Kafka怎么避免重复消费

Kafka 是一种分布式流式处理平台,它使用了一些机制来避免消息的重复消费,包括以下几种方式:
◆消息偏移量(Offset)管理:
Kafka 使用消息偏移量(Offset)来唯一标识每条消息。消费者在消费消息时,可以保存已经消费过的消息偏移量,然后在消费新消息时,从上一次消费的偏移量开始,避免重复消费。消费者可以使用 Kafka 提供的 API 来提交消费的偏移量,从而实现精确的消费控制.例如,将 enable.auto.commit 设置为 false 后手动提交消费的偏移量。
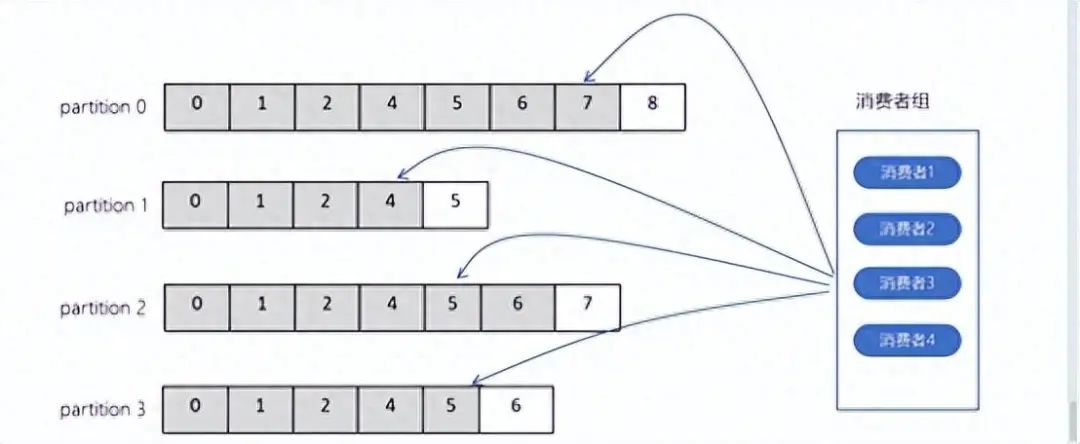
◆消费者组(Consumer Group)管理:
Kafka 允许多个消费者以消费者组的形式同时消费同一个主题(Topic)的消息。每个消费者组都有唯一的消费者组 ID,并且每个消费者在消费时只能消费属于该消费者组的某个分区(Partition)中的消息。这样,不同的消费者组可以独立消费消息,互不干扰,避免了重复消费。例如可以设置auto.offset.reset=earliest,earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
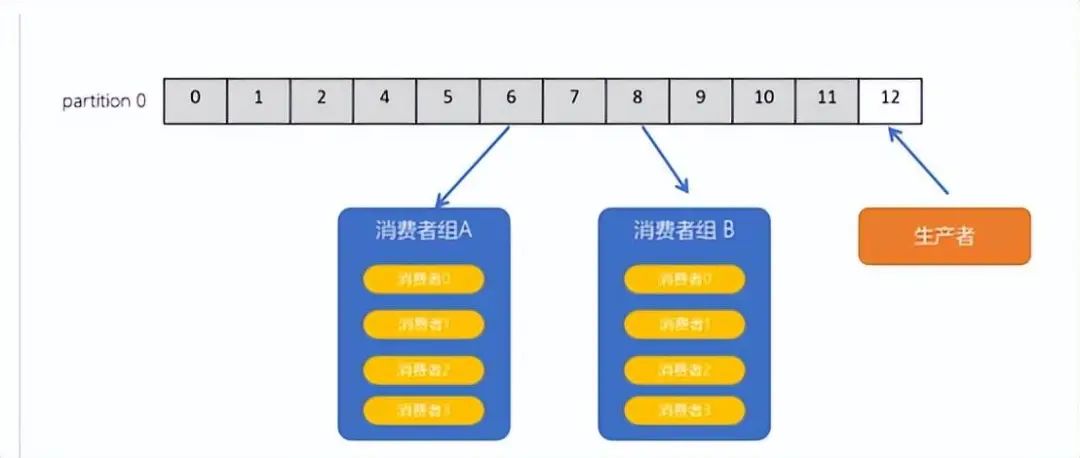
◆消息提交确认(Acknowledgment)机制:
Kafka 支持消费者在消费完消息后,通过确认机制将消费结果提交给 Kafka,Kafka 可以确认消息已经成功被消费。这样,即使消费者在消费过程中发生错误,也可以通过提交确认消息的方式来避免重复消费。消费者可以设置自动提交确认或手动提交确认的方式,根据具体的需求来选择。
比如设置ack=1时,等待leader副本确认接收后,才会发送下条信息
◆幂等性生产者(Idempotent Producer):
Kafka 提供了幂等性生产者的功能,可以保证生产者在发送消息时,消息不会重复发送。幂等性生产者通过在发送消息时为每条消息分配唯一的序列号,并在消息的生命周期内对消息进行去重和幂等性校验,避免了重复发送相同消息。
为了实现生产者的幂等性,Kafka引入了 Producer ID(PID)和 Sequence Number的概念。
- PID:每个Producer在初始化时,都会分配一个唯一的PID,这个PID对用户来说,是透明的。
- Sequence Number:针对每个生产者(对应PID)发送到指定主题分区的消息都对应一个从0开始递增的Sequence Number。
◆消息重复检测:
Kafka 在 Broker 端通过消息的消息 ID(Message ID)和日志段偏移量(Log Segment Offset)来检测消息的重复性。如果消费者在消费过程中由于某些原因重复消费了消息,Kafka 可以通过消息 ID 和日志段偏移量的对比来识别和丢弃重复消息。
通过kafka以上的措施,当消费者消费数据时,每隔一段时间会将自己消费过的消息的 offset 提交一下,表示“我已经消费过了,下次我要是重启啥的,你就让我继续从上次消费到的 offset 继续消费吧”。
但是,有时候可能会出现一些意外情况,比如重启系统时直接 kill 进程,导致消费者有些消息处理了但是没有来得及提交 offset,重启之后就会出现少数消息被重复消费的情况。
总的来说,消息队列(MQ)中产生重复消费的问题,主要是由于以下原因:
- 消费者异常关闭:当消费者异常关闭时,可能会导致已经消费过的消息没有被确认,从而出现重复消费的问题。
- 网络故障:当网络出现故障时,可能会导致消息没有被正确地发送到消费者端,从而出现重复消费的问题。
- 消费者处理消息失败:当消费者处理消息失败时,可能会导致消息没有被确认,从而出现重复消费的问题。
为了避免这些问题,我们需要采取一些措施来保证消息的可靠性,例如手动确认消息、消费者自身保证幂等性等。
我们也需要结合业务需求来思考解决方案。以下是几个可能的思路:
如果需要将数据写入数据库,可以先根据主键查询一下,如果该数据已经存在,就不需要再插入一条新的数据了,而是直接进行更新操作。
如果需要将数据写入 Redis 中,这个问题就比较简单了,因为 Redis 的 set 操作天然具有幂等性,即多次执行同样的 set 操作,只会产生一个相同的结果,不会产生重复数据。
如果不是上述两个场景,可能需要进行一些较为复杂的处理。可以在生产者发送每条数据的时候,加上一个全局唯一的 ID,例如订单 ID 等。在消费者消费消息时,可以先根据这个 ID 到 Redis 中查询一下,该消息是否已经被消费过。如果该消息没有被消费过,就进行处理,并将这个 ID 写入 Redis 中,表示该消息已经被消费过了。如果该消息已经被消费过了,就不需要再进行处理了,保证不会重复处理相同的消息。
另外一种解决方案是,基于数据库的唯一键来保证重复数据不会被插入多条。由于有唯一键的约束,重复数据插入时只会报错,而不会导致数据库中出现脏数据。这种方法需要在数据库中设置唯一键约束,从而保证数据的准确性。
来源:https://www.toutiao.com/article/7330615300901585418/?log_from=0546b0bd38f28_1715307831158