WWW'24 | 用相似用户和item增强点击率预估

1. 导读
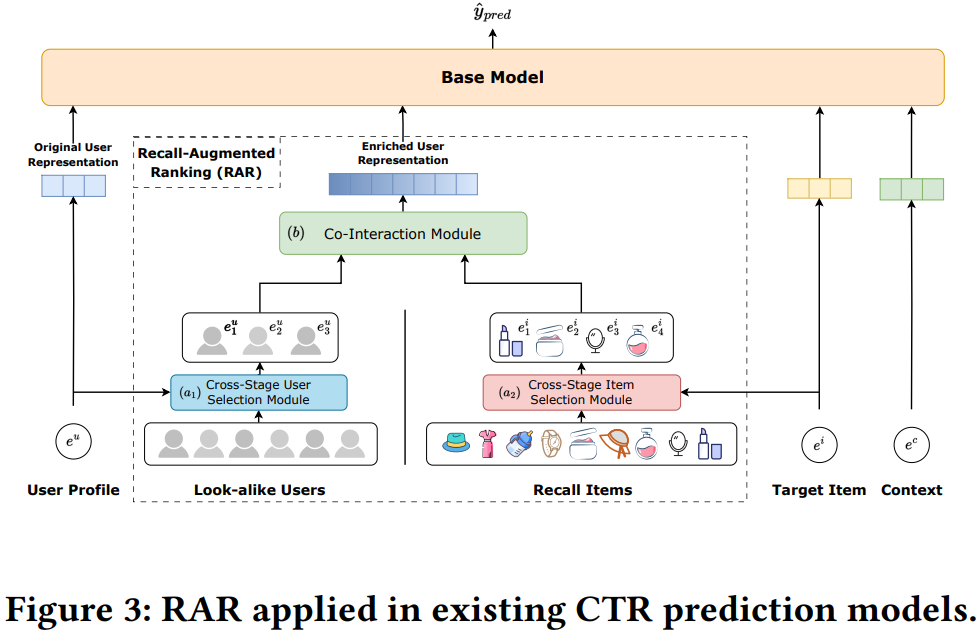
CTR预估中,我们可以利用用户行为序列来捕捉用户不断变化的偏好。但是,历史序列往往具有严重的同源性和稀缺性。本文提出了一种数据驱动的方法来丰富用户表征。将用户画像和召回的item看作是跨阶段框架内的两个理想数据源,分别包括u2u(用户对用户)和i2i(item对item)。本文提出了一种新的体系结构,称为召回增强排序(RAR),由两个子模块组成,它们协同地从大量相似的用户和召回item中收集信息,从而产生丰富的用户表征。
相比于其他推荐模型,本文额外增加了一些模块,可以和其他ctr模型结合:
- 基于用户emb,通过simhash在用户集合中检索相似用户
- 基于目标item的emb,通过simhash在召回item中检索相似item
- 基于检索得到的相似用户和item构建交互矩阵,使用交互矩阵对相似用户和item进行加权聚合
- 随后用于后续的点击率预估
2.方法
alt text
2.1 跨阶段用户/item选择模块
该模块的作用是选择最相似的用户和相关item。以item的选择为例:
- 通过相似性函数f()计算目标item和每个召回item之间的相似性
- 基于相似度得分来选择topk个相关召回item
简单直接的方式是计算emb之间的内积,然后选择topk个。但是这会存在大量的乘法运算,计算量太大。在实验中作者采用SimHash函数(局部敏感hash算法的一种,不了解的朋友可以搜一下)。
- 简单解释一下:在这里,将emb分成N组,并且设置一组随机向量,然后将分组后的emb和这些向量做内积,大于0则为1,小于0则为0,这样每一个子emb可以得到一串二进制串,基于二进制串可以得到对应的实数值,对于N组可以得到N个值,这样就可以根据值是否相同来判断emb之间是否相似。
2.2 协同交互模块
引入了一个匹配矩阵来评估用户-商品兴趣匹配度。匹配得分表示为高阶交互后的潜在向量的内积,表示为下式,其中
和
分别表示前面选出来的最相似的k个用户和item的emb矩阵,经过MLP后得到高阶表征,然后计算相似度,通过sigmoid得到0-1的得分。
为了让模型更清楚地表明哪些召回item更重要,将
作为匹配矩阵训练的监督信号。由于曝光的信号很稀疏,作者在这里应该是把与当前u相似的u中都没有曝光过item i,则信号0作为当前矩阵ui对应位置的信号,反之为1。
最后,按行和列对匹配矩阵进行平均,得到item和用户的加权向量。然后对前面筛选出来的相似item和用户的emb进行加权聚合,表示如下,
最后的损失函数由两部分组成,分别是原始的点击率预测的交叉熵损失和这里的权重矩阵学习的交叉熵损失函数。
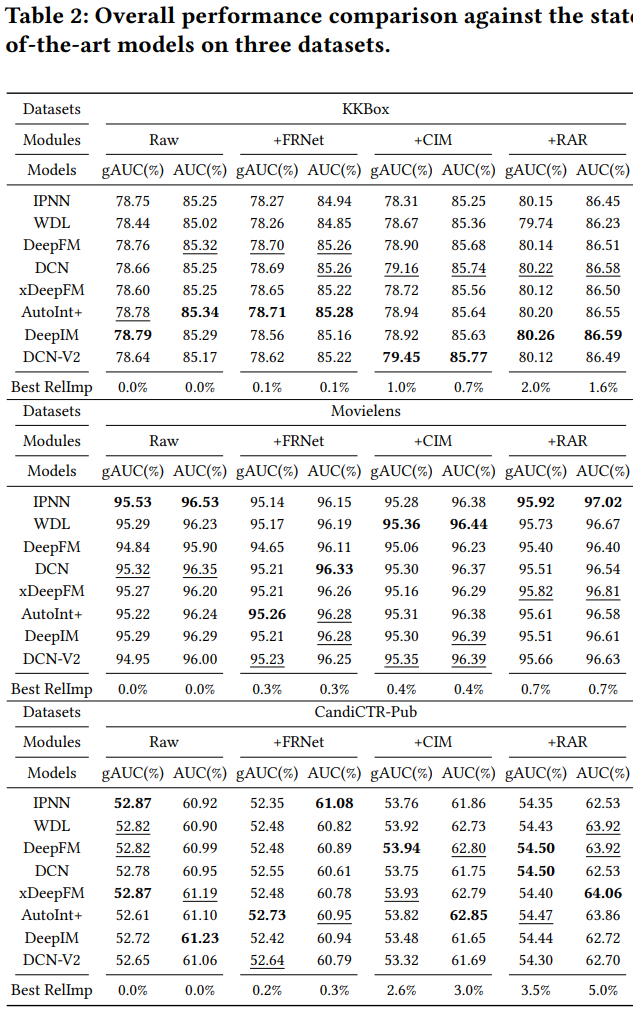
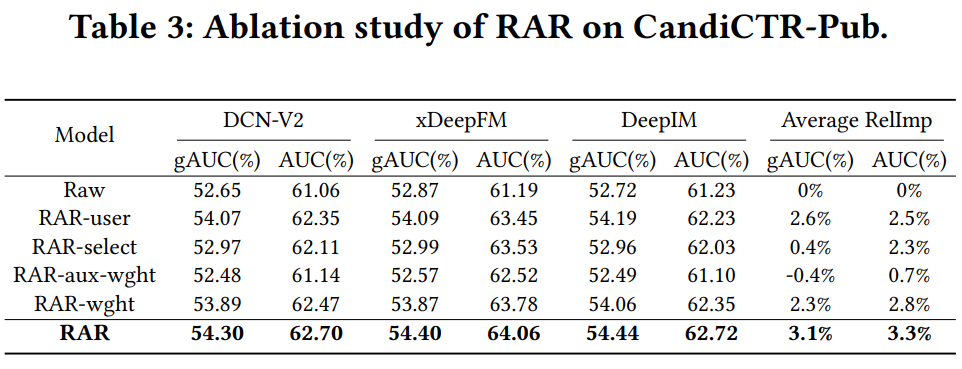
3. 结果
本文参与 腾讯云自媒体分享计划,分享自微信公众号。
原始发表:2024-05-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录