[kernel] 带着问题看源码 —— 进程 ID 是如何分配的
[kernel] 带着问题看源码 —— 进程 ID 是如何分配的

前言
在《[apue] 进程控制那些事儿 》一文中,曾提到进程 ID 并不是唯一的,在整个系统运行期间一个进程 ID 可能会出现好多次。
> ./pid
fork and exec child 18687
[18687] child running
wait child 18687 return 0
fork and exec child 18688
[18688] child running
wait child 18688 return 0
fork and exec child 18689
...
wait child 18683 return 0
fork and exec child 18684
[18684] child running
wait child 18684 return 0
fork and exec child 18685
[18685] child running
wait child 18685 return 0
fork and exec child 18687
[18687] child running
wait child 18687 return 0
duplicated pid find: 18687, total 31930, elapse 8如果一直不停的 fork 子进程,在 Linux 上大约 8 秒就会得到重复的 pid,在 macOS 上大约是一分多钟。
...
[32765] child running
wait child 32765 return 0
fork and exec child 32766
[32766] child running
wait child 32766 return 0
fork and exec child 32767
[32767] child running
wait child 32767 return 0
fork and exec child 300
[300] child running
wait child 300 return 0
fork and exec child 313
[313] child running
wait child 313 return 0
fork and exec child 314
[314] child running
wait child 314 return 0
...并且在 Linux 上 pid 的分配范围是 [300, 32768),约 3W 个;在 macOS 上是 [100,99999),约 10W 个。
为何会产生这种差异?Linux 上是如何检索并分配空闲 pid 的?带着这个问题,找出系统对应的内核源码看个究竟。
源码分析
和《[kernel] 带着问题看源码 —— setreuid 何时更新 saved-set-uid (SUID)》一样,这里使用 bootlin 查看内核 3.10.0 版本源码,关于 bootlin 的简单介绍也可以参考那篇文章。
进程 ID 是在 fork 时分配的,所以先搜索 sys_fork:
整个搜索过程大概是 sys_fork -> do_fork -> copy_process -> alloc_pid -> alloc_pidmap,下面分别说明。
copy_process
sys_fork & do_fork 都比较简单,其中 do_fork 主要调用 copy_process 复制进程内容,这个函数很长,直接搜索关键字 pid :
查看代码
/*
* This creates a new process as a copy of the old one,
* but does not actually start it yet.
*
* It copies the registers, and all the appropriate
* parts of the process environment (as per the clone
* flags). The actual kick-off is left to the caller.
*/
static struct task_struct *copy_process(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *child_tidptr,
struct pid *pid,
int trace)
{
int retval;
struct task_struct *p;
...
/* copy all the process information */
retval = copy_semundo(clone_flags, p);
if (retval)
goto bad_fork_cleanup_audit;
retval = copy_files(clone_flags, p);
if (retval)
goto bad_fork_cleanup_semundo;
retval = copy_fs(clone_flags, p);
if (retval)
goto bad_fork_cleanup_files;
retval = copy_sighand(clone_flags, p);
if (retval)
goto bad_fork_cleanup_fs;
retval = copy_signal(clone_flags, p);
if (retval)
goto bad_fork_cleanup_sighand;
retval = copy_mm(clone_flags, p);
if (retval)
goto bad_fork_cleanup_signal;
retval = copy_namespaces(clone_flags, p);
if (retval)
goto bad_fork_cleanup_mm;
retval = copy_io(clone_flags, p);
if (retval)
goto bad_fork_cleanup_namespaces;
retval = copy_thread(clone_flags, stack_start, stack_size, p);
if (retval)
goto bad_fork_cleanup_io;
if (pid != &init_struct_pid) {
retval = -ENOMEM;
pid = alloc_pid(p->nsproxy->pid_ns);
if (!pid)
goto bad_fork_cleanup_io;
}
p->pid = pid_nr(pid);
p->tgid = p->pid;
...
if (likely(p->pid)) {
ptrace_init_task(p, (clone_flags & CLONE_PTRACE) || trace);
if (thread_group_leader(p)) {
if (is_child_reaper(pid)) {
ns_of_pid(pid)->child_reaper = p;
p->signal->flags |= SIGNAL_UNKILLABLE;
}
p->signal->leader_pid = pid;
p->signal->tty = tty_kref_get(current->signal->tty);
attach_pid(p, PIDTYPE_PGID, task_pgrp(current));
attach_pid(p, PIDTYPE_SID, task_session(current));
list_add_tail(&p->sibling, &p->real_parent->children);
list_add_tail_rcu(&p->tasks, &init_task.tasks);
__this_cpu_inc(process_counts);
}
attach_pid(p, PIDTYPE_PID, pid);
nr_threads++;
}
...
return p;
bad_fork_free_pid:
if (pid != &init_struct_pid)
free_pid(pid);
bad_fork_cleanup_io:
if (p->io_context)
exit_io_context(p);
bad_fork_cleanup_namespaces:
exit_task_namespaces(p);
bad_fork_cleanup_mm:
if (p->mm)
mmput(p->mm);
bad_fork_cleanup_signal:
if (!(clone_flags & CLONE_THREAD))
free_signal_struct(p->signal);
bad_fork_cleanup_sighand:
__cleanup_sighand(p->sighand);
bad_fork_cleanup_fs:
exit_fs(p); /* blocking */
bad_fork_cleanup_files:
exit_files(p); /* blocking */
bad_fork_cleanup_semundo:
exit_sem(p);
bad_fork_cleanup_audit:
audit_free(p);
bad_fork_cleanup_policy:
perf_event_free_task(p);
if (clone_flags & CLONE_THREAD)
threadgroup_change_end(current);
cgroup_exit(p, 0);
delayacct_tsk_free(p);
module_put(task_thread_info(p)->exec_domain->module);
bad_fork_cleanup_count:
atomic_dec(&p->cred->user->processes);
exit_creds(p);
bad_fork_free:
free_task(p);
fork_out:
return ERR_PTR(retval);
}copy_process 的核心就是各种资源的拷贝,表现为 copy_xxx 函数的调用,如果有对应的 copy 函数失败了,会 goto 到整个函数末尾的 bad_fork_cleanup_xxx 标签进行清理,copy 调用与清理顺序是相反的,保证路径上的所有资源能得到正确释放。
在 copy_xxx 调用的末尾,搜到了一段与 pid 分配相关的代码:
if (pid != &init_struct_pid) {
retval = -ENOMEM;
pid = alloc_pid(p->nsproxy->pid_ns);
if (!pid)
goto bad_fork_cleanup_io;
}
p->pid = pid_nr(pid);
p->tgid = p->pid;首先判断进程不是 init 进程才给分配 pid (参数 pid 在 do_fork 调用 copy_process 时设置为 NULL,所以这里 if 条件为 true 可以进入),然后通过 alloc_pid 为进程分配新的 pid。
在继续分析 alloc_pid 之前,先把搜索到的另一段包含 pid 代码浏览下:
if (likely(p->pid)) {
ptrace_init_task(p, (clone_flags & CLONE_PTRACE) || trace);
if (thread_group_leader(p)) {
if (is_child_reaper(pid)) {
ns_of_pid(pid)->child_reaper = p;
p->signal->flags |= SIGNAL_UNKILLABLE;
}
p->signal->leader_pid = pid;
p->signal->tty = tty_kref_get(current->signal->tty);
attach_pid(p, PIDTYPE_PGID, task_pgrp(current));
attach_pid(p, PIDTYPE_SID, task_session(current));
list_add_tail(&p->sibling, &p->real_parent->children);
list_add_tail_rcu(&p->tasks, &init_task.tasks);
__this_cpu_inc(process_counts);
}
attach_pid(p, PIDTYPE_PID, pid);
nr_threads++;
}如果 pid 分配成功,将它们设置到进程结构中以便生效,主要工作在 attach_pid,限于篇幅就不深入研究了。
alloc_pid
代码不长,就不删减了:
查看代码
struct pid *alloc_pid(struct pid_namespace *ns)
{
struct pid *pid;
enum pid_type type;
int i, nr;
struct pid_namespace *tmp;
struct upid *upid;
pid = kmem_cache_alloc(ns->pid_cachep, GFP_KERNEL);
if (!pid)
goto out;
tmp = ns;
pid->level = ns->level;
for (i = ns->level; i >= 0; i--) {
nr = alloc_pidmap(tmp);
if (nr < 0)
goto out_free;
pid->numbers[i].nr = nr;
pid->numbers[i].ns = tmp;
tmp = tmp->parent;
}
if (unlikely(is_child_reaper(pid))) {
if (pid_ns_prepare_proc(ns))
goto out_free;
}
get_pid_ns(ns);
atomic_set(&pid->count, 1);
for (type = 0; type < PIDTYPE_MAX; ++type)
INIT_HLIST_HEAD(&pid->tasks[type]);
upid = pid->numbers + ns->level;
spin_lock_irq(&pidmap_lock);
if (!(ns->nr_hashed & PIDNS_HASH_ADDING))
goto out_unlock;
for ( ; upid >= pid->numbers; --upid) {
hlist_add_head_rcu(&upid->pid_chain,
&pid_hash[pid_hashfn(upid->nr, upid->ns)]);
upid->ns->nr_hashed++;
}
spin_unlock_irq(&pidmap_lock);
out:
return pid;
out_unlock:
spin_unlock_irq(&pidmap_lock);
out_free:
while (++i <= ns->level)
free_pidmap(pid->numbers + i);
kmem_cache_free(ns->pid_cachep, pid);
pid = NULL;
goto out;
}代码不长但是看得云里雾里,查找了一些相关资料,3.10 内核为了支持容器,通过各种 namespace 做资源隔离,与 pid 相关的就是 pid_namespace 啦。这东西还可以嵌套、还可以对上层可见,所以做的很复杂,可以开一个单独的文章去讲它了。这里为了不偏离主题,暂时搁置,直接看 alloc_pidmap 完事儿,感兴趣的可以参考附录 6。
alloc_pidmap
到这里才涉及到本文核心,每一行都很重要,就不做删减了:
static int alloc_pidmap(struct pid_namespace *pid_ns)
{
int i, offset, max_scan, pid, last = pid_ns->last_pid;
struct pidmap *map;
pid = last + 1;
if (pid >= pid_max)
pid = RESERVED_PIDS;
offset = pid & BITS_PER_PAGE_MASK;
map = &pid_ns->pidmap[pid/BITS_PER_PAGE];
/*
* If last_pid points into the middle of the map->page we
* want to scan this bitmap block twice, the second time
* we start with offset == 0 (or RESERVED_PIDS).
*/
max_scan = DIV_ROUND_UP(pid_max, BITS_PER_PAGE) - !offset;
for (i = 0; i <= max_scan; ++i) {
if (unlikely(!map->page)) {
void *page = kzalloc(PAGE_SIZE, GFP_KERNEL);
/*
* Free the page if someone raced with us
* installing it:
*/
spin_lock_irq(&pidmap_lock);
if (!map->page) {
map->page = page;
page = NULL;
}
spin_unlock_irq(&pidmap_lock);
kfree(page);
if (unlikely(!map->page))
break;
}
if (likely(atomic_read(&map->nr_free))) {
for ( ; ; ) {
if (!test_and_set_bit(offset, map->page)) {
atomic_dec(&map->nr_free);
set_last_pid(pid_ns, last, pid);
return pid;
}
offset = find_next_offset(map, offset);
if (offset >= BITS_PER_PAGE)
break;
pid = mk_pid(pid_ns, map, offset);
if (pid >= pid_max)
break;
}
}
if (map < &pid_ns->pidmap[(pid_max-1)/BITS_PER_PAGE]) {
++map;
offset = 0;
} else {
map = &pid_ns->pidmap[0];
offset = RESERVED_PIDS;
if (unlikely(last == offset))
break;
}
pid = mk_pid(pid_ns, map, offset);
}
return -1;
}Linux 实现 pid 快速检索的关键,就是通过位图这种数据结构,在系统页大小为 4K 的情况下,一个页就可以表示 4096 * 8 = 32768 个 ID,这个数据刚好是《[apue] 进程控制那些事儿 》中实测的最大进程 ID 值,看起来 Linux 只用一个内存页就解决了 pid 的快速检索、分配、释放等问题,兼顾了性能与准确性,不得不说确实精妙。
pid 范围
继续进行之前,先确定几个常量的值:
/* PAGE_SHIFT determines the page size */
#define PAGE_SHIFT 12
#define PAGE_SIZE (_AC(1,UL) << PAGE_SHIFT)
#define PAGE_MASK (~(PAGE_SIZE-1))
/*
* This controls the default maximum pid allocated to a process
*/
#define PID_MAX_DEFAULT (CONFIG_BASE_SMALL ? 0x1000 : 0x8000)
/*
* A maximum of 4 million PIDs should be enough for a while.
* [NOTE: PID/TIDs are limited to 2^29 ~= 500+ million, see futex.h.]
*/
#define PID_MAX_LIMIT (CONFIG_BASE_SMALL ? PAGE_SIZE * 8 : \
(sizeof(long) > 4 ? 4 * 1024 * 1024 : PID_MAX_DEFAULT))
/*
* Define a minimum number of pids per cpu. Heuristically based
* on original pid max of 32k for 32 cpus. Also, increase the
* minimum settable value for pid_max on the running system based
* on similar defaults. See kernel/pid.c:pidmap_init() for details.
*/
#define PIDS_PER_CPU_DEFAULT 1024
#define PIDS_PER_CPU_MIN 8
#define BITS_PER_PAGE (PAGE_SIZE * 8)
#define BITS_PER_PAGE_MASK (BITS_PER_PAGE-1)
#define PIDMAP_ENTRIES ((PID_MAX_LIMIT+BITS_PER_PAGE-1)/BITS_PER_PAGE)
int pid_max = PID_MAX_DEFAULT;
#define RESERVED_PIDS 300
int pid_max_min = RESERVED_PIDS + 1;
int pid_max_max = PID_MAX_LIMIT;它们受页大小、系统位数、CONFIG_BASE_SMALL 宏的影响,宏仅用于内存受限系统,可以理解为总为 0。列表看下 4K、8K 页大小与 32 位、64 位系统场景下各个常量的取值:
PAGE_SIZE | BITS_PER_PAGE | PID_MAX_DEFAULT | PID_MAX_LIMIT | PIDMAP_ENTRIES (实际占用) | |
|---|---|---|---|---|---|
32 位 4K 页面 | 4096 | 32768 | 32768 | 32768 | 1 |
64 位 4K 页面 | 4096 | 32768 | 32768 | 4194304 | 128 |
64 位 8K 页面 | 8192 | 65536 | 32768 | 4194304 | 64 |
结论:
- 32 位系统 pid 上限为 32768
- 64 位系统 pid 上限为 4194304 (400 W+)
- 32 位系统只需要 1 个页面就可以存储所有 pid
- 64 位系统需要 128 个页面存储所有 pid,不过具体使用几个页面视 PAGE_SIZE 大小而定
搜索 pid_max 全局变量的引用,发现还有下面的逻辑:
void __init pidmap_init(void)
{
/* Veryify no one has done anything silly */
BUILD_BUG_ON(PID_MAX_LIMIT >= PIDNS_HASH_ADDING);
/* bump default and minimum pid_max based on number of cpus */
pid_max = min(pid_max_max, max_t(int, pid_max,
PIDS_PER_CPU_DEFAULT * num_possible_cpus()));
pid_max_min = max_t(int, pid_max_min,
PIDS_PER_CPU_MIN * num_possible_cpus());
pr_info("pid_max: default: %u minimum: %u\n", pid_max, pid_max_min);
init_pid_ns.pidmap[0].page = kzalloc(PAGE_SIZE, GFP_KERNEL);
/* Reserve PID 0. We never call free_pidmap(0) */
set_bit(0, init_pid_ns.pidmap[0].page);
atomic_dec(&init_pid_ns.pidmap[0].nr_free);
init_pid_ns.nr_hashed = PIDNS_HASH_ADDING;
init_pid_ns.pid_cachep = KMEM_CACHE(pid,
SLAB_HWCACHE_ALIGN | SLAB_PANIC);
}重点看 pid_max & pid_max_min,它们会受系统 CPU 核数影响,对于我测试机:
> uname -p
x86_64
> getconf PAGE_SIZE
4096
> cat /proc/cpuinfo | grep 'processor' | wc -l
2
> cat /proc/cpuinfo | grep 'cpu cores' | wc -l
2为 64 位系统,页大小 4K,共有 2 * 2 = 4 个核,PID_MAX_LIMIT = 4194304、PID_MAX_DEFAULT = 32768、pid_max_cores (按核数计算的 PID_MAX 上限) 为 1024 * 4 = 4096、pid_min_cores (按核数计算的 PID_MAX 下限) 为 8 *4= 32;初始化时 pid_max = 32768、pid_max_max = 4194304、pid_max_min = 301;经过 pidmap_init 后,pid_max 被设置为 min (pid_max_max, max (pid_max, pid_max_cores)) = 32768、pid_max_min 被设置为 max (pid_max_min, pid_min_cores) = 301。
这里有一行 pr_info 打印了最终的 pid_max & pid_max_min 的值,通过 dmesg 查看:
> dmesg | grep pid_max
[ 0.621979] pid_max: default: 32768 minimum: 301与预期相符。
CPU 核数超过多少时会影响 pid_max 上限?简单计算一下: 32768 / 1024 = 32。当总核数超过 32 时,pid_max 的上限才会超过 32768;CPU 核数超过多少时会影响 pid_max 下限?301 / 4 = 75,当总核数超过 75 时,pid_max 的下限才会超过 301。下表列出了 64 位系统 4K 页面不同核数对应的 pid max 的上下限值:
pid_max_cores | pid_min_cores | pid_max | pid_max_min | PIDMAP_ENTRIES (实际占用) | |
|---|---|---|---|---|---|
32 核 | 32768 | 128 | 32768 | 301 | 1 |
64 核 | 65536 | 256 | 65536 | 301 | 2 |
128 核 | 131072 | 512 | 131072 | 512 | 4 |
可见虽然 pid_max 能到 400W+,实际根据核数计算的话没有那么多,pidmap 数组仅占用个位数的槽位。
另外 pid_max 也可以通过 proc 文件系统调整:
> su
Password:
$ echo 131072 > /proc/sys/kernel/pid_max
$ cat /proc/sys/kernel/pid_max
131072
$ suspend
[1]+ Stopped su
> ./pid
...
[20004] child running
wait child 20004 return 0
duplicated pid find: 20004, total 129344, elapse 74经过测试,未调整前使用测试程序仅能遍历 31930 个 pid,调整到 131072 后可以遍历 129344 个 pid,看来是实时生效了。
搜索相关的代码,发现在 kernel/sysctl.c 中有如下逻辑:
static struct ctl_table kern_table[] = {
...
{
.procname= "pid_max",
.data= &pid_max,
.maxlen= sizeof (int),
.mode= 0644,
.proc_handler= proc_dointvec_minmax,
.extra1= &pid_max_min,
.extra2= &pid_max_max,
},
...
{ }
};看起来 proc 文件系统是搭建在 ctl_table 数组之上,后者直接包含了要被修改的全局变量地址,实现"实时"修改。而且,ctl_table 还通过 pid_max_min & pid_max_max 的值标识了修改的范围,如果输入超出了范围将返回错误:
$ echo 300 > /proc/sys/kernel/pid_max
bash: echo: write error: Invalid argument
$ echo 4194305 > /proc/sys/kernel/pid_max
bash: echo: write error: Invalid argument可以实时修改 pid_max 的另外一个原因还与 PIDMAP_ENTRIES 有关,详情见下节。
最后补充一点,pidmap_init 是在 start_kernel 中调用的,后者又被 BIOS setup 程序所调用,整体调用链是这样:
boot/head.S -> start_kernel -> pidmap_init
start_kernel 中就是一堆 xxx_init 初始化调用:
查看代码
asmlinkage void __init start_kernel(void)
{
char * command_line;
extern const struct kernel_param __start___param[], __stop___param[];
/*
* Need to run as early as possible, to initialize the
* lockdep hash:
*/
lockdep_init();
smp_setup_processor_id();
debug_objects_early_init();
/*
* Set up the the initial canary ASAP:
*/
boot_init_stack_canary();
cgroup_init_early();
local_irq_disable();
early_boot_irqs_disabled = true;
/*
* Interrupts are still disabled. Do necessary setups, then
* enable them
*/
boot_cpu_init();
page_address_init();
pr_notice("%s", linux_banner);
setup_arch(&command_line);
mm_init_owner(&init_mm, &init_task);
mm_init_cpumask(&init_mm);
setup_command_line(command_line);
setup_nr_cpu_ids();
setup_per_cpu_areas();
smp_prepare_boot_cpu();/* arch-specific boot-cpu hooks */
build_all_zonelists(NULL, NULL);
page_alloc_init();
pr_notice("Kernel command line: %s\n", boot_command_line);
parse_early_param();
parse_args("Booting kernel", static_command_line, __start___param,
__stop___param - __start___param,
-1, -1, &unknown_bootoption);
jump_label_init();
/*
* These use large bootmem allocations and must precede
* kmem_cache_init()
*/
setup_log_buf(0);
pidhash_init();
vfs_caches_init_early();
sort_main_extable();
trap_init();
mm_init();
/*
* Set up the scheduler prior starting any interrupts (such as the
* timer interrupt). Full topology setup happens at smp_init()
* time - but meanwhile we still have a functioning scheduler.
*/
sched_init();
/*
* Disable preemption - early bootup scheduling is extremely
* fragile until we cpu_idle() for the first time.
*/
preempt_disable();
if (WARN(!irqs_disabled(), "Interrupts were enabled *very* early, fixing it\n"))
local_irq_disable();
idr_init_cache();
perf_event_init();
rcu_init();
tick_nohz_init();
radix_tree_init();
/* init some links before init_ISA_irqs() */
early_irq_init();
init_IRQ();
tick_init();
init_timers();
hrtimers_init();
softirq_init();
timekeeping_init();
time_init();
profile_init();
call_function_init();
WARN(!irqs_disabled(), "Interrupts were enabled early\n");
early_boot_irqs_disabled = false;
local_irq_enable();
kmem_cache_init_late();
/*
* HACK ALERT! This is early. We're enabling the console before
* we've done PCI setups etc, and console_init() must be aware of
* this. But we do want output early, in case something goes wrong.
*/
console_init();
if (panic_later)
panic(panic_later, panic_param);
lockdep_info();
/*
* Need to run this when irqs are enabled, because it wants
* to self-test [hard/soft]-irqs on/off lock inversion bugs
* too:
*/
locking_selftest();
#ifdef CONFIG_BLK_DEV_INITRD
if (initrd_start && !initrd_below_start_ok &&
page_to_pfn(virt_to_page((void *)initrd_start)) < min_low_pfn) {
pr_crit("initrd overwritten (0x%08lx < 0x%08lx) - disabling it.\n",
page_to_pfn(virt_to_page((void *)initrd_start)),
min_low_pfn);
initrd_start = 0;
}
#endif
page_cgroup_init();
debug_objects_mem_init();
kmemleak_init();
setup_per_cpu_pageset();
numa_policy_init();
if (late_time_init)
late_time_init();
sched_clock_init();
calibrate_delay();
pidmap_init();
anon_vma_init();
#ifdef CONFIG_X86
if (efi_enabled(EFI_RUNTIME_SERVICES))
efi_enter_virtual_mode();
#endif
thread_info_cache_init();
cred_init();
fork_init(totalram_pages);
proc_caches_init();
buffer_init();
key_init();
security_init();
dbg_late_init();
vfs_caches_init(totalram_pages);
signals_init();
/* rootfs populating might need page-writeback */
page_writeback_init();
#ifdef CONFIG_PROC_FS
proc_root_init();
#endif
cgroup_init();
cpuset_init();
taskstats_init_early();
delayacct_init();
check_bugs();
acpi_early_init(); /* before LAPIC and SMP init */
sfi_init_late();
if (efi_enabled(EFI_RUNTIME_SERVICES)) {
efi_late_init();
efi_free_boot_services();
}
ftrace_init();
/* Do the rest non-__init'ed, we're now alive */
rest_init();
}类似 Linux 0.11 中的 main。
pid 分配
先看看 pid 在 Linux 中是如何存放的:
struct pidmap {
atomic_t nr_free;
void *page;
};
struct pid_namespace {
...
struct pidmap pidmap[PIDMAP_ENTRIES];
int last_pid;
...
};做个简单说明:
- pidmap.page 指向分配的内存页
- pidmap.nr_free 表示空闲的 pid 数量,如果为零就表示分配满了,不必浪费时间检索
- pid_namespace.pidmap 数组用于存储多个 pidmap,数组大小是固定的,以 64 位 4K 页面计算是 128;实际并不分配这么多,与上一节中的 pid_max 有关,并且是在分配 pid 时才分配相关的页面,属于懒加载策略,这也是上一节可以实时修改 pid_max 值的原因之一
- pid_namespace.last_pid 用于记录上次分配位置,方便下次继续检索空闲 pid
下面进入代码。
初始化
pid = last + 1;
if (pid >= pid_max)
pid = RESERVED_PIDS;
offset = pid & BITS_PER_PAGE_MASK;
map = &pid_ns->pidmap[pid/BITS_PER_PAGE];函数开头,已经完成了下面的工作:
- 将起始检索位置设置为 last 的下个位置、达到最大位置时回卷 (pid)
- 确定起始 pid 所在页面 (map)
- 确定起始 pid 所在页中的位偏移 (offset)
这里简单补充一点位图的相关操作:
- pid / BITS_PER_PAGE:获取 bit 所在位图的索引,对于测试机这里总为 0 (只分配一个内存页);
- pid & BITS_PER_PAGE_MAX:获取 bit 在位图内部偏移,与操作相当于取余,而性能更好
经过处理,可使用 pid_ns->pidmap[map].page[offset] 定位这个 pid (注:page[offset] 是种形象的写法,表示页面中第 N 位,实际需要使用位操作宏)。
遍历页面
max_scan = DIV_ROUND_UP(pid_max, BITS_PER_PAGE) - !offset;
for (i = 0; i <= max_scan; ++i) {
if (unlikely(!map->page)) {
...
}
if (likely(atomic_read(&map->nr_free))) {
...
}
if (map < &pid_ns->pidmap[(pid_max-1)/BITS_PER_PAGE]) {
++map;
offset = 0;
} else {
map = &pid_ns->pidmap[0];
offset = RESERVED_PIDS;
if (unlikely(last == offset))
break;
}
pid = mk_pid(pid_ns, map, offset);
}做个简单说明:
- 外层 for 循环用来遍历 pidmap 数组,对于测试机遍历次数 max_scan == 1,会遍历两遍
- 第一遍是 (last_pid, max_pid)
- 第二遍是 (RESERVED_PIDS, last_pid]
- 保证即使 last_pid 位于页面中间,也能完整的遍历整个 bitmap
- 第一个 if 用于首次访问时分配内存页
- 第二个 if 用于当前 pidmap 内搜索空闲 pid
- 第三个 if 用于判断是否遍历到 pidmap 数组末尾。注意 map 是个 pidmap 指针,所以需要对比地址;
(pid_max-1)/BITS_PER_PAGE就是最后一个有效 pidmap 的索引- 若未超过末尾,递增 map 指向下一个 pidmap,重置 offset 为 0
- 若超过末尾,回卷 map 指向第一个 pidmap,offset 设置为 RESERVED_PIDS
- 若回卷后到了之前遍历的位置 (last),说明所有 pid 均已耗尽,退出外层 for 循环
- 根据新的位置生成 pid 继续上面的尝试
对于回卷后 offset = RESERVED_PIDS 有个疑问——是否设置为 pid_max_min 更为合理?否则打破了之前设置 pid_max_min 的努力,特别是当 CPU 核数大于 75 时,pid_max_min 是有可能超过 300 的。
列表考察下“不同的页面数” & “pid 是否位于页面第一个位置” (offset == 0) 对于多次遍历的影响:
PIDMAP_ENTRIES (实际占用) | pidmax | offset | max_scan | 遍历次数 | example | |||
|---|---|---|---|---|---|---|---|---|
1 | 32768 | 0 | 0 | 1 | 0 | - | - | - |
>0 | 1 | 2 | 0-rear,0-front | - | - | - | ||
2 | 65536 | 0 | 1 | 2 | 0,1 | 1,0 | - | - |
>0 | 2 | 3 | 0-rear,1,0-front | 1-rear,0,1-front | - | - | ||
4 | 131072 | 0 | 3 | 4 | 0,1,2,3 | 1,2,3,0 | 2,3,0,1 | 3,0,1,2 |
>0 | 4 | 5 | 0-rear,1,2,3,0-front | 1-rear,2.3,0,1-front | 2-rear,3,0,1,2-front | 3-rear,0,1,2,3-front | ||
表中根据页面数和 offset 推算出了 max_scan 的值,从而得到遍历次数,example 列每一子列都是一个独立的用例,其中:N-rear 表示第 N 页的后半部分,N-front 表示前半部分,不带后缀的就是整页遍历。逗号分隔的数字表示一个可能的页面遍历顺序。
从表中可以观察到,当 offset == 0 时,整个页面是从头到尾遍历的,不需要多一次遍历;而当 offset > 0 时,页面是从中间开始遍历的,需要多一次遍历。这就是代码 - !offset 蕴藏的奥妙:当 offset == 0 时会减去一次多余的遍历!
下面考察下第一次进入的场景 (以测试机为例):
/*
* PID-map pages start out as NULL, they get allocated upon
* first use and are never deallocated. This way a low pid_max
* value does not cause lots of bitmaps to be allocated, but
* the scheme scales to up to 4 million PIDs, runtime.
*/
struct pid_namespace init_pid_ns = {
.kref = {
.refcount = ATOMIC_INIT(2),
},
.pidmap = {
[ 0 ... PIDMAP_ENTRIES-1] = { ATOMIC_INIT(BITS_PER_PAGE), NULL }
},
.last_pid = 0,
.level = 0,
.child_reaper = &init_task,
.user_ns = &init_user_ns,
.proc_inum = PROC_PID_INIT_INO,
};
EXPORT_SYMBOL_GPL(init_pid_ns);last_pid 初始化为 0,所以初始 pid = 1,offset != 0,遍历次数为 2。不过因为是首次分配,找到第一个空闲的 pid 就会返回,不会真正遍历 2 次。这里我有个疑惑:空闲的 pid 会返回 < RESERVED_PIDS 的值吗?这与观察到的现象不符,看起来有什么地方设置了 last_pid,使其从 RESERVED_PIDS 开始,不过搜索整个库也没有找到与 RESERVED_PIDS、pid_max_min、last_pid 相关的代码,暂时存疑。
再考察运行中的情况,offset > 0,遍历次数仍然为 2,会先遍历后半部分,如没有找到空闲 pid,设置 offset = RESERVED_PIDS、同页面再进行第 2 次遍历,此时遍历前半部分,符合预期。
多页面的情况与此类似,就不再推理了。
页面分配
if (unlikely(!map->page)) {
void *page = kzalloc(PAGE_SIZE, GFP_KERNEL);
/*
* Free the page if someone raced with us
* installing it:
*/
spin_lock_irq(&pidmap_lock);
if (!map->page) {
map->page = page;
page = NULL;
}
spin_unlock_irq(&pidmap_lock);
kfree(page);
if (unlikely(!map->page))
break;
}之前讲过,页面采用懒加载策略,所以每次进来得先判断下内存页是否分配,如果未分配,调用 kzalloc 进行分配,注意在设置 map->page 时使用了自旋锁保证多线程安全性。若分配页面成功但设置失败,释放内存页面,直接使用别人分配好的页面;若页面分配失败,则直接中断外层 for 循环、失败退出。
页内遍历
if (likely(atomic_read(&map->nr_free))) {
for ( ; ; ) {
if (!test_and_set_bit(offset, map->page)) {
atomic_dec(&map->nr_free);
set_last_pid(pid_ns, last, pid);
return pid;
}
offset = find_next_offset(map, offset);
if (offset >= BITS_PER_PAGE)
break;
pid = mk_pid(pid_ns, map, offset);
if (pid >= pid_max)
break;
}
}检查 map->nr_free 字段,若大于 0 表示还有空闲 pid,进入页面查找,否则跳过。第一次分配页面时会将内容全部设置为 0,但 nr_free 是在另外的地方初始化的:
.pidmap = {
[ 0 ... PIDMAP_ENTRIES-1] = { ATOMIC_INIT(BITS_PER_PAGE), NULL }
},它将被设置为 BITS_PER_PAGE,对于 4K 页面就是 32768。接下来通过两个宏进行空闲位查找:test_and_set_bit & find_next_offset,前者是一个位操作宏,后者也差不多:
#define find_next_offset(map, off) \
find_next_zero_bit((map)->page, BITS_PER_PAGE, off)委托给 find_next_zero_bit,这个位操作函数。定义位于汇编语言中,太过底层没有贴上来,不过看名称应该能猜个七七八八。因为是整数位操作,可以使用一些类似 atomic 的手段保证多线程安全,所以这里没有施加额外的锁,例如对于 test_and_set_bit 来说,返回 0 就是设置成功,那就能保证同一时间没有其它线程在设置同一个比特位,是线程安全的;反之,返回 1 表示已有其它线程占了这个坑,咱们就只能继续“负重前行”了~
对于占坑成功的线程,atomic_dec 减少空闲 nr_free 数,注意在占坑和减少计数之间还是有其它线程插进来的可能,这会导致插入线程以为有坑位实际上没有,从而白遍历一遍。不过这样做不会产生错误结果,且这个间隔也比较短,插进来的机率并不高,可以容忍。
在返回新 pid 之前记得更新 pid_namespace.last_pid:
/*
* We might be racing with someone else trying to set pid_ns->last_pid
* at the pid allocation time (there's also a sysctl for this, but racing
* with this one is OK, see comment in kernel/pid_namespace.c about it).
* We want the winner to have the "later" value, because if the
* "earlier" value prevails, then a pid may get reused immediately.
*
* Since pids rollover, it is not sufficient to just pick the bigger
* value. We have to consider where we started counting from.
*
* 'base' is the value of pid_ns->last_pid that we observed when
* we started looking for a pid.
*
* 'pid' is the pid that we eventually found.
*/
static void set_last_pid(struct pid_namespace *pid_ns, int base, int pid)
{
int prev;
int last_write = base;
do {
prev = last_write;
last_write = cmpxchg(&pid_ns->last_pid, prev, pid);
} while ((prev != last_write) && (pid_before(base, last_write, pid)));
}
/*
* If we started walking pids at 'base', is 'a' seen before 'b'?
*/
static int pid_before(int base, int a, int b)
{
/*
* This is the same as saying
*
* (a - base + MAXUINT) % MAXUINT < (b - base + MAXUINT) % MAXUINT
* and that mapping orders 'a' and 'b' with respect to 'base'.
*/
return (unsigned)(a - base) < (unsigned)(b - base);
}更新也得考虑线程竞争的问题:这里在判断 compare_exchange 的返回值之外,还判断了新的 last_pid (last_write) 和给定的 pid 参数哪个距离原 last_pid (base) 更远,只设置更远的那个,从而保证在竞争后,last_pid 能反应更真实的情况。
内层 for 是无穷循环且 offset 单调增长,需要一个结束条件,这就是 offset > BITS_PER_PAGE;另外一个条件是pid >= pid_max,这个主要用于 max_pid 不是整数页面的情况,例如 43 个 CPU 核对应的 pid_max = 44032,占用 2 个内存页且第二页并不完整 (44032 - 32768 = 11264,< 32768),此时就需要通过 pid 来终止内层遍历了。为此需要根据最新 offset 更新当前遍历的 pid:
static inline int mk_pid(struct pid_namespace *pid_ns,
struct pidmap *map, int off)
{
return (map - pid_ns->pidmap)*BITS_PER_PAGE + off;
}细心的读者可能发现了,对于 pid 位于页面中间的场景,回卷后第二次遍历该页面时,仍然是从头遍历到尾,没有在中间提前结束 (last_pid),多遍历了 N-rear 这部分。
对于这一点,我是这样理解的:这一点点浪费其实微不足道,多写几个 if 判断节约的 CPU 时间可能还补偿不了指令流水被打断造成的性能损失。
pid 释放
进程结束时释放 pid,由于之前说过的原因,Linux 支持容器需要对 pid 进行 namespace 隔离,导致这一块前期的逻辑有点偏离主题 (且没太看懂),就看看具体的 pid 释放过程得了:
static void free_pidmap(struct upid *upid)
{
int nr = upid->nr;
struct pidmap *map = upid->ns->pidmap + nr / BITS_PER_PAGE;
int offset = nr & BITS_PER_PAGE_MASK;
clear_bit(offset, map->page);
atomic_inc(&map->nr_free);
}还是经典的 nr / BITS_PER_PAGE 确认页面索引、nr & BITS_PER_PAGE_MASK 确认 pid 所在比特位偏移;一个 clear_bit 优雅的将比特位清零;一个 atomic_inc 优雅的增加页面剩余空闲 pid 数。简洁明了,毋庸多言。
内核小知识
第一次看内核源码,发现有很多有趣的东西,下面一一说明。
likely & unlikely
很多 if 条件中都有这个,不清楚是干什么的,翻来定义看一看:
# ifndef likely
# define likely(x) (__builtin_expect(!!(x), 1))
# endif
# ifndef unlikely
# define unlikely(x) (__builtin_expect(!!(x), 0))
# endif条件 x 使用 !! 处理后将由整数变为 0 或 1,然后传递给 __builtin_expect,likely 第二个参数为 1,unlikely 为 0。经过一翻 google,这个是编译器 (gcc) 提供的分支预测优化函数:
long __builtin_expect(long exp, long c);第一个参数是条件;第二个是期望值,必需是编译期常量;函数返回值为 exp 参数。GCC v2.96 引入,用来帮助编译器生成汇编代码,如果期望值为 1,编译器将条件失败放在 jmp 语句;如果期望值为 0,编译器将条件成功放在 jmp 语句。实现更小概率的指令跳转,这样做的目的是提升 CPU 指令流水成功率,从而提升性能。
if (unlikely(!map->page)) {
void *page = kzalloc(PAGE_SIZE, GFP_KERNEL);
/*
* Free the page if someone raced with us
* installing it:
*/
spin_lock_irq(&pidmap_lock);
if (!map->page) {
map->page = page;
page = NULL;
}
spin_unlock_irq(&pidmap_lock);
kfree(page);
if (unlikely(!map->page))
break;
}
if (likely(atomic_read(&map->nr_free))) {
for ( ; ; ) {
if (!test_and_set_bit(offset, map->page)) {
atomic_dec(&map->nr_free);
set_last_pid(pid_ns, last, pid);
return pid;
}
offset = find_next_offset(map, offset);
if (offset >= BITS_PER_PAGE)
break;
pid = mk_pid(pid_ns, map, offset);
if (pid >= pid_max)
break;
}
}以页面分配和页内遍历为例,这里有 1 个 likely 和 2 个 unlikely,分别说明:
- 第一个 unlikely 用来判断页面是否为空,除第一次进入外,其它情况下此页面都是已分配状态,所以
!map->page倾向于 0,这里使用 unlikely; - 第二个 unlikely 用来判断页面是否分配失败,正常情况下
!map->page倾向于 0,这里使用 unlikely; - 第三个 likely 用来判断页面是否已分配完毕,正常情况下
atomic_read(&map->nr_free)结果倾向于 > 0,这里使用 likely。
总结一下,likely & unlikely 并不改变条件结果本身,在判断是否进入条件时完全可以忽略它们!如果大部分场景进入条件,使用 likely;如果大多数场景不进入条件,使用 unlikely。
为何编译器不能自己做这个工作?深入想想,代码只有在执行时才能知道哪些条件经常返回 true,而这已经离开编译型语言生成机器代码太远了,所以需要程序员提前告知编译器怎么生成代码。对于解释执行的语言,这方面可能稍好一些。
最后,如果程序员也不清楚哪种场景占优,最好就留空什么也不添加,千万不要画蛇添足。
pr_info 输出
这个是在 pidmap_init 中遇到的,看看定义:
#ifndef pr_fmt
#define pr_fmt(fmt) fmt
#endif
#define pr_emerg(fmt, ...) \
printk(KERN_EMERG pr_fmt(fmt), ##__VA_ARGS__)
#define pr_alert(fmt, ...) \
printk(KERN_ALERT pr_fmt(fmt), ##__VA_ARGS__)
#define pr_crit(fmt, ...) \
printk(KERN_CRIT pr_fmt(fmt), ##__VA_ARGS__)
#define pr_err(fmt, ...) \
printk(KERN_ERR pr_fmt(fmt), ##__VA_ARGS__)
#define pr_warning(fmt, ...) \
printk(KERN_WARNING pr_fmt(fmt), ##__VA_ARGS__)
#define pr_warn pr_warning
#define pr_notice(fmt, ...) \
printk(KERN_NOTICE pr_fmt(fmt), ##__VA_ARGS__)
#define pr_info(fmt, ...) \
printk(KERN_INFO pr_fmt(fmt), ##__VA_ARGS__)
#define pr_cont(fmt, ...) \
printk(KERN_CONT fmt, ##__VA_ARGS__)原来就是 printk 的包装,pr_info 使用的级别是 KERN_INFO。下面是网上搜到的 printk 分派图:
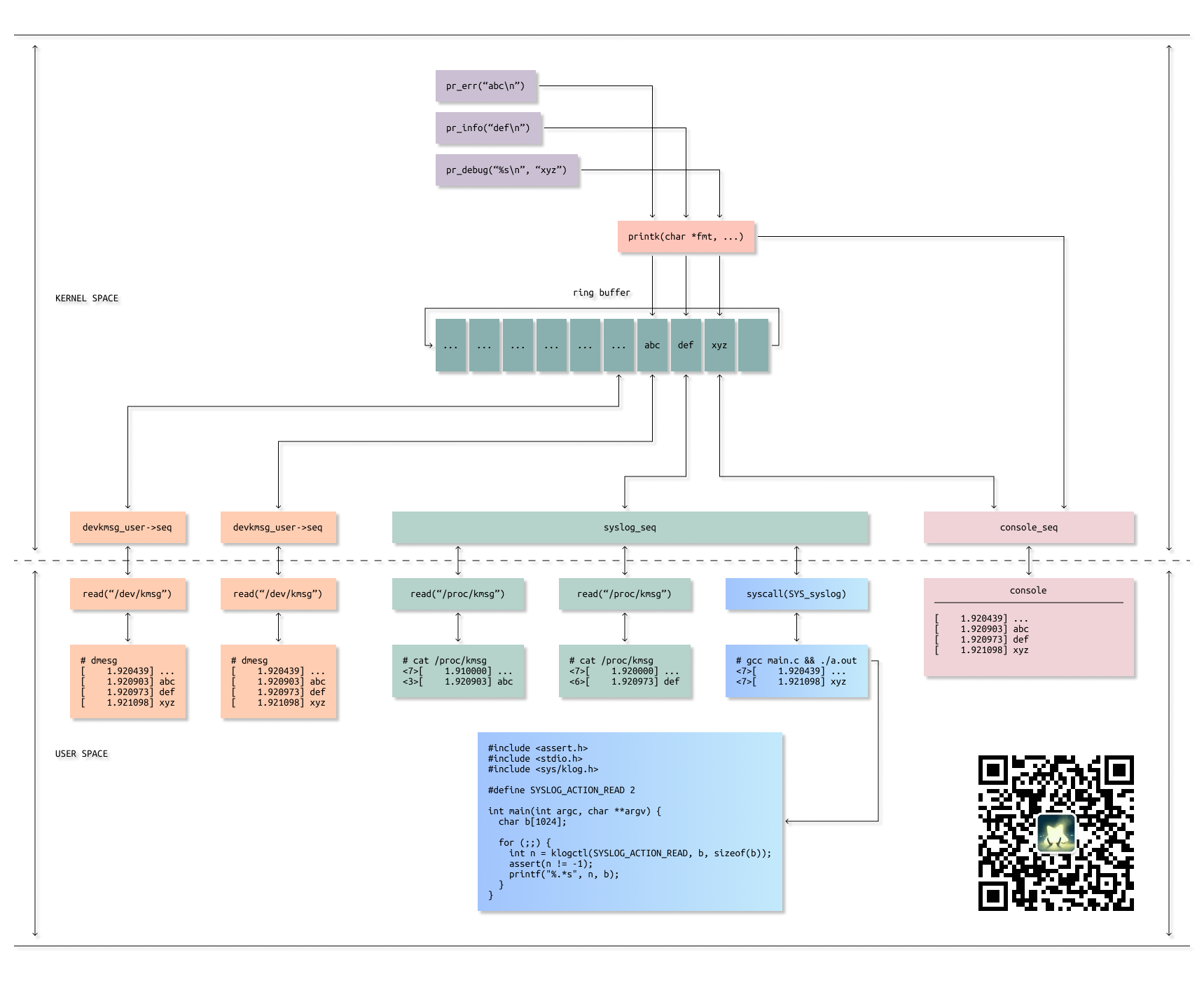
打到 console 的是系统初始化时在屏幕输出的,一闪而过不太容易看,所以这里是使用基于 /dev/kmsg 的方式,具体点就是直接使用 dmesg:
$ dmesg | grep -C 10 pid_max
[ 0.000000] Hierarchical RCU implementation.
[ 0.000000] RCU restricting CPUs from NR_CPUS=5120 to nr_cpu_ids=2.
[ 0.000000] NR_IRQS:327936 nr_irqs:440 0
[ 0.000000] Console: colour VGA+ 80x25
[ 0.000000] console [tty0] enabled
[ 0.000000] console [ttyS0] enabled
[ 0.000000] allocated 436207616 bytes of page_cgroup
[ 0.000000] please try 'cgroup_disable=memory' option if you don't want memory cgroups
[ 0.000000] tsc: Detected 2394.374 MHz processor
[ 0.620597] Calibrating delay loop (skipped) preset value.. 4788.74 BogoMIPS (lpj=2394374)
[ 0.621979] pid_max: default: 32768 minimum: 301
[ 0.622732] Security Framework initialized
[ 0.623423] SELinux: Initializing.
[ 0.624063] SELinux: Starting in permissive mode
[ 0.624064] Yama: becoming mindful.
[ 0.625585] Dentry cache hash table entries: 2097152 (order: 12, 16777216 bytes)
[ 0.629691] Inode-cache hash table entries: 1048576 (order: 11, 8388608 bytes)
[ 0.632167] Mount-cache hash table entries: 32768 (order: 6, 262144 bytes)
[ 0.633123] Mountpoint-cache hash table entries: 32768 (order: 6, 262144 bytes)
[ 0.634607] Initializing cgroup subsys memory
[ 0.635326] Initializing cgroup subsys devices也可以直接 cat /dev/kmsg:
$ cat /dev/kmsg | grep -C 10 pid_max
6,144,0,-;Hierarchical RCU implementation.
6,145,0,-;\x09RCU restricting CPUs from NR_CPUS=5120 to nr_cpu_ids=2.
6,146,0,-;NR_IRQS:327936 nr_irqs:440 0
6,147,0,-;Console: colour VGA+ 80x25
6,148,0,-;console [tty0] enabled
6,149,0,-;console [ttyS0] enabled
6,150,0,-;allocated 436207616 bytes of page_cgroup
6,151,0,-;please try 'cgroup_disable=memory' option if you don't want memory cgroups
6,152,0,-;tsc: Detected 2394.374 MHz processor
6,153,620597,-;Calibrating delay loop (skipped) preset value.. 4788.74 BogoMIPS (lpj=2394374)
6,154,621979,-;pid_max: default: 32768 minimum: 301
6,155,622732,-;Security Framework initialized
6,156,623423,-;SELinux: Initializing.
7,157,624063,-;SELinux: Starting in permissive mode
6,158,624064,-;Yama: becoming mindful.
6,159,625585,-;Dentry cache hash table entries: 2097152 (order: 12, 16777216 bytes)
6,160,629691,-;Inode-cache hash table entries: 1048576 (order: 11, 8388608 bytes)
6,161,632167,-;Mount-cache hash table entries: 32768 (order: 6, 262144 bytes)
6,162,633123,-;Mountpoint-cache hash table entries: 32768 (order: 6, 262144 bytes)
6,163,634607,-;Initializing cgroup subsys memory
6,164,635326,-;Initializing cgroup subsys devices这种会 hang 在结尾,需要 Ctrl+C 才能退出。甚至也可以自己写程序捞取:
/* The glibc interface */
#include <sys/klog.h>
int klogctl(int type, char *bufp, int len);不过与前两个不同,它是基于 /proc/kmsg 的,cat 查看这个文件内容通常为空,与 /dev/kmesg 还有一些区别。限于篇幅就不一一介绍了,感兴趣的读者自己 man 查看下吧。
参考
[1]. Linux内核入门-- likely和unlikely
[2]. Linux内核输出的日志去哪里了
[3]. Pid Namespace 详解
[5]. struct pid & pid_namespace
[6]. 一文看懂Linux进程ID的内核管理
[9]. linux系统pid的最大值研究