Rerank进一步提升RAG效果

RAG & Rerank
目前大模型应用中,RAG(Retrieval Augmented Generation,检索增强生成)是一种在对话(QA)场景下最主要的应用形式,它主要解决大模型的知识存储和更新问题。
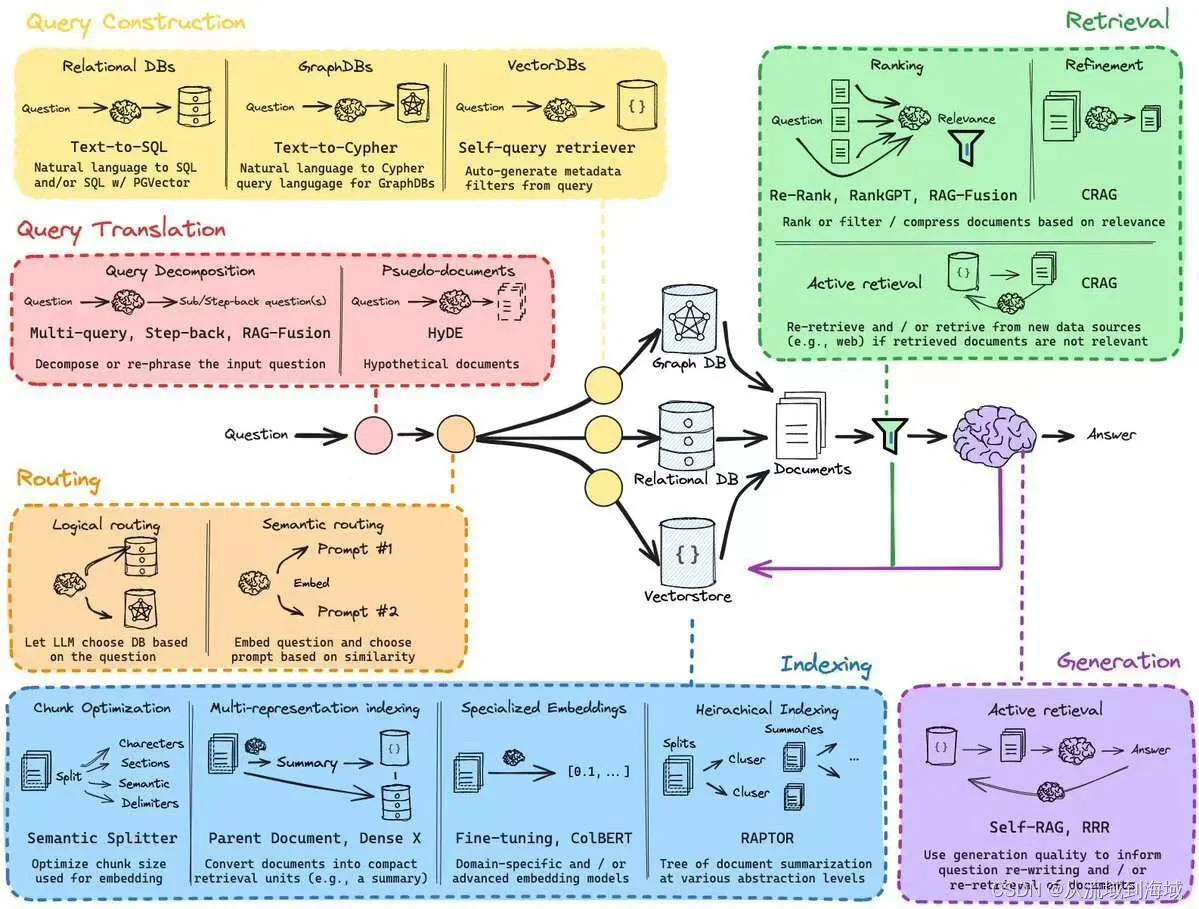
简述RAG without Rerank的主要过程:

相似度匹配
Question
从向量库或其他存储召回的相关chunk list
提示词
LLM
Answer
从向量库或其他存储召回的相关chunk list会按照检索时指定的距离计算公式由近及远排列,或者假设相似度得分记为distance_score,按distance_score大小从大到小排列。
Rerank指的是在检索结果的排序基础之上再排一次序,将对生成回复真正重要的chunk排在前面,排除干扰项,可以类比理解为推荐算法的粗排和精排过程。
为什么需要Rerank?
召回阶段使用向量库进行召回时,要求快速在大规模数据中检索到相关项,该过程需要度量当前question和库内全部向量的相似度,按指定窗口大小得到top x结果。也就是说,召回其实是个穷举过程,那么必然不能使用复杂度特别高的算法来计算相似度,为了召回的性能牺牲了召回的精度。
Rerank的概念在大模型之前就已经出现,比如推荐算法和搜索算法的精排过程,可以理解为在粗排结果的基础之上进行rerank(精排)。
RAG的Rerank必要性体现在3个方面:
- 精度提升:基于embedding的向量化检索过程可以通过一定程度的语义相似度来高效检索相关性较高的文本片段,但由于语义本身的复杂性和多义性,以及高维向量相似度匹配可能产生的噪音,向量检索可能会召回一些相关性较低的候选项。因而引入rerank模型,希望在向量召回(可以理解为粗排)的基础上进一步优化结果,降低为生成提供的参考内容中的无效信息。
- 语义匹配:向量库检索过程仅考察了query向量和候选向量在向量空间的语义距离,没有考虑query文本和候选文本其他方面的语义关系,比如上下文信息、句法结构等,而rerank模型有机会通过衡量query文本和候选文本之间更丰富的语义关系实现更精细的语义匹配。
- 场景适配:通过自训练rerank模型来进行精排,可以按照特定需求做进一步排序,从而提升QAG在特定应用场景下的表现。
二阶段检索
二阶段检索(Two-Stage Retrieval),即整个检索过程由原本的检索阶段和新增的精排阶段组成。很明显,这种组合方式能最大化利用向量库的检索速度,同时也能保证检索的效果,因而在RAG中广泛采用:检索过程使用基于向量的检索算法,精排过程使用rerank模型。Rerank模型一般基于双编码器(dual-encoder)架构,可以同时encode问题和知识库语料,从而进一步度量两者之间的语义相似度。
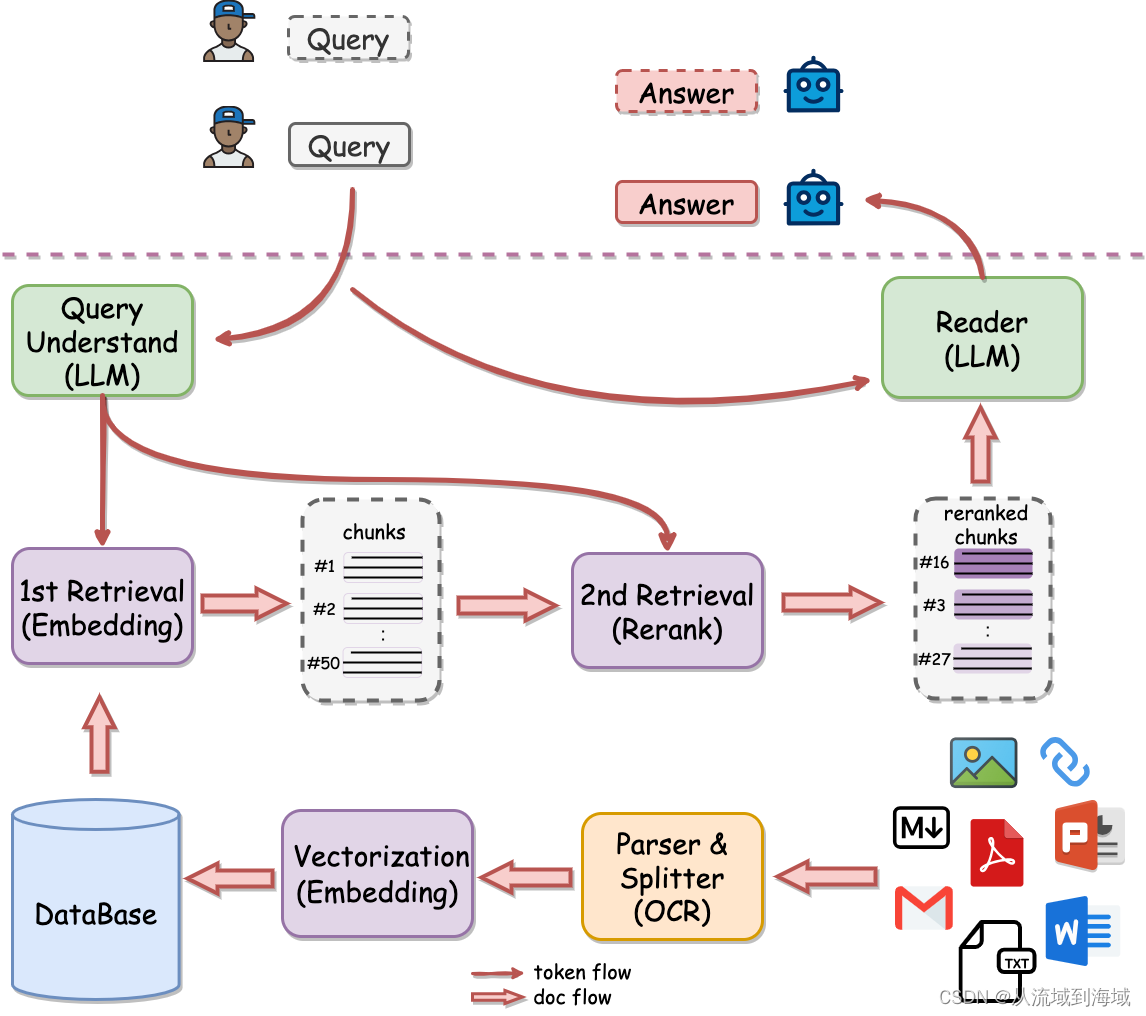
网易有道开源的QAnything采用流程的就是两阶段检索,可以理解为RAG with Rerank:

相似度匹配
Rerank
Question
从向量库或其他存储召回的相关chunk list
提示词
精排chunk list
LLM
Answer
Rerank模型
Rerank模型效果公认效果比较好的是一家AI独角兽cohere发布的cohere rerank:https://cohere.com/rerank,不过该模型是一个闭源商用模型,个人使用有一定的免费额度。
国内中文开源rerank模型中效果比较好的有BAAI的bge系列模型(和这家公司的开源的embedding模型是同一个模型系列):
Model | Base model | Language | layerwise | feature |
|---|---|---|---|---|
BAAI/bge-reranker-base | xlm-roberta-base | Chinese and English | - | Lightweight reranker model, easy to deploy, with fast inference. |
BAAI/bge-reranker-large | xlm-roberta-large | Chinese and English | - | Lightweight reranker model, easy to deploy, with fast inference. |
BAAI/bge-reranker-v2-m3 | bge-m3 | Multilingual | - | Lightweight reranker model, possesses strong multilingual capabilities, easy to deploy, with fast inference. |
BAAI/bge-reranker-v2-gemma | gemma-2b | Multilingual | - | Suitable for multilingual contexts, performs well in both English proficiency and multilingual capabilities. |
BAAI/bge-reranker-v2-minicpm-layerwise | MiniCPM-2B-dpo-bf16 | Multilingual | 8-40 | Suitable for multilingual contexts, performs well in both English and Chinese proficiency, allows freedom to select layers for output, facilitating accelerated inference. |
详见:https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/llm_reranker
模型可以在hugging face上下载使用:https://huggingface.co/BAAI/bge-reranker-large#model-list