机器学习模型融合stacking详解+实战
原创机器学习模型融合stacking详解+实战
原创
皮大大
发布于 2024-05-17 08:50:18
发布于 2024-05-17 08:50:18
公众号:尤而小屋 编辑:Peter 作者:Peter
大家好,我是Peter~
今天给大家分享一个机器学习和数据挖掘的模型融合方法:Stacking
1 Stacking原理
Stacking是一种集成学习技术,也被称为堆叠泛化,是一种机器学习中的Ensemble方法,它通过组合多个模型的预测来提高整体的预测性能。
具体来说,Stacking的工作流程如下:
- 训练基学习器:首先训练多个不同的模型,这些模型被称为基学习器或一级学习器。每个基学习器都是独立训练的,并且可以使用不同的算法或参数。
- 生成一级预测结果:使用这些基学习器对训练集或另一个数据集进行预测,得到每个模型的预测结果。
- 构造次级学习器:将基学习器的预测结果作为新的特征输入到一个次级学习器中,这个次级学习器也被称为元学习器或二级学习器。元学习器的目标是通过组合基学习器的预测来得到最终的预测结果。
- 得到最终预测结果:使用元学习器对基学习器的预测结果进行二次预测,从而得到最终的预测结果。
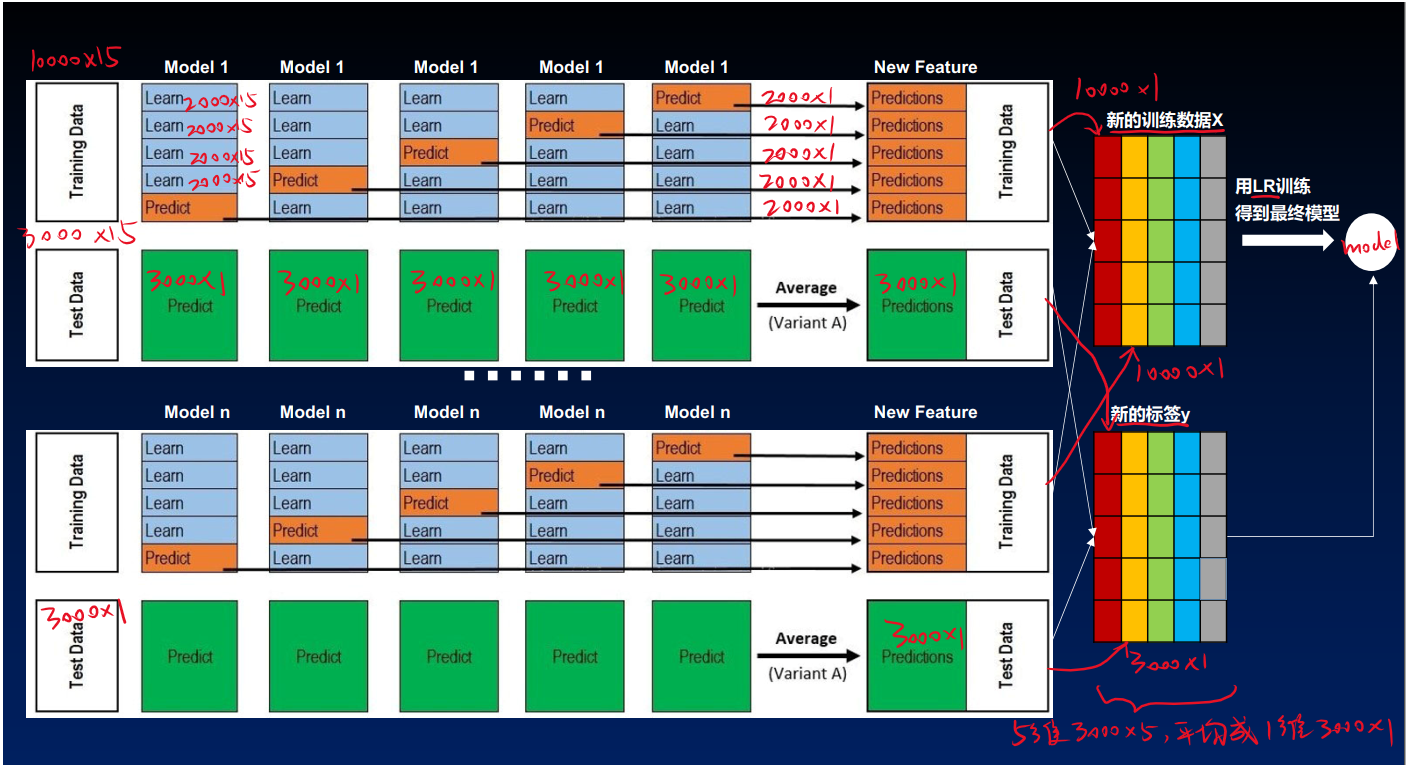
图片来源:https://blog.csdn.net/weixin_40633696/article/details/108721395
关于多个机器学习模型进行stacking,作者通过图解进行详细解释:
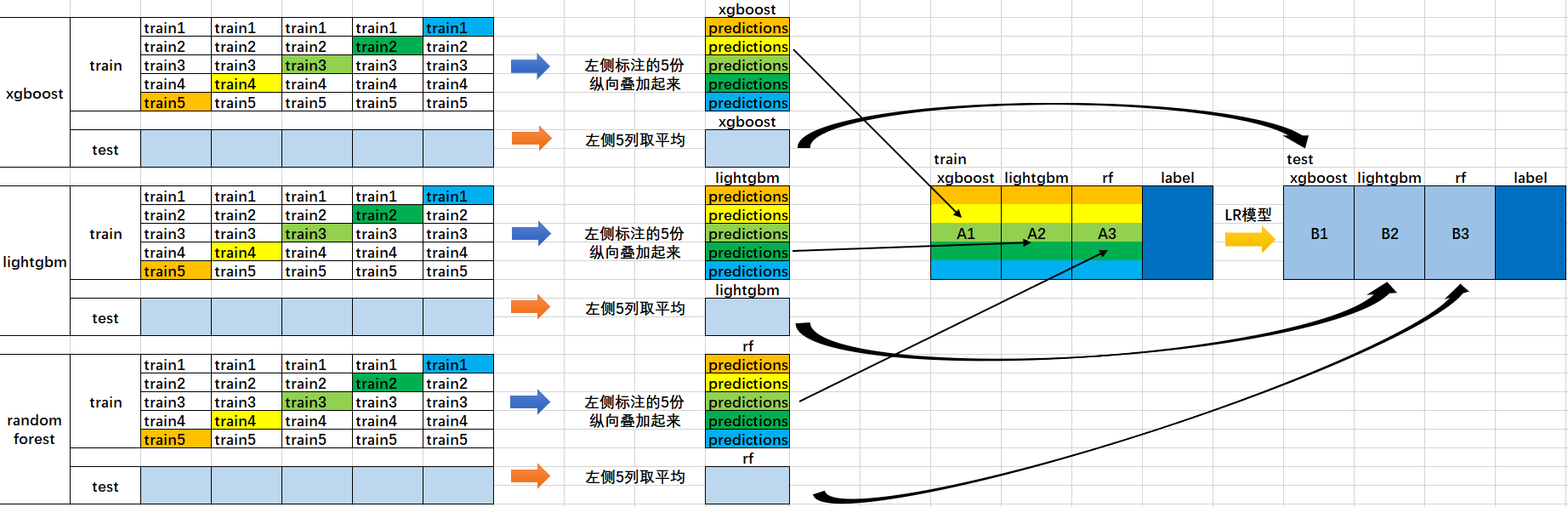
- 将原始数据训练集和测试集,然后将训练集分成5份:train1,train2,train3,train4,train5。
- 选定基模型。假定选择xgboost, lightgbm 和 randomforest 作为基模型。比如xgboost模型部分:依次用train1,train2,train3,train4,train5作为验证集,其余4份作为训练集,进行5折交叉验证进行模型训练;再在测试集上进行预测。这样会得到在训练集上由xgboost模型训练出来的5份predictions,和在测试集上的1份预测值B1。将这五份纵向重叠合并起来得到A1。lightgbm和randomforest模型部分同理。
- 三个基模型训练完毕后,将三个模型在训练集上的预测值作为分别作为3个"特征"A1,A2,A3,使用LR模型进行训练,建立LR模型。
- 使用训练好的LR模型,在三个基模型之前在测试集上的预测值所构建的三个"特征"的值(B1,B2,B3)上,进行预测,得出最终的预测类别或概率。
下面通过代码实操看看基于Stacking模型堆叠集成和单个模型的效果对比:
2 导入库
In 1:
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier, StackingClassifier
from sklearn.neighbors import KNeighborsClassifier
from sklearn.svm import SVC
from sklearn.datasets import load_iris, load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import warnings
warnings.filterwarnings("ignore")3 数据切分
分离X和y,并切分数据集:
In 2:
cancer = load_breast_cancer()
X = cancer.data
y = cancer.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)4 RandomForestClassifier单模型预测
实例化模型对象:
In 3:
rf = RandomForestClassifier() 进行模型训练:
In 4:
rf.fit(X_train,y_train)模型的预测:
In 5:
y_pred = rf.predict(X_test)输出单个模型的准确率:
In 6:
acc1 = accuracy_score(y_test, y_pred)
acc1Out6:
0.96491228070175445 KNeighborsClassifier单模型预测
In 7:
knc = KNeighborsClassifier()
knc.fit(X_train,y_train)模型的预测:
In 8:
y_pred = knc.predict(X_test)In 9:
acc2 = accuracy_score(y_test, y_pred)
acc2Out9:
0.9561403508771936 SVC单模型预测
In 10:
svc = SVC()
svc.fit(X_train,y_train)进行模型的预测:
In 11:
y_pred = svc.predict(X_test)In 12:
acc3 = accuracy_score(y_test, y_pred)
acc3Out12:
0.94736842105263157 基于Stacking的模型融合预测
7.1 定义基分类器
In 13:
base_models = [
('rf', RandomForestClassifier(n_estimators=50, random_state=42)),
('knn', KNeighborsClassifier()),
('svc', SVC(probability=True, random_state=42))
]7.2 定义最终的逻辑回归分类器
In 14:
meta_model = LogisticRegression() 7.3 定义堆叠集成
In 15:
stacking_clf = StackingClassifier(estimators=base_models, final_estimator=meta_model)
stacking_clf.fit(X_train, y_train)基于融合模型的预测:
In 16:
y_pred = stacking_clf.predict(X_test)
acc = accuracy_score(y_test, y_pred)
accOut16:
0.9736842105263158对比两种方案的效果:
In 17:
print("基于Stacking模型融合比RandomForestClassifier提升效果:{:.2f}%".format((acc - acc1) * 100))
print("基于Stacking模型融合比KNeighborsClassifier提升效果:{:.2f}%".format((acc - acc2) * 100))
print("基于Stacking模型融合比SVC提升效果:{:.2f}%".format((acc - acc3) * 100))基于Stacking模型融合比RandomForestClassifier提升效果:0.88%
基于Stacking模型融合比KNeighborsClassifier提升效果:1.75%
基于Stacking模型融合比SVC提升效果:2.63%最终的结果对比:发现stacking融合后比单个模型的效果都有所提升
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录