短语挖掘与流行度、一致性及信息度评估:基于文本挖掘与词频统计|附数据代码
短语挖掘与流行度、一致性及信息度评估:基于文本挖掘与词频统计|附数据代码

在信息爆炸的时代,文本数据呈现出爆炸式的增长,从新闻报道、社交媒体到学术论文,无处不在的文本信息构成了我们获取知识和理解世界的重要来源。然而,如何从海量的文本数据中提取有价值的信息,尤其是那些能够反映主题、趋势或情感倾向的短语,成为了文本挖掘领域的一个重要挑战(点击文末“阅读原文”获取完整代码数据)。
相关视频
短语挖掘作为文本挖掘的一个重要分支,旨在从文本数据中识别和提取出具有特定含义或功能的短语。这些短语不仅能够帮助我们快速了解文本的主题和内容,还能够揭示文本之间的关联和差异。然而,短语挖掘的过程并非易事,需要考虑到短语的流行度、一致性和信息度等多个因素。
流行度反映了短语在文本中的普遍程度,是短语重要性和影响力的体现。一致性则衡量了短语在不同文本或语境下的稳定性和一致性,对于理解短语的含义和用法至关重要。而信息度则代表了短语提供的信息量,是评估短语价值的重要指标。
文本挖掘与词频统计:基于R的tm包应用
我们将探讨如何帮助客户使用R语言的tm(Text Mining)包进行文本预处理和词频统计。tm包是一个广泛使用的文本挖掘工具,用于处理和分析文本数据。
首先,我们加载tm包,尽管在加载过程中可能会出现关于该包是在R的3.3.3版本下构建的警告。这通常不会影响包的正常使用,但建议用户检查是否有更新的版本可用。
接下来,我们假设已经有一个名为pinglun1的变量,其中包含了待处理的文本数据。我们将对该数据进行一系列预处理步骤,以改善文本质量并提取有价值的信息。
dtm <- DocumentTermMatrix(reuters,
control = list(weighting = function(x) weightTfIdf(x, normalize = FALSE),
通过上述步骤,我们成功地对文本数据进行了预处理,并创建了一个包含TF-IDF加权词频的文档-术语矩阵。这为我们后续的词云生成、主题建模等分析工作提供了基础。在文本挖掘的实践中,预处理步骤对于提取文本中的有用信息至关重要,因此需要根据具体任务和数据特点进行细致的调整和优化。
文档-术语矩阵的构建与稀疏项的处理
在文本挖掘的实践中,构建文档-术语矩阵(Document-Term Matrix, DTM)是分析文本数据的关键步骤之一。通过使用R语言的tm包,我们能够方便地创建并处理这类矩阵。在本节中,我们将展示如何构建DTM,并讨论如何处理其中的稀疏项。
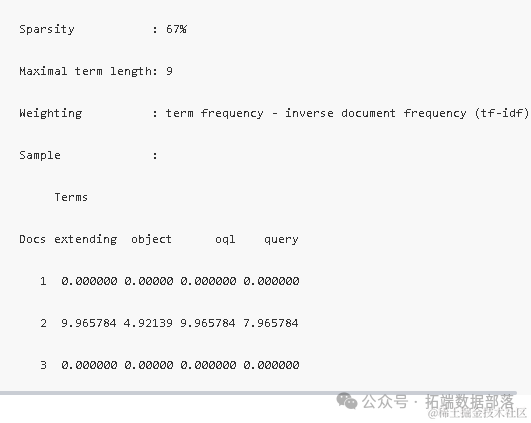
首先,我们成功创建了一个DTM,其包含了三个文档和四个术语。该矩阵的非零/稀疏项比例为4/8,稀疏度达到了67%,意味着大部分项都是零值。此外,矩阵中的最大术语长度为9个字符,而权重计算则基于词频-逆文档频率(TF-IDF)方法。以下是DTM的一个样本展示:
在文本分析中,稀疏项(即那些出现频率极低或根本不出现的术语)可能会引入噪声,影响后续分析的准确性。因此,我们通常采用一种策略来移除这些稀疏项。在R中,tm包提供了removeSparseTerms函数来实现这一目的。
为了移除稀疏项,我们设定了一个阈值,即当一个术语在文档中的出现频率低于某个比例时,它将被视为稀疏项并被移除。在本例中,我们选择了99%作为稀疏度的阈值,这意味着只有出现频率高于1%的术语会被保留在矩阵中。通过以下代码,我们实现了这一目标:
# 移除稀疏项
dtm2 <- removeSparseTerms(dtm, sparse=0.99)
通过上述步骤,我们成功地构建了一个DTM,并通过移除稀疏项来提高了矩阵的密度和质量。这为后续的文本分析工作提供了更为可靠的数据基础。
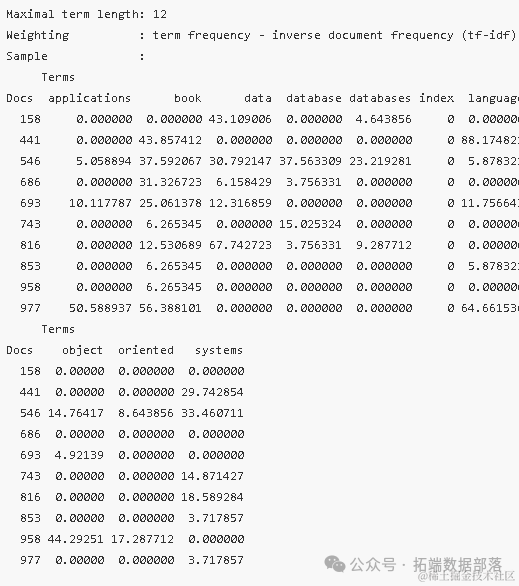
这些TF-IDF权重值不仅反映了词汇在特定文档中的使用频率,还考虑了词汇在整个文档集合中的普遍性。通过比较不同文档间的TF-IDF值,我们可以识别出在不同文档中频繁出现但在整个文档集中较为罕见的关键词,这些关键词往往与文档的主题或内容密切相关。
Weilong Zhang
拓端分析师
最后,基于优化后的文档-术语矩阵,我们将进行深入的词频统计分析,以揭示不同文档之间的词汇使用模式和差异。这些分析结果将有助于我们更好地理解文档的主题、内容和结构,并为后续的文本挖掘任务提供有价值的参考。
基于词频统计的文本数据分析与短语挖掘
在本文中,我们利用词频统计技术对文本数据进行了深入分析,并尝试从中提取出具有代表性的频繁短语。首先,我们展示了部分文档的词频统计结果,这些数据为后续的短语挖掘提供了基础。
一、词频统计结果展示
通过运行head(data2)函数,我们获得了部分文档的词频统计结果。这些统计结果展示了不同文档在各个词汇上的使用频率,如下表所示:
head(data2)
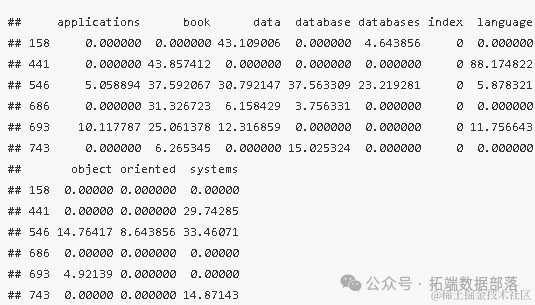
这些统计数据为我们提供了关于文档中词汇使用情况的直观认识,并揭示了不同词汇在不同文档中的权重差异。
短语挖掘与流行度分析
接下来,我们尝试根据流行度从词频统计结果中挖掘出频繁短语。尽管本文未提及具体的流行度计算公式,但我们可以假设该公式基于词频统计结果,并可能结合了其他文本特征(如逆文档频率等)。
在进行短语挖掘之前,我们首先通过summary(data)函数查看了文档数据的基本情况。该函数返回了文档的数量和类型(字符型),表明我们处理的是包含1000个文档的字符型数据集。
# 根据流行度把频繁短语挖出来
#
summary(data)

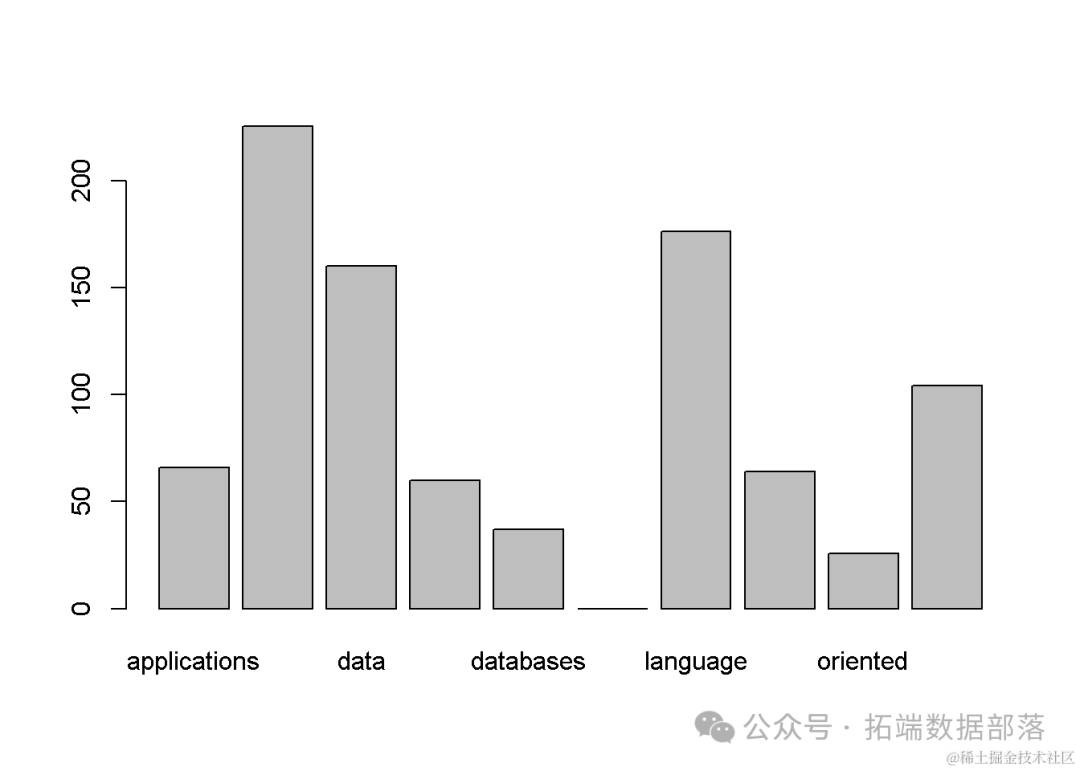
然后,为了更直观地展示各个词汇在文档集合中的整体使用情况,我们利用barplot(colSums(data2))函数绘制了词频总和的条形图。通过该图,我们可以迅速识别出在整个文档集合中频繁出现的词汇,并初步判断它们的流行度。
然而,需要注意的是,单纯的词频统计可能无法完全反映短语在文本中的实际意义和重要性。因此,在后续的研究中,我们计划进一步结合短语在文本中的上下文信息、语义关系等因素,以提高短语挖掘的准确性和有效性。
# data2=data2[,-1]
par(mfrow=c(1,1))
barplot(colSums(data2 ))