两名律师、一名精通预算分析的经济学家和一名房地产技术专家组成的团队。
工作组制定了定义各种策略激活条件的规则,与输入变量相关。
特别提及与行业分析相关的参数。所谓的行业是指公司属于通过 ATECO 代码(ATECO 2007)定义的精确产品类别。通过行业研究的分析(ISTAT 2021),专家组为能够产生国内生产总值的行业的每个产品组分配了正分数,而对于在当前宏观经济条件下存在衰退前景的行业则分配了负分数。
同样地,根据对表 8.3 中所列公司财务报表分析的具体规则,定义了与公司可融资性相关的公司融资能力规模。
对法人实体的财务报表进行分析是制定确定最可能的信贷回收策略规则的最重要因素。
因此确定的规则适用于输入的参数,并采取以下形式 (Table 8.6).Table 8.6
规则示例
规则 | 策略 |
|---|---|
若第一抵押(实质性) = 是 并且 D > A | 自愿出售资产 |
若 (第一抵押(实质性) = 否 (或空) 或 无抵押 = 是) 并且 活跃 > 被动 并且 激活 = 是 | 即使有岗位或逐步回归计划,也会自愿处置 |
若活跃 > (被动 + 容差 * 被动) 并且 D > 0 | 自愿出售资产 |
若活跃 > (被动 + 容差 * 被动) | 即使有岗位或逐步回归计划,也会自愿处置 |
若活跃 < = A 并且 活跃 > 被动 | 根据法律 67 lf 执行的复苏计划 |
若被动 > 活跃 并且 (A < 被动 + 容差 * 被动 并且 A > 被动—容差 * 被动) | 第 160 lf 条—法律协议 |
… | … |
然后,每种策略都与基于规则的回收预测相关联 (Table 8.7).Table 8.7
用于法人实体的策略改进
退出策略 | UTP 回收金额 |
|---|---|
资产出售 | 金额 = (min A; D) * % 折扣 1 |
DPO | 金额 = A * % 折扣 2 |
… | … |
通过对表格 8.3 中的信贷组合数据库进行统计分析确定的 DiscountN 百分比已经在多年内产生了收据。
结果在表 8.8 中突出显示。Table 8.8
百分比和个别策略相关的回收值
策略 | 容差 (%) | 折扣百分比 (%) | 回收年限 |
|---|---|---|---|
自愿出售资产 | 10 | 90 | 3 |
即使有岗位或逐步回归计划 | 80 | 5 | |
根据法律 67 lf 执行的复苏计划 | 10 | 80 | 4 |
第 67 lf 条—复苏计划 | 10 | 70 | 3 |
第 182 bis 条.—法律重组计划 | 20 | 50 | 5 |
第 160 lf 条—法律协议 | 30 | 60 | 4 |
因此制定的信贷增值可以生成信贷组合的业务计划,为每个位置分配:
- 将 NPL 过渡到 UTP 或保持在其中的归因
- 如果是 NPL,则策略是司法
- 如果是 UTP,则根据规则确定最可能的回收策略
- 对于所选的策略,根据统计计算的折扣百分比以及年度回收时间,确定回收预测。
结果是一个业务计划,如图 8.3 所示。

一个包含 11 列和 8 行数据的表格。列标题用外文提及,2022 年的 4 个日期分别是 3 月 31 日、6 月 30 日、9 月 30 日和 12 月 31 日。
图 8.3
UTP 信贷组合业务计划示例
文档的每一行代表一个债务头寸,其中提供了信贷价值或 GBV、法律性质、退出条件(作为 NPL 或 UTP)以及与相关的现金流预测和购买价格或折现的贡献值计算有关的回收策略。参考利率。
8.5 模型验证
使用所描述算法的程序对信贷投资组合进行估值处理的结果经过了与专家组的专家手动并行进行的估值测试的验证。这一活动使得价值规则得以巩固。
随后,在已知单个头寸的策略和回收的贷款组合的估值上进行了回测。从 UTP 条件的确定以及从 UTP 条件的退出策略方面来看,可靠度程度证明极高,如表 8.9 所示。表 8.9
与实际情况相比模型的误差
投资组合 ID | GBV € (~) | 借款人数量 (~) | NPL 与 UTP 的错误率 (%) | 策略确定性的错误率 (%) | 回收金额确定性的错误率 (%) |
|---|---|---|---|---|---|
P tf1 | 24,000,000.00 | 1 | 0 | 0 | 15 |
ptf2 | 20,000,000.00 | 20 | 10 | 11 | 9 |
ptf3 | 6,000,000.00 | 2 | 0 | 50 | 20 |
ptf4 | 30,000,000.00 | 40 | 6 | 7 | 6 |
ptf5 | 8,000,000.00 | 20 | 4 | 6 | 5 |
ptf6 | 14,000,000.00 | 15 | 9 | 9 | 8 |
ptf7 | 60,000,000.00 | 25 | 11 | 10 | 9 |
8.6 结论
基于专家系统的信用增强系统的使用具有将信贷回收过程的物理现象解释以透明和可验证方式的优势。规则可以随着时间的推移进行经验测试,以检查其描述的物理现实的遵循程度。此外,随着环境条件的变化,可以随时添加新规则。特别是,对新的监管义务或对宏观经济参数应用的考虑。
在实际信贷组合上应用模型使我们能够测试该方法,并在各种交易中验证其正确性,取得了令人满意的结果。
第九章:不仅仅是数据科学:未来 ICT 2.0
Federico Cecconi^(1 )(1)LABSS-ISTC-CNR, Via Palestro 32, 00185 罗马, 意大利 Federico CecconiEmail: federico.cecconi@istc.cnr.it
摘要
在一部阿西莫夫的小说中,他想象“机器”可以从世界上发生的所有“事实”中获得输入,日复一日,年复一年。根据阿西莫夫的定义,机器是机器人,因此它们不能以任何方式损害人类,而且它们必须服从人类,最终只能保护自己。因此,日复一日,年复一年,它们建议行动方针,修改程序,要求创建结构并修改其他结构。为了促进人类的福祉。未来 ICT 2.0,这是 2019 年欧盟的一项倡议,正是提出了这个想法,即创建决策辅助工具,从世界各地接收数据,并为动态、行动方针、解决方案提出解释。在这一章中,描述了未来 ICT 现在的情况,以及这个梦想内含的难以完全领会的挑战。
关键词预测模型大数据社会认知 Federico Cecconi
是 QBT Sagl(www.qbt.ch)的研发经理,负责计算机网络管理和仿真计算资源的 LABSS(CNR),并担任 Arcipelago Software Srl 的顾问。他为 Labss 的问题(社会动态、声誉、规范动态)开发计算和数学模型。对 Labss 进行传播和培训。他目前的研究兴趣有两个方面:一是使用计算模型和数据库研究社会经济现象。第二个是为金融科技和房地产科技开发人工智能模型。
9.1 什么是数据科学?
从一开始,数据科学旨在通过使用数学和统计学从大量数据中提取知识。有许多不同的技术用于实现这一目标,良好的研究导致更好的结果,从而为金融机构带来利润。数据科学在金融领域变得极为重要,主要用于风险管理和风险分析。公司还使用商业智能软件评估数据模型。
通过使用数据科学,识别异常和欺诈的准确性增加了。这有助于减少风险和诈骗,缓解损失并保护金融机构的形象。数据科学与金融密不可分,因为金融是数据的中心。金融机构是数据分析的早期先驱和采用者。
换句话说,数据科学是一个跨学科领域,利用科学方法、流程、算法和系统从大量结构化和非结构化数据中提取知识和见解。数据科学与数据挖掘、机器学习和大数据相关。简单来说,数据科学是从结构化和非结构化来源获取数据的集合,以提取有价值的见解。数据来源可能包括在线或手动调查、零售客户数据以及社交媒体使用信息和行为。这些数据被用来对网络或客户群体的行为进行建模,以预测未来的行为和模式。这项研究可以扩展到特定的样本群体,如零售客户或社交媒体消费者、天气预测、机器学习以及各种其他学科。
9.2 数据科学在金融领域的作用是什么?
那么,机器学习、大数据和人工智能对许多开发人员、商业人士和企业员工来说都是迷人且未来的选择。然而,由于安全顾虑,金融行业的组织通常对新技术持有抵制态度。事实上,金融世界更多地受到前沿发展的驱动。虽然机器学习可以通过减少欺诈来简化贷款流程,但 AI 驱动的应用程序可以为用户提供高级推荐。
自诞生以来,数据科学已经推动了许多行业的发展。事实上,金融分析师已经依靠数据来得出许多有用的见解。然而,数据科学和机器学习的发展导致了该行业的巨大进步。如今,自动化算法和先进的分析方法被一起使用,以前所未有的速度超越竞争。
为了跟上最新的趋势并了解它们的使用情况,我们将通过提供许多示例来讨论数据科学在金融领域的价值。因此,数据科学在风险分析、客户管理、欺诈检测和算法交易等领域被广泛使用。我们将探讨每个领域,并向您介绍数据科学在金融行业的应用。
最初,数据是批处理处理的,而不是实时处理,这给那些需要实时数据来获得当前状况的行业带来了问题。然而,随着技术的改进和动态数据管道的增长,现在可以以最小的延迟访问数据。
有了这种金融应用中的数据科学,组织能够在没有延迟问题的情况下监控购买、信用评分和其他金融指标。金融公司可以根据过去的行为模式做出关于每个客户可能的行为方式的假设。使用社会经济应用程序,他们可以将客户分类到不同的群体,并预测每个客户未来可能收到的金额。
9.3 超越数据科学:FutureICT 2.0
凭借我们对宇宙的了解,我们已经将人类送上了月球。我们知道我们周围和我们内部物体的微观细节。然而,我们对我们的社会运作方式以及它如何应对引发变化的知识相对较少。人类现在面临着严重的危机,我们必须开发新的方法来应对 21 世纪人类面临的全球挑战。随着人与人之间的连接迅速增加,我们现在能够利用信息和通信技术取得重大突破,这些突破超越了其他领域的渐进改进。
因此,及时创建一个信息和通信技术(ICT)旗舰项目来探索地球上的社会生活及其相关方面,就像我们过去的一个多世纪来理解我们的物理世界一样,是及时的。(1)
这一提案勾勒出了富有远见的科学努力,形成了一个雄心勃勃的概念,使我们能够回答一系列具有挑战性的问题。将欧洲的工程、自然和社会科学界整合起来,这一提案将释放出巨大的潜力。
对于建立一个社会经济知识碰撞器的需求首次是在 2008 年 10 月 5 日至 7 日在 Erice 举行的 OECD 全球科学论坛上提出的。从那时起,许多科学家呼吁开展一项关于技术-社会-经济-环境问题的大规模 ICT 研究计划,有时被形容为曼哈顿、阿波罗或 CERN 式的项目,以研究我们生活的行星如何在社会维度上运作。由于涵义,我们在这里使用术语知识加速器。
关于建立知识加速器的组织概念目前正在欧盟支持行动 VISIONEER 中勾勒出,详见www.visioneer.ethz.ch。欧盟旗舰计划正是实现这一概念的工具,从而应对 21 世纪人类面临的全球挑战。
从未来 ICT 计划的角度来看,我们对宇宙的理解要比对我们的社会和经济的演变方式更好。我们已经开发出了允许无处不在的交流和即时信息获取的技术,但我们不了解这如何改变了我们的社会。像金融危机、阿拉伯春季革命、全球流感大流行、恐怖主义网络和网络犯罪等挑战都是我们日益相互关联的世界的表现。它们也表明了我们对技术-社会-经济-环境系统的现有理解存在的差距。
实际上,全球和技术变革的步伐,特别是在信息和通信技术(ICT)领域,目前超出了我们处理它们的能力。为了理解和管理这类系统的动态,我们需要一种新型的科学和新颖的社交互动 ICT,促进透明度、信任、可持续性、韧性、尊重个体权利以及参与政治和经济进程的机会。
9.4 一个例子:FIN4
不可持续行为的一个原因是我们的行为和可能产生的后果之间的长时间间隔。例如,人们燃烧煤已有两个世纪之久,驾驶摩托车已有一个世纪之久,而二氧化碳排放直到最近才被视为严重的全球问题。这种情况造成认知失调,即,一种不一致的不舒服感。一些研究人员提出了解决这个问题的创新方法(详见link.springer.com/chapter/10.1007/978-3-030-71400-0_4):创建 FIN4,一个社会生态金融系统。
FIN4 旨在创建一个自组织、高度微妙的激励系统,通过鼓励可取的行动和阻止不良行为来支持人们的日常决策。
为了促进可持续性,重要的是 FIN4 系统考虑到外部性。然而,FIN4 系统通过多种货币来实现这一点,反映了不同的社会价值观。通过给外部性定价并允许其交易,它们可以更准确地以多维方式反映成本和收益。外部性可以是正面的(如某些类型的创新或基础设施)或负面的(如污染)。
FIN4 主要关注积极行动,而不是处罚,原因如下:
作为一个自愿参与的系统,如果参与者面临着负面外部性的负余额,要想鼓励他们参与几乎是不可能的。获得正面行动的代币是一个更好的价值主张。因此,FIN4 侧重于奖励积极行动,而不是惩罚消极行为。
我们日常的选择似乎经常与我们的价值观脱节。然而,通过使用智能分布式激励系统,社区可以奖励他们所重视的事情——通过发行新类型的代币来解决本地需求。
这些积极的行动可以是社区认为有价值的任何事情。例如,种植树木、使用自行车而不是汽车、帮助需要帮助的人或者回收垃圾。
在这种情况下,代币可以采取任何形式的价值给社区。它们可以是完全象征性的(想象一下代表你种植的树木的虚拟奖杯),提供对服务的访问权限(比如免费自行车维护)甚至具有货币价值。
现在,通过例子尝试理解这一点。Alice 创建了一种类型的代币,用于激励人们清理并处理他们在公园里发现的垃圾。社区集体认可了这个想法并采用了它。在徒步旅行时,Bob 发现了一个空的塑料瓶,并拍了几张照片,显示他发现它的地方和他丢弃它的地方。Bob 将这些照片上传到申领平台,其他用户批准了他的申领,并奖励他一定数量的积极行动代币。
传感器或移动设备的证明需要硬件或软件中的安全措施来防止作弊,例如双重索赔。社交证明需要一个额外的激励层,鼓励其他用户诚实提供证明,同时也防止串通作弊。
在区块链上放置真实数据是一个非常棘手的问题,容易受到操纵或错误的影响。在实践中,为了充分防止作弊,很可能需要结合这些证明方法(就像我们上面的例子一样)。毕竟,数据未必能真实反映真实世界行动的真相。基于第三方数据的预言机可能需要证明提交的数据是正确的,然后才能将其不可逆地放置在不可变的区块链上。一旦使用这些方法证明了要求,或者确实是它们的组合,代币就会被铸造并转移到申领用户名下。
提供者可能是代币的创建者,一个专门的团队(比如代币持有者)或者任意一个随机用户,这取决于行动的性质和代币的类型。最有效和有用的代币系统很可能会由社区自组织和自我维持地批准和采用。
我们设想一个多层次、多维度的去中心化数字加密货币系统,以不同的特征在不同的层次创建,为不同的目的服务。
代币系统可以在超国家、地区或地方层面运作。不同的目的可能涉及与可持续性或社会相关的环境、社会或其他价值观。
允许用户提出新代币设计的任何系统都将不得不处理垃圾信息的问题。那么,我们如何确保我们的生态系统促进有用的代币概念?我们的设计不是通过制定规则和障碍来限制代币的创建,而是利用独立代币提案的创新能力。每个代币的想法都受到欢迎,但要成为官方的 FIN4 代币,用户需要用他们的治理(GOV)代币投票支持它。因此,所有用户共同维护着一份已批准的正面行动代币清单。
用于促进社会证明的声誉代币(REP)尚不存在于我们的系统中。它们的目的是帮助用户建立彼此之间的信任,以便在平台上有效地进行交互。声誉应该反映用户对系统的支持(例如,证明、投票等),而不是他们实际的正面行动代币持有量,否则可能会向声誉系统引入偏见。
在我们目前的设计中,用户通过执行支持和加强整个 FIN4 系统的操作来获得声誉代币。至少,适用于获取这些声誉代币的行动包括(1)积极收集代币(低奖励),(2)参与证明机制(中等奖励)和(3)通过策展人接受代币设计(高奖励)。最后,用户也应该能够失去这些声誉代币。另外,我们如何激励已经建立自己代币的整个社区加入更大的生态系统?这个想法是通过我们称之为流动性代币(LIQ)的“储备货币”来代表加入更大 FIN4 网络时获得的额外流动性。这种代币将代表当启用更大的网络和市场时获得的网络效应。
一种可以想象的,但过于简单化的方法是为每个被接受的代币提案创建相同数量的 FIN4 代币。因此,流动性代币的总量将与系统中的 FIN4 代币总量相一致,从而使用户更加信任使用不同的代币,并确保代币之间可以互相交换。这可能基于约翰·梅纳德·凯恩斯的“班克尔”原始想法;然而,最终设计尚未确定。由于区块链技术的性质,区块链创建者无法阻止系统范围之外的交易。我们的方法是创建强大的激励措施来使用平台,同时保护用户随时离开并带走他们的代币余额的自由。此外,当用户希望参与 FIN4 的治理时,需要一种身份形式。这里的身份(ID)与扫描护照的概念相比,更多地对应于完全建立在 FIN4 系统内部或从其他平台转移的自主权概念。例如,声誉机制可能随着时间的推移建立身份。
9.5 处理复杂性²
21 世纪的社会已经达到了一种极度复杂的程度,这使得理解它们变得极其困难。此外,我们获得的任何暂时理解往往会被快速变化和新创新所超越,这使得社会和政治应对变得具有挑战性。信息和通信技术(ICT)已经为社会交流创造了新的工具,这是变化的主要推动力(例如,社交媒体,社交网络网站)。另一方面,政治决策者经常难以跟上新媒体的发展,并理解它们对社会及其许多机构(如家庭、学校和大学、政党、银行、商业组织或金融市场)的动态和影响。这不仅源于公共政策对挑战的无知和错误反应(如恐怖主义、食品安全、传染病爆发、金融危机或环境灾害),导致许多人死亡和巨大的财务支出。维护选民对政府的信任和信心同样重要,因为糟糕的政策可能会迅速侵蚀政府的合法性。世界各国领导人对新媒体在阿拉伯之春等政治革命、伦敦骚乱等社会动荡以及恐怖主义网络中的作用感到困惑。然而,受此类干预影响的利益相关者根据决策者努力提供最佳和最全面的数据,并运用最佳和最适用的模型和理论来理解事实的程度来追究责任。这是基于规范理想,即我们应该避免干预我们完全不了解并且无法预测其对我们干预作出响应的系统。只要这种规范理想继续存在,当前的情况就需要更深入地了解社会。
当代社会许多危机和灾难的现实是缺乏可信的实时数据和可操作的理解,这突显了对加强理解的需求。例如,德国杜伊斯堡的 2010 年派对灾难,2011 年春季欧洲多个国家的 EHEC 爆发,2011 年 7 月挪威的恐怖袭击,以及 2011 年 8 月英国的骚乱。这些事件经常引发一个问题,“我们能更好地了解吗?”更重要的是,我们应该更了解吗?这些都是合适的询问,但遗憾的是,它们可能会有一个积极的答案。例如,Helbing 及其同事的工作(以及其他 FuturICT 研究人员)表明,通过更深入地了解群体灾难,我们可以增强类似事件的设计。
道德结论是,负责任的组织和设计未来派对(Loveparades)必须认真考虑所学到的教训以及相关现象的科学。这个例子还表明,关键作用不仅是数据和科学理解的发展,而且还包括将这些知识传播给实际世界的决策者和参与者。因为信息和通信技术已经成为许多社会现象的组成部分,没有希望在其中理解现代信息社会和人类行为,而不使用计算机系统和网络研究所必需的技术和科学。
然后,这就是未来信息通信技术的基本概念发挥作用的地方。
-
知识责任:在复杂系统中负责政策和行动的人有责任开发知识。其知识工具的质量(即信息系统、程序和数据)往往决定了其决策和判断的质量。因此,决策者的责任在于设计前期的认知资源和信息基础设施,这是未来信息通信技术的一个基本目标。
-
社会知识作为公共产品:社会的广泛信息应该在平等机会条件下提供给所有公民。未来信息通信技术在关键社会领域内作为私营部门信息垄断发展的一个监督,有助于建立公正和公平的信息社会。
-
隐私保护设计:在信息社会中,隐私是获得对社会现实的知识和理解的必要道德限制。尽管这个短语涉及到关于个人、个人生活和个人身份(知识)的各种道德权利、愿望、要求、利益和责任,但隐私对于个人人类的繁荣至关重要。数据安全技术必须与数据挖掘技术和电子社会科学同时发展。未来信息通信技术的一个关键目标是开发新类型的隐私保护设计。
-
保持信息社会的信任:信任涉及到信任者和受托人之间的道德关系,这种关系部分是由受托人将会道德行事的信念或期望形成的。在复杂的以信息通信技术塑造的环境中,信任要求负责环境设计的个人尽可能明确和透明地阐明激发其创造的价值观、原则和政策。这是未来信息通信技术的第四个指导概念,其最终目标是一个价值观、信仰和政策开放透明的公平信息社会。
第十章:观点动态
Luca Marconi^(1 )(1)意大利国家研究委员会认知科学与技术研究所,人工智能、大脑、心灵和社会高级学校,罗马,意大利 Via San Martino Della Battaglia 44Luca Marconi 电子邮件:luca.marc@hotmail.it
摘要
计算社会科学是一个具有挑战性的跨学科研究领域,旨在通过将传统社会科学研究与计算和数据驱动的方法相结合来研究社会现象。在复杂系统科学的概念框架中,这些现象所处和行动的环境可以被视为一个社会系统,由许多元素组成,这些元素是代理人,形成一个社会复杂网络:因此,代理人可以被网络的节点所代表,它们的相互位置决定了所产生的网络结构。因此,复杂系统科学的视角特别有助于研究社会环境中发生的相互作用:事实上,这些机制导致了系统水平上出现的集体行为。因此,计算社会科学的目标是研究不同的相互作用机制,以便理解它们在集体社会现象的产生中的作用。为了进行有效和稳健的研究,已经提出了许多模型,范围从一般社会动态和社会传播到群体行为和观点,文化或语言动态,或层次结构或分离形成。在这种背景下,观点动态绝对是一个需要研究的基本社会行为。通过日常经验,最重要的社会现象之一是一致意见:特别是当涉及到涉及不同观点的讨论时,达成至少部分一致的过程在人类思维演变过程中被证明是一个基本的催化剂。从单个个体的相互作用动态到大规模人口的观点动态,社会和政治生活中有许多情况下,社区需要达成共识。通过在不同主题上逐步达成共识的过程,一些观点传播,一些观点消失,一些观点通过合并和非线性模因过程演变:通过这种方式,主导的宏观文化在社会中形成并演变。因此,观点动态模型可以被看作是所谓的共识模型的一个子集。通常,共识模型允许理解当选择多个选项时一组相互作用的代理人是否以及如何达成共识:政治投票,观点,文化特征是其中的著名例子。基于代理人的建模方法特别有助于表示个体的行为并分析人口动态。在文献中,已经有许多模型旨在研究观点动态:每个提出的模型通常可以通过各种变体进行修改。在本章中,我们将通过展示主要的挑战和方法来研究和分析异质设置和条件下共识形成的整体情景。
关键词意见动态计算社会科学社会物理学卢卡·马尔科尼
目前是米兰比科卡大学计算机科学博士候选人,在人工智能和决策系统、以及米兰一家人工智能公司的业务战略师和 AI 研究员研究领域有丰富经验。他还曾担任知名媒体情报和金融传播私人顾问的研究顾问和顾问。他拥有米兰理工大学管理工程的理学和学士学位,以及巴利阿里群岛大学交叉学科物理与复杂系统研究所(IFISC UIB-CSIC)的复杂系统物理理学硕士学位。他还持有意大利国家研究理事会认知科学和技术研究所(ISTC-CNR)举办的人工智能、大脑、心灵和社会高级学校的研究生文凭,他在那里与 ISTC-CNR 的基于代理人的社会模拟实验室合作开展了计算社会科学领域的研究项目。他的研究兴趣涉及人工智能、认知科学、社会系统动力学、复杂系统和管理科学等领域。
10.1 引言:舆论动态学
舆论动态学旨在以形式化和数学的方式研究、建模和评估在异质社会个体之间的社会互动过程中观点演变的过程(Xia 等人,2011;Zha 等人,2020)。虽然这个研究领域在文献中并不是最近才出现的,但它的受欢迎程度如今已经增长:实际上,对复杂系统和计算社会科学的日益关注(Lazer 等人,2009;Conte 等人,2012)明显刺激了这一学科的发展,以及它在政治、社会学甚至金融等广泛范围的具体现实场景中的应用。在这个视角下,舆论动态学致力于模拟代理人之间的互动过程中发生的复杂现象,这些现象在系统层面上产生了新兴行为:一般来说,代理人通过一些简单或复杂的社交网络相互连接,从而实现一些特定的互动、协调和信息交换过程(Patterson 和 Bamieh,2010;Fotakis 等人,2018)。这些机制在其本质上是有限和局限的,它们指导着潜在的动态,从而使学者和研究人员能够将他们的研究集中在特定的现象和情境上:在计算社会科学的视角下,挑战在于有效地模拟互动机制,以便理解它们在集体社会现象的产生中的作用。
在这个概念框架中,舆论动态研究了在某种社会网络中组织的群体之间的舆论演化过程。通过日常经验,最重要的社会现象之一是一致或共识:特别是当涉及到讨论不同观点的讨论时,至少达成部分一致的过程被证明是人类思维演化的基本催化剂之一。其重要性已经被哲学和逻辑学指出,从赫拉克利特到黑格尔,都有着论点-反论点的概念化。社会和政治生活中有许多情况需要社区达成共识。通过对不同主题的逐步达成一致的过程,一些观点传播开来,一些观点消失,另一些通过合并和非线性的模因过程演化(Mueller and Tan 2018; Nye 2011):这样,主导的宏观文化就形成并在社会中演化。因此,对参与社会群体中观点演化的不同社会和文化现象的数学和统计研究,对于帮助异质组织中的从业者、决策者、管理者和利益相关者在各种潜在的实际情况下改善和优化决策过程是非常重要的。
在舆论动态中,设计、调整、选择和评估在特定静态或演变条件和边界下的正确模型的过程需要双重视角:一方面,有必要对社会群体中代理之间的单一、精确的本地相互作用进行建模,这些代理通常在物理上或社会上邻近或在某种程度上“相似”。必须准确建立和预定义邻域、相似性、能力或特定阈值的概念,以允许这种相互作用。一般来说,代理之间的局部相互作用由所谓的更新规则来建模,这些规则封装了具体的机制和关系,同时考虑了代理行动和相互作用的网络特征和结构。简单、局限的局部相互作用和知识交换过程导致在整个社会网络水平上产生全局、一般的、新兴的行为(Bolzern 等人 2020; Giardini 等人 2015)。因此,舆论动态的主要目标之一是研究和分析社会系统达成共识所需的方式和整体时间,在几种边界条件下。一般来说,最终状态倾向于假定三种经典的稳定状态之一:共识、极化和分裂(Zha 等人 2020)。正如每个人的日常经验所表明的那样,在社会群体或交互中,并没有保证总是达成共识:在某些情况下,会出现两种最终意见,将人口极化为两个群集,或者,在其他情况下,没有出现主导意见,因此人口意见在某些群集中分裂。因此,舆论动态考虑了一些构建有效和完整模型的具体概念要素:意见表达格式,即意见如何表达和建模(例如,连续、离散、二进制等)、意见演变规则,即管理系统动态的更新规则,以及舆论动态环境,即在特定的、局限的社会或物理关系下围绕代理的社会网络。
在本章中,我们将通过展示主要挑战和方法来研究和分析异质环境和条件下共识形成的整体情景,来呈现舆论动态的总体情况。我们将从将计算社会科学的一般概念框架置于上下文中开始,作为有效研究和分析社会现象的手段,然后我们将提出文献中主要舆论动态模型的初步分类,这对我们的目标是有用的。然后,这些模型将被概括描述,旨在突出考虑的主要特征和行为。最后,我们将强调它们对金融领域的优势和潜在应用,以帮助读者欣赏和理解这个引人入胜的学科对于真实、具体和当前的金融情景和环境的潜力。
10.2 计算社会科学视角
计算社会科学(CSS)是一个充满挑战和前景的高度跨学科研究领域,旨在通过将传统社会科学研究与计算和数据驱动方法相结合,研究可能的任何社会现象(Lazer 等人 2009; Conte 等人 2012)。因此,CSS 专注于让社会科学家利用定量、客观的以数据为中心的方法,将他们的经典和传统的定性研究与来自于社会现象的定量分析的新证据相结合,这些证据来自于真实社会环境和社区。用于设计和评估计算模型的数据可以来自于多种数据来源,例如社交媒体、互联网、其他数字媒体或数字化档案。因此,CSS 本质上是跨学科和多层面的:它允许通过广泛而不断发展的一系列方法和途径进行关于人类和社会行为的推断,例如统计方法、数据挖掘和文本分析技术,以及多主体系统和基于代理人的模型。另一方面,可能的应用领域涵盖了文化和政治社会学、社会心理学,甚至经济学和人口统计学。
在复杂系统科学的概念框架中,这些现象存在和作用的环境可以被视为一个社会复杂系统,由许多元素,即代理人组成,它们形成了一个社会复杂网络:因此,代理人可以被表示为网络的节点,它们之间的相互位置决定了生成的网络结构。创建和调整“正确”的和最“有用”的网络结构证明是 CSS 方法和算法设计和开发中的基本步骤。节点之间发生的不同关系可以产生整个网络中的一些普遍和新兴的行为。然后,复杂系统科学的视角特别有用于研究社会环境中生成和发展的相互作用:这些机制导致了系统级别上的新兴集体行为。因此,整个网络的某些属性源自节点之间发生的各种关系。作为一个复杂系统,新兴行为不能从单个代理人的行为或属性中推断出来,根据亚里士多德的话:“整体大于部分之和”(Grieves and Vickers 2017; Aristotle and Armstrong 1933)。在任何社会系统中,代理人之间的相互作用在所有社会过程中都起着关键作用,从组织中的决策和协作,到社会群体中的意见动态和感知,再到大型人类社会中的文化演化和扩散。因此,CSS 面临的主要挑战是识别、分析和预测涉及的代理人之间的社会相互作用导致的异质社会行为和现象的演变。
总的来说,CSS 必须处理两个主要的宏观问题:社会计算和算法建模问题。前者与 CSS 相关的一般需求和挑战有关,例如将定性社会研究与数据分析和计算方法相结合,以及评估和模拟代理人在不同条件和社会情境中的协调、交互和社会过程的需求。这些交互和协调过程可能涉及代理人之间的信息或知识生产和分享,就像在观点动态模型中一样,导致网络层面存在或不存在最终状态,例如在整个系统中达成一致或同步。相反,后者与设计和建模不同交互机制相关的具体问题和算法问题有关,旨在理解它们在集体社会现象的出现中的作用。同样,信息和知识的创造与交流的作用必须经过算法调查,因为它们在定向人口社会和文化演变中起着重要作用。随后要面对的步骤是选择、设计、实施和评估适合的模型,在特定情况和涉及的社会动态中进行调整甚至扩展。
文献中提出的模型涉及许多不同类型的社会现象和过程,从一般的社会动态(González 等人 2008; Balcan 等人 2009)和社会传播(Conover 等人 2011; Gleeson 等人 2014)到人群行为(Helbing 2001)和舆论动态(Holley 和 Liggett 1975; Granovsky 和 Madras 1995; Vazquez 等人 2003; Castellano 等人 2003; Vilone 和 Castellano 2004; Scheucher 和 Spohn 1988; Clifford 和 Sudbury 1973; Fernández-Gracia 等人 2014),文化动态(Axelrod 1997),语言动态(Baronchelli 等人 2012; Castelló等人 2006),层次结构(Bonabeau 等人 1995)和社会人群中的分离形成。所涉及的一般宏观方法利用了复杂社会系统中微观和宏观水平之间的二分法:模型通常关注系统中包含的少数和简单机制,引导代理之间的局部交互,以研究社会动态随基本交互规则的变化而变化,从而引发特定现象对社会系统集体行为的单一贡献。通过在局部层面具体包含和调整社会机制,模型能够反映真实世界社会情况的日益复杂性,使从业者和学者既能专注于某些特定机制,又能评估全局网络中出现的整体行为和现象。
在这个一般性的视角下,现在我们将通过关注舆论动态和文献中提出的主要模型来进行。我们将首先描述舆论动态的一般情景,展示现有各种方法的可能分类。然后,我们将遵循提出的分类策略,关注不同的模型和机制,让读者欣赏它们在社会环境中的重要性,最后,在具体的金融应用中。
10.3 舆论动态模型分类
意见动态模型在文献中广泛传播和流行,在计算社会科学、数学和统计物理学建模人类行为的概念和学科框架中(Castellano 等人 2009;Perc 等人 2017),以及复杂系统中。模型的兴起、演变、适应和修改是正在进行中的过程,因此提供全面和完整的分类是具有挑战性的。对我们的范围来说,我们的目标是让读者能够在我们将在接下来的章节中报告的传统、基本和基本模型中取得方向。最终目标是让读者在涉及金融及其挑战时欣赏它们的特定优势或潜在应用。因此,这项工作绝对不是对文献中模型的穷尽审查。
为了为我们的范围提供一个有用的分类,我们考虑了两个主要维度:维度和意见的类型。实际上,一方面,意见可以用单维度或多维度向量来表示(Sîrbu 等人 2017);另一方面,模拟意见的向量可以是离散的或连续的(Zha 等人 2020;Sîrbu 等人 2017)。当模拟由一组特征或特征组成的代理的多维度意见时,多维度意见可以很有用。这在 Axelrod 模型的情况下发生(Sîrbu 等人 2017),在该模型中,代理被赋予了不同的文化特征,这些特征模拟了人口中个体的不同信仰或态度。相反,一维的、经典的意见动态模型被广泛用于研究不同条件和人口中的意见动态,重点关注特定类型的意见及其根据系统规则的演变。此外,意见可以是离散的或连续的。在前一种情况下,意见向量的分量只能取离散值,因此封装了有限数量的可能状态,而在后一种情况下,意见向量的分量是连续的,在实数域中取值(如果需要的话,可以具有任何特定的约束)。最后,在文献中也有混合模型,其中不同的可能性根据要研究和模拟的特定社会现象或行为混合,例如在 CODA(连续意见和离散行为)模型中(Zha 等人 2020;Sîrbu 等人 2017)我们将报告。
当然,可以有几种其他方法来提供对文献中不同观点动态模型进行研究和欣赏的分类方法。特别是,可能考虑其他显着的区分要素,具体包括在达成共识形成过程中达到的稳定状态的类型,以及代理人的行为、研究的社会现象,甚至利用的社会网络的类型。无论如何,可以通过关注特定建模因素的存在或缺失来构建文献中许多模型的任意分类或分类。值得注意的是,在进一步探索观点动态模型的可能分类时,信息表示和信息共享的作用可能是至关重要的,特别是当涉及到外部信息的角色时,即源自系统人口外部的信息来源(例如大众媒体广播)。然而,我们决定将所选择的分类尽可能简单化,以便专注于主要的基本模型及其在金融中的应用,如前所述。
在图 10.1 中,我们根据所述的分类方案对不同模型进行了简要表示!
4 象限动态模型说明。顶部是连续的,左侧是一维的,底部是离散的,右侧是多维的。
图 10.1
主要观点动态模型的分类定位图
10.4 连续观点模型
让我们从介绍具有一维和连续观点的主要观点动态模型开始。这些模型在文献中被广泛利用来分析和模拟现实世界中的情景,其中与特定主题相关的观点(以一维方式)不是离散或二元的,而是在连续的尺度上变化,必要时具有特定的边界或限制。在文献中,这一类别中的主要模型是 De Groot 模型(DeGroot 1974;Das 等人 2014)和有界信心模型:Deffuant-Weisbuch 模型(Weisbuch 等人 2002;Deffuant 等人 2000)以及 Hegselmann-Krause 模型(Hegselmann 和 Krause 2002)。
De Groot 模型
这是经典的意见动态模型,被广泛研究为更高级模型或扩展的基本方法。根据 De Groot 的说法,意见形成 过程及其动态是根据相互作用代理的初始意见的线性组合 来定义的。然后,让我们考虑代理的集合
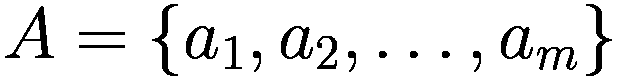
,并让
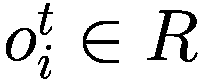
表示第
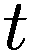
轮时代理
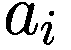
的意见。由于模型使用线性组合来定义代理的演变意见,我们引入了权重
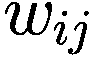
,即代理
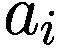
分配给代理
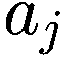
的条件
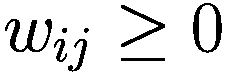
和
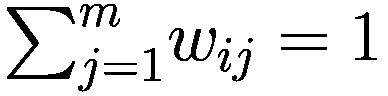
必须满足。然后,De Groot 模型利用以下更新规则,控制代理
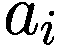
的意见演变:
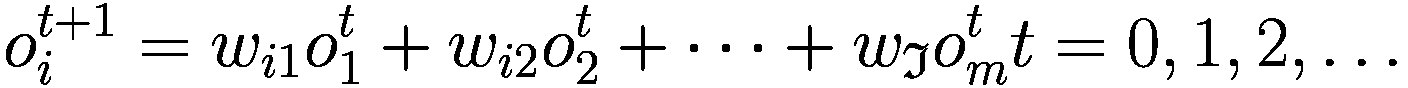
这个更新规则是明确等价于:
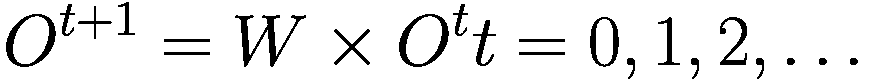
或者,替代地:
其中
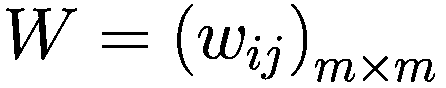
是封装了代理使用的不同权重的行随机权重矩阵,其中
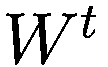
是它的
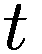
次幂,而
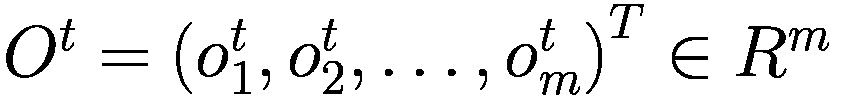
。这个模型本质上是线性的,而且随着时间的推移是可追踪的。它是一个迭代平均模型,可以达成共识:根据 De Groot 的说法,如果存在一个时间
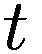
,使得矩阵
中至少一列的每个元素都是正的,则可以达成共识。换句话说,如果权重矩阵
具有严格正列,则可以达成共识。由于其简单和线性性,De Groot 模型在文献中有几个扩展:这些是所谓的 DeGrootian 模型(Degroot 1974; Noorazar et al. 2020; Noorazar 2020)。其中一个最广泛使用的是Friedkin-Johnsen模型(Noorazar 2020; Fried
有界信心模型
有界信心模型可以看作是 De Groot 模型的扩展,其中代理根据其观点之间的距离的给定阈值进行交互,而权重随时间或代理的观点变化而变化。主要思想是观点之间的距离决定了交互的发生:如果两个考虑的代理之间的差异低于给定的阈值,那么代理将进行交互,他们的观点可能会发生变化,否则他们彼此绝对不会考虑,因为两种想法相距太远。如果阈值对所有代理都采用相同的值,则有界信心模型是均匀的;否则,模型是异质的。两种主要的有界信心模型是 Deffuant-Weisbuch 模型,这是一个成对模型,以及 Hegselmann-Krause 模型,这是最常见的同步版本。
Deffuant-Weisbuch 模型
在 Deffuant 模型中,每个离散时间步骤从代理集合中随机选择两个相邻代理,并以成对方式进行交互。仅当它们的观点差异低于给定的阈值
时,交互的结果是一种朝着彼此观点的妥协。否则,他们的观点不会发生修改。然后,如果
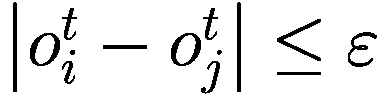
,代理将进行交互并更改他们的观点,否则他们将不会进行交互。如果交互发生,代理 i 的更新规则如下:
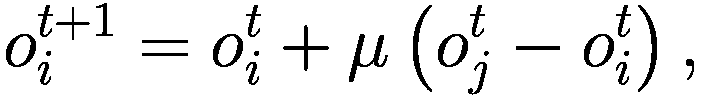
而代理 j 的更新规则如下:
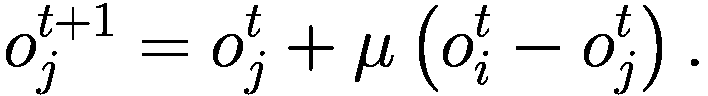
接着,在这个模型中有两个主要参数需要考虑:收敛参数
,也称为谨慎参数,它控制收敛的速度,或者换句话说,一个代理在人口中受到另一个代理意见影响的能力;以及置信半径
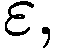
,即控制一个代理与人口中另一个代理实际交互能力的阈值。Deffuant-Weisbuch 模型在与这两个参数相关的许多条件下进行了广泛研究。根据两个参数在不同情况下和取值的不同,该模型可以导致三种可能的稳定状态:共识、极化和碎片化。特别是在特殊情况下,当
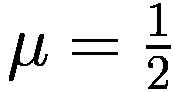
,交互的结果将是以他们先前意见的平均值完全一致。文献中还发现了几种扩展,考虑到诸如噪声、相互作用的代理类型以及参数值上的特定边界或条件等方面。
Hegselmann-Krause 模型
这是最为广为人知和传播的有界信心模型的同步版本。再次强调,这个模型有许多版本。我们的目标只是呈现最简单和最常用的版本,以便读者能够欣赏到这种方法在现实世界应用中的潜力。这里最简单的更新规则由以下公式给出:
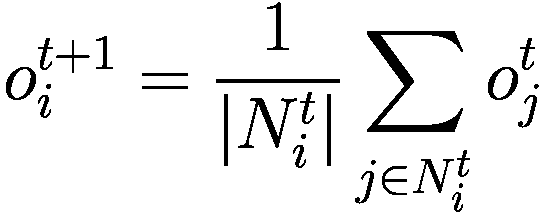
,其中
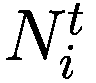
是时间

处代理
的邻居集,包括代理
本身,其中满足条件
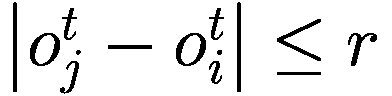
,即可能相互作用的代理意见之间的差异小于给定的阈值。这个模型着重研究了邻居意见动态及其收敛特性,甚至在扩展的多维情况下也是如此。
10.5 离散意见模型
这些模型被广泛用于探索和分析现实生活中意见呈离散范围的情况。通常,许多模型假设二元意见,至少在模型的初始版本中是这样,随后的版本中会对多种离散意见进行扩展。通常这样的模型被用来研究和模拟政治情景,就像特朗普的胜利一样。再次强调,我们这里的目的不是涵盖文献中设计和应用的所有模型,而是呈现用作更复杂和先进方法基础的最重要和基本的模型:我们的目的是向读者介绍这些方法在金融领域的许多潜力,我们将在本章的最后一节中探讨这些潜力。
投票者模型
选民模型是最古典和最简单的离散观点动态模型之一。正如其名称所示,它已被广泛应用于选举竞争和政治系统的研究。让我们考虑一个由
个代理组成的人口,并且让
代表人口中的代理集合,其中
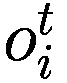
是时间
时代理
的观点,假设为二进制状态,即
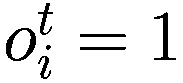
或
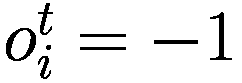
。然后,在每个时间
,选择一个随机代理
。接着,选择第二个随机代理
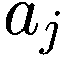
,并且代理

的观点
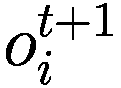
将采用代理
的值,即
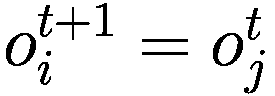
。通过这种方式,在交互之后,代理
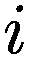
实际上采用了随机选择邻居的状态。在这个模型中,有两种可能的最终共识状态,并且人口达成的最终状态取决于代理的初始观点分布。这个模型在位于二维正则格点的代理人群中已被广泛和深入地研究。此外,许多研究与
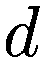
维超立方体格点有关。在一个无限系统中,已经证明了对于
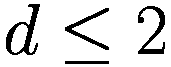
,会达成共识。
Sznajd 模型
Snajzd 模型背后的理念可以通过简单的格言“团结就是力量,分裂就是失败”有效传达。换句话说,该模型概括了社会系统中可能发生的两种特定社会行为,即在邻域级别上:社会验证 和 纷争破坏。前者涉及在邻居之间传播特定观点:如果邻域内的两个(或更多)代理人持有相同观点,则他们的邻居将同意他们,即该观点将在该邻域内传播并成为主导观点。而后者则涉及邻域内观点的分裂:如果两个(或更多)代理人持有不同意见,即他们持有相反的观点,则他们的邻居将与他们争论,因为每个代理人都将更改自己的观点,直到他们不再与相邻的邻居达成一致意见。更正式地说,让
或
表示时间为
时代理人
的观点。控制观点演变的更新规则如下:
-
在每个时刻
,随机选择一对代理人
和
,他们的邻居分别是
和
。
-
如果
和
持有相同的观点,它将传播到
和
,即如果
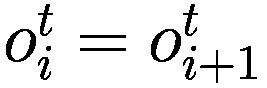
,那么
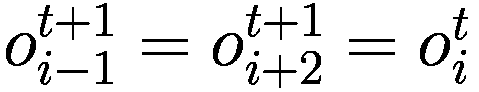
。
-
如果

和
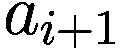
没有相同的观点,则不同的观点将传播给代理的邻居,即如果
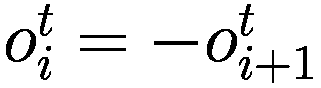
,那么
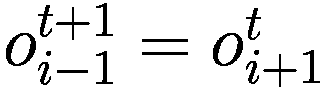
和
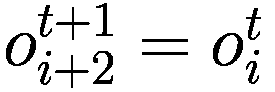
。
伊辛模型
伊辛模型是物理学中一个众所周知且广泛研究的模型,是统计力学中分析铁磁材料中相变最古典的方法之一。在观点动态领域,它被用来模拟社交互动的情况,其中代理人有二进制观点,由自旋表示,可以是上或下。这种选择似乎本质上有限,但在人们需要在特定主题上做出两个相反选项之间的选择时,证明它是有用的。自旋耦合被用来表示代理之间的同伴互动。此外,该模型还考虑了另一个因素,即外部信息(例如媒体推广),在模型中由磁场表示。因此,交互能量,称为
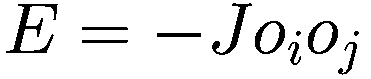
代表了代理之间的冲突程度,其中
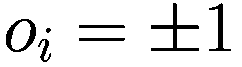
和
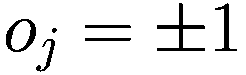
代表代理的自旋,分别对应上升和下降的状态,而
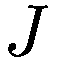
是能量耦合常数,表示代理之间的相互作用强度。此外,观点和外部信息之间存在一种交互能量
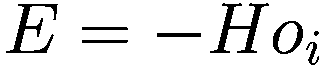
。前者的交互能量在两个代理分享相同观点时最小,而后者在观点和外部场共享相同值时最小。
多数规则模型
这个模型由加拉姆引入,用来研究多数规则在社会系统中意见动态演化中的运用。在这种情况下,从代理人群体中随机选择一个由
代理人组成的小组,所有意见都是二进制的。然后采用多数规则更新意见,最后,所有过程再次从其他随机选择的代理人开始。在文献中,已经研究了许多版本的更新规则和条件。在加拉姆版本中,代理人
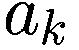
在时间
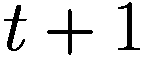
的意见

将等于
,如果
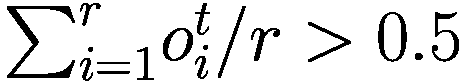
,而如果
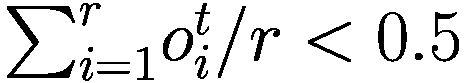
,则
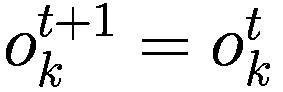
,在所有其他可能的情况下
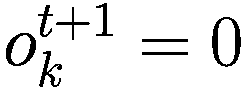
。加拉姆的工作对于增强和促进对层次系统中意见动态以及政治和选举系统中决策制定的研究至关重要,包括在人口中代理人之间意见的联盟或分裂的情况下。
格拉诺维特的阈值模型
这是最著名的阈值模型之一,研究了一种临界阈值在同意决策者数量中的可能存在和作用,如果达到,将决定共识的实现。在这个模型中,每个代理人都有一个确定其选择是否积极参与集体行为(例如特定政治决策或决策过程)的激活阈值。这个阈值基本上取决于特定个体在决定加入群体和过程之前应观察到的其他代理人的数量。然后,一个由
代理人组成的人口,每个个体都被赋予一个特定的阈值,定义了在考虑个体决定参与决策过程和集体行为之前所需的参与代理人数量。在异质条件和人口中研究这些阈值可以预测人口中意见的最终状态。
10.6 混合模型
除了文献中可能找到的离散和连续的经典意见动态模型外,还可以找到几种混合方法,将不同类型的观点混合或合并异构模型,目的是相互加强所包含的方法并利用它们的协同作用。不同模型的混合化可以是研究某些行为或机制的一种方式,也可以在更大、更全面的框架中有效地创建一种方法,以更好地模拟它们在实际应用或场景中的情况。在这个简短的部分中,我们简要介绍连续观点和离散行动(CODA)模型,为离散和连续元素在意见动态中的混合提供了一种解释性方法。
CODA 模型
在这个模型中,代理处理二进制决策,因此代表了一个(非常常见的)情况,即个体面对两种冲突相反的观点选择之间。然后,每个代理!
必须在两种离散(二进制)观点之间选择一个选择。在这种情况下,合理假设每个代理!
都会以概率!
选择两个替代方案之一。CODA 方法有助于建模这种概率,允许在特定条件下建模选择某种离散观点的程度。然后,我们有一个变量代表两个相反的选择,即!
,所有代理都用连续概率在一个方格网络上表示,其中概率!
表示同意观点!
的程度,而概率!
对应于同意观点!
的程度。代理通过使用阈值!
来选择一个离散观点。此外,每个代理都声明哪种选择更受欢迎,从而通知其他代理。所有代理只看到其他人的离散观点,并根据邻居的情况改变相应的概率,通过特定的贝叶斯更新规则,以刺激和促进邻居之间的协议。邻居之间的相互作用可以根据不同的模式进行,可以是选民模型,其中每个代理在每个步骤中与一个邻居互动,也可以是 Sznajd 模型,其中两个邻居能够影响其他人。在任何情况下,即使在开始时没有极端观点,该模型也显示了极端主义的出现。已经研究了模型的几个扩展,例如在代理社交网络中存在迁移的情况,即代理移动并改变他们在网络中相对于其他代理的位置的可能性。其他情况包括允许第三种可能的观点的存在,以及为代理提供对他们对其他个体产生的影响的“意识”的可能性。最后,值得一提的是,在系统中包含一些“信任”的可能性,通过使每个代理能够评判其他代理,将它们归类为“值得信赖”的和“不值得信赖”的。在每种情况下,在几种不同的异质条件下研究了共识或极化的可能出现。
除了 CODA 模型外,文献中还研究和探索了许多其他混合方法,从考虑代理人在互动过程中过去关系的模型,到试图创建混合连续-离散动态的尝试,甚至到试图将认知或心理现象或行为纳入结构或代理人之间的互动的模型。为了充分利用某些模型的潜力,有时它们被扩展到多个意见维度。事实上,直到现在,我们只考虑了一维模型,在许多实际场景和具体应用中证明了其有效性。然而,许多情况需要超过一维才能充分表示所考虑的意见范围:因此,值得一提的是多维意见动态模型。
10.7 多维意见
在广泛的意见动态模型和方法场景中,有必要并值得提及多维情况,使得可以设计、开发和应用多种方法,无论是专门为这些情况创建的方法还是从一维情况延伸而来的方法。乍一看,这样的模型在实际场景中可能显得有些奇怪或无用。相反,当人群中的代理人的观点由一系列异质变量组成并受到影响时,这样的模型尤其适用和必要,这些变量代表他们的特征或特性,与不同的社会学、政治或文化特征相关联,影响并构成整个观点。因此,多维模型的使用在真实的生活复杂场景中甚至可能比在真实世界更加真实或有用,其中代理人、他们的观点和特征是复杂的,并与几个维度相关联。因此,文献中有大量研究专注于探索此类模型,通常会扩展和调整一维经典情况,就像有界信心模型一样。在文献中特别研究的方面中,有 信心水平 的变化、模型 收敛、在异质条件下的 稳健性 和 稳定性,影响在人群中出现共识、极化或观点分段的外观。在这个简短的部分中,我们简要介绍了著名的 Axelrod 模型的主要方面,其中代理人具有不同的文化特征,用于建模其信仰或态度。
Axelrod 模型
该模型是为了文化动态而引入的,用于研究和模拟文化形成和演变过程。在人口中,包括两种主要的社会学现象,即同质性和社会影响。前者指的是偏爱与相似的同龄人互动,因此代理人具有一组相似的特征。同质性是一种常见的社会现象,它可以导致在相互作用代理人的人口中出现集群,在许多种类的社会网络和社会群体中都是如此。而后者则指的是个体在互动后变得更加相似的倾向,因此它是在互动过程中相互影响的能力。
在拥有
个个体的群体中,每个代理都有由
个变量建模的文化,因此存在文化特征的向量

。它们中的每一个可以假设
个离散值,这些值是不同特征的特性,其中
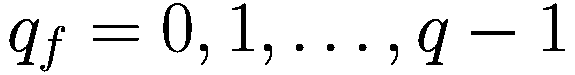
。这种结构绝对有助于有效且立即地对代理的不同信仰、行为或态度进行建模。两个代理
和
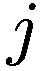
之间的交互根据交互概率
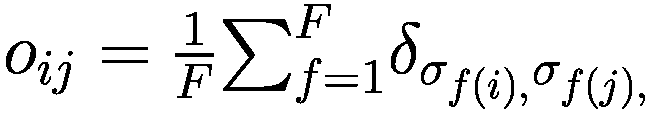
发生,其中
是 Kronecker’s delta。然后,根据这样的概率,如果发生交互,将选择一个特征,并设置
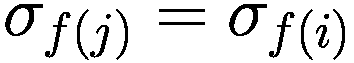
。否则,交互不会发生,两个代理将保持各自的特征。这种模型导致一个随机初始化的群体达到两种可能的吸收状态:一种是一种共识,即代理共享特征的有序状态,另一种是一种分段,即不同特征的多个集群在群体中共存。最终状态特别取决于可能的初始
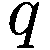
个初始特性的数量:如果
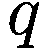
很小,那么具有相似特性的代理之间的交互更容易,因此可以达成共识。相反,对于较大的
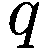
,没有足够的相似特性共享,因此相似代理之间的交互无法创建和维护不断增长的文化领域。当然,研究两种可能状态之间的相变尤为重要。在正规晶格上,这种相变出现在临界
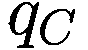
,取决于群体中特征数

的数量。
当然,这种模型已经在文献中得到了广泛的分析、调整和扩展。总的来说,它具有一个简单而重要的结构,可用于研究文化动态和意见动态在多维变量存在的情况下。因此,这种模型适用于许多可能的调整、修改,甚至扩展到更一般的结构。在可能的修改版本中,值得提到的是修改更新规则的情况,例如始终允许选择一对相互作用的代理人,而不是随机选择它们。其他有趣的模型利用所谓的文化漂移,即影响文化集群形成和共识出现的外部噪声。最后,还可以改变代理人对于他们意见变化的态度,例如包含一些阈值来判断重叠,确定代理人何时会不同意,以及包含忠实个体,他们在任何情况下都不会改变他们的意见。
10.8 金融应用
意见动态在金融领域被广泛应用,在商业和组织研究中也是如此。让我们想起金融市场本质上是一个复杂的系统,在这个系统中,大量人类代理人相互作用、交换信息、交易并创建具有内部动态的群体。这是在努力理解意见动态的许多可能应用以及对金融领域的社会行为进行数学建模时需要考虑的基本概念。此外,还有必要提醒,这些代理人具有异质性特征,例如与他们的文化、社会或人口统计特征相关,以及不同的投资策略和风险倾向。这些特征和行为在微观和中观层次上引发了 emergent 现象,影响了金融市场的演变,以及整个社会的演变。在这种情况下,意见动态被证明是一个有用的方法论和数学工具,用于模拟金融领域社交网络的结构,模拟可能行为的范围,并研究现实情况下的 emergent 和集体现象。虽然在金融情境中利用二元模型是常见的,允许研究代理人必须在两种相反行动之间选择的情况,但通常可以找到已经提出的基本模型或其扩展的应用,以及新创建的模型,专门设计用于分析特定情况或场景。
在所提出的模型中,Ising 模型是最常应用于金融领域之一,无论是其原始版本还是专门为金融设计的扩展版本。在这种情况下,有必要将研究限制在二元情况下,这并不是问题,因为这是观点动态和金融实际应用中的典型场景。Ising 模型可用于模拟多头和空头交易者之间的交互和交易策略,在一个受到外部力量影响代理之间的交互和行为的环境中。更进一步,有一些扩展能够更好地代表在这种情况下发挥作用的力量:特别是,Ising 模型的基本元素可以扩展到考虑所谓的相互影响,即交易者的决定对其他交易者的影响,还有外部消息或其他可能影响交易者决策和可能的交易者特征或特质的外部力量。Ising 模型的其他可能扩展扩大了潜在的交易者选择范围,允许代理人决定是买、卖还是不采取行动。因此,Ising 模型被证明在对模拟金融情况和场景进行广泛的模拟时,既对模拟代理的特征和影响其交互的力量有用,又对交易者可能进行的行动种类进行模拟。
Sznajd 模型可以帮助更好地理解和研究在交易员群体中的某些特定观点动态的特征。事实上,像许多其他社会系统一样,这些群体受到赶羊效应的影响,一些追随者模仿一个领导者的决定。由于 Sznajd 模型代表了社会认可和分歧破坏的社会现象,这种方法可以包含通常存在于金融市场中的一些常见和典型社会机制。实际上,当有一些具有权威、经验和沟通能力及渠道以影响其本地邻居的本地专家时,该群体中的许多市场参与者是趋势追随者:他们将根据其本地专家的意见做出决定和下订单。相反,当这样的专家在邻里中不存在时,趋势追随者将随机行事,系统中没有占主导地位的意见。此外,模型中还可以添加理性交易者:这些交易者精确了解市场上的供求水平,因此能够计算出准确下单的方式。
类似地,选民模型被应用于金融领域,以研究社区中的社会行为,特别是在交易者之间的金融选择和行动的扩散和演变方面。可能的应用涉及使用选民模型来研究市场上代理人的状态:买入、卖出或不作为。其他应用研究了通过选民模型来研究金融市场中的熵波动行为。选民模型最重要的应用之一是使用所谓的“社会温度”,它代表市场温度,影响某些代理人群体的说服力,进而影响代理人的投资策略的不确定性。
使用基本模型分析复杂金融和社会环境中代理人的行为是重要的,从而允许模拟和理解市场演变,以及市场历史上发生的市场趋势、特定泡沫或崩溃等现象。因此,这些模型能够让研究人员和学者欣赏和检验不同种类的相变、稳定状态以及在多种异质条件下市场的一般演变。然而,基本模型有许多可能的扩展,以及专门设计的模型来捕捉一些特定的金融情况和机制或方面。一个主要的扩展是使用连续模型,而不是简单和常见的离散二进制观点和时间。此外,可以通过考虑代理人之间的观点和信息交流来增加复杂性水平。由于模型的结构包含的元素比最经典和基本的方法中的元素更多,因此可以适当地利用模型的分析解,基于微分方程,而不是数值和计算机模拟。所有这些可能性通常都存在于所谓的“动力学模型”中,这些模型用于研究投机市场的演变,或者价格形成和变化以及风险倾向的机制。另外,其他模型尝试将基于代理人的和经典观点动态方法与机器学习相融合,以数据驱动和更具计算性的方式。这种协同作用产生了用于通过使用广泛的概率参数来研究复杂随机情况中的观点演变过程的概率模型。从分析的角度来看,在这种情况下通常使用随机微分方程,以及神经网络结构,以帮助研究社交网络中的非线性依赖性和观点动态。
总的来说,舆论动态是一种非常有前景的方法论工具,可以帮助学者、研究人员和从业者深入了解市场结构和演化,捕捉相关的和隐藏的社会和金融现象,并在广泛的潜在应用和情境中预测未来的市场状态。我们确信,进一步研究这些方法,特别是与机器学习和深度学习的众多计算潜力协同作用的研究,将揭示许多社会和金融机制,从而推动我们向着理解更加迷人的复杂系统之一迈进,这些系统深刻影响着我们的日常生活。